
スクレイプレスMCPサーバーが公式に稼働開始!究極のAIウェブコネクターを構築しよう
Expert Network Defense Engineer
大規模言語モデル(LLM)はますます強力になっていますが、静的コンテンツの処理に限界があります。リアルタイムのウェブページを開くことや、JavaScriptでレンダリングされたコンテンツを処理すること、CAPTCHAを解くこと、ウェブサイトと対話することはできません。これらの制限は、AIの実際のアプリケーションや自動化の可能性を著しく制限します。
Scrapelessは、MCP(モデルコンテキストプロトコル)サービスを正式に立ち上げました。これは、LLMがライブウェブデータにアクセスし、インタラクティブなタスクを実行できる統一インターフェースです。この記事では、MCPとは何か、どのように展開できるのか、基本的な通信メカニズム、Scrapelessを使用してウェブを検索、ブラウジング、抽出、および対話する能力を持つAIエージェントを迅速に構築する方法について説明します。
Scrapeless MCP Server
MCPとは?
定義
モデルコンテキストプロトコル(MCP)は、JSON-RPC 2.0に基づいたオープンスタンダードです。これにより、大規模言語モデル(LLM)がウェブスクレイパーの実行、SQLデータベースへのクエリ、REST APIの呼び出しなど、外部ツールにアクセスできる統一されたインターフェースを提供します。
仕組み
MCPはレイヤーアーキテクチャに従っており、LLMと外部リソースとの間の相互作用において3つの役割を定義しています:
- クライアント:リクエストを送信し、MCPサーバーに接続します。
- サーバー:クライアントのリクエストを受信し、解析し、適切なリソース(データベース、スクレイパー、APIなど)にディスパッチします。
- リソース:要求されたタスクを実行し、結果をサーバーに返し、それをクライアントに再送信します。
この設計は効率的なタスクルーティングと厳格なアクセス制御を可能にし、特定のツールを使用できるのは認証されたクライアントのみであることを保証します。
通信メカニズム
MCPは、標準入力/出力(Stdio)を介したローカル通信と、HTTP + サーバー送信イベント(SSE)を介したリモート通信の2つの主要な通信タイプをサポートしています。どちらも統一されたJSON-RPC 2.0構造に従い、標準化されてスケーラブルな通信を可能にします。
- ローカル(Stdio):標準入力/出力ストリームを使用します。ローカル開発やクライアントとサーバーが同じマシンにいる場合に最適です。高速で軽量、デバッグやローカルワークフローに最適です。
- リモート(HTTP + SSE):リクエストはHTTP POST経由で送信され、リアルタイムの応答はSSEを介してストリーミングされます。このモードは永続的なセッション、再接続、およびメッセージの再生をサポートしており、クラウドベースや分散環境に適しています。
プロトコルの意味からトランスポートを切り離すことで、MCPは異なる環境に柔軟に適応でき、LLMの外部ツールとの相互作用能力を最大化します。
なぜMCPが必要なのか?
LLMはテキスト生成に優れていますが、リアルタイムの認識と相互作用に苦労しています。
LLMは静的データとツールへのアクセスの欠如によって制限されています
ほとんどのモデルはインターネットの歴史的スナップショットでトレーニングされているため、世界についてのリアルタイムの知識が欠けています。また、アーキテクチャやセキュリティの制約により、外部システムに積極的にアプローチすることもできません。
例えば、ChatGPTはAmazonから現在の製品データを直接取得することはできません。その結果、提供される価格や在庫情報は古くなっている可能性があり、リアルタイムでのプロモーション、推奨、在庫の変化を見逃してしまいます。
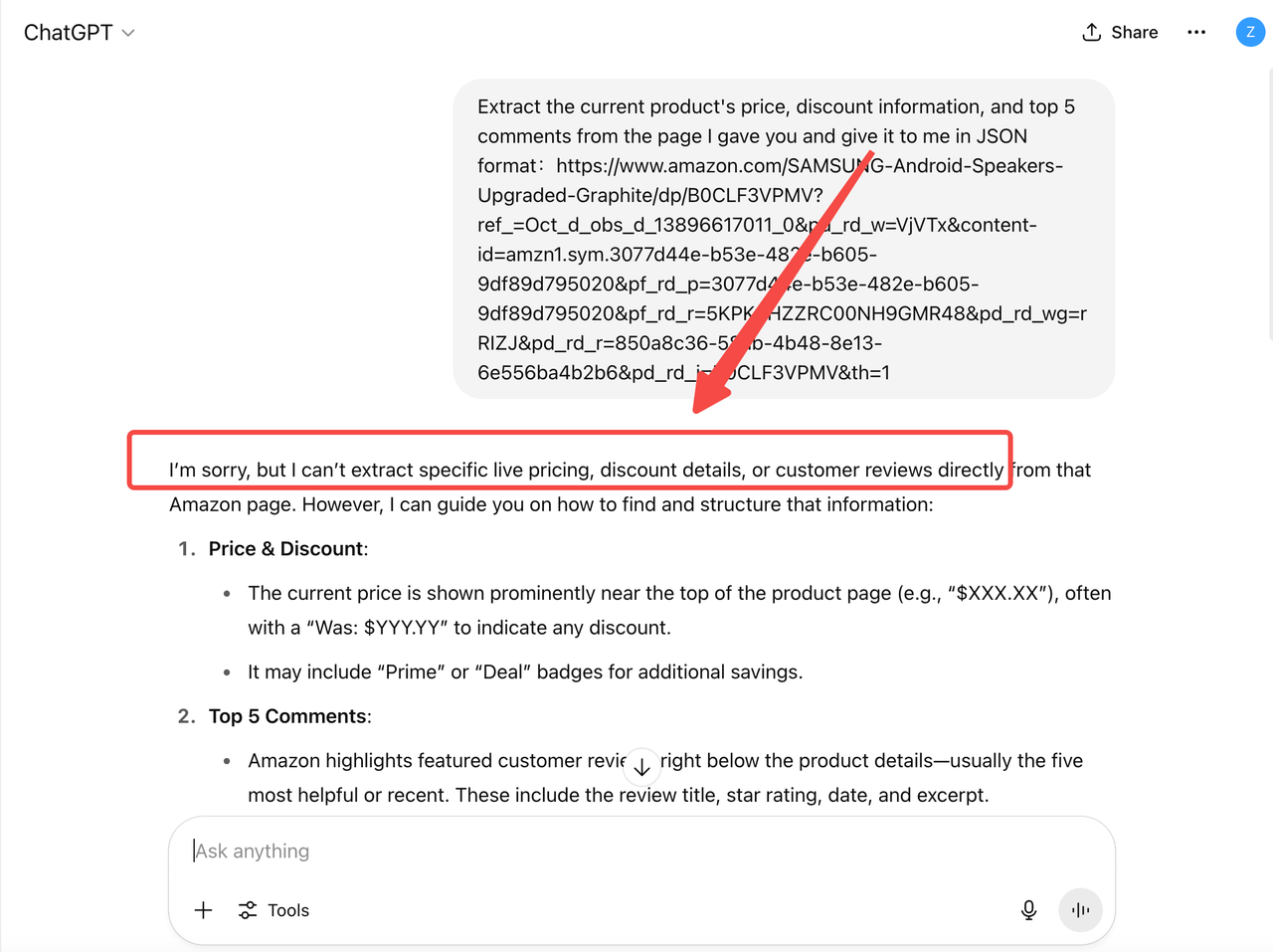
このため、カスタマーサービス、オペレーションサポート、分析レポート、インテリジェントアシスタントなどの典型的なビジネスシナリオにおいて、従来のLLMの能力にのみ依存するのは十分ではありません。
MCPのコア機能: 「チャット」から「インタラクション」へ進化
MCPは、LLMを現実世界に接続するブリッジとして作られました。上記の課題を解決するだけでなく、標準化されたインターフェース、モジュール伝送、プラグイン可能なモデルサポートを通じて、LLMに真のエンタープライズグレードのタスクエージェント機能を提供します。
オープンスタンダードとエコシステムの互換性
前述のように、MCPはLLMがウェブスクレイパー、データベース、ワークフロービルダーなどの外部ツールを呼び出すことを可能にします。これはモデル非依存、ベンダー非依存、展開非依存です。MCP準拠のクライアントとサーバーは自由に組み合わせて接続できます。
これにより、追加の開発なしに、同じUI内でClaude、Gemini、Mistral、または自分自身のローカルホストモデルの間でシームレスに切り替えることができます。
プラグイン可能なトランスポートプロトコルとモデルの置き換え
MCPは完全にトランスポート方法(例えば、stdioやHTTPストリーミング)をモデルロジックから切り離し、ビジネスロジック、スクレイピングスクリプト、データベース操作を変更することなく、異なる展開環境での柔軟な置き換えを可能にします。
リアルタイム操作と複雑なツールの呼び出しをサポート
MCPは単なる会話インターフェース以上のものであり、ウェブスクレイパー、データベースクエリエンジン、Webhook API、関数ランナーなど、さまざまな外部ツールを登録およびオーケストレーションすることを可能にします。これにより、真の「言語 + インタラクション」のクローズドループシステムが実現します。
例えば、ユーザーが企業の財務情報を問い合わせると、LLMは自動的にMCPを介してSQLクエリをトリガーし、リアルタイムデータを取得して要約レポートを生成できます。
柔軟性、USB-Cポートのように
MCPはLLMの「USB-Cポート」として見ることができます。これは、マルチモデルおよびマルチプロトコル切替をサポートし、以下のようなさまざまな機能モジュールに動的に接続できます:
- ウェブスクレイピングツール(Scrapers)
- サードパーティAPIゲートウェイ
- ERP、CRM、Jenkinsなどの内部システム
Scrapeless MCPサーバーが提供するサービス
オープンMCP標準に基づいて構築されたScrapeless MCPサーバーは、ChatGPT、Claudeのようなモデルや、CursorやWindsurfのようなツールをさまざまな外部機能にシームレスに接続します。これには以下が含まれます:
- Googleサービス統合(検索、フライト、トレンド、学術、等)
- ページレベルのナビゲーションとインタラクションのためのブラウザ自動化
- 動的でJSが重いサイトのスクレイピング—HTML、Markdown、またはスクリーンショットとしてエクスポート
AIリサーチアシスタント、コーディングコパイロット、または自律的なウェブエージェントを構築する場合でも、このサーバーはあなたのワークフローに必要な動的コンテキストと実世界のデータを提供します—ブロックされることなく。
サポートされているMCPツール
| 名称 | 説明 |
|---|---|
| google_search | 汎用情報検索エンジン。 |
| google_flights | 限定フライト情報クエリツール。 |
| google_trends | Googleトレンドからトレンド検索データを取得。 |
| google_scholar | Google Scholarで学術論文を検索。 |
| browser_goto | 指定されたURLにブラウザをナビゲート。 |
| browser_go_back | ブラウザ履歴で一つ前に戻る。 |
| browser_go_forward | ブラウザ履歴で一つ進む。 |
| browser_click | ページ上の特定の要素をクリック。 |
| browser_type | 指定された入力フィールドにテキストを入力。 |
| browser_press_key | キー押下をシミュレート。 |
| browser_wait_for | 特定のページ要素が表示されるまで待つ。 |
| browser_wait | 固定の時間だけ実行を一時停止。 |
| browser_screenshot | 現在のページのスクリーンショットをキャプチャ。 |
| browser_get_html | 現在のページの全HTMLを取得。 |
| browser_get_text | 現在のページからすべての可視テキストを取得。 |
| browser_scroll | ページの下部までスクロール。 |
| browser_scroll_to | 特定の要素を表示するようにスクロール。 |
| scrape_html | URLをスクレイピングし、その全HTMLコンテンツを返す。 |
| scrape_markdown | URLをスクレイピングし、その内容をMarkdownとして返す。 |
| scrape_screenshot | 任意のウェブページの高品質なスクリーンショットをキャプチャ。 |
詳細については、次を確認してください: Scrapeless MCP Server
MCPサービスの展開カテゴリー
展開環境および使用ケースによって、Scrapeless MCPサーバーは複数のサービスモードをサポートし、主にローカル展開とリモート展開の2つのカテゴリに分かれます。
| カテゴリ | 説明 | 利点 | 例 |
|---|---|---|---|
| ローカルサービス (ローカルMCP) | ローカルマシンまたはローカルネットワーク内に展開されたMCPサービスで、ユーザーシステムと密接に結びついています。 | 高いデータプライバシー、低遅延アクセス、ローカルデータベース、プライベートAPI、オフラインモデルなど内部システムとの統合が容易。 | ローカルスクレイパーの呼び出し、ローカルモデル推論、ローカルスクリプト自動化。 |
| リモートサービス (リモートMCP) | クラウドに展開されたMCPサービスで、通常はSaaSまたはリモートAPIサービスとしてアクセスされます。 | 高速な展開、弾力的スケーリング、大規模同時処理をサポート、リモートモデル、サードパーティAPI、クラウドスクレイピングサービス呼び出しに適しています。 | リモートスクレイピングプロキシ、クラウドClaude/Geminiモデルサービス、OpenAPIツール統合。 |
Scrapeless MCPサーバーケーススタディ
ケース1: Claudeによる自動ウェブインタラクションとデータ抽出
スクレイプレスMCPブラウザを使用することで、クロードはウェブナビゲーション、クリック、スクロール、データ抽出などの複雑なタスクを会話形式のコマンドで実行し、ライブセッションを介してウェブインタラクションの結果をリアルタイムでプレビューできます。
対象ページ: https://www.scrapeless.com/en
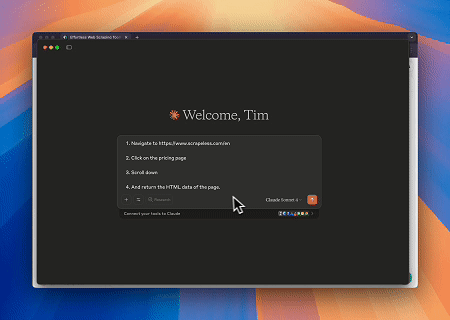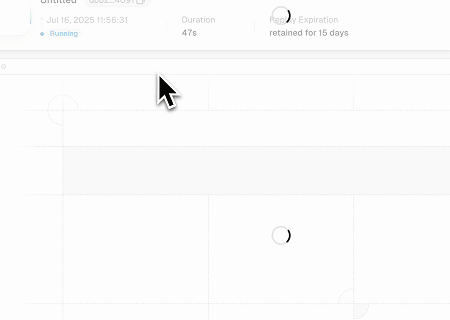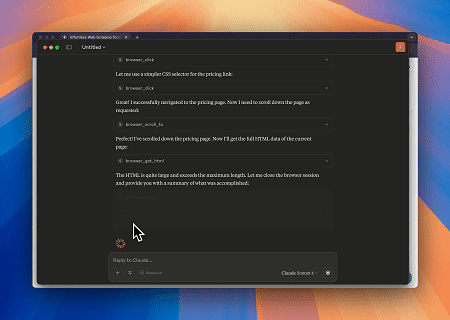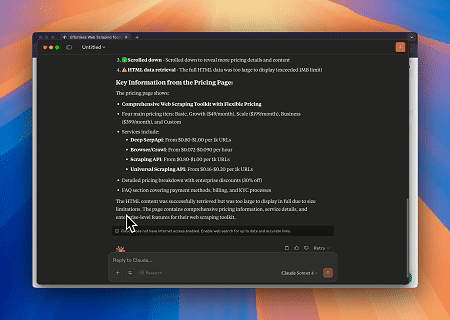
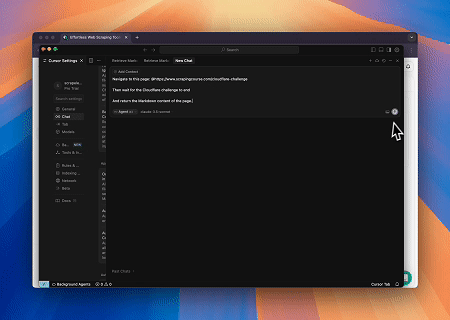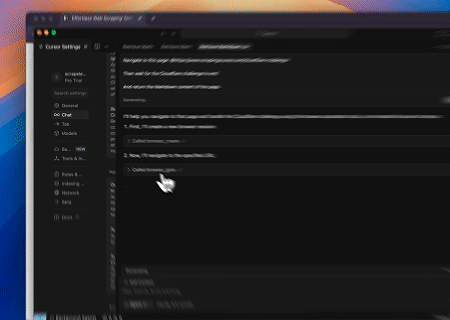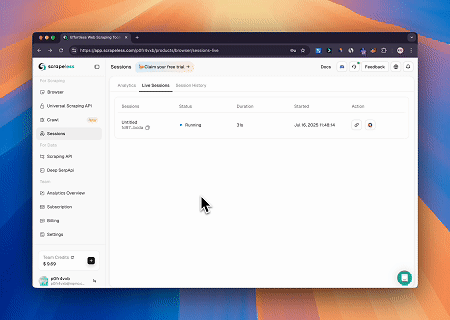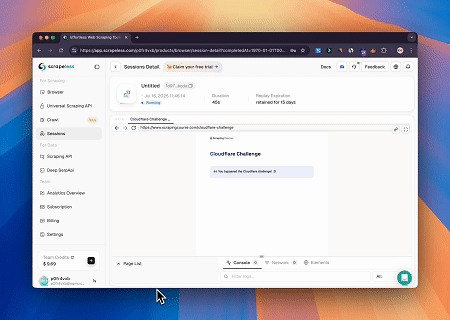
ケース2: Cloudflareを回避してターゲットページのコンテンツを取得
スクレイプレスMCPブラウザサービスを使用して、Cloudflareページに自動的にアクセスし、プロセスが完了するとページコンテンツが抽出され、Markdown形式で返されます。
対象ページ: https://www.scrapingcourse.com/cloudflare-challenge
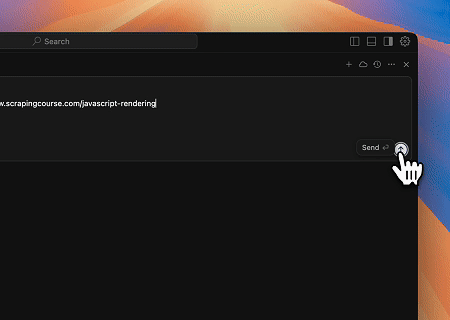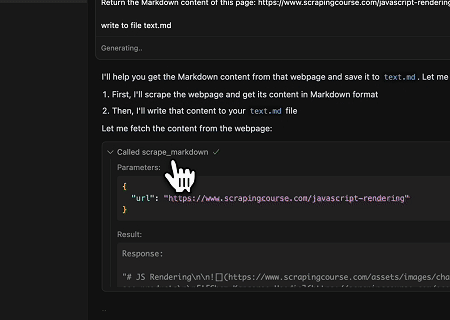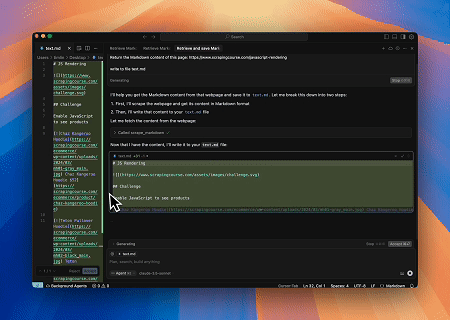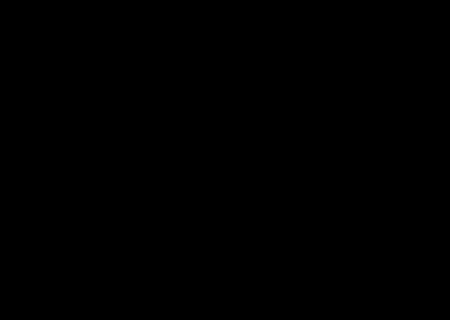
ケース3: 動的にレンダリングされたページコンテンツの抽出とファイルへの書き込み
スクレイプレスMCPユニバーサルAPIを使用して、上記のターゲットページのJavaScriptレンダリングされたコンテンツを抽出し、Markdown形式でエクスポートし、最終的に**text.md**という名前のローカルファイルに書き込みます。
対象ページ: https://www.scrapingcourse.com/javascript-rendering
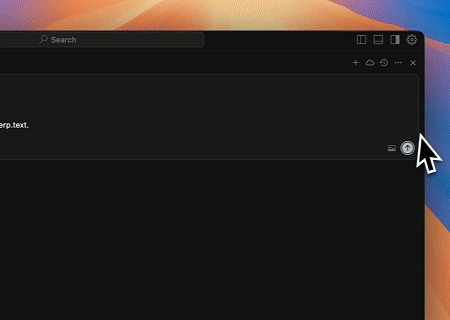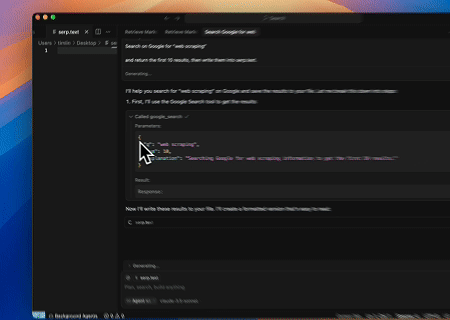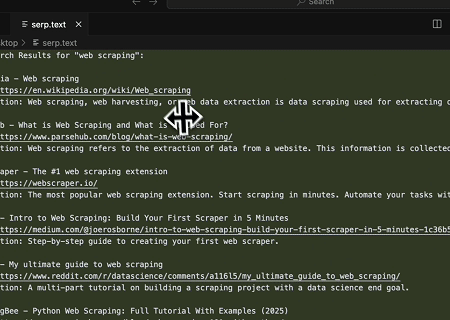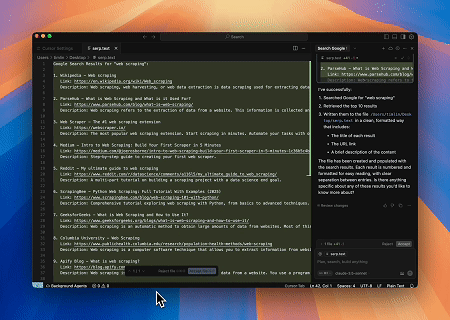
ケース4: 自動化されたSERPスクレイピング
スクレイプレスMCPサーバーを使用して、Google検索で「ウェブスクレイピング」というキーワードを検索し、最初の10件の検索結果(タイトル、リンク、要約を含む)を取得して、serp.textという名前のファイルに書き込みます。
結論
このガイドでは、MCPが従来のLLMをウェブインタラクション機能を持つAIエージェントに拡張する方法を示しています。スクレイプレスMCPサーバーを使用することで、モデルは単純にリクエストを送信できます:
- 任意のウェブページからリアルタイムで動的にレンダリングされたコンテンツ(HTML、Markdown、またはスクリーンショットを含む)を取得する。
- Cloudflareなどの反スクレイピング機構を回避し、自動的にCAPTCHAチャレンジを処理する。
- 実際のブラウザ環境を制御して、ナビゲーション、クリック、スクロールなどの完全なインタラクティブワークフローを実行する。
AIアプリケーション向けにスケーラブルで安定したコンプライアンスのあるウェブデータアクセスインフラを構築することを目指す場合、スクレイプレスMCPサーバーは、次世代の「検索 + スクレイプ + インタラクト」機能を持つAIエージェントを迅速に開発するのに役立つ理想的なツールセットを提供します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


