
SHEINデータのスクレイピング方法|2025年最新の方法🔥
Senior Web Scraping Engineer
Redditでは、多くのユーザーがSheinのデータスクレイピング方法を活発に議論しており、ファッション小売情報を入手することに強い関心を示しています。しかし、Sheinデータのスクレイピングは容易ではなく、ユーザーはしばしば、反スクレイピング対策、IPブロック、動的コンテンツの読み込みといった課題に直面します。
これらの問題はデータ抽出を複雑にし、多くのユーザーが効果的な解決策とベストプラクティスを探しています。このガイドでは、SheinスクレイピングAPIを効率的に使用してSheinから最も重要なデータを抽出し、より良い意思決定を行い、競争優位性を獲得する方法を示します。
なぜSheinデータをスクレイピングするのか?
Sheinは主要なファッションeコマースプラットフォームであり、企業はデータ抽出から大きな恩恵を受け、競争力を維持できます。Sheinデータのスクレイピングにより、以下が可能になります。
- リアルタイムでの製品価格、在庫状況、割引の監視
- ファッショントレンドの分析、市場の先取り
- 競合他社の価格戦略とプロモーションオファーの追跡
- 詳細な顧客レビューと評価の抽出によるサービス向上
- 人気商品と新興のファッションカテゴリーに関するインサイトの獲得
その他必要なもの:
GoogleトレンドスクレイピングAPI
Shopee製品詳細のスクレイピング手順
Sheinスクレイピングとは?
Sheinスクレイピングとは、自動化ツールを使用してSheinのウェブサイトから製品データを取り出すことを指します。HTTPリクエストを送信してページにアクセスし、HTMLを解析して製品名、価格、説明などの関連情報を抽出し、そのデータを構造化された形式で保存します。
ウェブスクレイパーは、プロキシローテーションやユーザーエージェントマスキングなどの技術を使用して検出とレート制限を回避し、Sheinプラットフォームからの効率的でスケーラブルなデータ抽出を保証します。
Sheinのスクレイピングは合法か?
Sheinなどのウェブサイトから公開されているデータを収集する場合、ウェブスクレイピングは一般的に合法です。ただし、以下の点に注意する必要があります。
- サイトの利用規約と倫理ガイドラインに従うこと
- スクラピング活動がウェブサイトの通常の運用を妨げたり、サーバーに過負荷をかけたりしないようにすること
- 個人情報、機密情報、または専有情報には注意すること
Sheinデータのスクレイピング方法 [簡単&安全]
Sheinからの効率的で安全なデータスクレイピングには、Scrapeless SheinスクレイパーAPIの使用を強くお勧めします。このツールは、製品価格、説明、レビューなどの貴重な情報を抽出するプロセスを簡素化し、ウェブスクレイピングのベストプラクティスへの準拠を保証します。
主な機能:
- ユーザーフレンドリーなインターフェース:ノーコードインターフェースにより、広範なプログラミング知識がなくても、スクレイピングタスクを迅速に設定できます。
- 自動IPローテーション:この機能はIP禁止を回避し、複数のIPアドレス間をローテーションすることで途切れることのないデータ収集を保証します。
- CAPTCHA解決:APIには、CAPTCHAを自動的に処理する組み込みメカニズムが含まれており、手動による介入の必要性を減らします。
- データパース:生のHTMLを構造化されたデータ形式に効率的に変換し、スクレイピングされた情報の分析と統合を容易にします。
- 一括リクエスト処理:ユーザーは大量のスクレイピングタスクを効果的に管理し、サーバーの負荷を最小限に抑え、パフォーマンスを最適化できます。
- スケーラビリティ:APIはデータニーズに合わせて簡単にスケーリングするように設計されており、パフォーマンスを損なうことなく小規模なプロジェクトと大規模なプロジェクトの両方に対応できます。
- SheinスクレイピングAPIに加えて、ScrapelessはAmazonスクレイパーAPIやLazadaスクレイパーAPIなどの他の一般的なeコマースプラットフォームのAPIも提供しています。
Scrapeless SheinスクレイパーAPIを使用したデータのスクレイピング方法:
ステップ1: Scrapelessにログインをクリックします。 ID認証用の独自のAPIトークンを自動的に取得できます。
ステップ2: ログイン後、[スクレイピングAPI] > [Sheinを選択] > 以下のインターフェースを入力します。
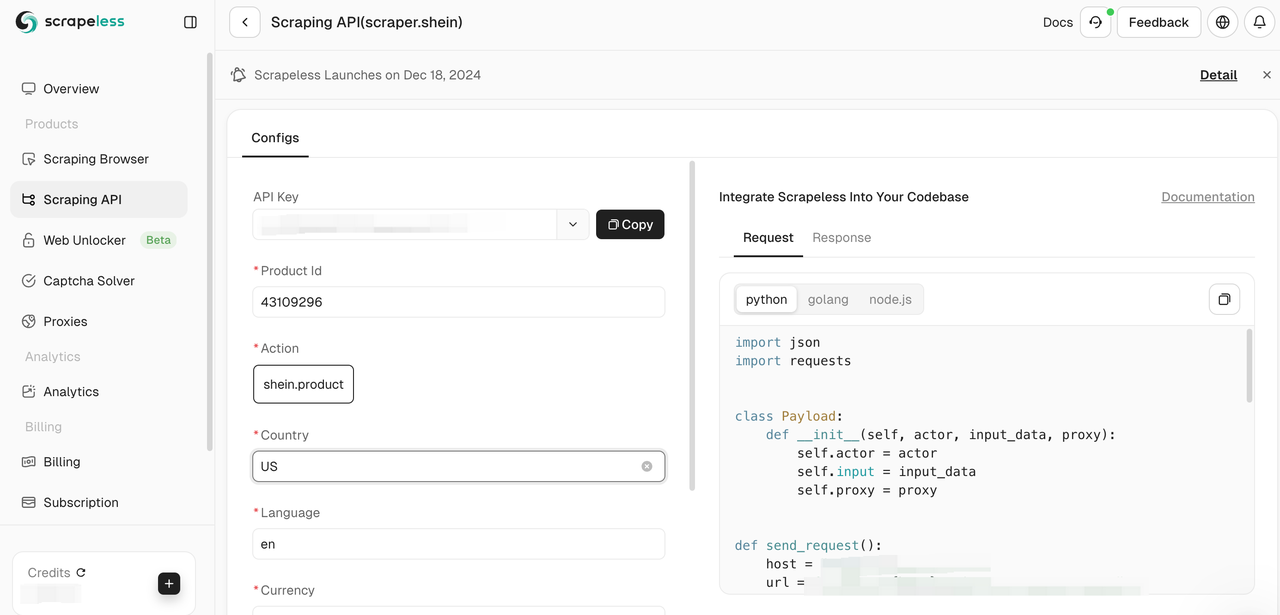
ステップ3: [スクレイピング開始]をクリックしてデータスクレイピングを開始します。 スクラピングの結果は右側に数秒で出力されます。
Scrapeless Sheinスクレイパーは無料トライアルを提供していますか?
はい、Scrapeless Sheinスクレイパーは無料トライアルを提供しています! ログインしてダッシュボードにアクセスし、今すぐ無料トライアルを請求してください!
まとめ
Scrapeless Sheinスクレイパーなどのツールを使用することで、ユーザーは製品の詳細、価格、顧客レビューなどの構造化されたデータを効果的に抽出し、情報に基づいた意思決定を行うことができます。データスクレイピングの取り組みを開始する際には、倫理基準を遵守することを忘れないでください。
今すぐScrapelessにログインして、数秒でSheinデータを入手しましょう!
Sheinスクレイパーに関するFAQ
1. Scrapeless Sheinスクレイパーのパフォーマンスは?
Scrapeless Sheinスクレイパーは優れたパフォーマンスを備えており、主に以下の点で表れています。
- 構造化されたデータの取得:スクレイピングされたデータは、JSONまたはHTML形式で出力され、後続の分析と使用に利用できます。
- 複数のプラットフォームのサポート:100以上の一般的なドメイン名とウェブサイトと互換性があり、幅広いデータスクレイピング機能を提供します。
- 高度なカスタマイズ性:特定のニーズに合わせて柔軟に設定でき、さまざまなデータ抽出要件を満たすことができます。
2. Scrapelessはマルチスレッド抽出をサポートしていますか?
はい、Scrapelessはマルチスレッド抽出をサポートしています。この機能は、複数のスレッドを同時に実行することでスクレイピング効率を高め、Sheinおよびその他のサポートされているプラットフォームからのデータ収集を高速化します。
3. Sheinウェブサイトの反クローラー対策に対処するにはどうすればよいですか?
- リクエスト頻度の削減:同じページへの頻繁なアクセスを避けるために、リクエスト間隔を設定します。
- リクエストデータパケットの偽装:User-Agentとリクエストヘッダーを変更して、クローラーを通常のブラウザーのように見せかけます。
- プロキシIPの使用:動的IPプロキシを使用して、同じIPからの頻繁なアクセスによってブロックされるのを防ぎます。
- 検証コードの処理:コーディングプラットフォームを使用して検証コードを識別するか、自動化ツールを使用して処理します。
- 動的ウェブページの解析:SeleniumやPuppeteerなどのツールを使用して、動的に読み込まれたコンテンツを取得します。
- さらに、Scrapeless Sheinスクレイパーを使用すると、これらの反クローラー対策を自動的に回避し、データクロールプロセスを簡素化し、効率を向上させることができます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


