
Webスクレイピングとは何か?ウェブサイトからデータをスクレイピングするには?
Senior Web Scraping Engineer
ウェブスクレイピングは、ウェブサイトからデータを自動的に抽出するプロセスであり、非構造化または半構造化されたウェブデータをCSVやJSONなどの構造化された形式に変換します。
この技術は、eコマース、金融、マーケティング、研究など、さまざまな業界における意思決定におけるデータへの依存の高まりから、大きな注目を集めています。
信頼性の高いウェブスクレイピングサービスを利用することで、データ抽出プロセスの効率をさらに向上させることができます。これは、市場調査の実施、営業・マーケティングチームのリード獲得の促進、競合する小売・旅行ビジネスの価格監視において特に重要です。
ウェブスクレイピングとは何か、そしてどのようにシームレスにウェブサイトをスクレイピングするか?
この記事で詳細なガイドを入手してください!
ウェブスクレイピングとは?
ウェブスクレイピングには、ソフトウェアまたはスクリプトを使用してウェブサイトから情報を収集および処理することが含まれます。手動によるデータ収集とは異なり、ウェブスクレイピングは抽出プロセスを自動化するため、より効率的でスケーラブルになります。主な目標は、分析、研究、またはアプリケーションへの統合のための、実行可能な洞察や大規模なデータセットを収集することです。
ウェブスクレイピングは、機械学習モデルのためのデータを提供する上で重要な役割を果たし、人工知能技術の進歩をさらに進めています。データ収集プロセスを自動化し、さまざまなソースから情報を収集するためのデータを拡張することにより、ウェブスクレイピングは強力で正確で、適切にトレーニングされた人工知能モデルの作成に役立ちます。
公開されているウェブサイトからデータを取得したい場合、APIが提供されていない、またはウェブデータへのアクセスが制限されている場合、ウェブスクレイピングは特に役立ちます!
この場合、従来の方法ではニーズを満たすことができず、Scrapelessなどの外部ウェブスクレイピングサービスを活用することが戦略的なアプローチとなります。**これらのサービスは、より効率的でスケーラブルなソリューションを提供します。**さらに、高度な機能を探しているユーザーのために、ScrapelessのAPIやScraping Browserなどのツールは、ブロッキングの処理、自動ブラウザ操作、セッションとCookieの管理、効率的なデータ抽出などの機能を提供する包括的なソリューションを提供します。
そして、他の同様の製品と比較して、Scrapelessは高い安定性を確保しながら、より安い価格を提供します。予算は限られているがニーズが強い企業にとって、コストの負担を軽減します。
ウェブスクレイピングの仕組み
ウェブスクレイピングは、非構造化データと構造化データの収集を自動化するプロセスです。ウェブデータ抽出またはウェブデータスクレイピングとしても広く知られています。
ウェブスクレイピングの主要なユースケースには、価格監視、価格インテリジェンス、ニュース監視、リードジェネレーション、市場調査などがあります。
一般的に、公開されているウェブデータを利用して貴重な洞察を生み出し、より賢明な意思決定を行いたい個人や企業によって使用されます。
手動によるウェブスクレイピング
ウェブサイトから情報をコピーして貼り付けたことがある場合、ウェブスクレイピングツールと同じ機能を実行しましたが、データスクレイピングプロセスを手動で行いました。
- ターゲットウェブサイトを特定する
- ターゲットページのURLを収集する
- これらのURLにリクエストを送信してページのHTMLを取得する
- ローケーターを使用してHTML内の情報を見つける
- データをJSONまたはCSVファイル、またはその他の構造化された形式で保存する
毎日のウェブスクレイピングにはこれで十分そうです。残念ながら、大規模にデータを抽出する必要がある場合、多くの課題に対処する必要があります。
たとえば、ウェブサイトのレイアウトが変更された場合、データ抽出ツールとウェブクローラの維持、プロキシの管理、JavaScriptの実行、またはアンチボットの回避が必要です。これらは内部リソースを消費する技術的な問題です。
この時点で、より強力な自動化ツールであるWebスクレイパーを使用する必要があります。
ウェブスクレイパー
自分でデータを抽出するという面倒なプロセスとは異なり、ウェブスクレイピングは機械学習とインテリジェントな自動化を使用して、インターネットから数百万、あるいは数十億もの抽出されたデータポイントを取得します。
- ウェブスクレイピングは、ウェブサイトにHTTPリクエストを送信し、そのHTMLコンテンツを取得することによって機能します。
- 次に、スクリプトはHTML構造を解析して、タグ、属性、またはパターンを使用して特定のデータポイントを見つけ、抽出します。
- 高度な方法は、PuppeteerやSeleniumなどのツールを使用してブラウザの動作をシミュレートすることにより、JavaScriptによってレンダリングされた動的なコンテンツを処理できます。
自分でウェブスクレイパーを作成する場合でも、強力なウェブデータ抽出ツールを使用する場合でも、ウェブスクレイピングまたはウェブデータ抽出の基本についてさらに知っておく必要があります!
ウェブスクレイピングとウェブクロールの違い
| 機能 | ウェブスクレイピング | ウェブクロール |
|---|---|---|
| 目標 | 特定のデータを抽出する | ウェブリンクをクロールし、コンテンツインデックスを作成する |
| 範囲 | 少数のウェブページと特定のコンテンツに焦点を当てる | 多数のウェブページをクロールする |
| 技術的な複雑さ | 中程度、主にデータ分析に使用される | 高い、リンク追跡と重複排除を管理する必要がある |
| 一般的なツール | BeautifulSoup、Puppeteer、Scrapy | Scrapy、Apache Nutch、Selenium |
| 主な用途 | データ分析、eコマース価格監視 | 検索エンジンのインデックス作成、SEO分析 |
ウェブスクレイピング
ウェブスクレイピングは、ウェブページから特定のデータを抽出してCSVやJSONなどの構造化された形式に変換するために使用される集中的なプロセスです。目標は、価格、レビュー、製品の詳細など、分析やさらなる使用のために正確な情報を取得することです。スクレイパーはXPath、CSSセレクター、または正規表現などのツールを使用して、目的のデータを効率的に見つけて抽出します。
ウェブクロール
ウェブクロールは、「スパイダー」と呼ばれることが多く、リンクに従ってウェブページをインデックス付けして収集するためにインターネットを閲覧する自動化されたプロセスです。クローラーは通常、検索エンジンなどの大規模なデータセットまたはインデックスを作成するために使用されます。一部のプロジェクトでは、ウェブクロールはURLを収集するための予備的な手順であり、その後、ウェブスクレイパーによって処理されて特定のデータが抽出されます。
サイトをスクレイピングするための2つの一般的なウェブスクレイピング方法
ウェブサイトのスクレイピング方法をより明確に理解するために、ここでは2つの一般的で強力なクロールツールであるScraping APIとScraping Browserを使用してGoogleトレンドをスクレイピングします。
Scraping API
高度なScraping APIを使用すると、複雑なスクレイピングスクリプトを作成または維持することなく、Googleトレンドデータに簡単にアクセスしてスクレイピングできます。提供するAPIを呼び出すだけで、必要な情報をすぐに取得できます。
Googleトレンドデータのカテゴリ(時間経過に伴う関心度、地域別の比較内訳、小地域別の関心度、関連クエリ、関連トピックなど)を簡単にスクレイピングできます。
手順は以下のとおりです。
- 手順1。Scrapelessにログインします。
- 手順2。「Scraping API」をクリックします。
- 手順3。「Googleトレンド」パネルを見つけ、入力します。
- 手順4。左側の操作パネルでデータを設定します。
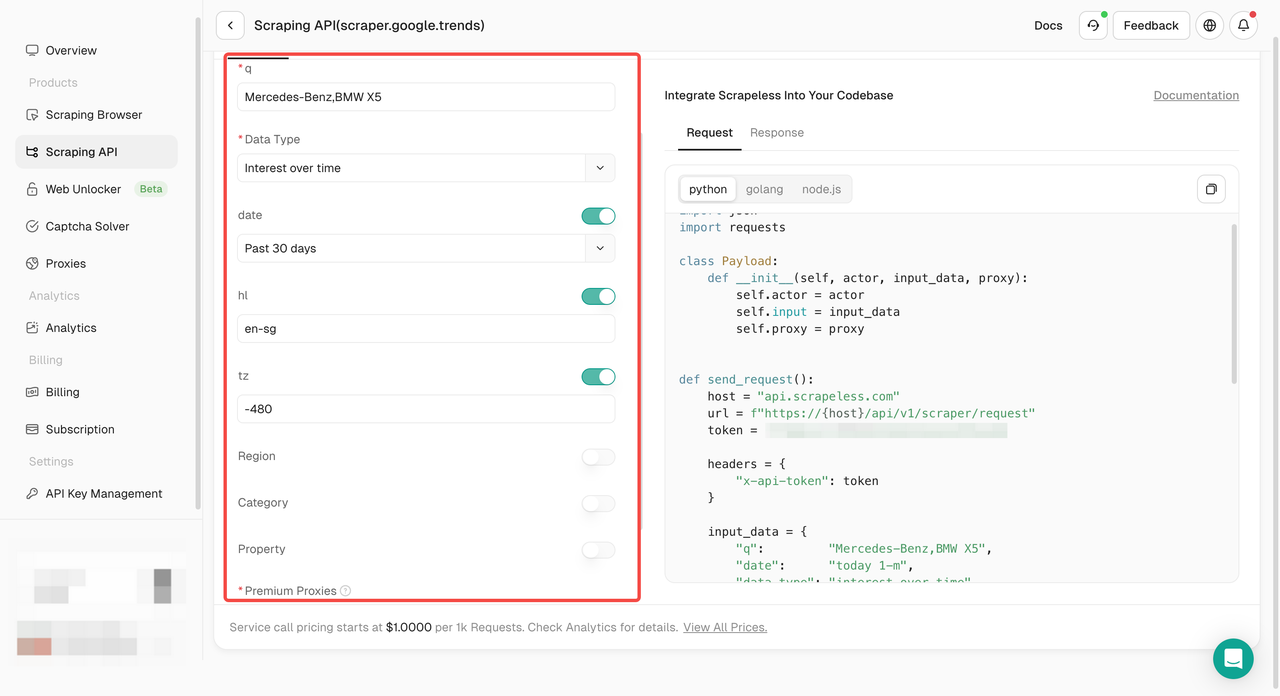
- 手順5。「スクレイピングを開始」ボタンをクリックすると、結果を取得できます。
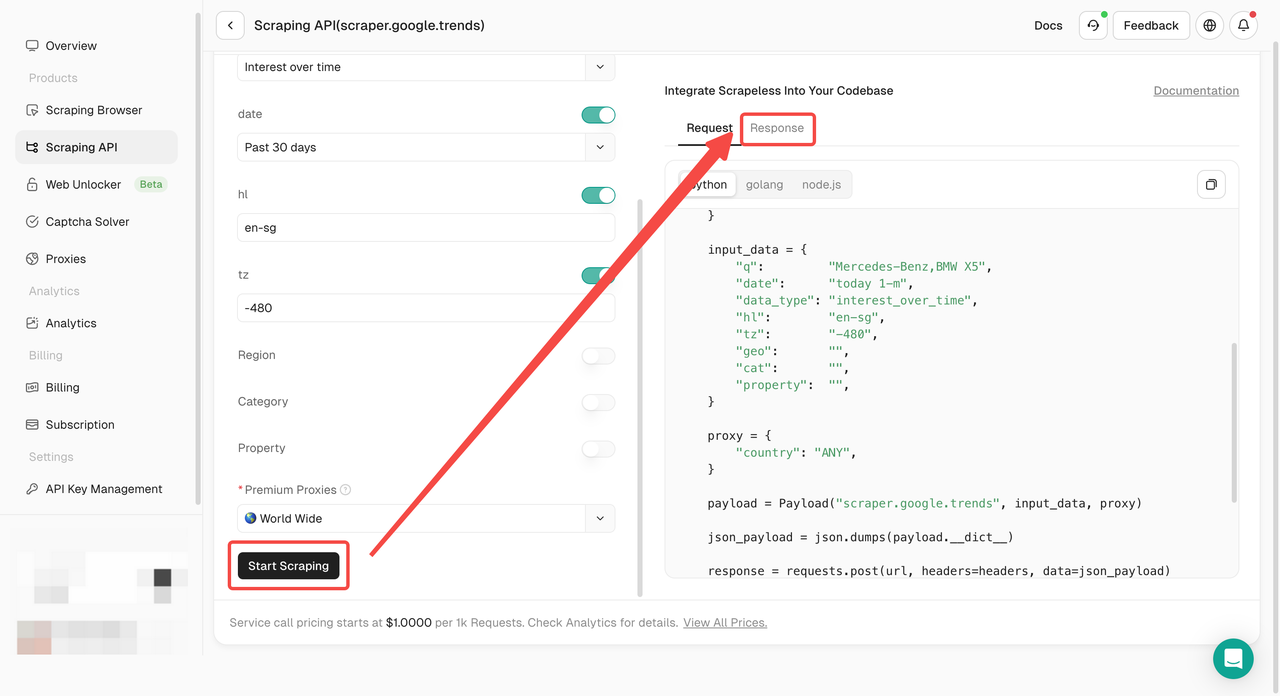
または、独自のプロジェクトにAPIをデプロイすることもできます。例:
- Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.trends",
"input": {
"keywords": "Mercedes-Benz,BMW X5",
"geo": "",
"time": "today 1-m",
"category": "0",
"property": ""
},
"proxy": {
"country": "US"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.trends",
"input": {
"data_type": "autocomplete",
"q": "Mercedes-Benz"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Scraping Browser
要件:
- Node.js: バージョン14以上がインストールされていることを確認してください。
- npm: 依存関係を処理するためのNodeパッケージマネージャー。
- Scrapeless Browserless Service: Scrapelessが提供するブラウザサービスを使用します。
次に、Scraping Browserダッシュボードにアクセスし、「設定」タブに移動してAPIキーを取得します。
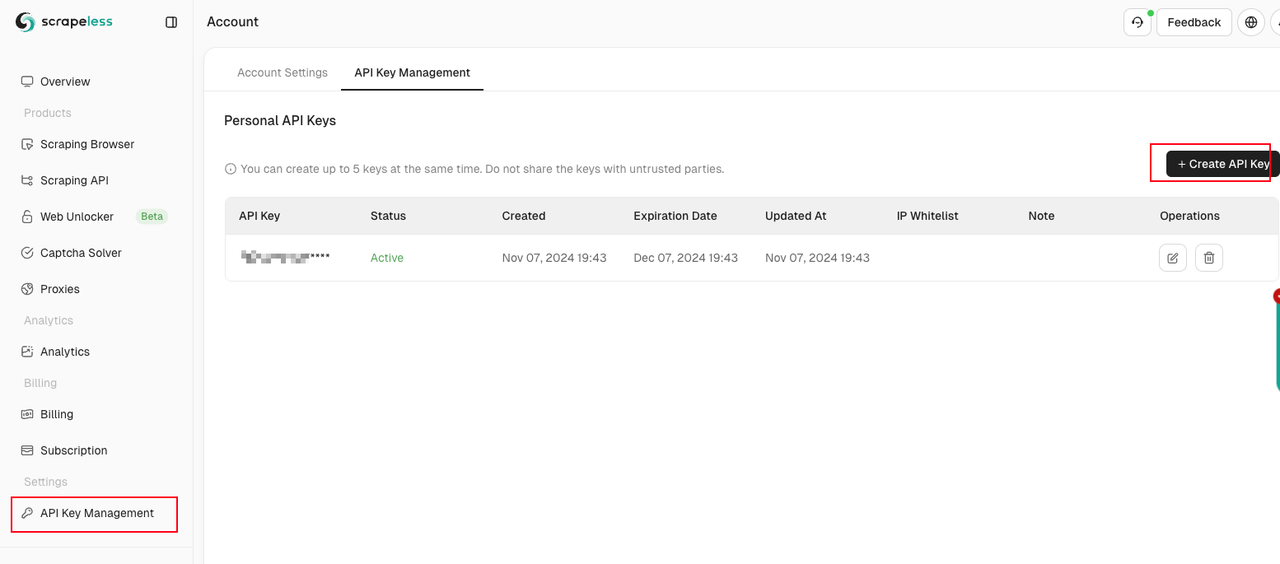
次に、以下の手順に従ってください。
- 次を使用して必要な依存関係をインストールします。
Bash
npm install- 環境変数を設定する
プロジェクトのルートディレクトリに.envファイルを作成し、APIキーを次のように追加します。
Bash
API_KEY=your_scrapeless_api_key- スクリプトパラメーターをカスタマイズする
スクリプトは、過去7日間にわたって米国で「youtube」と「twitter」のトレンドを取得するように事前に構成されています。以下の設定を調整できます。
- キーワード:
QUERY_PARAMS変数のqパラメーターを変更して、検索用語を変更します。 - 位置情報:
geoパラメーターを更新して、目的の場所を設定します。 - 日付範囲: 分析する期間に基づいて
dateパラメーターを調整します。
- Cookieを設定する
時間経過に伴う変化する関心に関連するデータを安定させるために、ウェブサイトにアクセスする前にPuppeteerを使用してCookieを設定します。
JavaScript
const cookies = JSON.parse(fs.readFileSync('./data/cookies.json', 'utf-8'));
await browser.setCookie(...cookies);cookies.jsonファイルを作成するには、ブラウザを介してGoogleトレンドにログインし、CookieをJSON形式でエクスポートします。方法がわからない場合は、Cookieエクスポート用に設計されたブラウザ拡張機能を使用することを検討してください。
- Node.jsを使用してスクリプトを実行します。
Bash
node index.jsウェブスクレイピングは何に使用できますか?
価格インテリジェンス
はい、価格インテリジェンスはウェブスクレイピングの最大のユースケースです。
eコマースウェブサイトから製品と価格情報を抽出し、それをインテリジェンスに変換することは、データに基づいてより良い価格設定/マーケティングの意思決定を行いたいと考えている現代のeコマース企業にとって不可欠な要素です。
ウェブ価格データと価格インテリジェンスの利点:
- ダイナミックプライシング
- 収益最適化
- 競合他社の監視
- 製品トレンドの監視
- ブランドおよびMAPのコンプライアンス
市場調査
市場調査は非常に重要であり、最も正確な情報に基づいて行われる必要があります。データスクレイピングを使用すると、あらゆる形状とサイズの、高品質で大量の高洞察力のあるウェブスクレイプされたデータにアクセスできるようになり、世界中の市場分析とビジネスインテリジェンスを推進しています。
- 市場トレンド分析
- 市場価格
- 参入ポイントの最適化
- 研究開発
- 競合他社の監視
金融代替データ
投資家に合わせたウェブデータを使用して、アルファを発見し、基礎から価値を生み出します。
意思決定はかつてないほどスマートになり、データはかつてないほど洞察力に富んでいます。ウェブスクレイプされたデータはその信じられないほどの戦略的価値を考えると、世界の主要企業によってますます使用されています。
- SEC提出書類からの洞察の抽出
- 企業の基本的な評価
- 世論の統合
- ニュース監視
不動産
過去20年間の不動産のデジタル変革は、従来のビジネスを混乱させ、業界に強力な新しいプレーヤーを生み出す可能性を秘めています。
ウェブからスクレイプされた不動産データを日常業務に組み込むことで、代理店や仲介業者は、トップダウンのオンライン競争を回避し、市場で賢明な意思決定を行うことができます。
- 不動産価値の評価
- 空室率の監視
- 推定賃貸収益率
- 市場の方向性の理解
ニュースとコンテンツの監視
現代のメディアは、1つのニュースサイクルであなたのビジネスに優れた価値または存在論的な脅威を生み出す可能性があります。
あなたの会社がタイムリーなニュース分析に依存している場合、または頻繁にニュースに取り上げられている会社である場合、ウェブスクレイピングニュースデータは、業界で最も重要なニュースを監視、集約、および解析するための究極のソリューションです。
- 投資判断
- オンライン世論分析
- 競合他社の監視
- 政治キャンペーン
- 感情分析
リードジェネレーション
リードジェネレーションは、すべてのビジネスにとって重要なマーケティング/営業活動です。
2024年のHubspotレポートでは、インバウンドマーケターの65%が、トラフィックとリードの生成が最大の課題であると述べています。幸いなことに、ウェブデータ抽出を使用して、ウェブから構造化されたリードリストを取得できます。
ブランド監視
今日の競争の激しい市場では、オンライン上の評判を守ることは最優先事項です。
オンラインで製品を販売していて厳格な価格設定ポリシーを実施する必要がある場合でも、人々がオンラインで製品をどのように見ているかを知りたい場合でも、ウェブスクレイピングを使用したブランド監視はその情報を提供できます。
ビジネスオートメーション
場合によっては、データへのアクセスが面倒になることがあります。独自のウェブサイトまたはパートナーのウェブサイトからデータを構造化された方法で抽出する必要があるかもしれません。
しかし、社内でこれを行う簡単な方法はないため、スクレイピングツールを作成してデータを直接スクレイピングすることは賢明な策です。複雑な内部システムでそれを理解しようとするのではなく。
MAP監視
最低広告価格(MAP)監視は、ブランドのオンライン価格がその価格設定ポリシーと一致していることを保証するための標準的な慣行です。
多数のディーラーやディストリビューターがいるため、価格を手動で監視することは不可能です。
そのため、製品の価格を簡単に監視できるため、ウェブスクレイピングは非常に便利です。
ウェブサイトを無料でスクレイピングする方法?
ウェブからコンテンツを自動的にスクレイピングし、データを抽出するために利用できるさまざまな無料のウェブスクレイピングソリューションがあります。これらのソリューションは、専門家以外のための簡単なポイントアンドクリックのスクレイピングソリューションから、広範な構成と管理オプションを備えた、より強力な開発者中心のアプリケーションまで多岐にわたります。
Scraping APIとScraping Browserは、インターネット社会の発展に沿った最も強力なツールになります。これらには、組み込みのウェブアンロッカー、プロキシ、CAPTCHAなどが搭載されているため、ウェブスクレイピングをより便利かつ高速に行うことができます。
最も正確なデータをすぐに取得するには、簡単な構成操作のみが必要です。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


