
最強のLazadaデータスクレイピングAPI 2025 - 高性能&効果的
Expert Network Defense Engineer
Lazadaは東南アジアをリードするECプラットフォームの一つです。月間平均約1億5000万人のユーザーを抱え、インドネシア、マレーシア、シンガポール、ベトナム、タイ、フィリピンで事業を展開しています。プラットフォームでは、家電からファッションまで3億以上の商品を提供しています。Lazadaの商品データを調査することで、東南アジア市場を分析することができます。
この記事では、Lazadaの商品データをスクレイピングする方法を詳しく解説します。
必要なのは、スクレイピングしたいLazadaのURLをScrapeless APIに渡すだけです。
準備はよろしいでしょうか?
読み始めましょう!
なぜLazadaのデータをスクレイピングするのか?
- 市場情報と競合分析
Lazadaには、リアルタイムの価格と在庫情報を持つ何百万もの商品が掲載されています。Lazadaのデータをスクレイピングすることで、企業は競合の価格、プロモーション、商品の在庫状況、カスタマーレビューを追跡できます。この情報は、企業が自社の価格、プロモーション、在庫管理を調整するための戦略的決定を下すのに役立ちます。
- 商品調査とトレンド分析
Lazadaからデータ収集することで、企業は新たな商品トレンド、顧客の嗜好、季節的な需要パターンを監視できます。この情報は、商品開発の指針になったり、消費者の需要を満たすために販売者が提供する商品を最適化するのに役立ちます。
- 価格と在庫の監視
Lazadaの価格と在庫状況は、市場の需要、季節販売、競合他社の活動などによって頻繁に変動します。このデータをスクレイピングすることで、企業はこれらの変動を追跡し、価格戦略を調整し、競争力を維持するために動的な価格モデルを実装できます。
- SEOとデジタルマーケティング
タイトル、説明、カスタマーレビューなど、商品のデータは、ECサイト、PPCキャンペーン、SEO戦略を最適化するために不可欠です。Lazadaの商品リストを分析することで、企業は成功した商品リストで使用されている最も効果的なキーワードやフレーズを特定し、オンラインでの可視性を向上させることができます。
- 自動化されたデータ収集
Lazadaの商品データは常に変化しており、この情報を手動で収集するのは時間と効率の点で非効率です。Lazada Data Scraper APIを使用すると、プロセスを自動化でき、企業は手動による介入を大幅に減らしながら、継続的にデータを監視できます。
Lazadaのデータスクレイピングの課題
Lazadaからのデータスクレイピングは貴重な洞察を提供しますが、企業や開発者が克服しなければならないいくつかの課題があります。
- スクレイピング対策
多くのECプラットフォームと同様に、Lazadaはデータの不正なスクレイピングを防ぐために、スクレイピング対策技術を採用しています。これには、CAPTCHA、IPブロッキング、レート制限、スクレイピングが困難な動的なウェブコンテンツ(AJAX)の使用などが含まれます。これらの障害を克服するには、ローテーションプロキシ、ヘッドレスブラウザ、ユーザーエージェントマスキングなどの高度なツールと技術が必要です。
- データ構造の複雑さ
Lazadaのデータは、多くの場合、動的なウェブページに表示されるため、洗練されたスクレイピング技術なしでは抽出が困難です。データはウェブサイトの複数のレイヤーにまたがって配置されているため、スクレイパーは複雑なDOM構造をナビゲートし、関連情報を抽出する必要があります。信頼性の高いAPIは、分析しやすい形式で構造化されたデータを提供することにより、このプロセスを簡素化します。
- 法的およびコンプライアンスの問題
Lazadaを含む任意のウェブサイトからデータスクレイピングを行う場合は、プラットフォームの利用規約とプライバシーポリシーに準拠する必要があります。これらの規約に違反すると、サイトからブロックされたり、法的措置を講じられる可能性があります。プラットフォームのポリシーに従って、責任ある合法的な方法でデータスクレイピングを行うことが重要です。
- データ量とスケーラビリティ
Lazadaは複数のカテゴリにわたって数百万の商品を提供しており、これだけの量のデータをスクレイピングすると、インフラストラクチャに大きな負荷がかかります。大規模なデータ収集を効率的に処理できる、堅牢でスケーラブルなスクレイピングソリューションが必要です。
Lazadaはウェブスクレイピングを許可していますか?
Lazadaからデータスクレイピングを行う場合、Lazadaがウェブスクレイピングを許可しているかどうか、そしてそれが合法かどうか疑問に思うかもしれません。では、Lazadaはウェブスクレイピングを許可していますか?
一般的に、Lazadaの利用規約ではウェブスクレイピングを禁止していません。ウェブサイトのポリシーを尊重することが不可欠であるため、当社のLazadaスクレイパーは完全に合法であり、倫理的なデータ抽出を優先しています。
商品名、説明、ブランド、販売者、カテゴリ、画像、価格、状態レビュー、商品URL、配送情報など、Lazadaから公開されているすべてのデータをスクレイピングできます。このデータを使用して市場と人気商品を分析し、どの商品が購入者に人気があり、愛されているかを理解できます。販売者の場合、このデータを使用して同様の商品をストアに追加し、売上を増やすことができます。
そのため、Lazadaで販売している場合、またはLazadaで商品を販売する予定がある場合、ウェブサイトからデータを取得し、Lazadaのトレンドと人気商品を分析することで、販売者としての成功に確実に役立ちます。
優れたスクレイパーAPIは、私たちの作業負荷を大幅に削減し、作業効率を向上させることができます。スクレイパーAPIが良いかどうかを判断するにはどうすればよいでしょうか?最高のLazadaスクレイパーAPIはどれですか?
さあ、読み進めましょう!
Scrapeless - 最高のLazadaデータスクレイパーAPI
Scrapeless Lazada Scraping APIは、Lazadaからのデータ抽出プロセスを簡素化するために設計された革新的なソリューションです。
当社の高度なスクレイピングAPIを使用すると、複雑なスクレイピングスクリプトを作成または維持することなく、必要なデータにアクセスできます。シンプルなAPI呼び出しで、Lazadaの商品詳細データに瞬時にアクセスできます。
当社のLazada APIを呼び出す方法は?ガイドに従ってください。
- ステップ1。Scrapelessにログインします。
- ステップ2。「スクレイピングAPI」をクリックします。
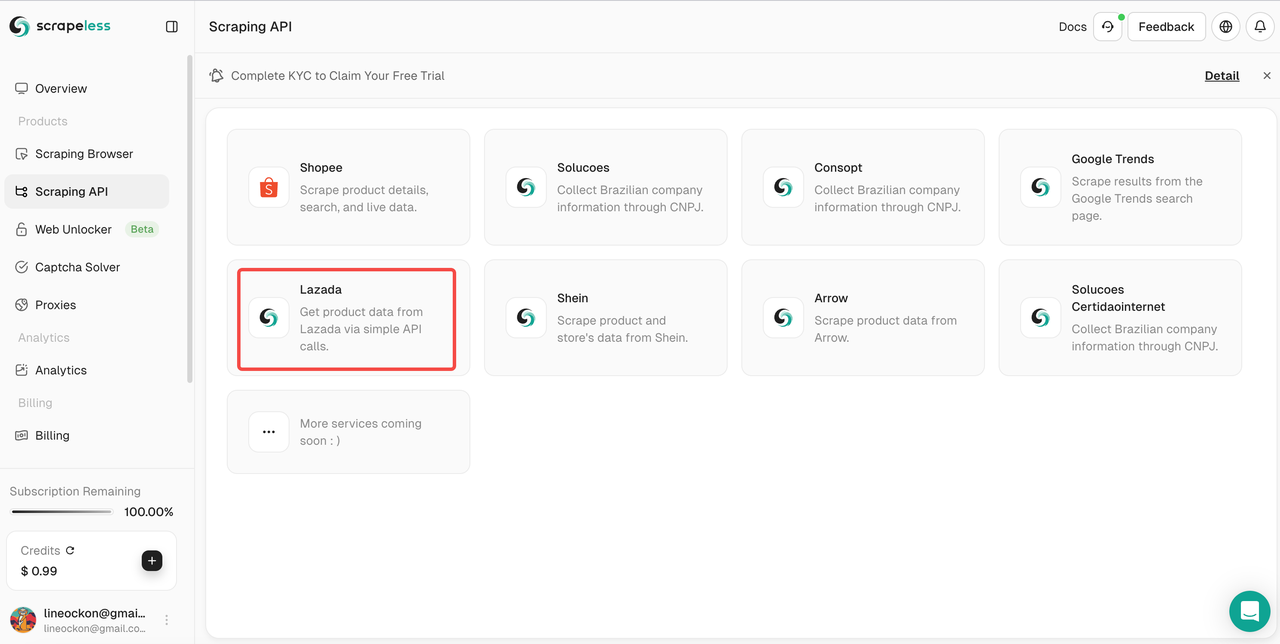
- ステップ3。「Lazada」APIを見つけ、入力します。
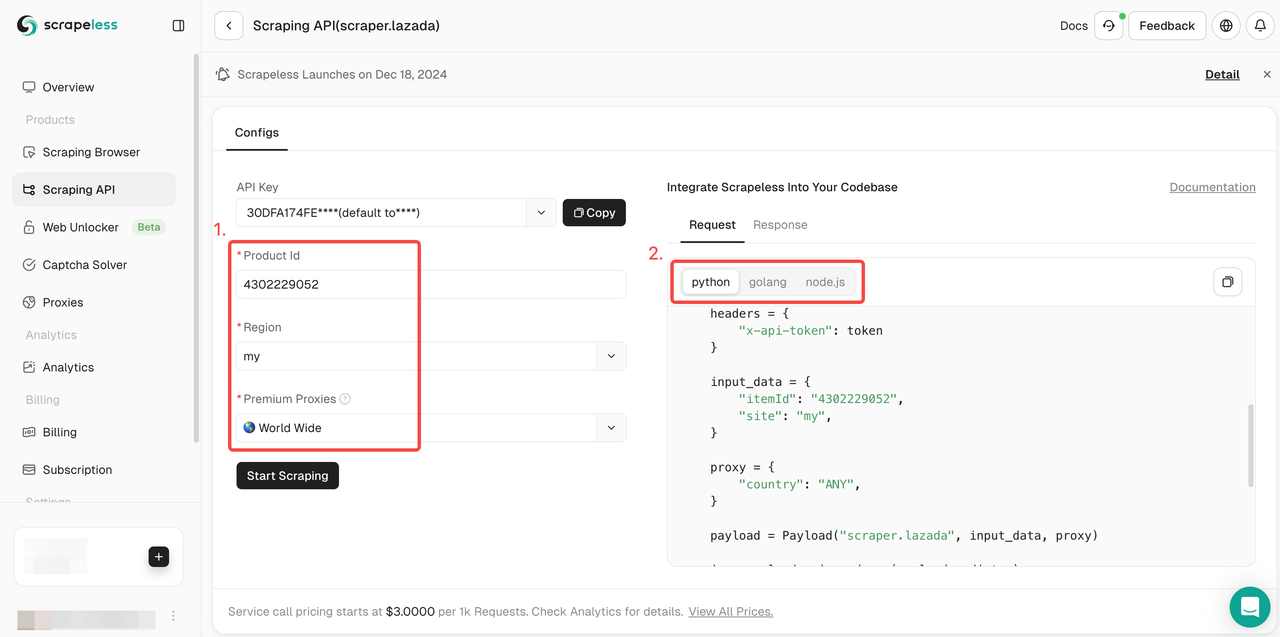
- ステップ4。左側の操作ボックスに、クロールしたい商品の完全な情報を入力します。次に、使用する式言語を選択します。
- ステップ5。「スクレイピング開始」をクリックすると、右側のプレビューボックスに商品のクロール結果が表示されます。
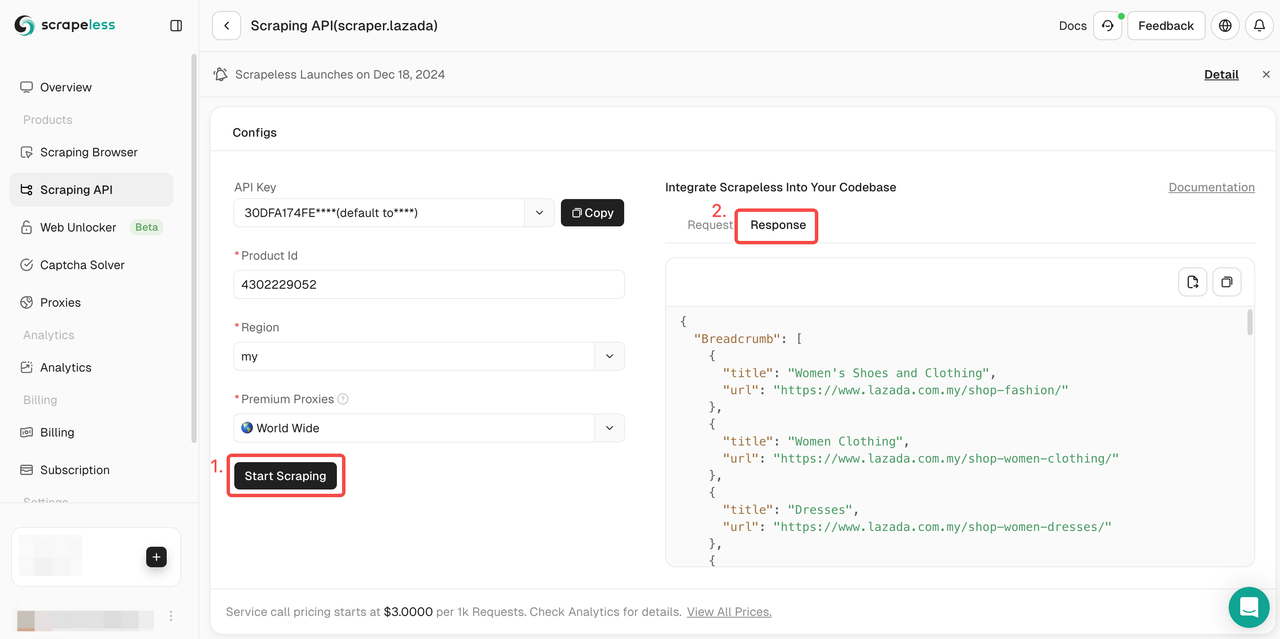
これで、右上隅にあるコピーボタンをクリックするだけで、すべての商品データを完全にコピーできます!
または、独自のプロジェクトにサンプルコードをデプロイすることもできます。
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #あなたのAPIトークン
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #商品IDを入力
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()- Golang:
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " #あなたのAPIトークン
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": " ", #商品IDを入力
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}- Node.JS:
JavaScript
const https = require('https');
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; //あなたのAPIトークン
const inputData = {
"itemId": " ", //商品IDを入力
"site": "my",
};
const proxy = {
country: "ANY",
}
const payload = new Payload("scraper.lazada", inputData, proxy);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();LazadaスクレイパーAPIを判断する方法
最高のLazada Data Scraper APIは、上記の多くの課題を克服し、企業に包括的で正確な商品データを提供する必要があります。
優れたLazadaデータスクレイパーAPIの特長を以下に示します。
- リアルタイムデータ抽出
- スクレイピング対策の回避
- データの解析と構造化
- カスタマイズ可能なフィルタリング
- スケーラビリティと速度
- ユーザーフレンドリーなインターフェースとドキュメント
最高のLazadaデータスクレイパーAPIのユースケース
- EC販売者
競合の価格と在庫を追跡し、独自のリストと価格戦略を調整します。価格チェックを自動化して、市場で競争力を維持します。
- 市場調査会社
商品情報、カスタマーレビュー、評価をスクレイピングして、消費者行動に関する洞察を得ることで、詳細な商品および市場トレンド分析を実施します。
- SEOおよびデジタルマーケティング代理店
上位のLazadaリストを分析することで、製品の説明、キーワード、タイトルを最適化し、検索ランキングを向上させます。
- アフィリエイトマーケター
商品データとレビュー、評価をスクレイピングし、分析することで、商品のパフォーマンスとアフィリエイトの機会を監視します。
まとめ
Lazadaのスクレイピングは、包括的で詳細な商品データコンテンツを提供し、タイムリーな市場情報を取得するのに役立ちます。Lazadaをクロールし、商品データを最も迅速かつ簡単な方法で抽出したい場合、Scrapeless Lazada Scraping APIが最適な選択肢です!複雑なコーディングプロセスなしで、APIインターフェースを呼び出すだけで済みます。
さらに、Scrapeless APIの価格は、多額の費用を心配することなく、すべての呼び出しニーズに対応できます。
こちらもおすすめ:
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


