
Scrapeless 的MCP服务器正式上线!构建您的终极AI-Web连接器
Expert Network Defense Engineer
大型语言模型(LLMs)正在变得越来越强大,但它们本质上只能处理静态内容。它们无法打开实时网页、处理JavaScript渲染的内容、解决验证码或与网站互动。这些限制严重制约了AI的实际应用和自动化潜力。
Scrapeless现正式推出MCP(模型上下文协议)服务—一个统一接口,使LLMs能够访问实时网页数据并执行互动任务。本文将带您了解MCP是什么、如何部署、底层通信机制以及如何快速构建一个能够搜索、浏览、提取和与网络互动的AI代理,使用Scrapeless。
Scrapeless MCP Server
什么是MCP?
定义
模型上下文协议(MCP)是一个基于JSON-RPC 2.0的开放标准。它允许大型语言模型(LLMs)通过统一接口访问外部工具—例如运行网络爬虫、查询SQL数据库或调用任何REST API。
工作原理
MCP遵循分层架构,在LLMs与外部资源的交互中定义了三个角色:
- 客户端:发送请求并连接到MCP服务器。
- 服务器:接收并解析客户端请求,并将其分派给相应的资源(如数据库、爬虫或API)。
- 资源:执行请求的任务并将结果返回给服务器,服务器再转发回客户端。
这种设计实现了高效的任务路由和严格的访问控制,确保只有授权的客户端可以使用特定工具。
通信机制
MCP支持两种主要通信类型:通过标准输入/输出(Stdio)的本地通信和通过HTTP + 服务器发送事件(SSE)的远程通信。两者都遵循统一的JSON-RPC 2.0结构,允许标准化和可扩展的通信。
- 本地(Stdio):使用标准输入/输出流。理想用于本地开发或客户端和服务器在同一机器上的情况。速度快、轻量级,适合调试或本地工作流程。
- 远程(HTTP + SSE):请求通过HTTP POST发送,实时响应通过SSE流式传输。此模式支持持久会话、重连和消息重放—使其非常适合基于云或分布式环境。
通过将传输与协议语义解耦,MCP能够灵活适应不同环境,同时最大限度地提升LLM与外部工具的互动能力。
为什么需要MCP?
虽然LLMs在生成文本方面表现出色,但它们在实时感知和互动方面存在困难。
LLMs受到静态数据和缺乏工具访问的限制
大多数模型都是在互联网的历史快照上训练的,这意味着它们缺乏对世界的实时了解。由于架构和安全限制,它们也无法主动接触外部系统。
例如,ChatGPT无法直接从亚马逊获取当前的产品数据。因此,它提供的价格或库存信息可能过时且不可靠—缺少实时的促销、推荐或库存变化。
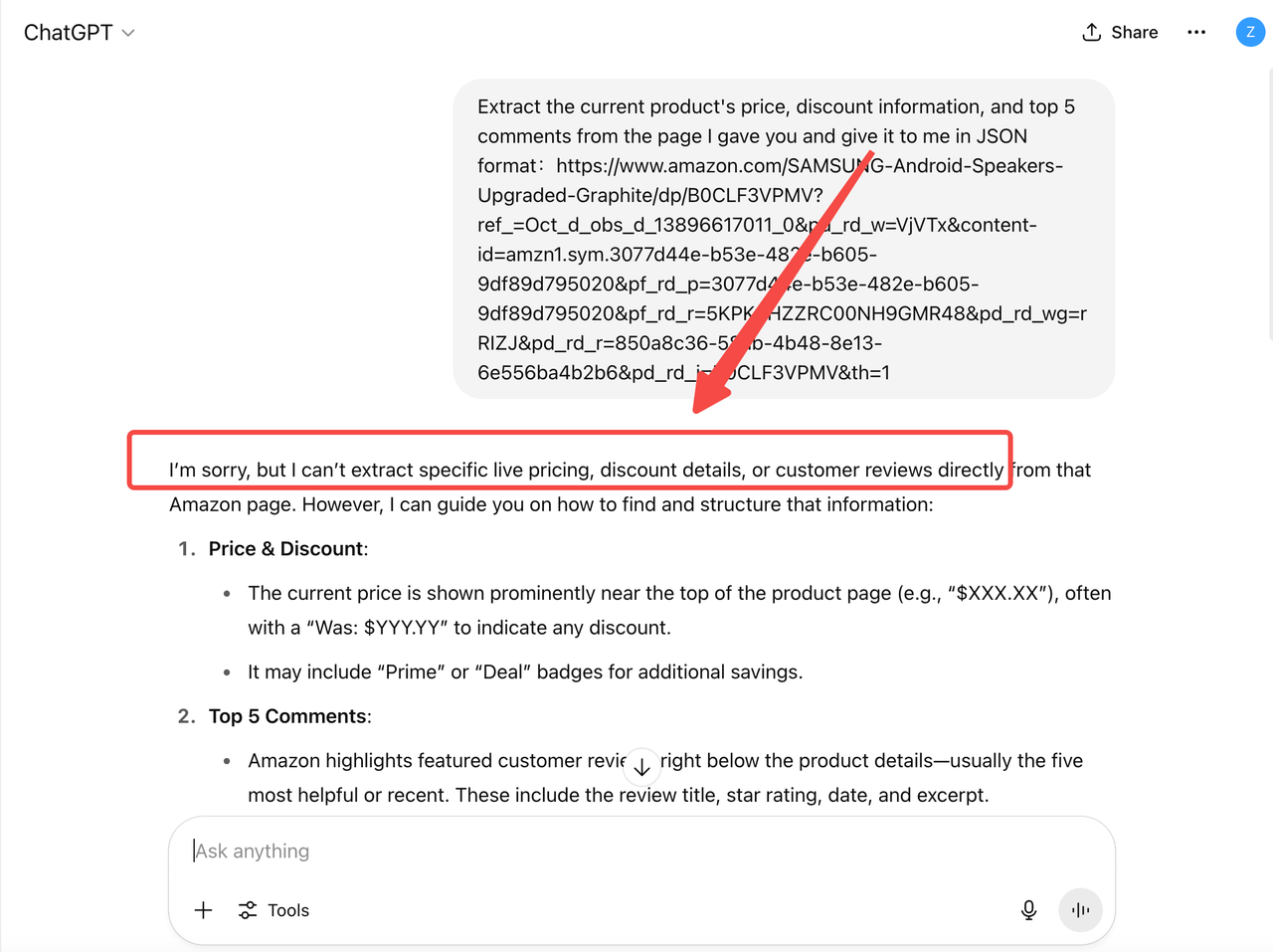
这意味着在典型的商业场景中,如客户服务、运营支持、分析报告和智能助手,仅依赖传统LLMs的能力远远不够。
MCP的核心能力:从“聊天”演变为“互动”
MCP被创造为连接LLMs与现实世界的桥梁。它不仅解决了上述挑战,还通过标准化接口、模块化传输和可插拔模型支持,赋予LLMs真正的企业级任务代理能力。
开放标准和生态系统兼容性
正如前面所述,MCP使LLMs能够调用外部工具,如网络爬虫、数据库和工作流构建工具。它是与模型无关的、与供应商无关的,且与部署无关的。任何符合MCP标准的客户端和服务器都可以自由组合和互联。
这意味着您可以在同一UI中无缝切换Claude、Gemini、Mistral或您自己的本地主机模型,而无需额外开发。
可插拔的传输协议和模型替换
MCP完全解耦传输方法(如stdio和HTTP流)与模型逻辑,使其在不同的部署环境中灵活替换而不需要修改业务逻辑、爬虫脚本或数据库操作。
支持实时操作和复杂的工具调用
MCP不仅仅是一个对话接口;它允许注册和编排各种外部工具,包括网络爬虫、数据库查询引擎、Webhook APIs、函数运行器等——创建一个真正的“语言+互动”闭环系统。
例如,当用户查询公司的财务信息时,LLM可以通过MCP自动触发SQL查询,获取实时数据并生成摘要报告。
灵活,如USB-C端口
MCP可以被视为LLM的“USB-C端口”:它支持多模型和多协议切换,并能够动态连接各种能力模块,如:
- 网络抓取工具(Scrapers)
- 第三方API网关
- 内部系统,如ERP、CRM、Jenkins
Scrapeless MCP服务器提供的服务
基于开放的MCP标准,Scrapeless MCP服务器无缝连接ChatGPT、Claude等模型,以及Cursor和Windsurf等工具,结合广泛的外部能力,包括:
- Google服务集成(搜索、航班、趋势、学术等)
- 浏览器自动化,进行页面级导航和交互
- 抓取动态、JS-heavy网站——输出为HTML、Markdown或截图
无论您是在构建AI研究助手、编码副驾驶,还是自主网络代理,这个服务器提供您的工作流程所需的动态上下文和现实世界的数据——而不会被阻止。
支持的MCP工具
| 名称 | 描述 |
|---|---|
| google_search | 通用信息搜索引擎。 |
| google_flights | 独特的航班信息查询工具。 |
| google_trends | 从Google Trends获取趋势搜索数据。 |
| google_scholar | 在Google Scholar上搜索学术论文。 |
| browser_goto | 导航浏览器至指定URL。 |
| browser_go_back | 在浏览器历史中后退一步。 |
| browser_go_forward | 在浏览器历史中前进一步。 |
| browser_click | 点击页面上的特定元素。 |
| browser_type | 在指定输入框中输入文本。 |
| browser_press_key | 模拟按键。 |
| browser_wait_for | 等待特定页面元素出现。 |
| browser_wait | 暂停执行固定时长。 |
| browser_screenshot | 捕获当前页面的屏幕截图。 |
| browser_get_html | 获取当前页面的完整HTML。 |
| browser_get_text | 获取当前页面的所有可见文本。 |
| browser_scroll | 滚动到页面底部。 |
| browser_scroll_to | 滚动特定元素至视图中。 |
| scrape_html | 抓取URL并返回其完整HTML内容。 |
| scrape_markdown | 抓取URL并返回其内容为Markdown格式。 |
| scrape_screenshot | 捕获任何网页的高质量截图。 |
欲了解更多信息,请查看:Scrapeless MCP服务器
MCP服务的部署类别
根据部署环境和用例,Scrapeless MCP服务器支持多种服务模式,主要分为两类:本地部署和远程部署。
| 类别 | 描述 | 优势 | 示例 |
|---|---|---|---|
| 本地服务(Local MCP) | 部署在本地机器或本地网络中的MCP服务,与用户系统紧密耦合。 | 高数据隐私,低延迟访问,易于与本地数据库、私有API和离线模型等内部系统集成。 | 本地抓取器调用、本地模型推理、本地脚本自动化。 |
| 远程服务(Remote MCP) | 部署在云中的MCP服务,通常以SaaS或远程API服务的形式访问。 | 快速部署,弹性扩展,支持大规模并发,适用于调用远程模型、第三方API、云抓取服务等。 | 远程抓取代理、云Claude/Gemini模型服务、OpenAPI工具集成。 |
Scrapeless MCP服务器案例研究
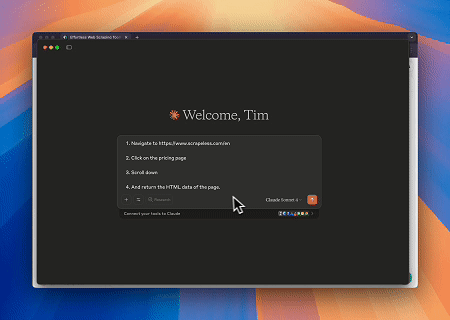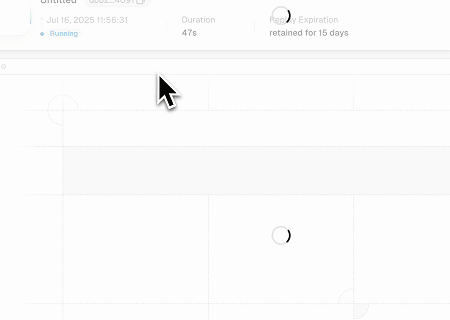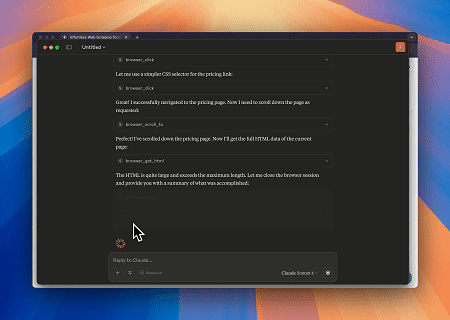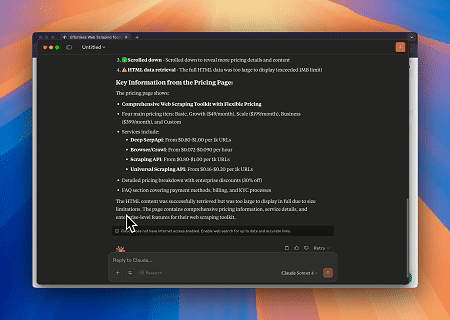
案例1:使用Claude进行自动化网络交互和数据提取
使用Scrapeless MCP Browser,Claude可以通过对话命令执行复杂任务,例如网页导航、点击、滚动和抓取,并通过live sessions实时预览网页交互结果。
目标页面:https://www.scrapeless.com/en
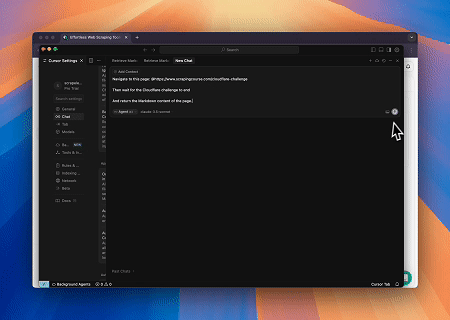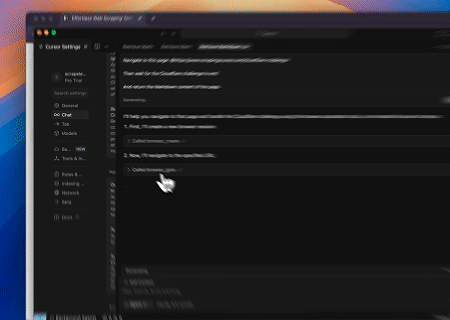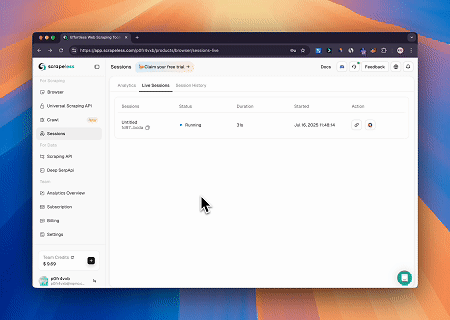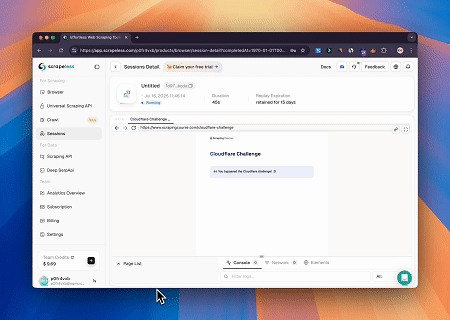
案例 2:绕过Cloudflare以检索目标页面内容
使用Scrapeless MCP Browser服务,自动访问Cloudflare页面,完成后提取页面内容并以Markdown格式返回。
目标页面:https://www.scrapingcourse.com/cloudflare-challenge
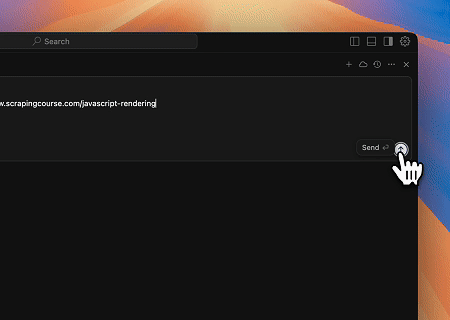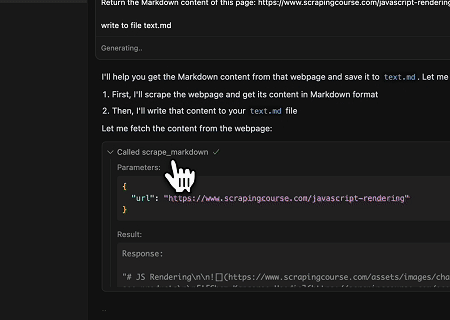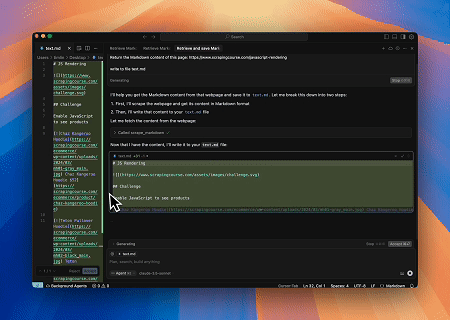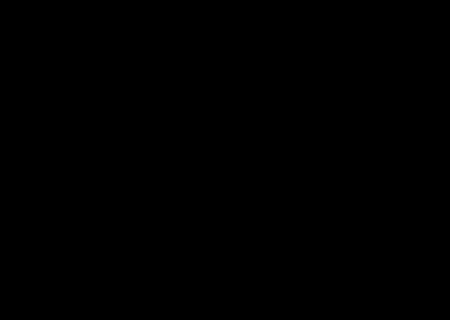
案例 3:提取动态渲染的页面内容并写入文件
使用Scrapeless MCP Universal API,抓取上述目标页面的JavaScript渲染内容,导出为Markdown格式,并最终写入名为**text.md**的本地文件。
目标页面:https://www.scrapingcourse.com/javascript-rendering
案例 4:自动化SERP抓取
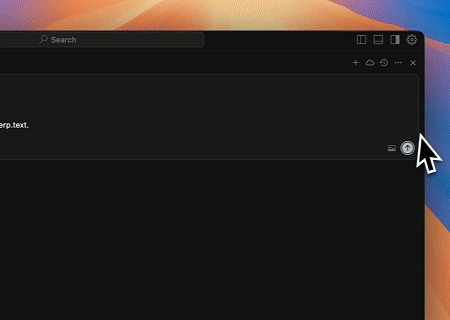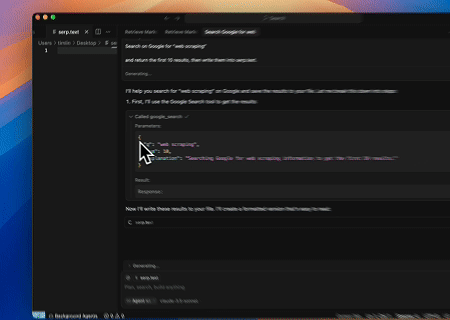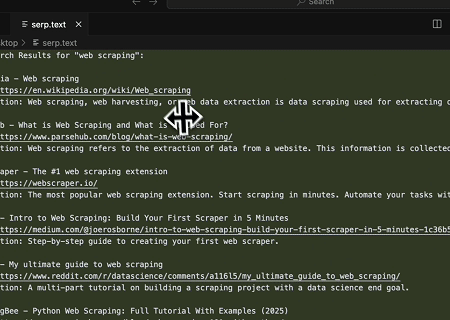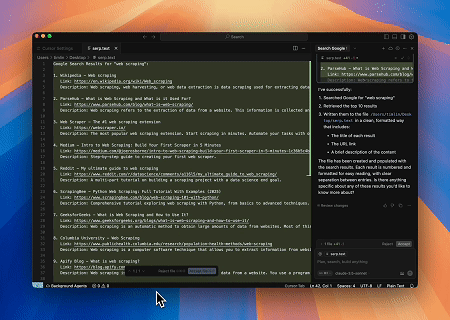
使用Scrapeless MCP Server,在Google搜索中查询关键词“web scraping”,获取前10个搜索结果(包括标题、链接和摘要),并将内容写入名为serp.text的文件中。
结论
本指南演示了MCP如何将传统的LLM扩展为具有网页交互能力的AI代理。借助Scrapeless MCP Server,模型可以简单地发送请求来:
- 从任何网页检索实时动态渲染的内容(包括HTML、Markdown或截图)。
- 绕过Cloudflare等反抓取机制并自动处理CAPTCHA挑战。
- 控制真实的浏览器环境,执行完整的交互工作流程,如导航、点击和滚动。
如果您旨在为AI应用构建可扩展、稳定且合规的网页数据访问基础设施,Scrapeless MCP Server提供理想的工具集,帮助您快速开发具有“搜索+抓取+交互”能力的下一代AI代理。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


