
安定したプロキシを使用してアンチボット検出を回避する方法は?
Expert Network Defense Engineer
多くのウェブサイトは、ウェブスクレイピングがますます一般的になってきたため、ボット対策の対策を実施し始めました。これには、情報を取得するために自動化ソフトウェアをブロックする複雑な技術が含まれています。ウェブサイトは、ウェブスクレイパーが行うリクエストの数量を制限したり、発見された場合には完全に停止させたりすることがあります。
ボット対策があなたをどのように検出し、それを回避する方法を学ぶための最も人気のある方法を見つけることができます。
今すぐスクロールを開始しましょう!
ボット対策認証とは?
ボット対策認証技術とは、ボットによって行われる自動化された活動を特定し、ブロックするシステムや技術を指します。ボットとは、オンラインタスクを自律的に実行するために作られたソフトウェアです。「ボット」という名前には否定的な意味があるように思えますが、それらすべてがそうではありません。たとえば、Googleのクロール機もボットです!
一方で、悪意のあるボットは世界中のオンライントラフィックの少なくとも27.7%を占めています。彼らはDDoS攻撃、スパム、身分盗用などの犯罪行為を行います。ユーザーのプライバシーを保護し、ユーザーエクスペリエンスを向上させるために、ウェブサイトはそれらを避けようとしており、あなたのウェブスクレイパーを禁止することさえあります。
さまざまな技術、たとえばHTTPヘッダーの検証、フィンガープリンティング、CAPTCHAなどを使用して、ボット対策フィルタは実際のユーザーと自動プログラムを区別します。
ウェブサイトはなぜボット対策を導入するのか?
ウェブサイトの所有者にとって、ボット対策技術はほとんどの妨害や課題を取り除くのに役立ちます:
- データ保護: ボット対策は、機密または独自の情報の無許可のスクレイピングを防ぎます。
- サービスの信頼性: ボットはサーバーリソースを過剰に消費し、ユーザーエクスペリエンスを低下させる可能性があり、ボット対策システムはそのようなリスクを軽減します。
- 詐欺防止: ボット対策チェックシステムは、偽アカウントの作成、チケットの転売、広告詐欺などの活動に対抗します。
- ユーザーのプライバシー: 無許可のボットをブロックすることによって、これらのシステムはユーザーデータの悪用から保護します。
ボット対策技術はどのように機能するのか?
ボット対策システムは、自動化された活動を検出し、抑制するためにさまざまな技術の組み合わせを採用しています:
ヘッダーの検証
ヘッダーの検証は一般的なボット対策技術です。これは、受信したHTTPリクエストのヘッダーを分析して異常や疑わしいパターンを探します。システムが不規則なものを検出した場合、そのリクエストをボットからのものとしてマークし、ブロックします。
すべてのブラウザリクエストには、ヘッダーに大量のデータが送信されます。これらのフィールドのいくつかが欠けている、不正な値を持っている、または不正な順序である場合、ボット対策システムはリクエストをブロックします。
行動分析
ボット対策認証メカニズムは、マウスの動き、キーストローク、ブラウジングパターンなどのユーザーインタラクションを分析します。自然でないまたは非常に繰り返しの多い行動は、ボットの活動を示す可能性があります。
IPアドレスの監視
多くのウェブサイトは、特定の地理的地域からのリクエストをブロックする位置ベースのブロックを採用しており、特定の国に対してコンテンツへのアクセスを制限しています。政府は、国内の特定のウェブサイトを禁止するためにこの戦略を使用します。
地理的禁止はDNSまたはISPレベルで適用されます。
ユーザーのIPアドレスを調べて、ユーザーの位置を特定し、ブロックするかどうかを判断します。したがって、地理的にブロックされたターゲットをスクレイピングするには、許可された国のIPアドレスが必要です。
位置ベースのブロックポリシーを回避するには、プロキシサーバーが必要です。通常、プレミアムプロキシはサーバーの所在国を選択できるようにします。この方法で、ウェブスクレイパーのクエリは正しい場所から来ることになります。
連続してウェブスクレイピングがブロックされることに疲れましたか?
Scrapeless Rotate Proxy は IP 禁止を回避するのに役立ちます。
今すぐ無料トライアルを取得!
ブラウザフィンガープリンティング
ブラウザフィンガープリンティングは、ユーザーのデバイスデータを収集することによってウェブクライアントを特定するプロセスです。インストールされたフォント、ブラウザプラグイン、画面解像度などの要素を見て、リクエストが正式なユーザーから来ているのか、スクレイパーから来ているのかを見分けることができます。
ブラウザフィンガープリンティングの実装戦略の大部分は、ユーザーデータを収集するためのクライアントサイドの技術を含みます。
上記のスクリプトは、フィンガープリントを取得するためにユーザーデータを収集します。
このボット対策ソフトウェアは、リクエストがブラウザから来ていると想定することがよくあります。ウェブスクレイピング中はヘッドレスブラウザが必要であり、そうでなければボットとして認識されます。
CAPTCHAチャレンジ
ウェブサイトは、ユーザーが人間かどうかを確認するためにチャレンジ・レスポンステスト、つまりCAPTCHAを使用しています。ボット対策ソリューションは、スクレイパーがウェブサイトにアクセスしたり、特定のタスクを実行したりするのを防ぐためにこれらの技術を使用します。人間はこの問題を簡単に解決できますが、ボットにとっては難しいのです。
ユーザーは、歪んだ画像に表示された数字を入力したり、画像のグループを選んだりするなど、ページ上で特定の活動を完了する必要があります。
TLSフィンガープリンティング
TLSハンドシェイク中に転送されるパラメータを分析することをTLSフィンガープリンティングと呼びます。アンチボット検証システムは、これらが適切なものでない場合、リクエストをボットからのものと特定し、それを停止します。
リクエスト検証
アンチボット検証システムは、HTTPリクエストの信頼性を検証します。疑わしいヘッダー、無効なユーザーエージェント文字列、または欠落したクッキーは、ボットトラフィックの兆候を示すことがあります。
アンチボット検出を回避するための5つの方法
アンチボットチェックシステムを回避するのは簡単ではないかもしれませんが、試せるトリックはいくつかあります。考慮すべき戦略のリストは以下の通りです:
1. スクラペラスの回転プロキシ
スクラペラスは、動的住宅IPv4プロキシに特化したプレミアムグローバルクリーンIPプロキシサービスを提供しています。
195カ国に70百万以上のIPアドレスを持つスクラペラスの住宅プロキシネットワークは、ビジネスの成長を促進するための包括的なグローバルプロキシサポートを提供します。
ウェブスクレイピング、市場調査、SEOモニタリング、価格比較、ソーシャルメディアマーケティング、広告検証、ブランド保護など、多岐にわたる利用ケースに対応しており、グローバル市場でビジネスを円滑に実行できるようにします。
特別なプロキシを取得するには?次の手順に従ってください:
- ステップ1. Scrapelessにサインインします。
- ステップ2. 「プロキシ」をクリックし、チャネルを作成します。
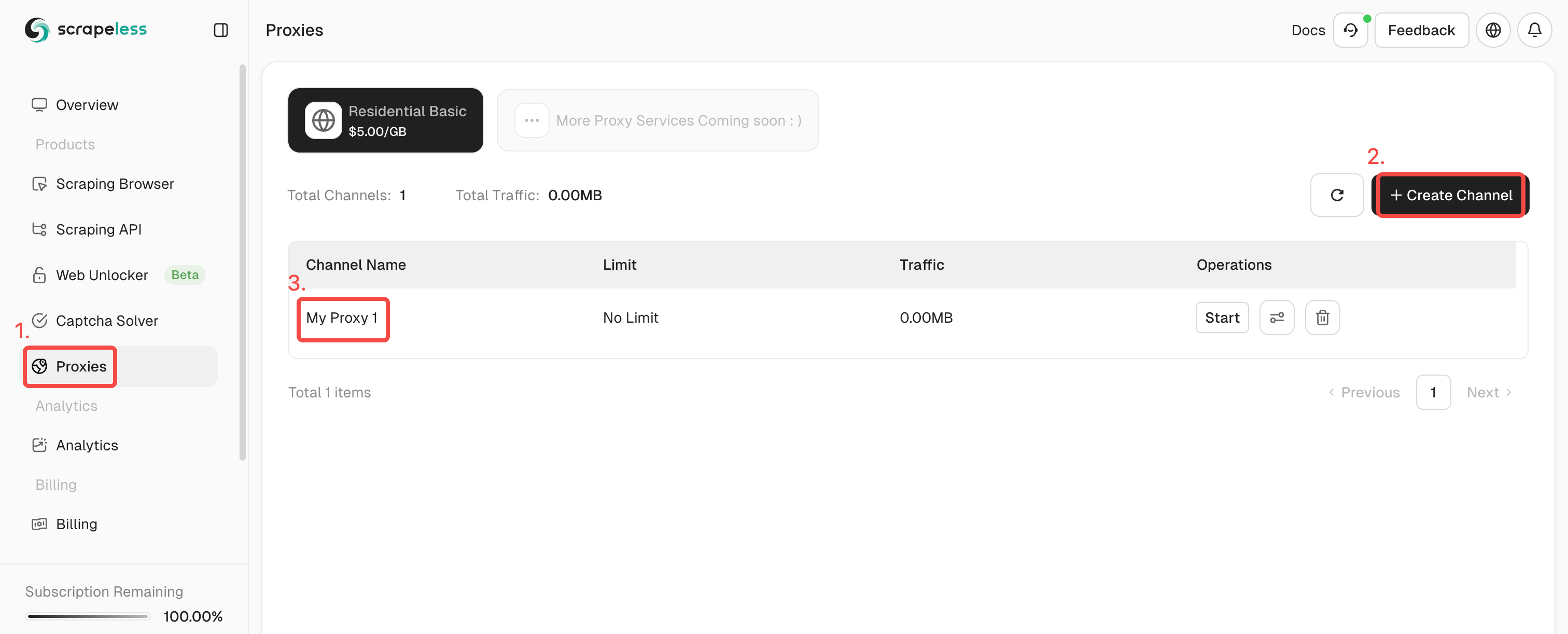
- ステップ3. 左側の操作ボックスに必要な情報を入力します。次に「生成」をクリックします。しばらくすると、右側に生成された回転プロキシが表示されます。あとは「コピー」をクリックして使用してください。
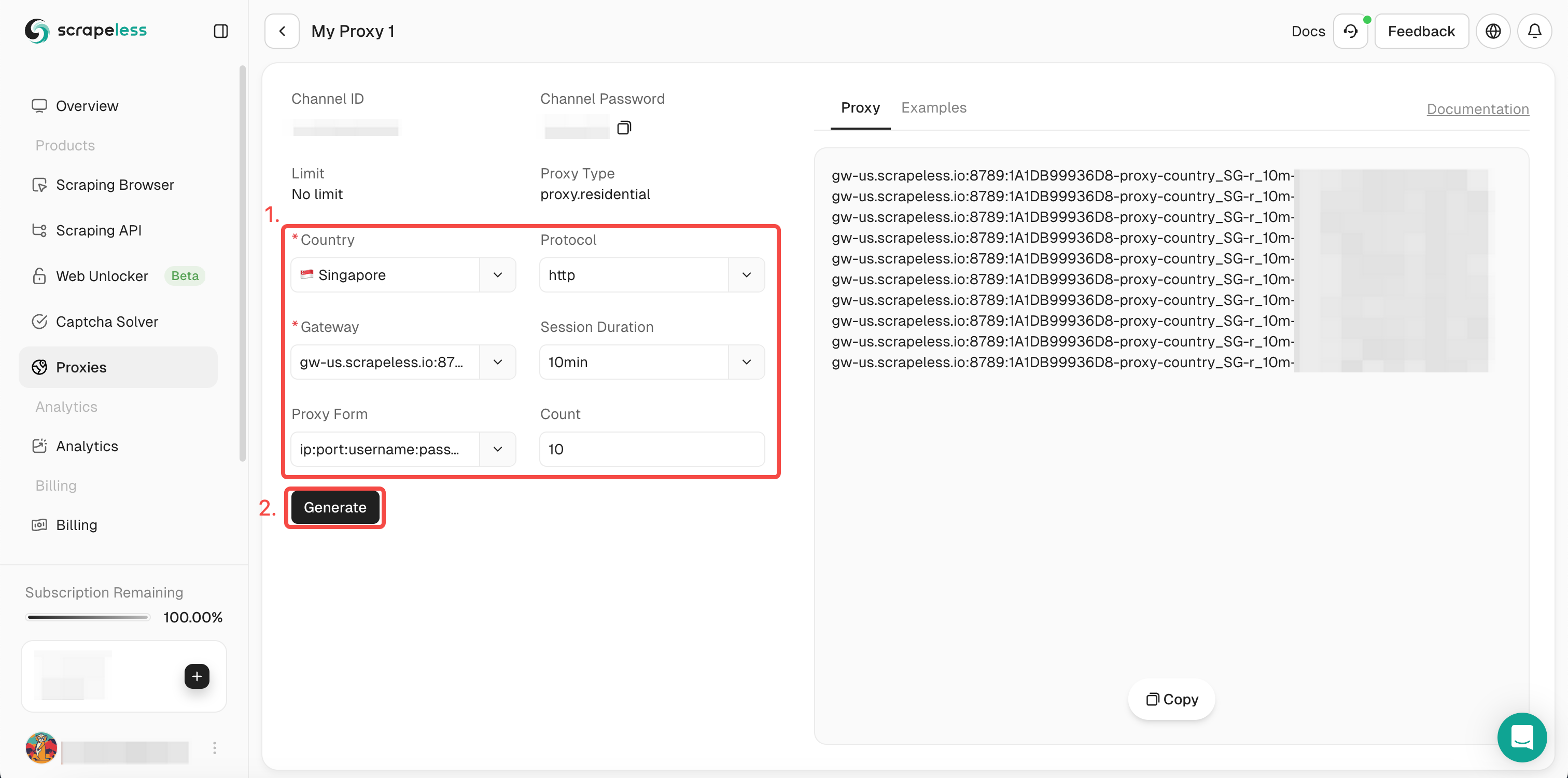
また、プロキシコードを統合してプロジェクトに組み込むこともできます:
- コード:
C
curl --proxy host:port --proxy-user username:password API_URL- ブラウザ:
- Selenium
Python
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
JavaScript
const puppeteer =require('puppeteer');
(async() => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();2. robots.txtを遵守する
このファイルは、ウェブサイトがファイルやページをボットがアクセス可能かどうかを示すための標準として機能します。ウェブスクレイパーは、指定された基準に従うことで、アンチボット対策が発動するのを防ぐことができます。ウェブスクレイピングの目的でrobot.txtファイルを読む方法について詳しく知ることができます。
同じIPアドレスからのクエリの数を制限する: ウェブスクレイパーは時々、ウェブサイトに対して多くのリクエストを短時間に送ることがあります。この行動はアンチボットシステムを作動させる可能性があるため、同じIPアドレスからのクエリの量を最小限に抑えることを検討してください。ウェブスクレイピングを使用している間にレート制限を回避する方法を調べてください。
3. ユーザーエージェントを適応させる
ユーザーエージェントのHTTPヘッダーには、リクエストの出所となるブラウザとオペレーティングシステムを示す文字列が含まれています。このヘッダーが修正されているため、リクエストは通常のユーザーからのものであるかのように見えます。ウェブスクレイピングに最も人気のあるユーザーエージェントのリストを確認してください。
4. ヘッドのないブラウザを使用する
グラフィカルユーザーインターフェースなしでも、ヘッドレスブラウザは制御可能です。このようなツールを使用することで、スクレイパーをボットとして識別されないようにし、人間のユーザーのように振る舞わせることができます。それは、スクロールを行うことです。ヘッドレスブラウザと、ウェブスクレイピングに適したものについて詳しく学んでください。
5. オンラインスクレイピングAPIで手続きを簡素化する
簡単なAPI呼び出しを使用することで、ウェブスクレイピングAPIはユーザーがアンチボットシステムに検出されることなくウェブサイトをスクレイピングすることを可能にします。そのため、ウェブスクレイピングは迅速、簡単、かつ効果的です。
今すぐスクラペラススクレイピングAPIを無料で試して、利用可能な最も強力なウェブスクレイピングAPIが提供するものを確認してください。
まとめ
このチュートリアルでは、アンチボット検出について多くのことを学びました。アンチボット検出を回避する方法は簡単です。
ブロッキングを避けるための最良の方法はどれですか?
Scrapelessを使用すれば、高度なCAPTCHAソルバー、内蔵のIPローテーション、ヘッドレスブラウザ機能、ウェブアンロッカーを備えたオンラインスクレイピングツールで、すべてを回避できます!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


