
Lazadaからデータをスクレイピングする方法 - 最適なLazadaスクレイピングAPI
Advanced Data Extraction Specialist
Lazadaからのデータスクレイピングは、製品トレンド、価格、市場競争に関する貴重な洞察を解き放ち、企業が情報に基づいた意思決定を可能にします。しかし、アンチスクレイピング対策、動的なウェブページ、IP制限などの課題により、このプロセスはしばしば困難になります。
これらのハードルに対処するために、最高のLazadaスクレイピングAPIを使用することが重要です。これらのAPIは、一般的な障害を回避し、データ抽出プロセスを簡素化するために設計されており、企業が必要とする構造化され正確なLazadaデータを効率的に収集できるようにします。
Lazadaはウェブスクレイピングを許可していますか?
Lazadaの利用規約では、ウェブスクレイピングを禁止していません。ただし、プラットフォームのポリシーを尊重することが重要です。ScrapelessのLazadaスクレイパーは、法的および倫理的な境界内で動作するように設計されており、関連するガイドラインへの準拠を確保するために、責任あるデータ抽出の実践を優先しています。
なぜLazadaからデータスクレイピングを行うのですか?
Lazadaからのデータスクレイピングは、eコマース事業に貴重な洞察を提供します。LazadaスクレイピングAPIを使用すると、次のような利点があります。
- 市場分析: トレンド、人気商品、価格戦略を追跡して競争力を維持します。
- 競合他社分析: 競合他社のリストと価格を監視して、独自の戦略を調整します。
- 在庫最適化: 在庫レベルと需要を把握して、在庫管理を改善します。
- マーケティング戦略: 売れ筋カテゴリーとキーワードに関するデータを使用して、キャンペーンを最適化します。
- 自動化: データ抽出を自動化して、正確性と効率性を高めます。
LazadaスクレイピングAPIを使用すると、データ収集が容易になり、競争優位性を獲得できます。
Lazadaからデータスクレイピングする方法 - 最高のLazadaスクレイピングAPI
強力なスクレイピングAPIを使用して、Lazadaの製品データをクロールできます。独自のコードをプログラミングするのと比較して、APIは時間と労力を節約し、必要なデータをより迅速にクロールできます。
LazadaスクレイピングAPIの概要:
- Scrapeless
- Outscraper
- Piloterr
- Setuserv
- Actowiz
1. ScrapelessスクレイピングAPI
Scrapelessは、正確で安全かつスケーラブルなデータ抽出を必要とする企業や開発者向けに設計された高度なウェブスクレイピングプラットフォームです。LazadaやAmazonなどのeコマースプラットフォームを含むさまざまなソースからのデータ収集のプロセスを簡素化する高度なソリューションを提供します。
その強力なインフラストラクチャにより、Scrapelessは独自のスクレイピングツールの構築と保守の必要性を排除し、CAPTCHA解決、アンチボットシステム、IPローテーションなどの複雑な課題を容易に処理します。製品の詳細、価格トレンド、カスタマーレビューを収集する場合でも、Scrapelessはデータニーズを満たす信頼性が高く効率的な方法を提供します。
主な機能:
- カスタマイズ可能: 製品カテゴリ、価格帯、地理的地域などのパラメーターを調整することで、スクレイピングニーズを調整できます。
- スケーラブル: 大量のデータを処理できるため、データ抽出ニーズの高い企業に最適です。
- プロキシサポート: 組み込みのプロキシローテーションにより、IP禁止のリスクなしで中断のないデータ収集を保証します。
- 高精度: 分析や自動化のためにビジネスオペレーションに簡単に統合できる、正確で構造化されたデータを提供します。
Scrapelessを使用してLazadaデータをスクレイピングする方法:
- ステップ1. Scrapelessにログインして、無料トライアルを取得します。
- ステップ2. 「スクレイピングAPI」をクリックします。
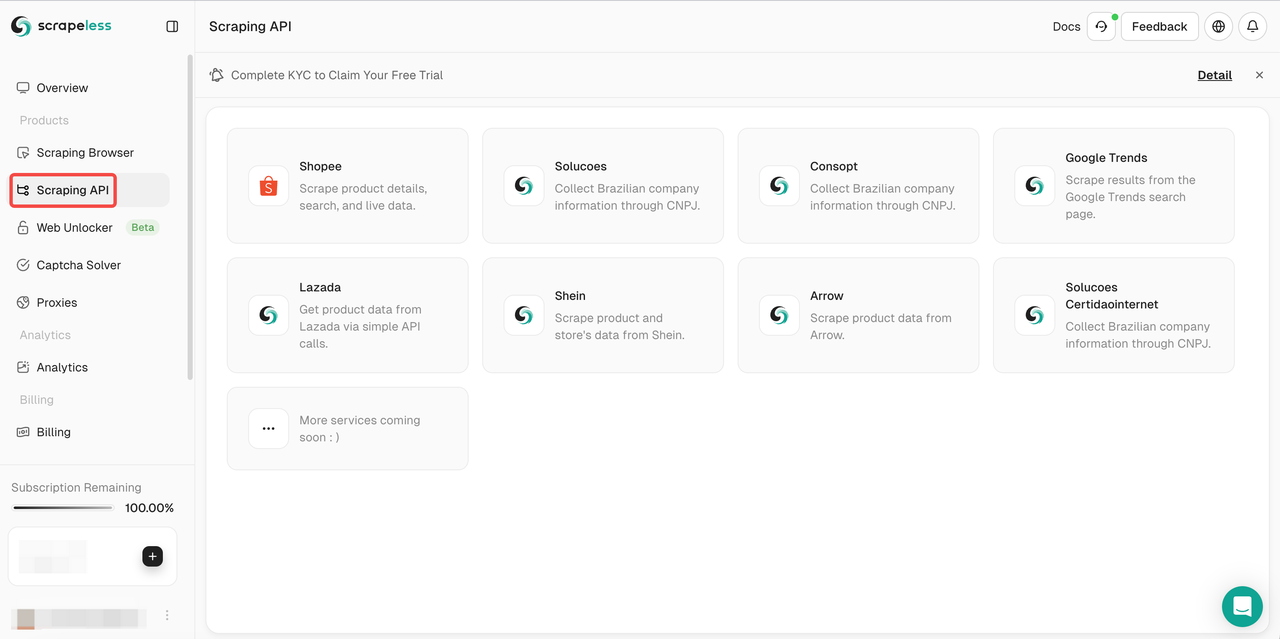
- ステップ3. Lazadaを選択し、Lazadaスクレイピングページを入力します。
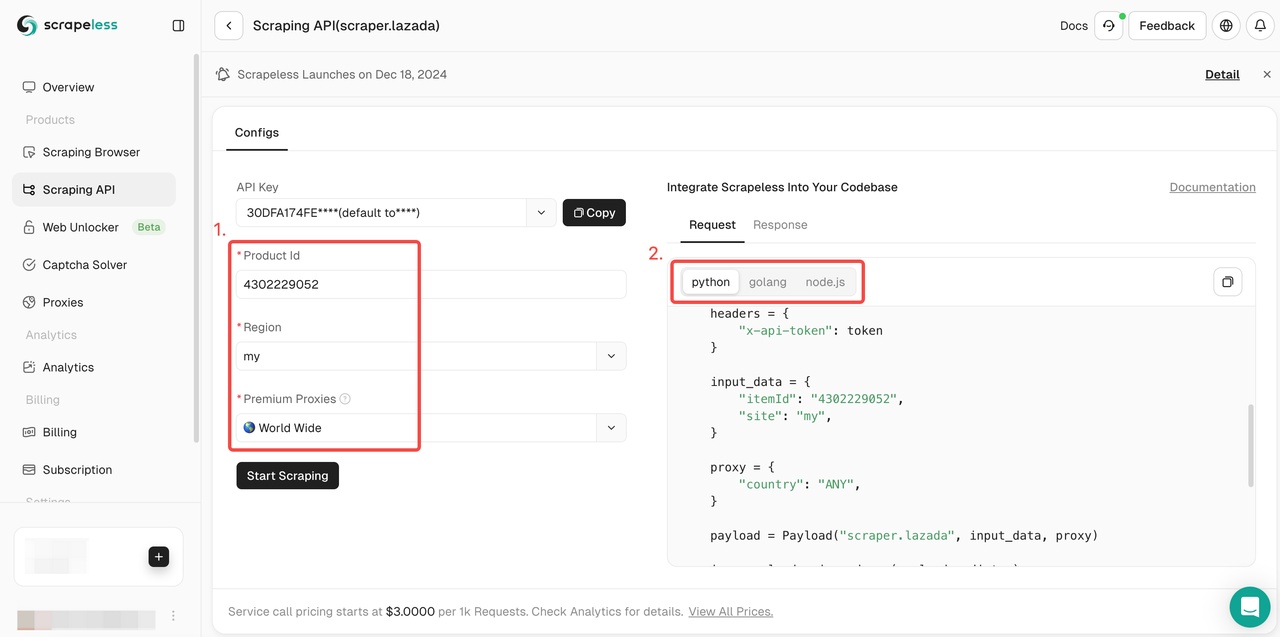
- ステップ4. アクションリストを引き下げて、クロールするデータ条件設定を選択します。次に、「スクレイピング開始」をクリックします。
- ステップ5. 数秒でクロールが成功します。対応する構造化データが右側に表示されます。
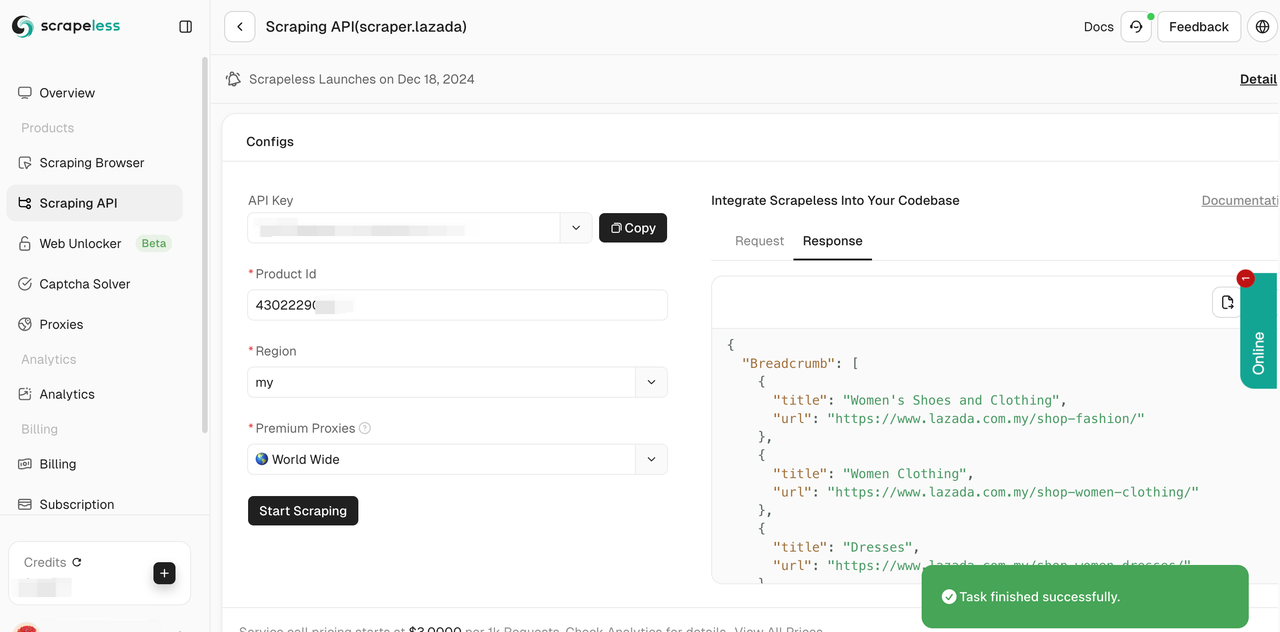
また、参照コードをプロジェクトに統合し、大規模なデータスクレイピングを展開することもできます。ここではPythonを例として使用します。クライアントではGolongとNodeJSも使用できます。
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #あなたのAPIトークン
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #製品IDを入力
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()2. Outscraper
Outscraperはマルチプラットフォームクロールをサポートする一般的なツールであり、Lazadaなどのeコマースプラットフォームでのデータ取得に適しています。そのAPIは簡潔で明確なインターフェースを提供し、ユーザーはクロール機能を迅速に呼び出すことができ、初心者やクロールタスクに高い要件を持たないユーザーに適しています。
しかし、このAPIでは2つの重要な欠点に反発しました。
- 不十分な検出能力
- 単一機能
3. Piloterr
Piloterrは大規模な同時実行と複雑なスクレイピングタスクを必要とするユーザーに適した、高性能と柔軟性に焦点を当てたスクレイピングツールです。Lazadaなどのeコマースプラットフォームからのデータ取得をサポートし、強力なカスタマイズ機能とAPIサポートを提供します。
注意すべき点:
- 高い技術的要件
- 高コスト
4. Setuserv
Setuservは、中小企業や個人開発者を対象とした手頃な価格のクロールツールです。基本的なデータ取得を必要とするユーザーに信頼性の高いクロールサービスを提供することに重点を置いています。他のハイエンドツールほど複雑ではありませんが、使いやすさと価格のメリットにより、エントリーレベルの選択肢となります。
- 機能が限定されている
- アンチクロール性能が弱い
5. Actowiz
Actowizは、長期的な安定したクロールを必要とする企業ユーザーに適した、包括的なデータクロールサービスを提供するソリューションです。そのクロール機能はLazadaプラットフォーム上のほとんどのコンテンツを網羅し、高度な分析機能を提供して、ユーザーがクロールされたデータを直接処理できるようにします。
- 高価格
- 一般的な柔軟性
まとめ
高性能で柔軟性の高いLazadaスクレイピングツールが必要な場合は、Scrapelessが間違いなく最適な選択肢です。その強力なアンチブロッキング機能と高同時実行サポートにより、複雑なシナリオでも優れたパフォーマンスを発揮します。
関連ブログ:
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


