Loading...
🎯 Um navegador em nuvem personalizável e anti-detecção alimentado por Chromium desenvolvido internamente, projetado para rastreadores web e agentes de IA. 👉Experimente agora
Guia mais abrangente, criado para todos os desenvolvedores de raspagem na web.
A Scorresless oferece serviços de raspagem e automação da Web, movidos a IA, robustos e escaláveis, confiáveis pelas principais empresas. Nossas soluções de nível corporativo são adaptadas para atender às necessidades do seu projeto, com suporte técnico dedicado por toda parte. Com uma equipe técnica forte e prazos de entrega flexíveis, cobramos apenas dados bem -sucedidos, permitindo uma extração de dados eficientes enquanto ignora as limitações.
Entre em contato conosco agora para alimentar o crescimento dos seus negócios.
Forneça seus detalhes de contato e prontamente entraremos em contato para oferecer uma demonstração e introdução do produto. Garantimos que suas informações permaneçam confidenciais, cumprindo os padrões do GDPR.
Sua avaliação gratuita está pronta! Inscreva -se para uma conta sem descarga gratuitamente e seu teste será ativado instantaneamente em sua conta.
Aprenda a usar pacotes de stealth do Playwright em Python e Node.js para corrigir impressões digitais do navegador, gerenciar proxies e contornar a detecção de bots para raspagem da web.

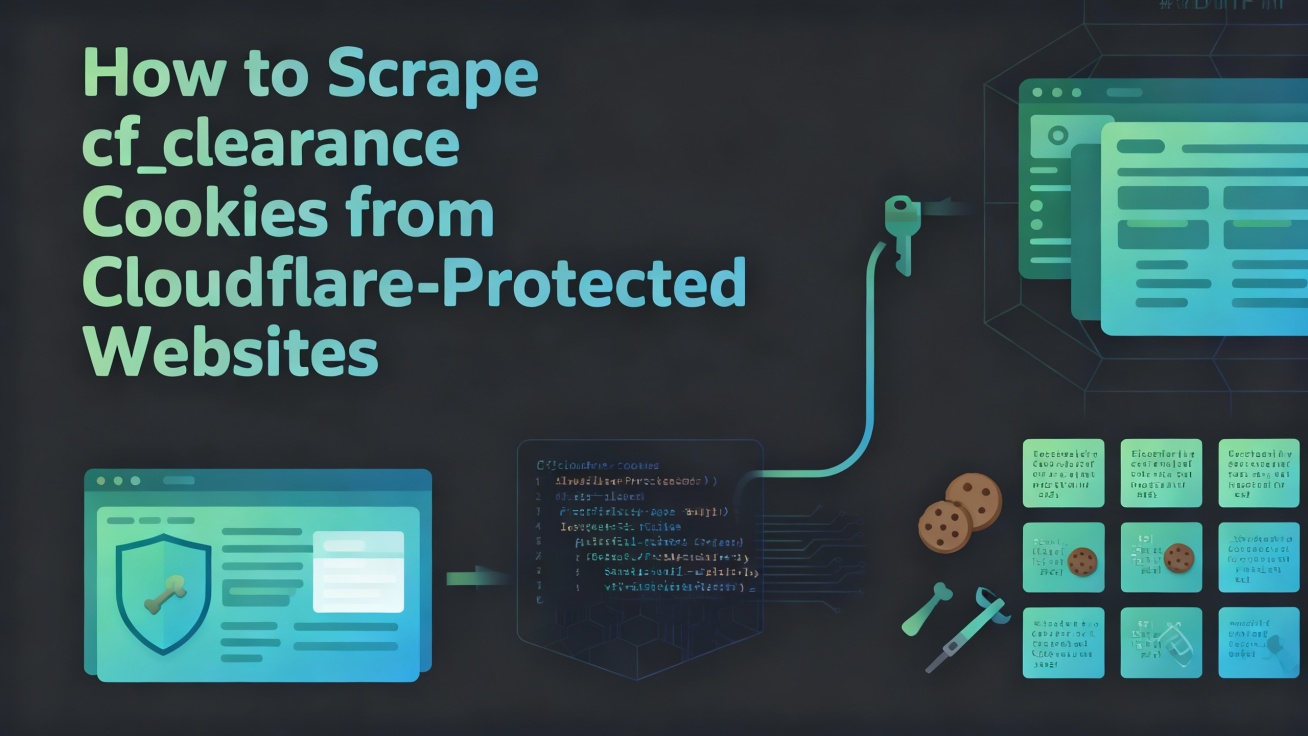
Aprenda como o cookie cf_clearance da Cloudflare funciona, seus níveis de liberação e como manter sessões de scraping persistentes sem a gestão manual de tokens.
C++ é um ótimo analisador e um cliente de raspagem incômodo. Deixe a libcurl buscar através de uma API de renderização e a libxml2 analisar — uma linha g++, 20 títulos analisados, verificados ao vivo.

Um crawler de notícias consiste em dois loops limpos: descobrir os links dos artigos e, em seguida, buscar e extrair cada história. Descoberta e busca de um artigo de 40 parágrafos verificados ao vivo.

Quatro tipos de paginação, quatro condições de parada. Siga os próprios controles de próximo/carregar mais do site em vez de adivinhar URLs — verificação do botão de próximo realizada em 10 páginas, 100 itens.

O Instagram renderiza a partir de suas próprias APIs JSON - então, chame-as diretamente de uma sessão aquecida com o cabeçalho x-ig-app-id. Extração de perfil verificada ao vivo.

O atributo src é o local menos confiável para encontrar uma imagem. Role para baixo primeiro, leia currentSrc, mantenha os metadados e busque bytes através da sessão — 20 imagens verificadas ao vivo.

A submissão de formulário confiável é preencher, enviar, esperar — e o envio/espera deve ser uma Promise.all. Login mais formulários de múltiplos campos verificados contra endpoints ao vivo.



