
Servidor MCP sem resíduos está oficialmente no ar! Construa seu Conector AI-Web definitivo.
Expert Network Defense Engineer
Os Grandes Modelos de Linguagem (LLMs) estão se tornando cada vez mais poderosos, mas são inerentemente limitados ao lidar com conteúdo estático. Eles não podem abrir páginas da web em tempo real, processar conteúdo renderizado em JavaScript, resolver CAPTCHAs ou interagir com websites. Essas limitações restringem severamente a aplicação no mundo real e o potencial de automação da IA.
A Scrapeless agora lança oficialmente o serviço MCP (Modelo de Protocolo de Contexto) — uma interface unificada que dá aos LLMs a capacidade de acessar dados da web ao vivo e realizar tarefas interativas. Este artigo irá guiá-lo através do que é o MCP, como ele pode ser implementado, os mecanismos de comunicação subjacentes e como construir rapidamente um agente de IA capaz de pesquisar, navegar, extrair e interagir com a web usando a Scrapeless.
Scrapeless MCP Server
O Que É o MCP?
Definição
O Protocolo de Contexto do Modelo (MCP) é um padrão aberto baseado em JSON-RPC 2.0. Ele permite que os Grandes Modelos de Linguagem (LLMs) acessem ferramentas externas através de uma interface unificada — como executar scrapers de web, consultar bancos de dados SQL ou invocar qualquer API REST.
Como Funciona
O MCP segue uma arquitetura em camadas, definindo três papéis na interação entre LLMs e recursos externos:
- Cliente: Envia solicitações e se conecta ao servidor MCP.
- Servidor: Recebe e analisa o pedido do cliente, encaminhando-o para o recurso apropriado (como um banco de dados, scraper ou API).
- Recurso: Executa a tarefa solicitada e retorna o resultado ao servidor, que o reencaminha ao cliente.
Esse design permite um roteamento eficiente de tarefas e um controle de acesso rígido, garantindo que apenas clientes autorizados possam usar ferramentas específicas.
Mecanismos de Comunicação
O MCP suporta dois tipos principais de comunicação: comunicação local via entrada/saída padrão (Stdio) e comunicação remota via HTTP + Eventos Enviados pelo Servidor (SSE). Ambos seguem a estrutura unificada do JSON-RPC 2.0, permitindo uma comunicação padronizada e escalável.
- Local (Stdio): Usa fluxos de entrada/saída padrão. Ideal para desenvolvimento local ou quando o cliente e o servidor estão na mesma máquina. É rápido, leve e ótimo para depuração ou fluxos de trabalho locais.
- Remoto (HTTP + SSE): As solicitações são enviadas por HTTP POST, e as respostas em tempo real são transmitidas via SSE. Este modo suporta sessões persistentes, reconexão e reprodução de mensagens — tornando-o bem adequado para ambientes baseados em nuvem ou distribuídos.
Ao desacoplar o transporte da semântica do protocolo, o MCP pode se adaptar de forma flexível a diferentes ambientes, maximizando a capacidade do LLM de interagir com ferramentas externas.
Por Que o MCP É Necessário?
Embora os LLMs sejam ótimos na geração de texto, eles enfrentam dificuldades com a consciência e interação em tempo real.
LLMs São Limitados por Dados Estáticos e Falta de Acesso a Ferramentas
A maioria dos modelos é treinada em instantâneas históricas da internet, o que significa que eles carecem de conhecimento em tempo real do mundo. Eles também não podem alcançar ativamente sistemas externos devido a restrições arquitetônicas e de segurança.
Por exemplo, o ChatGPT não pode recuperar diretamente dados de produtos atuais da Amazon. Como resultado, os preços ou informações de estoque que ele fornece podem estar desatualizados e serem pouco confiáveis — perdendo promoções, recomendações ou alterações de inventário em tempo real.
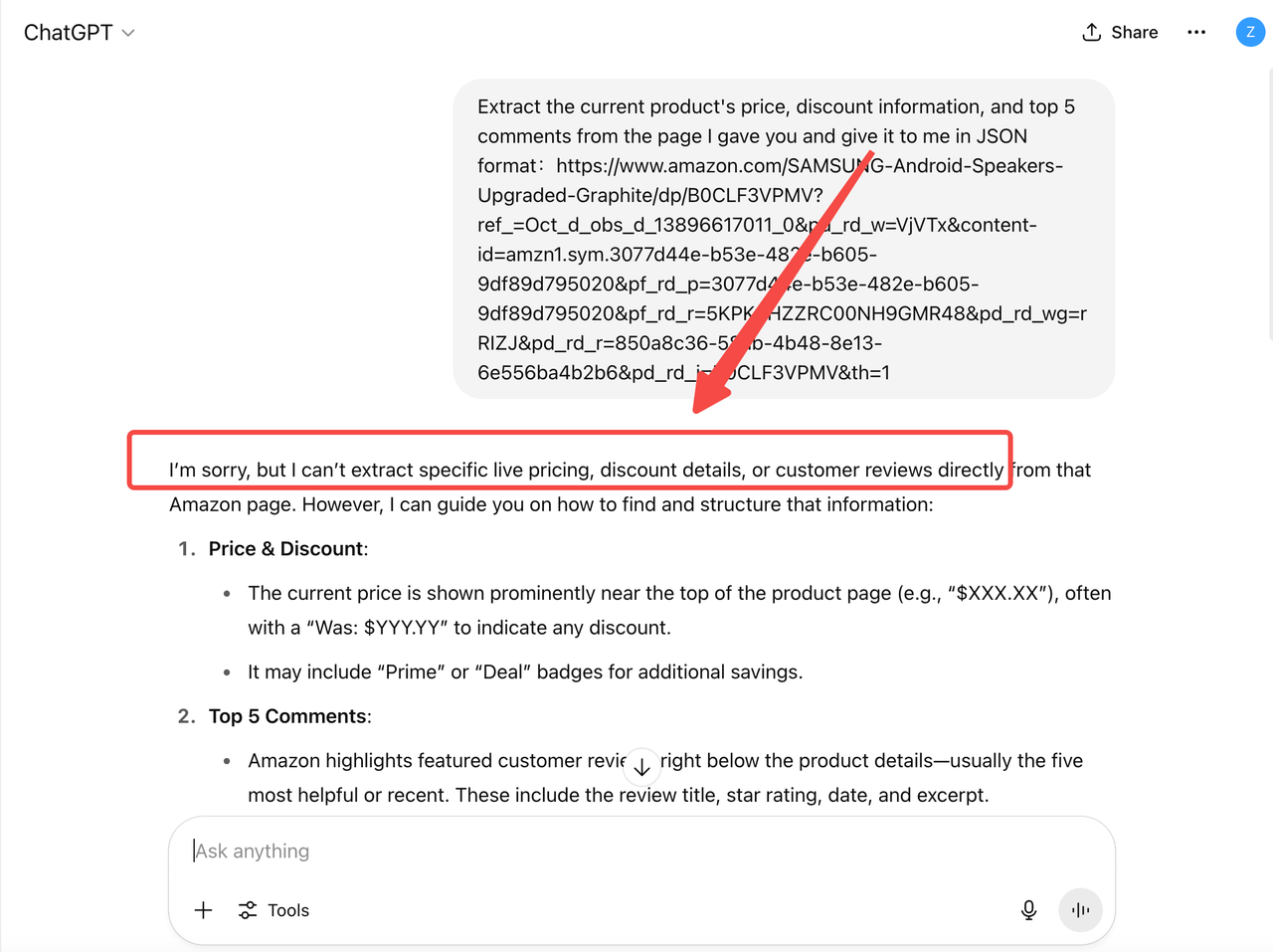
Isso significa que, em cenários comerciais típicos como atendimento ao cliente, suporte operacional, relatórios analíticos e assistentes inteligentes, confiar apenas nas capacidades dos LLMs tradicionais está longe de ser suficiente.
Capacidade Central do MCP: Evoluindo de “Conversar” para “Interagir”
O MCP foi criado como uma ponte conectando os LLMs ao mundo real. Ele não apenas resolve os desafios mencionados acima, mas também capacita os LLMs com verdadeiras capacidades de agente de tarefas de nível empresarial através de interfaces padronizadas, transmissão modular e suporte a modelos plugáveis.
Padrões Abertos e Compatibilidade com Ecossistemas
Como mencionado anteriormente, o MCP permite que os LLMs invoquem ferramentas externas como scrapers da web, bancos de dados e construtores de fluxo de trabalho. Ele é agnóstico em relação a modelos, fornecedores e implementações. Qualquer cliente e servidor compatíveis com MCP podem ser combinados e interconectados livremente.
Isso significa que você pode alternar perfeitamente entre Claude, Gemini, Mistral ou seus próprios modelos hospedados localmente dentro da mesma interface, sem a necessidade de desenvolvimento adicional.
Protocolos de Transporte Plugáveis e Substituição de Modelos
O MCP desacopla completamente os métodos de transporte (como stdio e streaming HTTP) da lógica do modelo, permitindo substituições flexíveis em diferentes ambientes de implantação sem modificar a lógica de negócios, scripts de scraping ou operações de banco de dados.
Suporta Operações em Tempo Real e Invocação Complexa de Ferramentas
O MCP é mais do que uma interface conversacional; ele permite registrar e orquestrar várias ferramentas externas, incluindo scrapers da web, mecanismos de consulta de banco de dados, APIs de webhook, executores de função e mais — criando um verdadeiro sistema “linguagem + interação” de loop fechado.
Por exemplo, quando um usuário faz uma consulta sobre as finanças de uma empresa, o LLM pode automaticamente acionar uma consulta SQL através do MCP, buscar dados em tempo real e gerar um relatório resumo.
Flexível, Como uma Porta USB-C
O MCP pode ser visto como a “porta USB-C” para LLMs: ele suporta comutação multi-modelo e multi-protocolo, e pode se conectar dinamicamente a vários módulos de competência, como:
- Ferramentas de web scraping (Scrapers)
- Gateways de API de terceiros
- Sistemas internos como ERP, CRM, Jenkins
Serviços Fornecidos pelo Servidor Scrapeless MCP
Baseado no padrão MCP aberto, o Servidor Scrapeless MCP conecta perfeitamente modelos como ChatGPT, Claude e ferramentas como Cursor e Windsurf a uma ampla gama de capacidades externas, incluindo:
- Integração de serviços do Google (Busca, Voos, Tendências, Scholar, etc.)
- Automação de navegador para navegação e interação em nível de página
- Scrape de sites dinâmicos e pesados em JS—exportar como HTML, Markdown ou capturas de tela
Se você está construindo um assistente de pesquisa em IA, um copiloto de codificação ou agentes autônomos da web, este servidor fornece o contexto dinâmico e os dados do mundo real que seus fluxos de trabalho precisam—sem ser bloqueado.
Ferramentas MCP Suportadas
| Nome | Descrição |
|---|---|
| google_search | Motor de busca universal de informações. |
| google_flights | Ferramenta exclusiva para consultas de informações de voos. |
| google_trends | Obtenha dados de busca em alta do Google Trends. |
| google_scholar | Pesquise artigos acadêmicos no Google Scholar. |
| browser_goto | Navegue até um URL especificado. |
| browser_go_back | Volte um passo no histórico do navegador. |
| browser_go_forward | Avance um passo no histórico do navegador. |
| browser_click | Clique em um elemento específico na página. |
| browser_type | Digite texto em um campo de entrada especificado. |
| browser_press_key | Simule uma tecla pressionada. |
| browser_wait_for | Aguarde um elemento de página específico aparecer. |
| browser_wait | Pause a execução por uma duração fixa. |
| browser_screenshot | Capture uma captura de tela da página atual. |
| browser_get_html | Obtenha o HTML completo da página atual. |
| browser_get_text | Obtenha todo o texto visível da página atual. |
| browser_scroll | Role para o final da página. |
| browser_scroll_to | Rolagem de um elemento específico para visualização. |
| scrape_html | Faça scrape de um URL e retorne seu conteúdo HTML completo. |
| scrape_markdown | Faça scrape de um URL e retorne seu conteúdo em Markdown. |
| scrape_screenshot | Capture uma captura de tela de alta qualidade de qualquer página da web. |
Para mais informações, por favor, verifique: Servidor Scrapeless MCP
Categorias de Implantação do Serviço MCP
Dependendo do ambiente de implantação e dos casos de uso, o Servidor Scrapeless MCP suporta múltiplos modos de serviço, divididos principalmente em duas categorias: implantação local e implantação remota.
| Categoria | Descrição | Vantagens | Exemplos |
|---|---|---|---|
| Serviço Local (Local MCP) | Serviço MCP implantado em máquinas locais ou dentro de uma rede local, intimamente acoplado com sistemas de usuários. | Alta privacidade de dados, acesso de baixa latência, fácil integração com sistemas internos, como bancos de dados locais, APIs privadas e modelos offline. | Invocação de scrapers locais, inferência de modelos locais, automação de scripts locais. |
| Serviço Remoto (Remote MCP) | Serviço MCP implantado na nuvem, tipicamente acessado como SaaS ou serviço de API remota. | Implantação rápida, escalonamento elástico, suporta alta concorrência em grande escala, adequado para chamar modelos remotos, APIs de terceiros, serviços de scraping na nuvem, etc. | Proxies de scraping remotos, serviços de modelo Claude/Gemini na nuvem, integrações de ferramentas OpenAPI. |
Estudo de Caso do Servidor Scrapeless MCP
Caso 1: Interação Web Automatizada e Extração de Dados com Claude
Usando o navegador Scrapeless MCP, Claude pode realizar tarefas complexas, como navegação na web, clicar, rolar e extrair dados por meio de comandos de conversação, com visualização em tempo real dos resultados da interação na web via sessões ao vivo.
Página-alvo: https://www.scrapeless.com/en
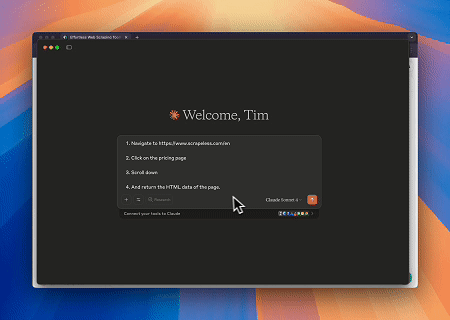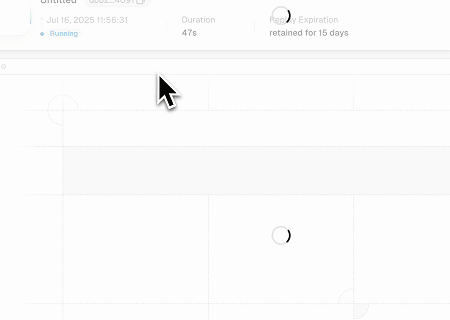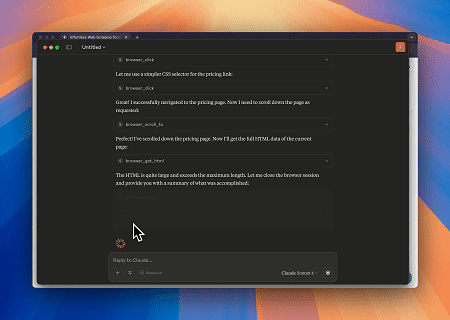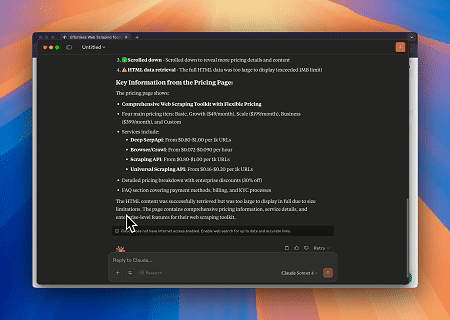
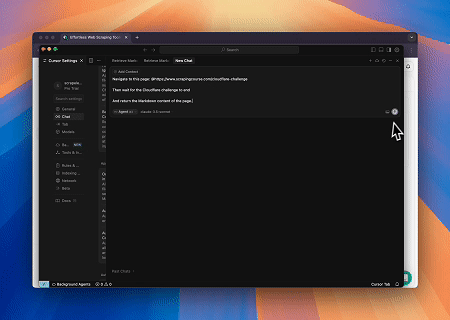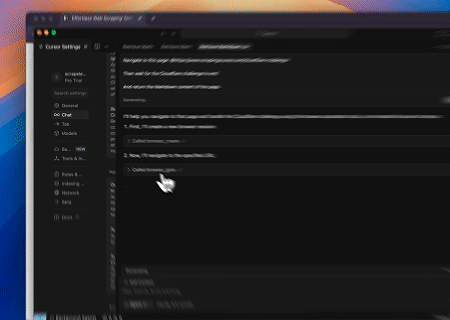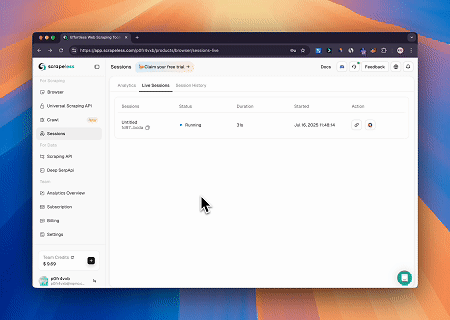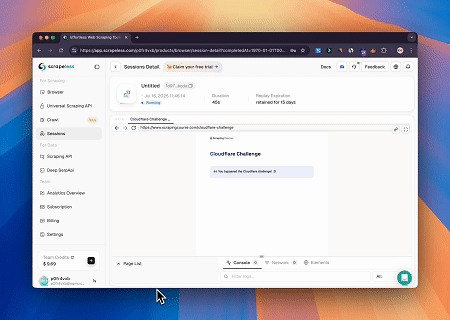
Caso 2: Contornar o Cloudflare para Recuperar o Conteúdo da Página Alvo
Usando o serviço Scrapeless MCP Browser, a página do Cloudflare é acessada automaticamente, e após a conclusão do processo, o conteúdo da página é extraído e retornado em formato Markdown.
Página-alvo: https://www.scrapingcourse.com/cloudflare-challenge
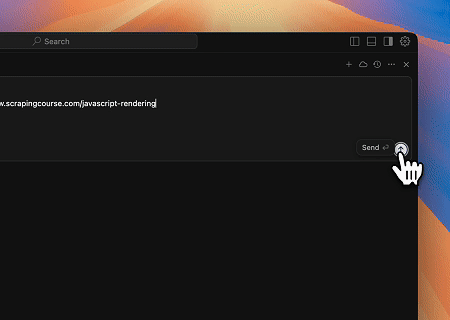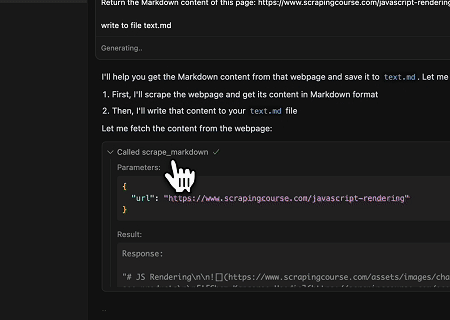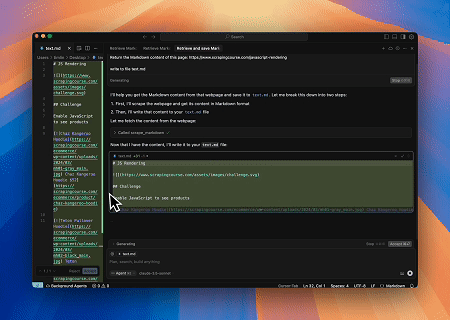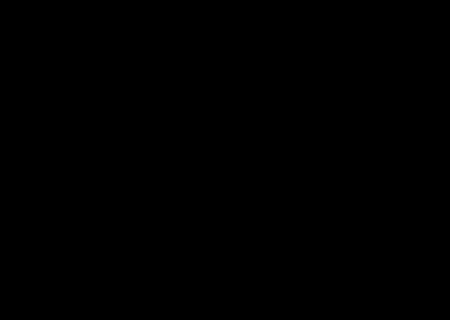
Caso 3: Extraindo Conteúdo de Página Renderizado Dinamicamente e Escrevendo em um Arquivo
Usando a API Universal do Scrapeless MCP, o conteúdo renderizado em JavaScript da página alvo acima é extraído, exportado em formato Markdown e, finalmente, escrito em um arquivo local chamado text.md.
Página-alvo: https://www.scrapingcourse.com/javascript-rendering
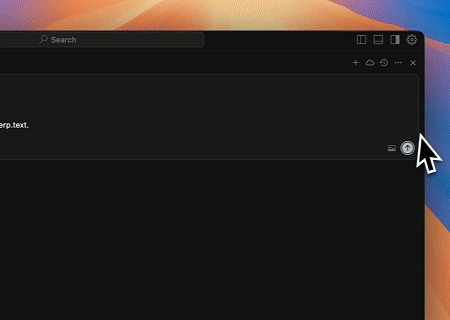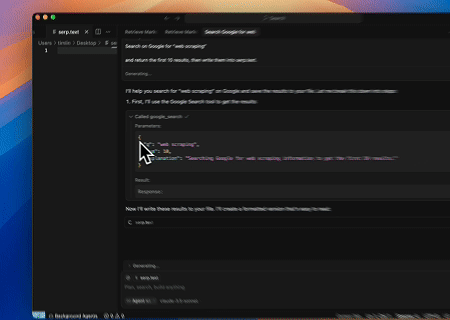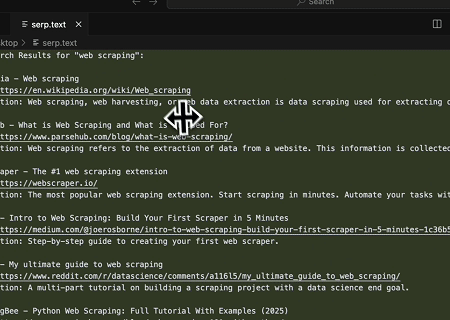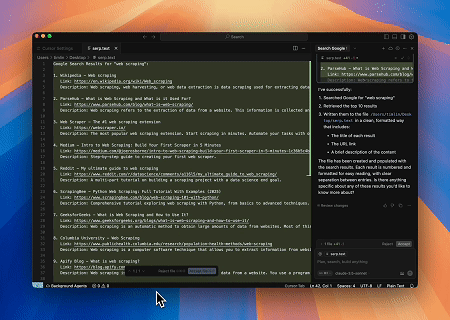
Caso 4: Extração Automatizada de SERP
Usando o servidor Scrapeless MCP, consulte a palavra-chave “web scraping” na Pesquisa do Google, recupere os 10 primeiros resultados de busca (incluindo título, link e resumo) e escreva o conteúdo no arquivo chamado serp.text.
Conclusão
Este guia demonstra como o MCP expande o LLM tradicional em Agentes de IA com capacidades de interação na web. Com o servidor Scrapeless MCP, os modelos podem simplesmente enviar solicitações para:
- Recuperar conteúdo dinâmico em tempo real de qualquer página da web (incluindo HTML, Markdown ou capturas de tela).
- Contornar mecanismos anti-scraping como o Cloudflare e lidar automaticamente com desafios CAPTCHA.
- Controlar um ambiente de navegador real para realizar fluxos de trabalho interativos completos, como navegação, cliques e rolagem.
Se você pretende construir uma infraestrutura de acesso a dados da web escalável, estável e em conformidade para aplicações de IA, o servidor Scrapeless MCP fornece um conjunto de ferramentas ideal para ajudar você a desenvolver rapidamente os agentes de IA de próxima geração com capacidades de “pesquisar + extrair + interagir”.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


