
Crawl4AIをScrapeless Cloud Browserで強化する方法
Expert Network Defense Engineer
このチュートリアルでは、以下のことを学びます:
- Crawl4AIが何であるかと、ウェブスクレイピングのために何を提供するか
- Scrapeless BrowserとCrawl4AIを統合する方法
始めましょう!
第1部:Crawl4AIとは何ですか?
概要
Crawl4AIは、大規模な言語モデル(LLM)、AIエージェント、およびデータパイプラインとシームレスに統合するように設計されたオープンソースのウェブクローリングとスクレイピングツールです。これは、高速でリアルタイムのデータ抽出を可能にし、柔軟でデプロイが容易です。
AIによるウェブスクレイピングの主な機能は以下の通りです:
- LLMs向けに構築: Retrieval-Augmented Generation(RAG)とファインチューニングに最適化された構造化されたMarkdownを生成。
- 柔軟なブラウザ制御: セッション管理、プロキシ使用、およびカスタムフックをサポート。
- ヒューリスティックインテリジェンス: スマートアルゴリズムを使用してデータ解析を最適化。
- 完全なオープンソース: APIキー不要、Dockerやクラウドプラットフォームを通じてデプロイ可能。
詳細は公式ドキュメントを参照してください。
ユースケース
Crawl4AIは、市場調査、ニュース集約、eコマース製品収集などの大規模なデータ抽出タスクに最適です。動的でJavaScriptが多いウェブサイトを処理でき、AIエージェントや自動データパイプラインの信頼できるデータソースとして機能します。
第2部:Scrapeless Browserとは何ですか?
Scrapeless Browserは、クラウドベースのサーバーレスブラウザ自動化ツールです。これは深くカスタマイズされたChromiumカーネル上に構築されており、グローバルに分散したサーバーとプロキシネットワークによってサポートされています。これにより、ユーザーは多数のヘッドレスブラウザインスタンスをシームレスに実行および管理でき、スケールでウェブと対話するAIアプリケーションおよびAIエージェントの構築が容易になります。
第3部:なぜScrapelessとCrawl4AIを組み合わせるのか?
Crawl4AIは構造化されたウェブデータ抽出に優れており、LLM駆動の解析やパターンベースのスクレイピングをサポートしています。しかし、次のような高度なボット対策メカニズムに対処する際に課題に直面することがあります:
- Cloudflare、AWS WAF、またはreCAPTCHAによってローカルブラウザがブロックされる
- 大規模な同時クローリング中のパフォーマンスボトルネック、遅いブラウザ起動
- 問題追跡が難しい複雑なデバッグプロセス
Scrapeless Cloud Browserはこれらの痛点を完璧に解決します:
- ワンクリックのボット回避: 自動的にreCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAFなどに対処。Crawl4AIの構造化抽出-powerと組み合わせることで、成功率が大幅に向上します。
- 無制限の同時スケーリング: タスクごとに50~1000以上のブラウザインスタンスを数秒で起動し、ローカルクローリングのパフォーマンス制限を取り除き、Crawl4AIの効率を最大限にします。
- 40%~80%のコスト削減: 同様のクラウドサービスと比較して、総コストがわずか20%~60%に低下。従量課金制の価格設定により、小規模プロジェクトでも手頃です。
- 視覚デバッグツール: セッションリプレイやライブURLモニタリングを使用して、Crawl4AIタスクをリアルタイムで監視し、失敗原因を迅速に特定し、デバッグのオーバーヘッドを削減します。
- 無コスト統合: Playwright(Crawl4AIで使用)とネイティブに互換性があり、Crawl4AIをクラウドに接続するのに1行のコードだけが必要 — コードのリファクタリングは不要です。
- エッジノードサービス(ENS): 複数のグローバルノードが、他のクラウドブラウザの2~3倍の起動速度と安定性を提供し、Crawl4AIの実行を加速します。
- 隔離された環境と永続セッション: 各Scrapelessプロフィールは、永続的なログインおよびアイデンティティの分離を持つ独自の環境で実行され、セッションの干渉を防ぎ、大規模な安定性を向上させます。
- 柔軟なフィンガープリント管理: Scrapelessはランダムなブラウザフィンガープリントを生成したり、カスタム設定を使用したりして、検出リスクを効果的に低減し、Crawl4AIの成功率を改善します。
第4部:Crawl4AIでScrapelessを使用するには?
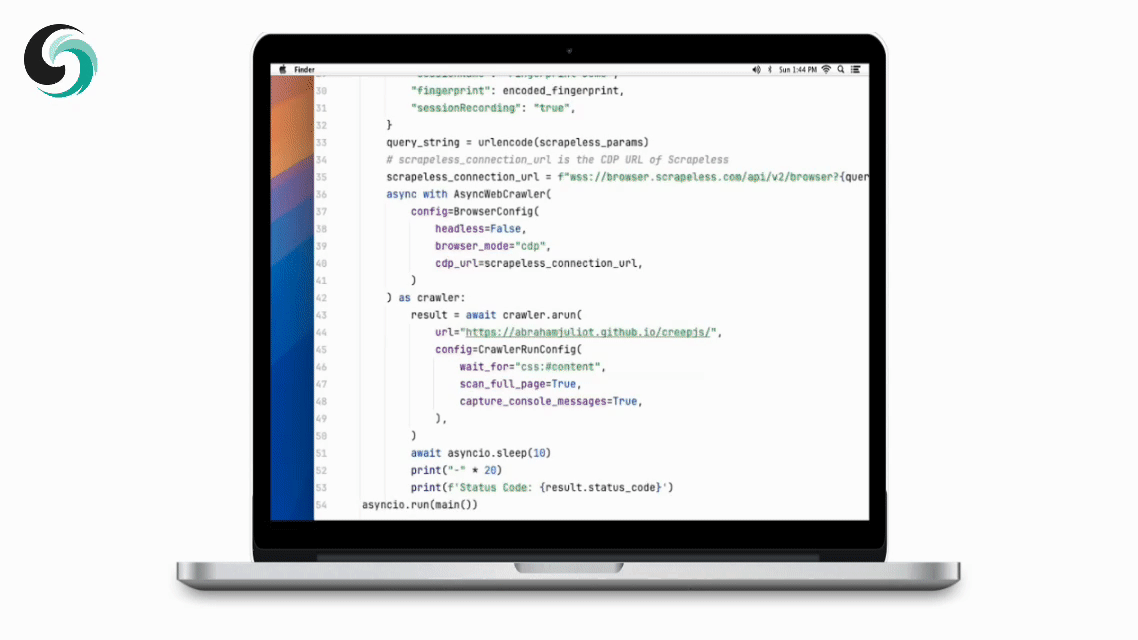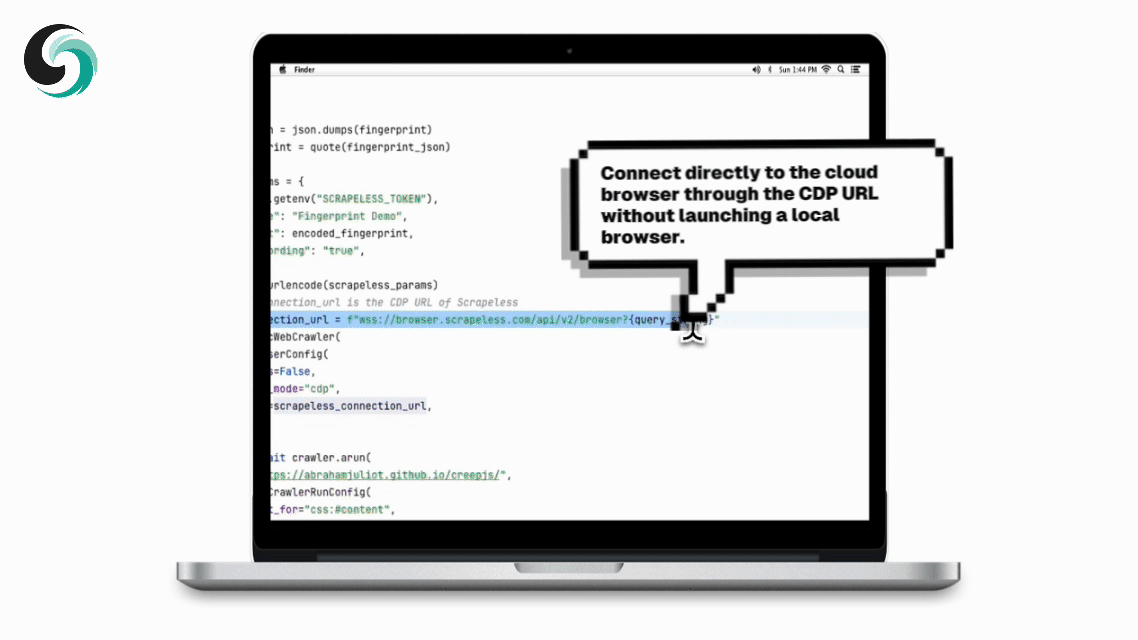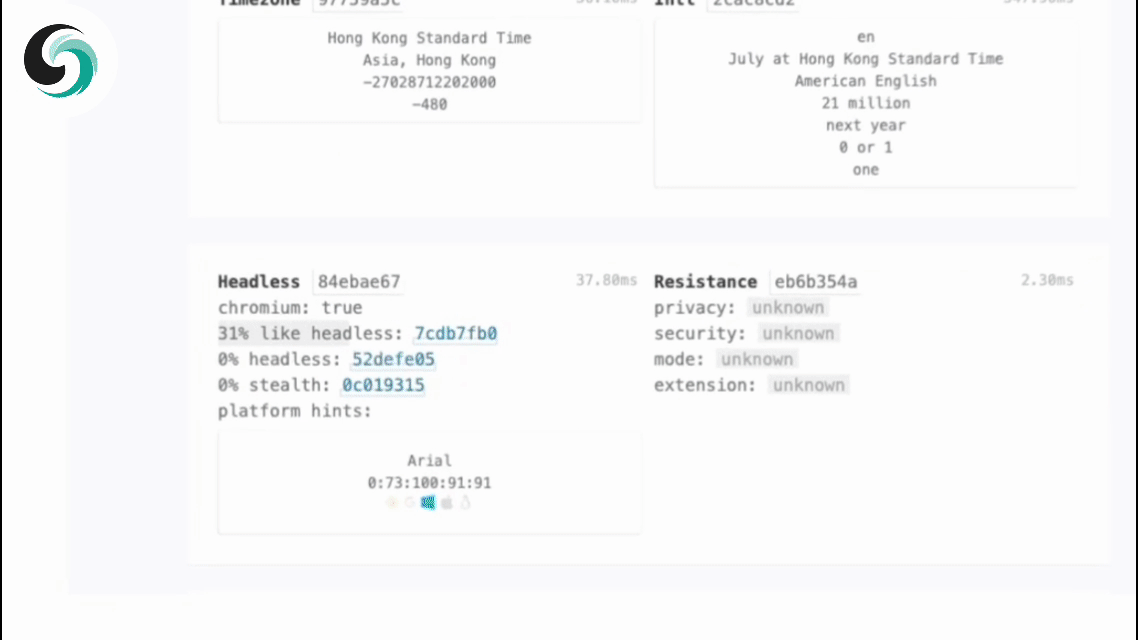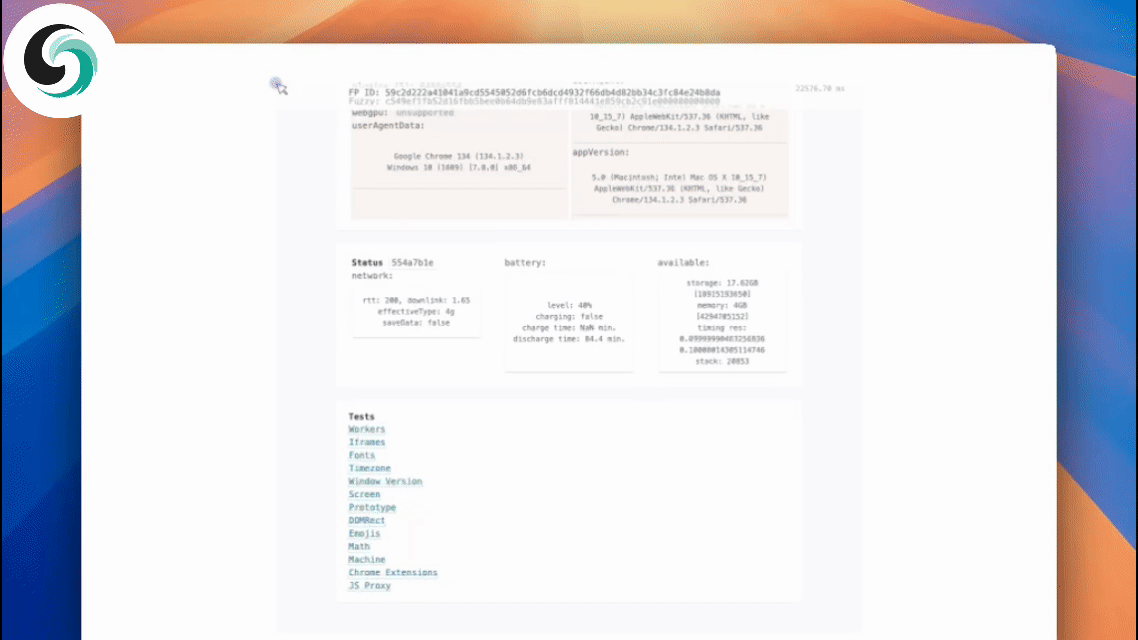
Scrapelessは通常CDP_URLを返すクラウドブラウザサービスを提供します。Crawl4AIは、このURLを使用してクラウドブラウザに直接接続でき、ローカルでブラウザを起動する必要がありません。
次の例では、Crawl4AIとScrapeless Cloud Browserをシームレスに統合して効率的なスクレイピングを行い、自動プロキシローテーション、カスタムフィンガープリント、およびプロフィール再利用をサポートしています。
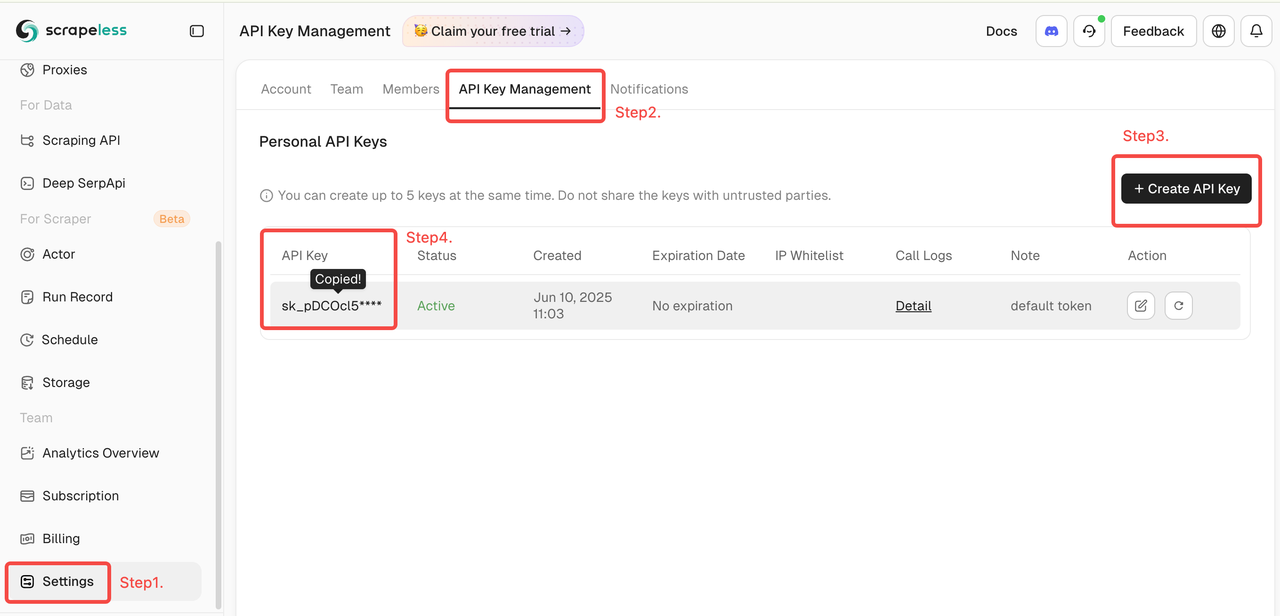
Scrapelessトークンを取得する
Scrapelessにログインして、APIトークンを取得してください。
1. クイックスタート
以下の例は、Crawl4AIをScrapeless Cloud Browserに迅速かつ簡単に接続する方法を示しています:
詳細な機能や手順については、紹介をご覧ください。
scrapeless_params = {
"token": "https://www.scrapeless.comからトークンを取得",
"sessionName": "Scrapelessブラウザ",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)設定後、Crawl4AIはCDP(Chrome DevTools Protocol)モードを通じてScrapeless Cloud Browserに接続し、ローカルブラウザ環境なしでウェブスクレイピングを可能にします。ユーザーはプロキシ、フィンガープリント、セッション再利用などの他の機能をさらに設定して、高い同時接続や複雑なボット対策のニーズを満たすことができます。
2. グローバル自動プロキシローテーション
Scrapelessは195か国の住宅IPをサポートしています。ユーザーはproxycountryを使用してターゲット地域を設定し、特定の場所からリクエストを送信できます。IPは自動的にローテーションされ、ブロックを回避します。
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "あなたのトークン",
"sessionTTL": 1000,
"sessionName": "プロキシデモ",
"proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'ステータスコード: {result.status_code}')
print("-" * 20)
print(f'タイトル: {result.metadata["title"]}')
print(f'説明: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())3. カスタムブラウザフィンガープリント
実際のユーザーの行動を模倣するために、Scrapelessはランダムに生成されたブラウザフィンガープリントをサポートし、カスタムフィンガープリンティングパラメータも許可します。これは、ターゲットウェブサイトに検出されるリスクを効果的に減少させます。
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# カスタマイズされたブラウザフィンガープリント
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "あなたのトークン",
"sessionTTL": 1000,
"sessionName": "フィンガープリントデモ",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'ステータスコード: {result.status_code}')
print("-" * 20)
print(f'タイトル: {result.metadata["title"]}')
print(f'説明: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())4. プロファイル再利用
Scrapelessは各プロファイルに独立したブラウザ環境を割り当て、永続的なログインとアイデンティティの分離を可能にします。ユーザーは単にprofileIdを提供することで、以前のセッションを再利用できます。
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "プロファイルデモ",
"profileId": "your profileId", # scrapelessでプロファイルを作成
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'ステータスコード: {result.status_code}')
print("-" * 20)
print(f'タイトル: {result.metadata["title"]}')
print(f'説明: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())ビデオ
よくある質問
Q: ブラウザ実行プロセスを記録して閲覧するにはどうすればよいですか?
A: 単にsessionRecordingパラメータを"true"に設定してください。ブラウザの実行全体が自動的に記録されます。セッションが終了した後、フルアクティビティをセッション履歴リストで再生および確認できます。デフォルト値は"false"です。
scrapeless_params = {
# ...
"sessionRecording": "true",
}Q: ランダムなフィンガープリンツを使用するにはどうすればよいですか?
A: Scrapelessブラウザサービスは、各セッションのためにランダムなブラウザフィンガープリンツを自動的に生成します。ユーザーはfingerprintフィールドを使用してカスタムフィンガープリンツを設定することもできます。
Q: カスタムプロキシを設定するにはどうすればよいですか?
A: 当社の組み込みプロキシネットワークは195か国/地域をサポートしています。ユーザーが独自のプロキシを使用したい場合は、proxyURLパラメータを使用してプロキシURLを指定できます。たとえば: http://user:pass@ip:port。
(注: カスタムプロキシ機能は現在、エンタープライズおよびエンタープライズプラスの加入者のみ利用可能です。)
scrapeless_params = {
# ...
"proxyURL": "proxyURL",
}概要
Scrapeless Cloud BrowserをCrawl4AIと組み合わせることで、開発者には安定したスケーラブルなウェブスクレイピング環境が提供されます:
- ローカルChromeインスタンスをインストールまたは維持する必要がなく、すべてのタスクがクラウドで直接実行されます。
- 各セッションは分離されており、ランダムまたはカスタムのフィンガープリンツをサポートするため、ブロックやCAPTCHAの中断のリスクが減少します。
- 自動セッション記録と再生のサポートにより、デバッグと再現性が向上します。
- 195か国/地域での自動プロキシローテーションをサポート。
- グローバルエッジノードサービスを活用し、他の類似サービスよりも起動速度が速いです。
このコラボレーションは、ウェブデータスクレイピング分野におけるScrapelessとCrawl4AIにとって重要なマイルストーンとなります。今後、Scrapelessはクラウドブラウザ技術に注力し、企業クライアントに効率的でスケーラブルなデータ抽出、オートメーション、およびAIエージェントインフラのサポートを提供します。強力なクラウド機能を活用して、Scrapelessは金融、小売、eコマース、SEO、マーケティングなどの業界向けにカスタマイズされたシナリオベースのソリューションを提供し、企業がデータインテリジェンスの時代に真の自動化された成長を達成する手助けをします。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


