
Cloudflareで保護されたウェブサイトをバイパスする方法
Senior Web Scraping Engineer
Cloudflareで保護されたウェブサイトは、スクレイピングが最も困難なものの1つです。その自動ボット検出機能では、Cloudflareのアンチスクレイピング対策を回避し、ウェブページのデータを取得するために、強力なウェブスクレイピングツールを使用する必要があります。
今日は、PythonとオープンソースのCloudscraperライブラリを使用して、Cloudflareで保護されたウェブサイトをスクレイピングする方法をご紹介します。ただし、場合によっては効果的ですが、Cloudscraperには避けられないいくつかの制限があることがわかります。
Cloudflare Bot Managementとは?
Cloudflareは、コンテンツ配信およびWebセキュリティ企業です。クロスサイトスクリプティング(XSS)、クレデンシャルスタッフィング、DDoS攻撃などのセキュリティ脅威からウェブサイトを保護するために、Webアプリケーションファイアウォール(WAF)を提供しています。
Cloudflare WAFの中核システムの1つはBot Managerであり、実際のユーザーに影響を与えることなく、悪意のあるボットによる攻撃を軽減します。ただし、CloudflareはGoogleなどの既知のクローラーボットを許可しますが、未知のボットトラフィック(Webクローラーを含む)は悪意があると仮定します。
Cloudflare WAFの紹介
Cloudflare WAFは、Cloudflareの中核保護システムにおける重要なコンポーネントであり、HTTP/HTTPSトラフィックをリアルタイムで分析することにより、悪意のあるリクエストを検出してブロックするように設計されています。SQLインジェクション、クロスサイトスクリプティング(XSS)、DDoS攻撃など、潜在的な脅威を、ルールセット(定義済みのルールとカスタムルールを含む)に基づいてフィルタリングします。
Cloudflare WAFは、IPレピュテーションデータベース、行動分析モデル、機械学習技術を組み合わせ、新しい攻撃に対応するために保護戦略を動的に調整できます。さらに、WAFはCloudflareのCDNおよびDDoS保護とシームレスに統合され、正当なユーザーの低遅延と高可用性を維持しながら、ウェブサイトに多層セキュリティを提供します。
以下の表から、WAFの保護対策とその突破の難易度が明確にわかります。
| 保護レイヤー | 技術原理 | 突破の難易度 |
|---|---|---|
| IPレピュテーション検出 | IPの履歴に基づく行動分析(ASN/地理位置情報) | ★★☆☆☆ |
| JSチャレンジ | ブラウザ環境を確認するための動的な数学問題の生成 | ★★★☆☆ |
| ブラウザフィンガープリント | Canvas/WebGLレンダリング機能の抽出 | ★★★★☆ |
| 動的トークン | タイムスタンプベースの暗号化トークン検証 | ★★★★☆ |
| 行動分析 | マウスの軌跡/クリックパターンの認識 | ★★★★★ |
Cloudflareはどのようにボットを検出するか?
Cloudflareのボット管理システムは、悪意のあるボットと正当なトラフィック(検索エンジンクローラーなど)を区別するように設計されています。着信リクエストを分析することにより、異常なパターンを特定し、疑わしいアクティビティをブロックして、サイトとアプリケーションの整合性を維持します。
その検出方法は、パッシブまたはアクティブのいずれかです。パッシブボット検出技術はバックエンドフィンガープリントを使用する一方、アクティブ検出技術はクライアント側分析に依存します。
- パッシブボット検出技術
- ボットネットの検出
- IPアドレスのレピュテーション
- HTTPリクエストヘッダー
- TLSフィンガープリンティング
- HTTP/2フィンガープリンティング
- アクティブボット検出技術
- CAPTCHA
- Canvasフィンガープリンティング
- イベントトレース
- 環境APIクエリ
Cloudflareの3つの主なエラー
- Cloudflareエラー1015:それは何か、そしてどのように回避するか
- Cloudflareエラー1006、1007、1008:それらは何であり、どのように修正するか
- Cloudflare 403拒否:この問題を回避する
Cloudflareで保護されたウェブサイトをスクレイピングする方法?
ステップ1:環境の設定
まず、システムにPythonがインストールされていることを確認します。このプロジェクトのコードを保存するための新しいディレクトリを作成します。次に、cloudscraperとrequestsをインストールする必要があります。これはpipを使用して行うことができます。
Shell
$ pip install cloudscraper requestsステップ2:requestsを使用した単純なリクエストの実行
次に、https://sailboatdata.com/sailboat/11-meter/ のページからデータを取得する必要があります。ページコンテンツの一部は次のようになります。
ウェブサイトのプライバシーを厳格に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモとしてのみ使用されます。情報は一切保存しません。
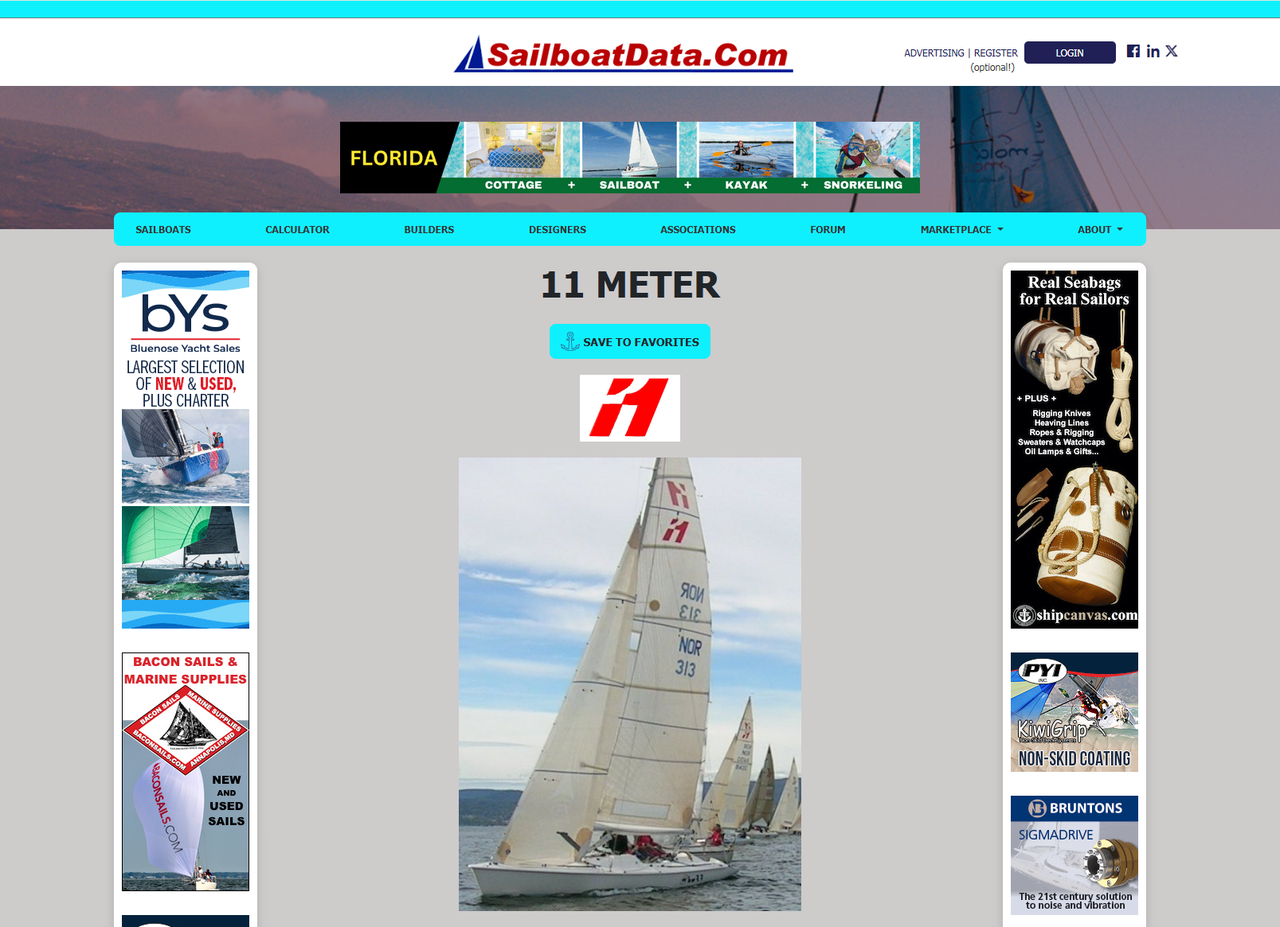
まず、requestsを使用して単純なGETリクエストを送信して確認してみましょう。
Python
def sailboatdata():
html = requests.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 403
with open("response.html", "wb") as f:
f.write(html.content)予想通り、ウェブページは403 Forbiddenステータスコードを返します。レスポンスはローカルファイルに保存されました。返されたコンテンツの具体的なソースコードを以下に示します。

ターゲットウェブサイトは保護されており、ローカルファイルは正しく開けません。ここで、これを回避する方法を見つける必要があります。
ステップ3:Cloudscraperを使用したデータのスクレイピング
Cloudscraperを使用して、ターゲットウェブサイトに同じGETリクエストを送信してみましょう。コードを以下に示します。
Python
def sailboatdata_cloudscraper():
scraper = cloudscraper.create_scraper()
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 200
with open("response.html", "wb") as f:
f.write(html.content)今回は、Cloudflareがリクエストをブロックしませんでした。保存したHTMLファイルをローカルで開き、ブラウザで表示します。ページは次のようになります。
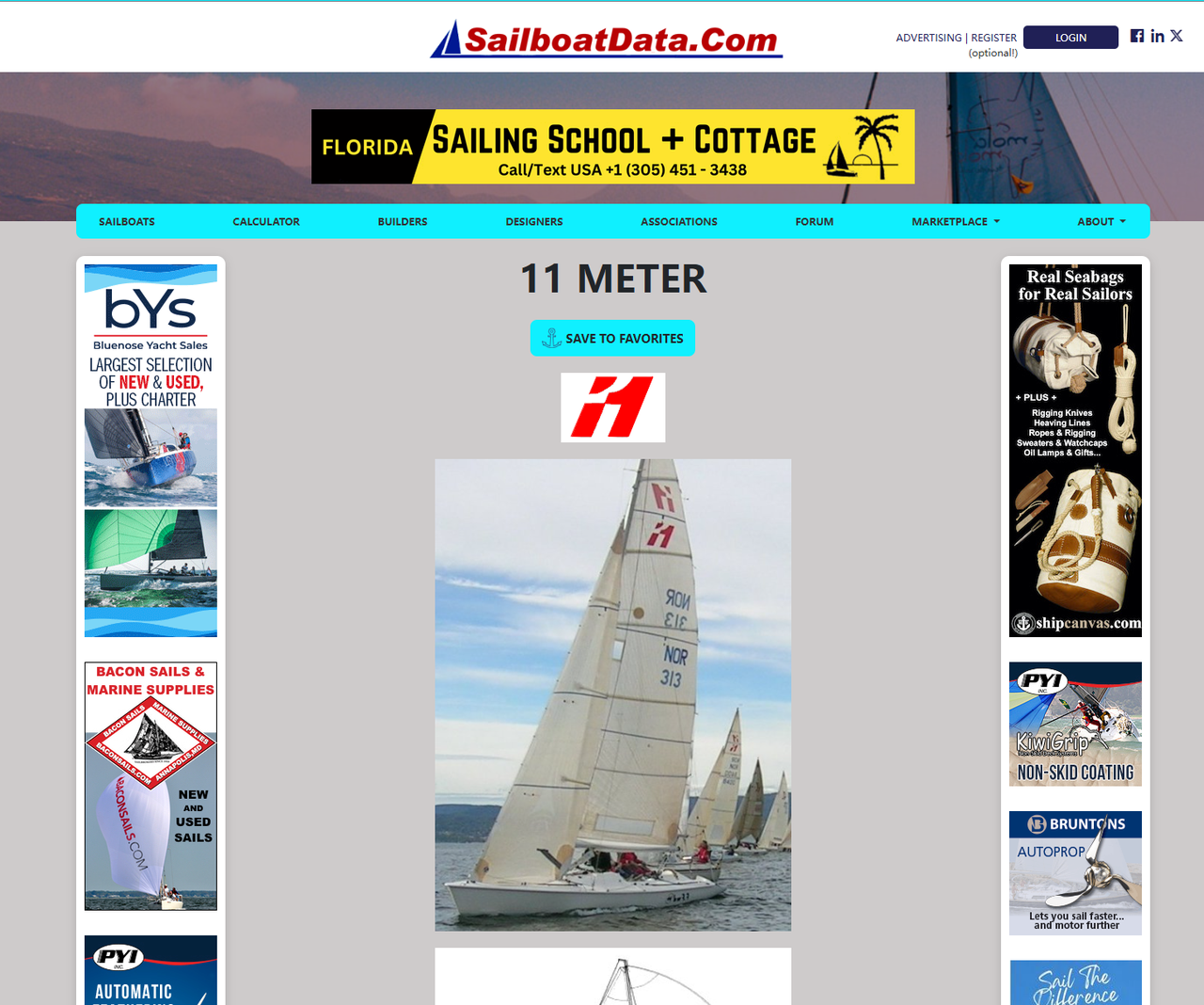
Cloudscraperの高度な機能
組み込みCAPTCHA処理
JavaScript
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': '2captcha_api_key'
}
)カスタムプロキシサポート
Python
proxies = {"http": "あなたのプロキシアドレス", "https": "あなたのプロキシアドレス"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")Scrapeless Scraping Browser:Cloudscraperよりも強力な代替手段
Cloudscraperの制限
Cloudscraperには、特定のCloudflareで保護されたウェブサイトを扱う際にいくつかの制限があります。最も顕著な問題は、Cloudflareのロボット検出v2保護メカニズムを回避できないことです。このようなウェブサイトからデータを取得しようとすると、次のエラーメッセージが表示されます。
JSON
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.さらに、Cloudscraperは、Cloudflareの高度なJavaScriptチャレンジにも対処できません。これらのチャレンジは、複雑な動的計算やページ要素とのインタラクションを伴うことが多く、Cloudscraperなどの自動化ツールが検証に合格するためにシミュレートするのは困難です。
もう1つの問題は、Cloudflareのレート制限ポリシーです。不正使用を防ぐため、Cloudflareはリクエスト頻度を厳格に制御しており、Cloudscraperにはこれらの制限を管理するための効果的なメカニズムがなく、リクエストの遅延や失敗を引き起こす可能性があります。
最後に、Cloudflareがボット検出技術を継続的にアップグレードするにつれて、オープンソースツールであるCloudscraperがこれらの変更に対応するのは困難です。時間の経過とともに、その機能の有効性と安定性は、特に新しいバージョンの保護メカニズムに直面した場合、徐々に低下する可能性があります。
なぜScrapelessが効果的か?
Scraping Browserは、動的なウェブサイトから大量のデータを抽出するための高性能なソリューションです。開発者は、専用のサーバーリソースなしで、ヘッドレスブラウザを実行、管理、監視できます。効率的で大規模なWebデータ抽出のために設計されています。
- ブラウザフィンガープリンティングやTLSフィンガープリンティング検出などの高度なアンチクローラーメカニズムを回避するために、実際の人間のインタラクション動作をシミュレートします。
- cf_challengeなど、複数の種類の検証コードの自動解決をサポートし、中断のないクロールプロセスを保証します。
- PuppeteerやPlaywrightなどの一般的なツールとのシームレスな統合により、開発プロセスを簡素化し、自動化されたタスクを開始するための1行のコードをサポートします。
Scraping Browserを統合してCloudflareをバイパスする方法?
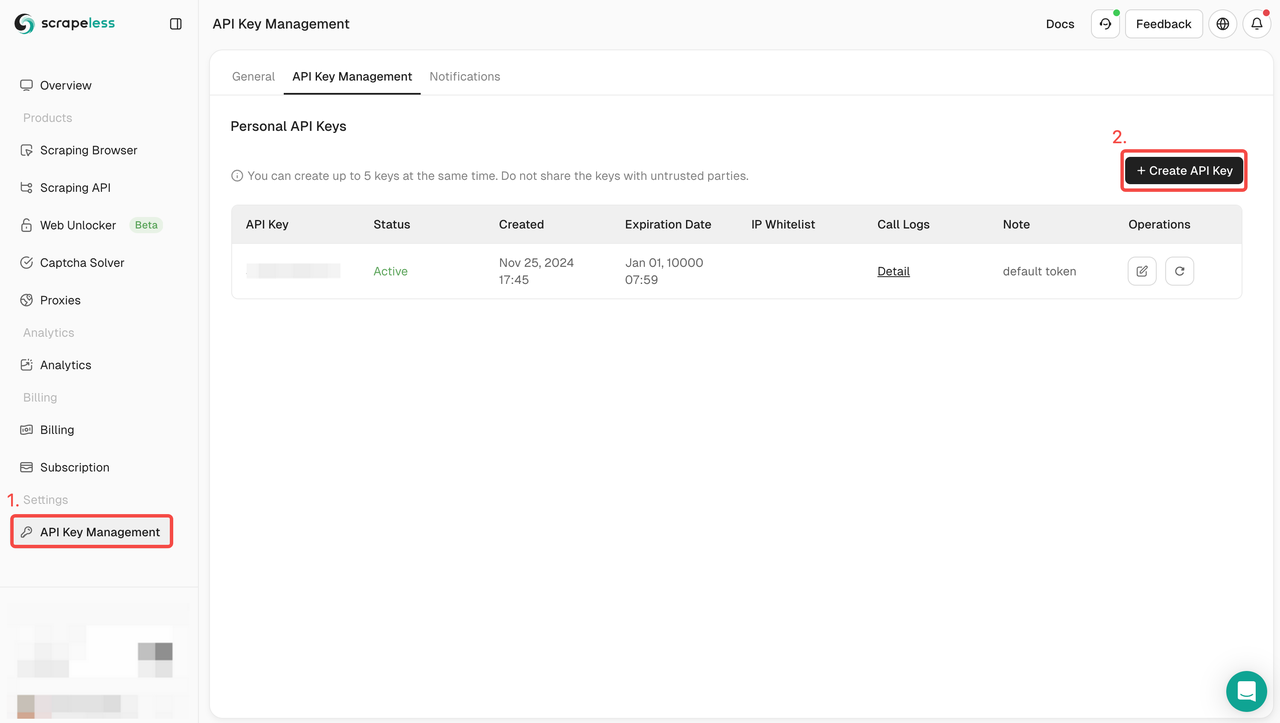
ステップ1. APIトークンの作成
- Scrapelessにサインアップ
- APIキー管理を選択
- APIキーの作成をクリックして、Scrapeless APIキーを作成します。
ScrapelessはシームレスなWebスクレイピングを保証します。
🎁 Discordに参加して無料トライアルを今すぐ入手!
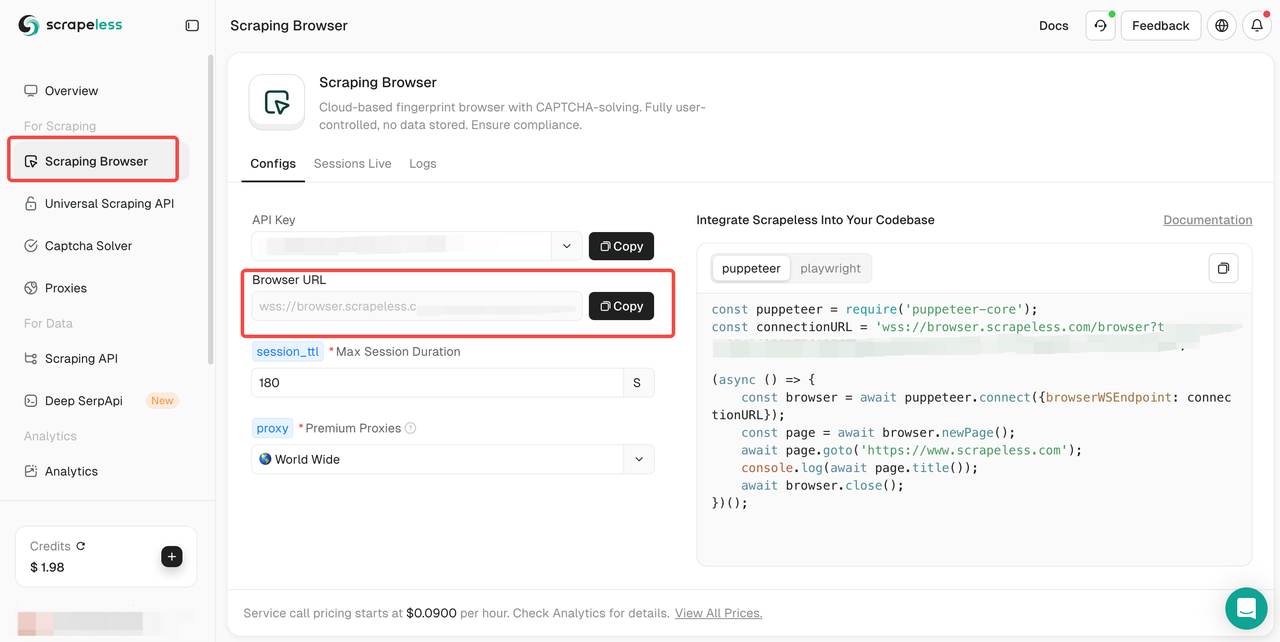
ステップ2. 次に、Scraping Browserに移動して、ブラウザURLをコピーします。
または、参照としてリクエストコードを確認できます。
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_API_TOKEN>&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();ステップ3. コードまたはブラウザURLをPuppeteerスクリプトに統合します。
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// ブラウザ環境を設定
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// 新しいページを作成
const page = await browser.newPage();
// URLに移動
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'networkidle0',
}); // ターゲットURLに置き換える
// チャレンジが解決するのを待つ
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// ページのスクリーンショットを撮る
await page.screenshot({ path: 'screenshot.png' });
// ブラウザインスタンスを閉じる
await browser.close();
})();Cloudflareをバイパスするための4つのヒント
自分でCloudflareをハックしようとすると、非常に困難になります!Cloudflareがボットに対して持つすべての防御手段を考慮し、それらを克服する方法を見つける必要があります。ほとんどの人は間違いなくこれを選ぶことはありません。
試してみたいですか?Cloudflareをバイパスするためのヒントをいくつかご紹介します。
JavaScriptレンダリング
Cloudflareは、ボットを検出するために、しばしばJavaScriptチャレンジを使用します。これらのスクリプトはウェブページに埋め込まれており、ブラウザを通じて特定のチェックを実行して、訪問者がボットかどうかを判断します。ボットが疑われる場合、CloudflareはCAPTCHA(Turnstile検証コードなど)を表示し、そうでない場合は通常のアクセスを許可します。
したがって、保護されたページをクロールするには、Playwright、Selenium、Puppeteerなどのブラウザ自動化ツールを使用して、実際のユーザーインタラクションをシミュレートする必要があります。ただし、ヘッドレスブラウザのデフォルト設定は、アンチボットシステムに公開される可能性があります。自動化の痕跡を隠すために、Playwright StealthまたはPuppeteer Stealthライブラリを使用することをお勧めします。
CAPTCHA解決
CAPTCHAは、ボットと人間を区別するための重要なテストです。簡単なクリック検証や複雑なパズルが含まれる場合があります。CAPTCHAを自動的に解析するのは困難であるため、Pythonテクノロジーを使用してバイパスするか、Bright DataのCloudflare Turnstile Solverを使用して自動的に解決してみてください。
レート制限の回避
Cloudflareは、短時間で非常に多くのリクエストが発生するとレート制限をトリガーし、IPが一時的または永続的にブロックされる可能性があります。この問題を回避するには、住宅用プロキシなどのプロキシサービスを使用してIPローテーションを実装し、リクエストを実際のデバイスとして偽装することをお勧めします。
ブラウザのスプーフィング
ブラウザ自動化ツールは効果的ですが、多くのリソースを消費します。Cloudflare WAFが厳密に構成されていない場合は、ブラウジングのスプーフィング技術を使用してHTTPリクエストを送信し、実際のブラウザの動作を模倣できます(User-Agentヘッダーの設定など)。ただし、より複雑なシナリオでは、ヘッダーだけでは不十分な場合があり、ブラウザのTLSフィンガープリントもコピーする必要があります(curl-impersonateツールを使用するなど)。
終わりに
この記事では、Cloudflareで保護されたウェブサイトをスクレイピングする方法に関するヒントとコツを学びました。Cloudflareは市場で最も人気のあるCDNサービスであり、高度なアンチボットソリューションも提供しています。
この記事が示すように、Cloudflareのアンチスクレイピング対策を回避するのは困難ですが、不可能ではありません。以下のようなプロフェッショナルで高速かつ信頼性の高いスクレイピングソリューションを使用すると、すべてが簡単になります。
- ユニバーサルスクレイピングAPI:レート制限、フィンガープリンティング、その他のアンチボット制限を自動的に回避し、シームレスなパブリックWebデータ収集を実現します。
- Scraping Browser:ウェブサイトのブロックを自動化しながら、動的なWebデータをスクレイピングできる完全にホストされたブラウザです。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


