
如何绕过 Cloudflare 保护的网站?
Senior Web Scraping Engineer
使用Cloudflare保护的网站可能是最难抓取的网站之一。其自动机器人检测需要您使用强大的网页抓取工具来绕过Cloudflare的反抓取措施并提取其网页数据。
今天,我们将向您展示如何使用Python和开源Cloudscraper库来抓取受Cloudflare保护的网站。话虽如此,虽然在某些情况下有效,但您会发现Cloudscraper有一些难以避免的限制。
什么是Cloudflare机器人管理?
Cloudflare是一家内容交付和网络安全公司。它提供Web应用防火墙 (WAF) 来保护网站免受诸如跨站脚本 (XSS)、凭据填充和DDoS攻击等安全威胁。
Cloudflare WAF的核心系统之一是Bot Manager,它可以减轻恶意机器人发起的攻击,而不会影响真实用户。但是,虽然Cloudflare允许已知的爬虫机器人(如Google),但它假设任何未知的机器人流量(包括网络爬虫)都是恶意的。
Cloudflare WAF简介
Cloudflare WAF是Cloudflare核心保护系统中的一个关键组件,旨在通过实时分析HTTP/HTTPS流量来检测和阻止恶意请求。它根据规则集(包括预定义规则和自定义规则)过滤SQL注入、跨站脚本(XSS)、DDoS攻击等潜在威胁。
Cloudflare WAF结合了IP信誉数据库、行为分析模型和机器学习技术,可以动态调整保护策略以应对新的攻击。此外,WAF与Cloudflare的CDN和DDoS防护无缝集成,为网站提供多层安全保护,同时保持合法用户的低延迟和高可用性。
从下表中,您可以清楚地看到WAF的防护措施和破解难度:
| 防护层 | 技术原理 | 破解难度 |
|---|---|---|
| IP信誉检测 | 分析IP历史行为(ASN/地理位置) | ★★☆☆☆ |
| JS挑战 | 动态生成数学题验证浏览器环境 | ★★★☆☆ |
| 浏览器指纹 | Canvas/WebGL渲染特性提取 | ★★★★☆ |
| 动态令牌 | 基于时间戳的加密令牌验证 | ★★★★☆ |
| 行为分析 | 鼠标轨迹/点击模式识别 | ★★★★★ |
Cloudflare如何检测机器人?
Cloudflare的机器人管理系统旨在区分恶意机器人和合法流量(例如搜索引擎爬虫)。通过分析传入的请求,它可以识别异常模式并阻止可疑活动,以维护您网站和应用程序的完整性。
其检测方法可以是被动的或主动的。被动机器人检测技术使用后端指纹识别,而主动检测技术依赖于客户端分析。
- 被动机器人检测技术
- 检测僵尸网络
- IP地址信誉
- HTTP请求头
- TLS指纹识别
- HTTP/2指纹识别
- 主动机器人检测技术
- CAPTCHA
- Canvas指纹识别
- 事件跟踪
- 环境API查询
Cloudflare的3个主要错误
如何抓取受Cloudflare保护的网站?
步骤1:设置环境
首先,确保您的系统上安装了Python。创建一个新目录来存储此项目的代码。接下来,您需要安装cloudscraper和requests。您可以通过pip来完成此操作:
Shell
$ pip install cloudscraper requests步骤2:使用requests发出简单的请求
现在,我们需要从https://sailboatdata.com/sailboat/11-meter/上的页面抓取数据。页面内容的一部分如下所示:
我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用作抓取过程的演示。我们不保存任何信息和数据。
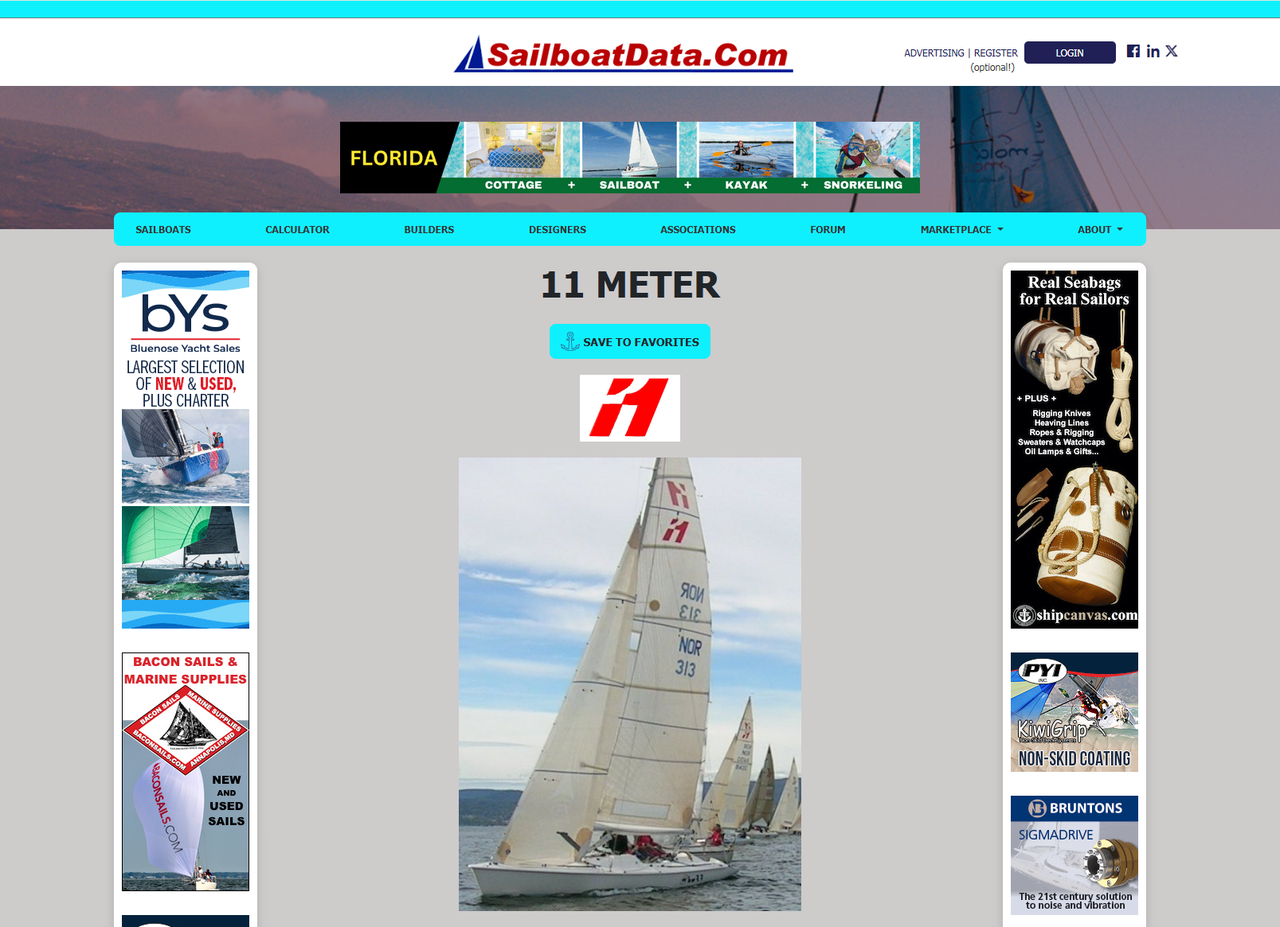
让我们首先尝试使用requests发送一个简单的GET请求来确认:
Python
def sailboatdata():
html = requests.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 403
with open("response.html", "wb") as f:
f.write(html.content)正如预期的那样,网页返回403禁止状态代码。我们将响应保存到本地文件中。返回内容的具体源代码如下所示:

目标网站受到保护,本地文件无法正常打开。现在,我们需要找到一种方法来绕过它。
步骤3:使用Cloudscraper抓取数据
让我们使用Cloudscraper向目标网站发送相同的GET请求。代码如下:
Python
def sailboatdata_cloudscraper():
scraper = cloudscraper.create_scraper()
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 200
with open("response.html", "wb") as f:
f.write(html.content)这次,Cloudflare没有阻止我们的请求。我们在本地打开保存的HTML文件并在浏览器中查看它。页面如下所示:
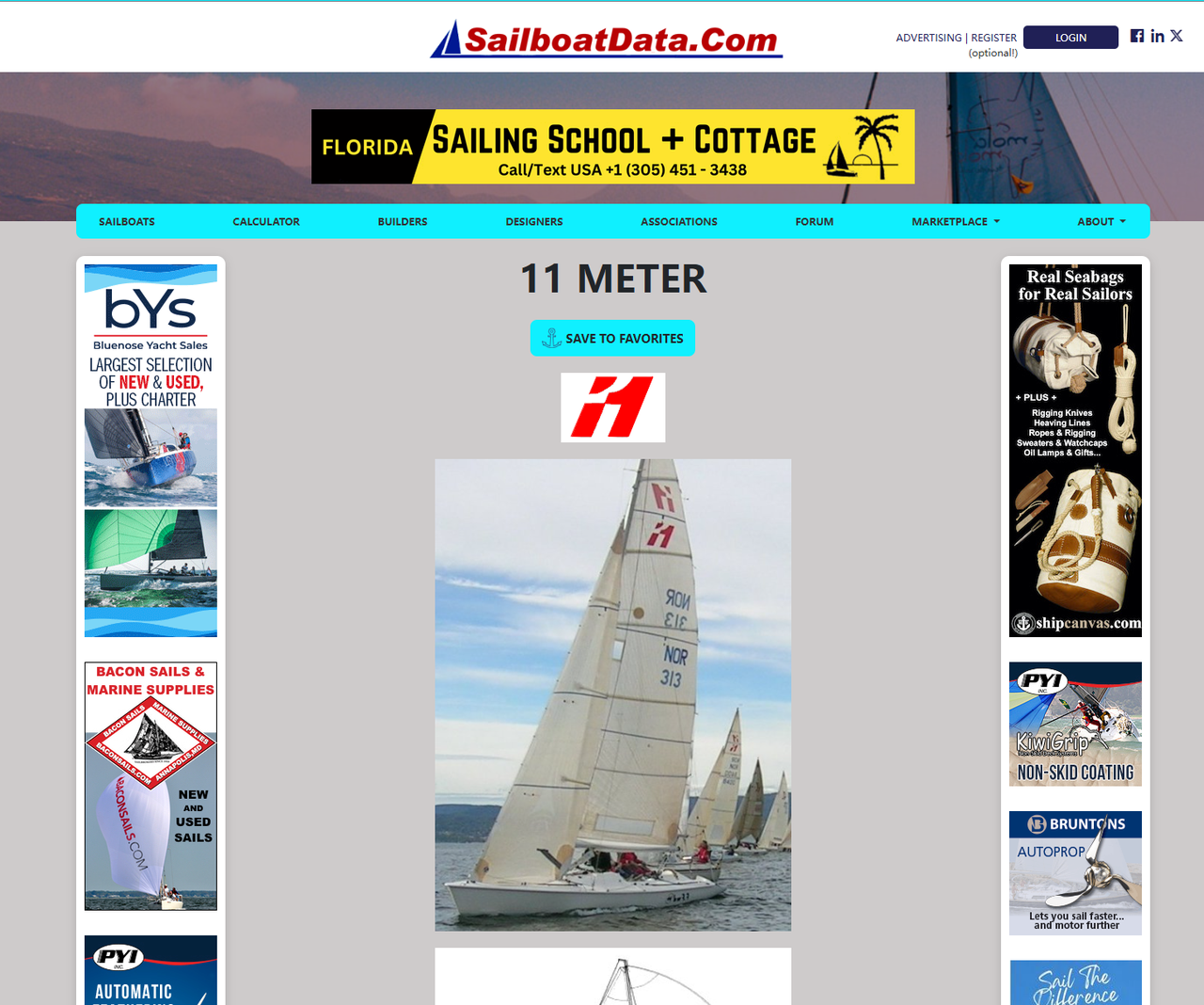
Cloudscraper的高级功能
内置CAPTCHA处理
JavaScript
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': '2captcha_api_key'
}
)自定义代理支持
Python
proxies = {"http": "your proxy address", "https": "your proxy address"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")Scrapeless抓取浏览器:比Cloudscraper更强大的替代方案
Cloudscraper的局限性
在处理某些受Cloudflare保护的网站时,Cloudscraper有一些局限性。最显著的问题是它无法绕过Cloudflare的机器人检测v2保护机制。如果您尝试从这样的网站抓取数据,将会触发以下错误消息:
JSON
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.此外,Cloudscraper也无法应对Cloudflare的高级JavaScript挑战。这些挑战通常涉及复杂的动态计算或与页面元素的交互,对于Cloudscraper等自动化工具来说,模拟这些交互以通过验证是困难的。
另一个问题是Cloudflare的速率限制策略。为了防止滥用,Cloudflare严格控制请求频率,而Cloudscraper缺乏有效的机制来管理这些限制,这可能会导致请求延迟甚至失败。
最后但并非最不重要的一点是,随着Cloudflare不断升级其机器人检测技术,作为开源工具的Cloudscraper很难跟上这些变化。随着时间的推移,其功能的有效性和稳定性可能会逐渐下降,尤其是在面对新版本的保护机制时。
为什么Scrapeless有效?
抓取浏览器是一个用于从动态网站提取大量数据的高性能解决方案。它允许开发人员运行、管理和监控无头浏览器,而无需专用服务器资源。它专为高效的大规模网页数据提取而设计:
- 模拟真实的人机交互行为,绕过高级反爬虫机制,例如浏览器指纹和TLS指纹检测。
- 支持自动解决多种类型的验证码,包括cf_challenge,确保抓取过程不中断。
- 与Puppeteer和Playwright等流行工具无缝集成,简化开发流程,并支持单行代码启动自动化任务。
如何集成Scraping Browser绕过Cloudflare?
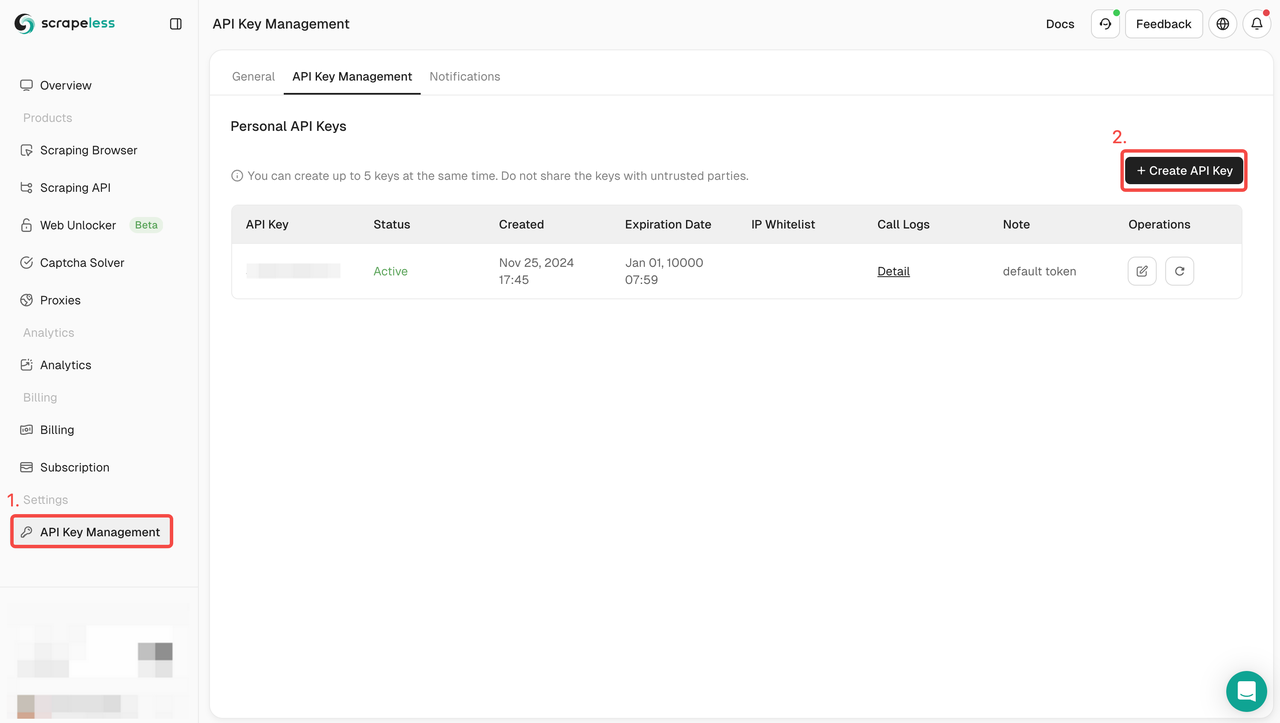
步骤1. 创建您的API令牌
- 注册Scrapeless
- 选择API密钥管理
- 点击创建API密钥来创建您的Scrapeless API密钥。
Scrapeless确保无缝网页抓取。
🎁 加入Discord并立即领取免费试用!
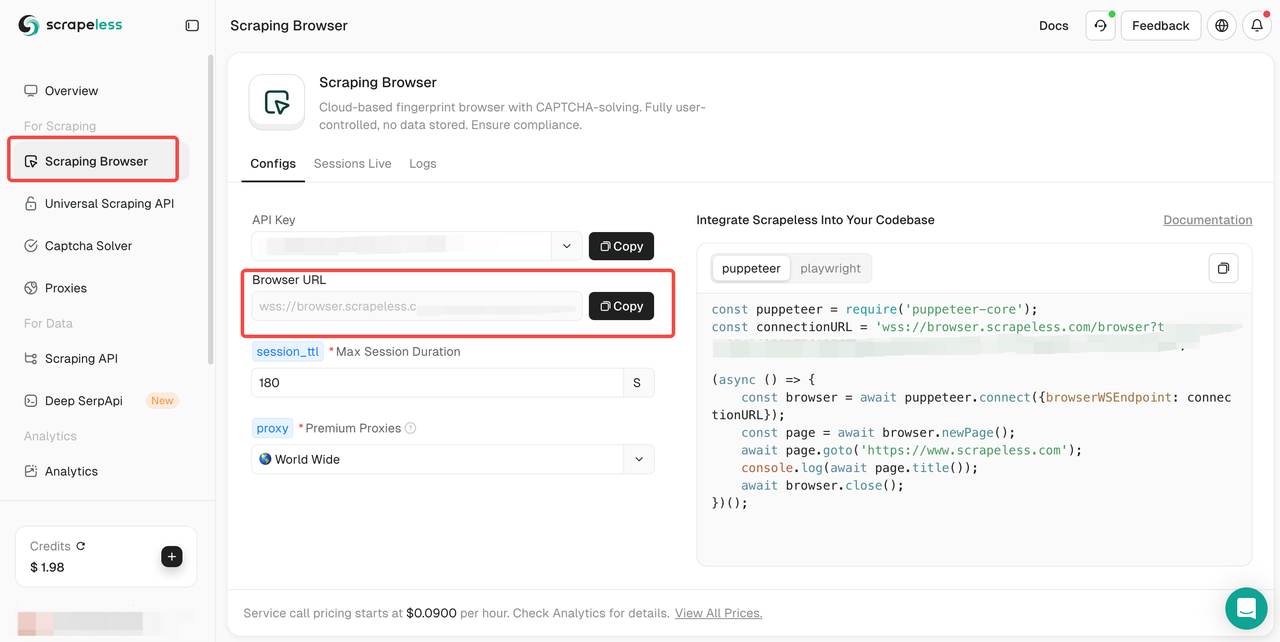
步骤2. 然后,转到Scraping Browser并复制您的浏览器URL。
或者您可以查看我们的请求代码作为参考:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_API_TOKEN>&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();步骤3. 将代码或浏览器URL集成到您的Puppeteer脚本中:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// 设置浏览器环境
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// 创建一个新页面
const page = await browser.newPage();
// 导航到URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'networkidle0',
}); // 替换为您的目标URL
// 等待挑战解决
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// 拍摄页面截图
await page.screenshot({ path: 'screenshot.png' });
// 关闭浏览器实例
await browser.close();
})();绕过Cloudflare的4个技巧
如果您想自己破解Cloudflare,这将非常困难!您必须考虑Cloudflare针对机器人的所有防御措施,并找到克服这些措施的方法。大多数人肯定不会选择这样做。
您想尝试一下吗?以下是一些帮助您绕过Cloudflare的技巧:
JavaScript渲染
Cloudflare经常使用JavaScript挑战来检测机器人。这些脚本嵌入在网页中,并通过浏览器执行特定的检查以确定访问者是否是机器人。如果怀疑是机器人,Cloudflare将显示CAPTCHA(例如Turnstile验证码),否则将允许正常访问。
因此,要抓取受保护的页面,您需要使用浏览器自动化工具(例如Playwright、Selenium或Puppeteer)来模拟真实用户的交互。但是,无头浏览器的默认配置可能会暴露给反机器人系统。建议使用Playwright Stealth或Puppeteer Stealth库来隐藏自动化痕迹。
CAPTCHA解决
CAPTCHA是区分机器人和人类的关键测试。它可能包括简单的点击验证或复杂的难题。自动解析CAPTCHA很困难,因此您可以尝试使用Python技术绕过它,或者使用Bright Data的Cloudflare Turnstile Solver自动解决它。
速率限制规避
Cloudflare会在短时间内触发对过多请求的速率限制,这可能会导致IP被暂时或永久阻止。为了避免这个问题,建议使用代理服务(例如住宅代理)来实现IP轮换并将请求伪装成真实设备。
浏览器欺骗
虽然浏览器自动化工具有效,但它们会消耗大量资源。如果Cloudflare WAF没有严格配置,您可以使用浏览器欺骗技术发送HTTP请求来模仿真实的浏览器行为(例如设置User-Agent标头)。但是,在更复杂的场景中,仅标头可能不够,您还需要复制浏览器的TLS指纹(例如使用curl-impersonate工具)。
结尾
在本文中,您学习了有关如何抓取受Cloudflare保护的网站的技巧和窍门。Cloudflare是市场上最流行的CDN服务,它还提供先进的反机器人解决方案。
如本文所示,绕过Cloudflare的反抓取措施具有挑战性,但并非不可能。借助专业、快速和可靠的抓取解决方案,一切都会变得更容易,例如:
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


