
Como contornar um site protegido pelo Cloudflare?
Senior Web Scraping Engineer
Sites protegidos pelo Cloudflare podem ser alguns dos mais difíceis de raspar. Sua detecção automática de bots exige que você use uma ferramenta de web scraping poderosa para contornar as medidas anti-raspagem do Cloudflare e extrair os dados de sua página da web.
Hoje, mostraremos como raspar sites protegidos pelo Cloudflare usando Python e a biblioteca de código aberto Cloudscraper. Dito isso, embora eficaz em alguns casos, você descobrirá que o Cloudscraper tem algumas limitações difíceis de evitar.
O que é o Gerenciamento de Bots do Cloudflare?
O Cloudflare é uma empresa de entrega de conteúdo e segurança na web. Ele oferece um firewall de aplicativo web (WAF) para proteger sites de ameaças de segurança, como script entre sites (XSS), preenchimento de credenciais e ataques DDoS.
Um dos sistemas principais do Cloudflare WAF é o Bot Manager, que mitiga ataques de bots maliciosos sem afetar usuários reais. No entanto, embora o Cloudflare permita bots rastreadores conhecidos, como o Google, ele presume que qualquer tráfego de bot desconhecido (incluindo rastreadores da web) é malicioso.
Introdução ao Cloudflare WAF
O Cloudflare WAF é um componente essencial no sistema de proteção central do Cloudflare, projetado para detectar e bloquear solicitações maliciosas analisando o tráfego HTTP/HTTPS em tempo real. Ele filtra potenciais ameaças, como injeção de SQL, script entre sites (XSS), ataques DDoS etc., com base em conjuntos de regras (incluindo regras predefinidas e regras personalizadas).
O Cloudflare WAF combina banco de dados de reputação de IP, modelo de análise de comportamento e tecnologia de aprendizado de máquina e pode ajustar dinamicamente as estratégias de proteção para responder a novos ataques. Além disso, o WAF é perfeitamente integrado ao CDN e à proteção DDoS do Cloudflare para fornecer segurança multinível para sites, mantendo baixa latência e alta disponibilidade para usuários legítimos.
Na tabela abaixo, você pode ver claramente as medidas de proteção do WAF e a dificuldade de quebra:
| Camada de proteção | Princípio técnico | Dificuldade de quebra |
|---|---|---|
| Detecção de reputação de IP | Análise do comportamento histórico do IP (ASN/geolocalização) | ★★☆☆☆ |
| Desafio JS | Geração dinâmica de problemas matemáticos para verificar o ambiente do navegador | ★★★☆☆ |
| Impressão digital do navegador | Extração de recursos de renderização Canvas/WebGL | ★★★★☆ |
| Token dinâmico | Verificação de token criptografado baseado em timestamp | ★★★★☆ |
| Análise de comportamento | Reconhecimento de trajetória do mouse/padrão de clique | ★★★★★ |
Como o Cloudflare detecta bots?
O sistema de gerenciamento de bots do Cloudflare é projetado para diferenciar bots maliciosos do tráfego legítimo (como rastreadores de mecanismos de pesquisa). Ao analisar as solicitações recebidas, ele identifica padrões incomuns e bloqueia atividades suspeitas para manter a integridade de seus sites e aplicativos.
Seus métodos de detecção podem ser passivos ou ativos. As técnicas passivas de detecção de bots usam impressão digital de back-end, enquanto as técnicas de detecção ativas dependem da análise do lado do cliente.
- Técnicas passivas de detecção de bots
- Detecção de botnets
- Reputação de endereço IP
- Cabeçalhos de solicitação HTTP
- Impressão digital TLS
- Impressão digital HTTP/2
- Técnicas ativas de detecção de bots
- CAPTCHAs
- Impressão digital do Canvas
- Rastreamento de eventos
- Consultas da API do ambiente
3 Erros Principais do Cloudflare
- Erro do Cloudflare 1015: O que é e como evitar
- Erro do Cloudflare 1006, 1007, 1008: O que são e como corrigir
- Cloudflare 403 Negado: Contornar este problema
Como raspar um site protegido pelo Cloudflare?
Etapa 1: Configurar o ambiente
Primeiro, certifique-se de que o Python esteja instalado em seu sistema. Crie um novo diretório para armazenar o código deste projeto. Em seguida, você precisa instalar cloudscraper e requests. Você pode fazer isso via pip:
Shell
$ pip install cloudscraper requestsEtapa 2: Fazer uma solicitação simples usando requests
Agora, precisamos raspar dados da página em https://sailboatdata.com/sailboat/11-meter/ . Uma parte do conteúdo da página é assim:
Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como demonstração do processo de rastreamento. Não salvamos nenhuma informação e dados.
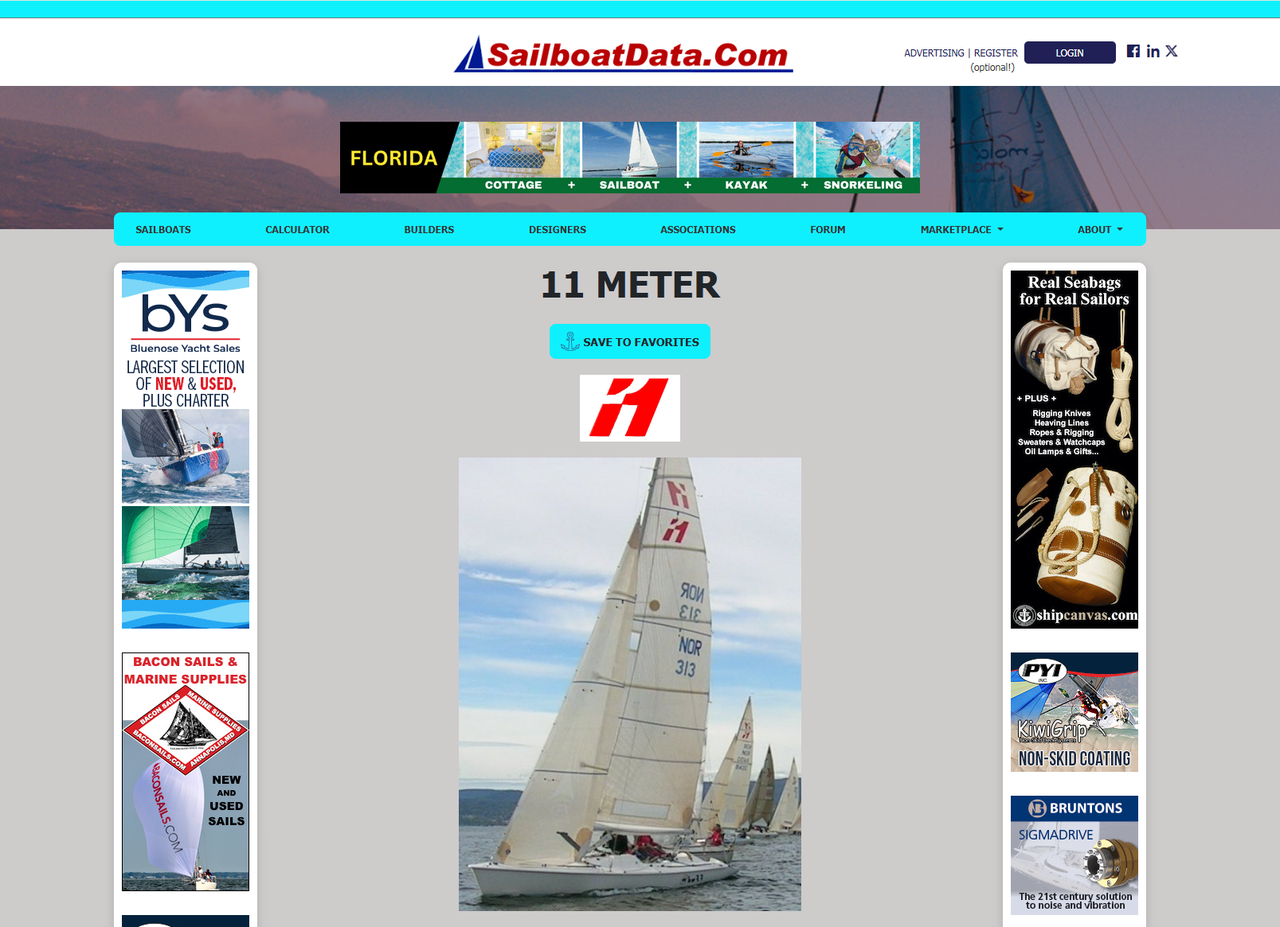
Vamos primeiro tentar enviar uma solicitação GET simples usando requests para confirmar:
Python
def sailboatdata():
html = requests.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 403
with open("response.html", "wb") as f:
f.write(html.content)Como esperado, a página da web retorna um código de status 403 Forbidden. Salvamos a resposta em um arquivo local. O código-fonte específico do conteúdo retornado é mostrado abaixo:

O site de destino está protegido e o arquivo local não pode ser aberto corretamente. Agora, precisamos encontrar uma maneira de contornar isso.
Etapa 3: Raspar dados usando Cloudscraper
Vamos usar o Cloudscraper para enviar a mesma solicitação GET para o site de destino. Aqui está o código:
Python
def sailboatdata_cloudscraper():
scraper = cloudscraper.create_scraper()
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 200
with open("response.html", "wb") as f:
f.write(html.content)Desta vez, o Cloudflare não bloqueou nossa solicitação. Abrimos o arquivo HTML salvo localmente e o visualizamos no navegador. A página é assim:
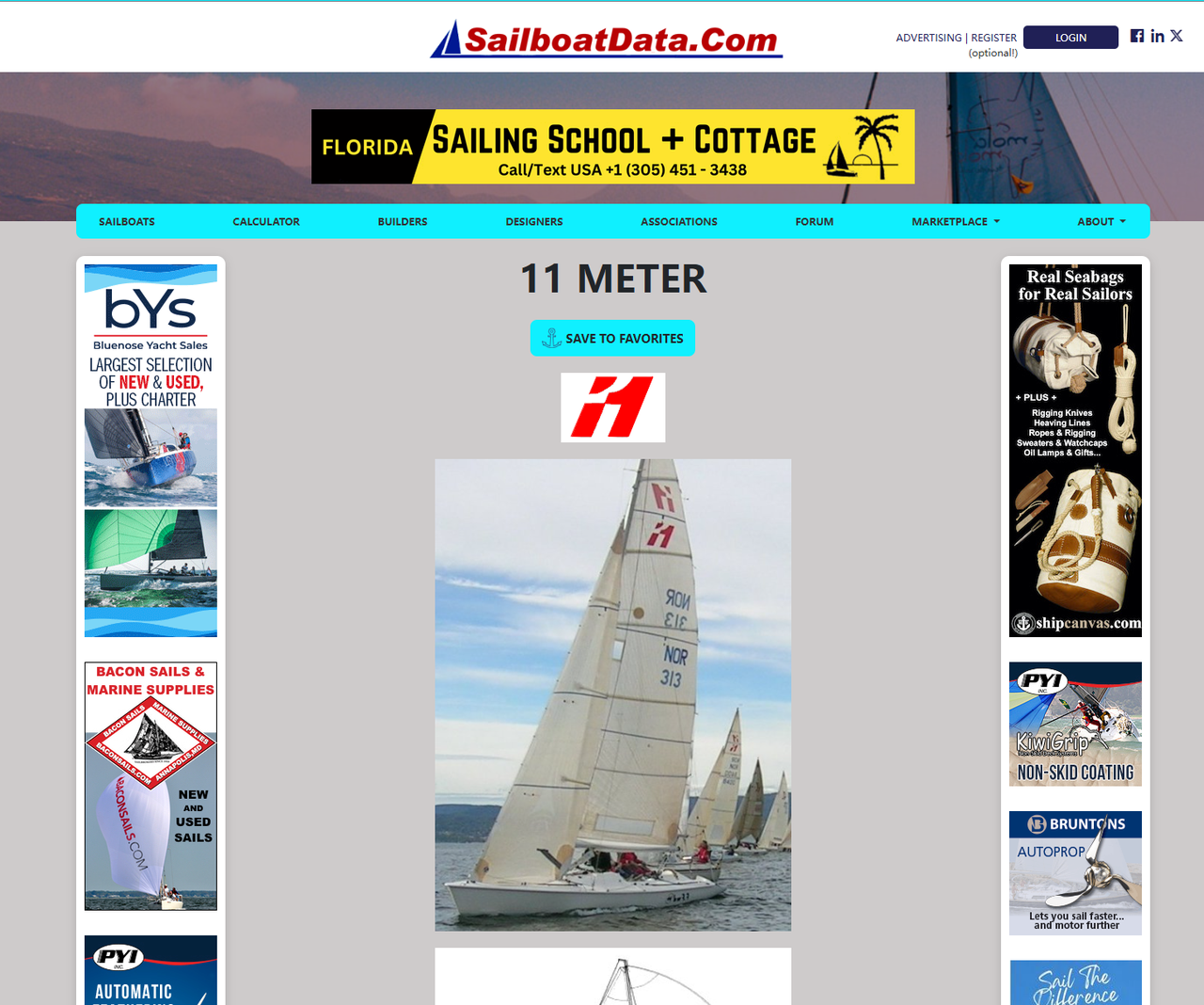
Recursos avançados do Cloudscraper
Manipulação de CAPTCHA integrada
JavaScript
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': '2captcha_api_key'
}
)Suporte a proxy personalizado
Python
proxies = {"http": "seu endereço de proxy", "https": "seu endereço de proxy"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")Navegador de Raspagem Scrapeless: Uma alternativa mais poderosa ao Cloudscraper
Limitações do Cloudscraper
O Cloudscraper tem algumas limitações ao lidar com determinados sites protegidos pelo Cloudflare. O problema mais notável é que ele não consegue contornar o mecanismo de proteção de detecção de robôs versão 2 do Cloudflare. Se você tentar raspar dados de um site desse tipo, o seguinte erro será acionado:
JSON
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.Além disso, o Cloudscraper também não consegue lidar com os desafios avançados de JavaScript do Cloudflare. Esses desafios geralmente envolvem cálculos dinâmicos complexos ou interações com elementos da página, que são difíceis para ferramentas automatizadas como o Cloudscraper simular para passar na verificação.
Outro problema é a política de limitação de taxa do Cloudflare. Para evitar abusos, o Cloudflare controla estritamente a frequência de solicitações, e o Cloudscraper não possui um mecanismo eficaz para gerenciar esses limites, o que pode causar atrasos nas solicitações ou até mesmo falhas.
Por fim, mas não menos importante, à medida que o Cloudflare continua atualizando sua tecnologia de detecção de bots, é difícil para o Cloudscraper, como uma ferramenta de código aberto, acompanhar essas mudanças. Com o tempo, a eficácia e a estabilidade de sua funcionalidade podem diminuir gradualmente, especialmente diante de novas versões de mecanismos de proteção.
Por que o Scrapeless é eficaz?
O Scraping Browser é uma solução de alto desempenho para extrair grandes quantidades de dados de sites dinâmicos. Ele permite que os desenvolvedores executem, gerenciem e monitorem navegadores sem cabeça sem recursos de servidor dedicados. Ele é projetado para extração eficiente de dados da web em larga escala:
- Simule comportamentos de interação humana reais para contornar mecanismos avançados anti-rastreador, como detecção de impressão digital do navegador e detecção de impressão digital TLS.
- Suporte à resolução automática de vários tipos de códigos de verificação, incluindo cf_challenge, para garantir um processo de rastreamento ininterrupto.
- Integração perfeita de ferramentas populares, como Puppeteer e Playwright, para simplificar o processo de desenvolvimento e suportar código de uma linha para iniciar tarefas automatizadas.
Como integrar o Scraping Browser para contornar o Cloudflare?
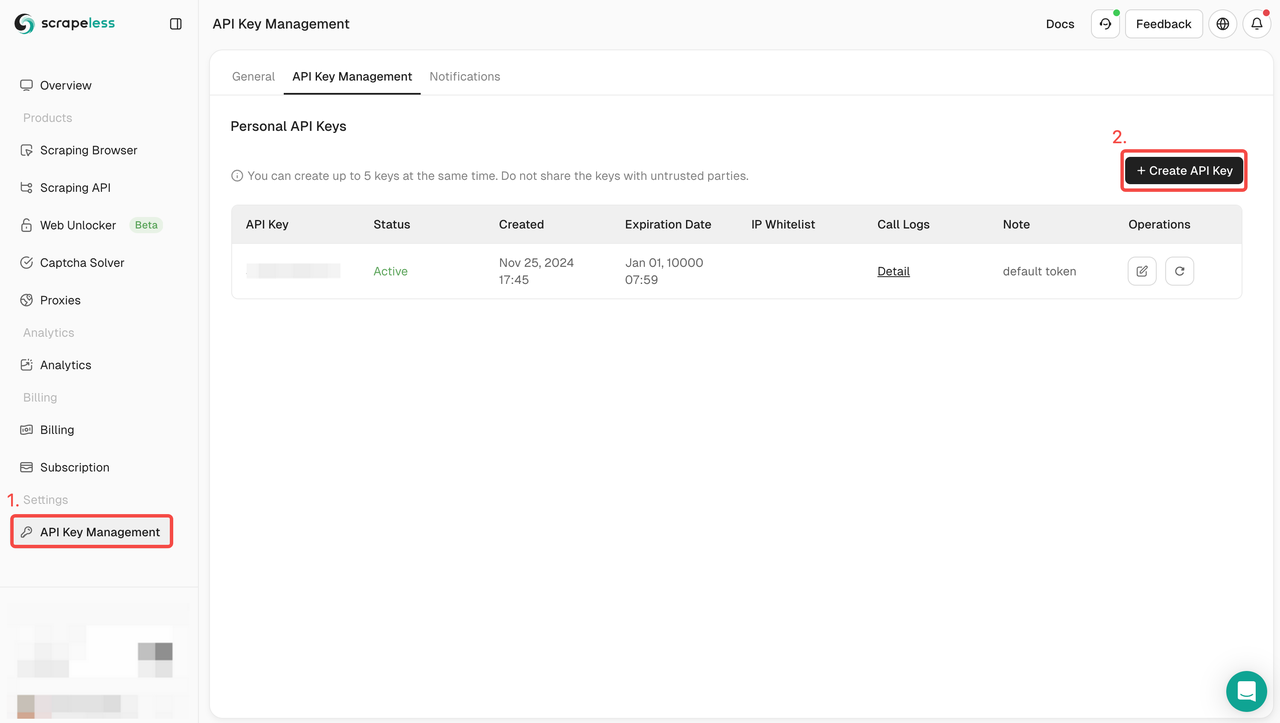
Etapa 1. Crie seu token de API
- Inscreva-se no Scrapeless
- Escolha Gerenciamento de Chave API
- Clique em Criar Chave API para criar sua Chave API Scrapeless.
O Scrapeless garante rastreamento de web perfeito.
🎁 Junte-se ao Discord e solicite sua avaliação gratuita agora!
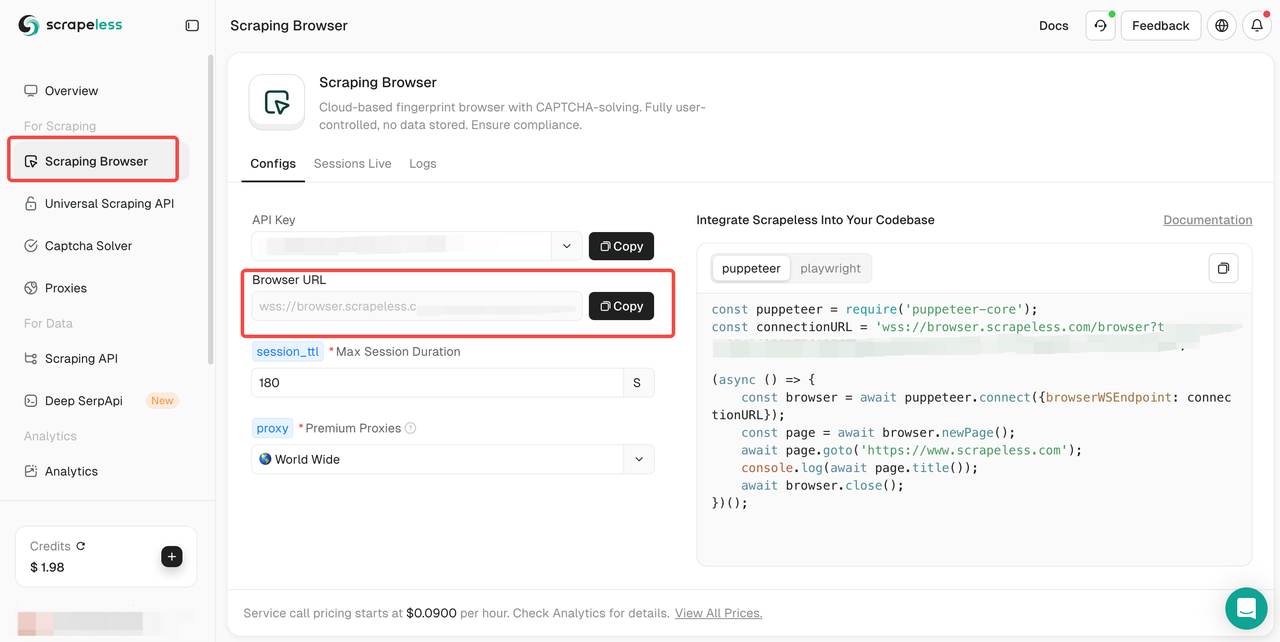
Etapa 2. Em seguida, vá para o Scraping Browser e copie seu URL do navegador.
Ou você pode verificar nosso código de solicitação como referência:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_API_TOKEN>&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Etapa 3. Integre o código ou URL do navegador em seu script Puppeteer:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// configurar ambiente do navegador
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// criar uma nova página
const page = await browser.newPage();
// navegar para um URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'networkidle0',
}); // Substitua pelo seu URL de destino
// aguardar a resolução do desafio
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// tirar captura de tela da página
await page.screenshot({ path: 'screenshot.png' });
// fechar a instância do navegador
await browser.close();
})();4 Dicas para contornar o Cloudflare
Se você quiser hackear o Cloudflare sozinho, será muito difícil! Você tem que considerar todas as defesas que o Cloudflare tem contra bots e encontrar maneiras de superá-las. A maioria das pessoas definitivamente não escolherá fazer isso.
Você quer tentar? Aqui estão algumas dicas para ajudá-lo a contornar o Cloudflare:
Renderização JavaScript
O Cloudflare costuma usar desafios de JavaScript para detectar bots. Esses scripts são incorporados em páginas da web e executam verificações específicas por meio do navegador para determinar se o visitante é um bot. Se um bot for suspeito, o Cloudflare exibirá um CAPTCHA (como o código de verificação Turnstile), caso contrário, permitirá acesso normal.
Portanto, para rastrear páginas protegidas, você precisa usar ferramentas de automação de navegador, como Playwright, Selenium ou Puppeteer, para simular interações reais do usuário. No entanto, a configuração padrão de navegadores sem cabeça pode ser exposta a sistemas anti-bot. É recomendável usar bibliotecas Playwright Stealth ou Puppeteer Stealth para ocultar rastros de automação.
Resolução de CAPTCHA
O CAPTCHA é um teste-chave para distinguir bots de humanos. Pode incluir verificação de clique simples ou quebra-cabeças complexos. Analisar automaticamente o CAPTCHA é difícil, portanto, você pode tentar contorná-lo com tecnologia Python ou usar o Cloudflare Turnstile Solver do Bright Data para resolvê-lo automaticamente.
Evitando o limite de taxa
O Cloudflare acionará limites de taxa para muitas solicitações em um curto período de tempo, o que pode fazer com que o IP seja bloqueado temporária ou permanentemente. Para evitar esse problema, é recomendável usar um serviço de proxy (como um proxy residencial) para implementar a rotação de IP e disfarçar a solicitação como um dispositivo real.
Spoofing de navegador
Embora as ferramentas de automação de navegador sejam eficazes, elas consomem muitos recursos. Se o Cloudflare WAF não estiver configurado estritamente, você pode usar a tecnologia de spoofing de navegador para enviar solicitações HTTP para imitar o comportamento de um navegador real (como definir o cabeçalho User-Agent). No entanto, em cenários mais complexos, os cabeçalhos sozinhos podem não ser suficientes e você também precisa copiar a impressão digital TLS do navegador (como usar a ferramenta curl-impersonate).
Finalizando
Neste artigo, você aprendeu dicas e truques sobre como raspar sites protegidos pelo Cloudflare. O Cloudflare é o serviço CDN mais popular do mercado e também oferece soluções anti-bot avançadas.
Como este artigo mostra, contornar as medidas anti-raspagem do Cloudflare é desafiador, mas não impossível. Tudo fica mais fácil com soluções de rastreamento profissionais, rápidas e confiáveis, como:
- API de Raspagem Universal: Contorna autonomamente limites de taxa, impressão digital e outras restrições anti-bot para coleta perfeita de dados da web pública.
- Scraping Browser: Um navegador totalmente hospedado que permite raspar dados da web dinâmica enquanto automatiza o processo de desbloqueio de sites.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


