
如何通过无缝云浏览器增强 Crawl4AI
Expert Network Defense Engineer
在本教程中,您将学习:
- 什么是 Crawl4AI 以及它为网页抓取提供了什么
- 如何将 Crawl4AI 与 Scrapeless Browser 集成
我们开始吧!
第1部分:什么是 Crawl4AI?
概述
Crawl4AI 是一个开源网页爬虫和抓取工具,旨在与大型语言模型(LLMs)、AI 代理和数据管道无缝集成。它能够进行高速、实时的数据提取,同时保持灵活性和易于部署的特点。
AI 驱动的网页抓取 的主要特点包括:
- 为 LLM 量身打造: 生成针对检索增强生成(RAG)和微调优化的结构化 Markdown。
- 灵活的浏览器控制: 支持会话管理、代理使用和自定义钩子。
- 启发式智能: 使用智能算法优化 数据解析。
- 完全开源: 无需 API 密钥;可通过 Docker 和云平台进行部署。
在 官方文档 中了解更多信息。
使用案例
Crawl4AI 非常适合大规模数据提取任务,例如市场研究、新闻聚合和电子商务产品收集。它能够处理动态、重 JavaScript 的网站,并为 AI 代理和自动化数据管道提供可靠的数据源。
第2部分:什么是 Scrapeless Browser?
Scrapeless Browser 是一个基于云的无服务器浏览器自动化工具。它建立在深度定制的 Chromium 内核上,得到全球分布的服务器和代理网络的支持。这使用户能够无缝运行和管理多个无头浏览器实例,方便构建与网络大规模互动的 AI 应用和 AI 代理。
第3部分:为什么将 Scrapeless 与 Crawl4AI 结合使用?
Crawl4AI 在结构化网页数据提取方面表现出色,并支持 LLM 驱动的解析和基于模式的抓取。然而,在处理先进的反机器人机制时,它仍然可能面临挑战,例如:
- 本地浏览器被 Cloudflare、AWS WAF 或 reCAPTCHA 阻止
- 在大规模并发爬取时,浏览器启动缓慢导致性能瓶颈
- 复杂的调试过程使问题跟踪困难
Scrapeless Cloud Browser 解决了这些痛点:
- 一键反机器人绕过: 自动处理 reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF 等。结合 Crawl4AI 的结构化提取能力,显著提高成功率。
- 无限并发扩展: 在几秒钟内为每项任务启动 50–1000+ 个浏览器实例,消除本地爬虫性能限制,最大化 Crawl4AI 效率。
- 40%–80% 成本降低: 与类似的云服务相比,整体成本降至仅 20%–60%。按需付费定价使其即使对小规模项目也可承受。
- 可视化调试工具: 使用 Session Replay 和 Live URL Monitoring 实时查看 Crawl4AI 任务,快速识别失败原因,减少调试开销。
- 零成本集成: 天然兼容 Playwright(Crawl4AI 使用的),只需 一行代码 即可将 Crawl4AI 连接到云 — 无需代码重构。
- 边缘节点服务(ENS): 多个全球节点提供启动速度和稳定性比其他云浏览器快 2–3 倍,加速 Crawl4AI 执行。
- 隔离环境与持久会话: 每个 Scrapeless 配置文件在自己的环境中运行,保持登录和身份隔离,防止会话干扰,提高大规模稳定性。
- 灵活的指纹管理: Scrapeless 可以生成随机浏览器指纹或使用自定义配置,有效减少检测风险,提高 Crawl4AI 的成功率。
第4部分:如何在 Crawl4AI 中使用 Scrapeless?
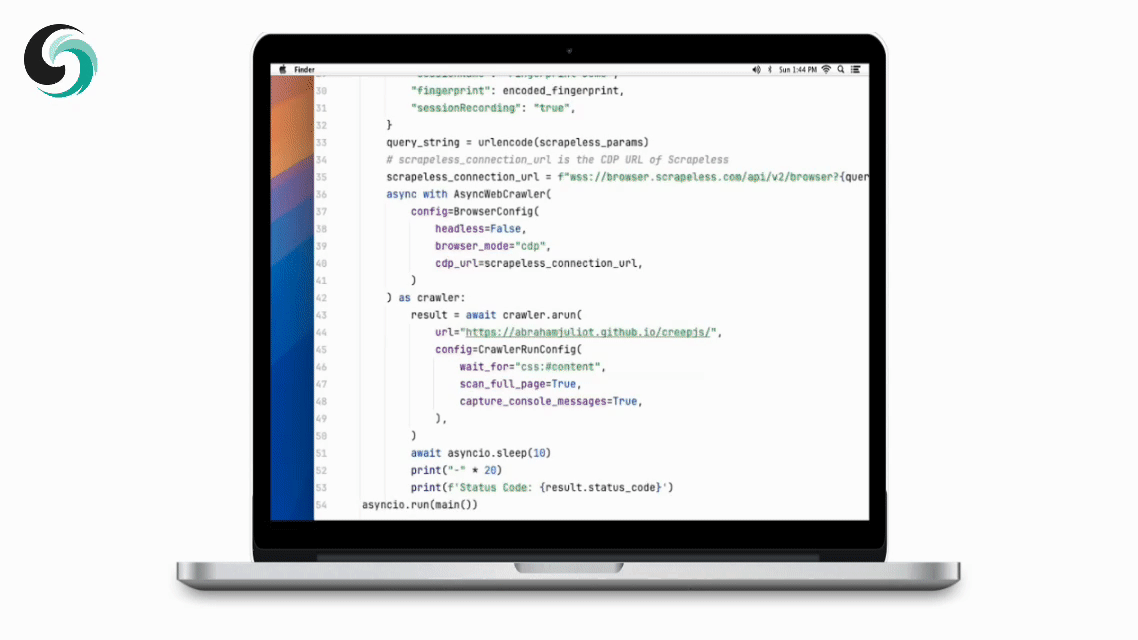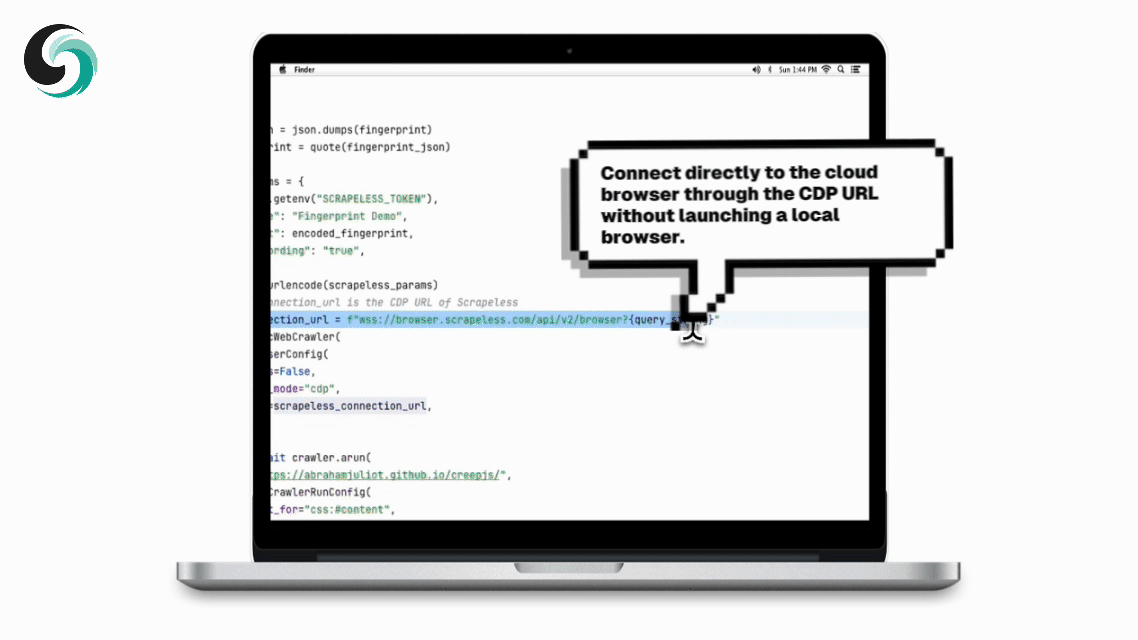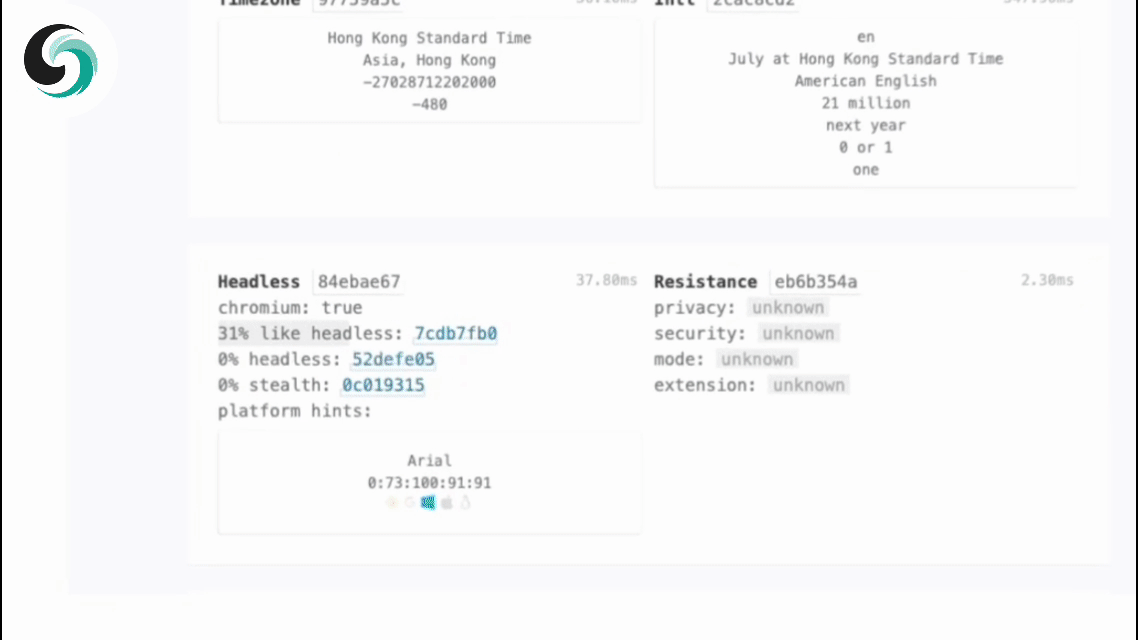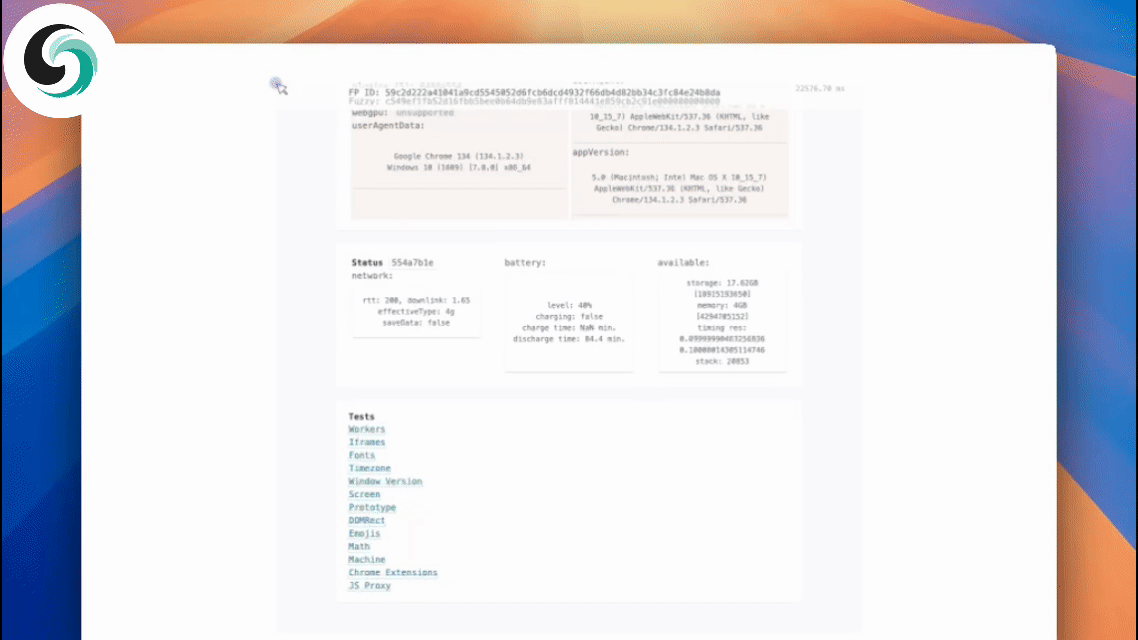
Scrapeless 提供的云浏览器服务通常返回一个 CDP_URL。Crawl4AI 可以直接使用此 URL 连接到云浏览器,无需在本地启动浏览器。
以下示例演示了如何无缝集成 Crawl4AI 与 Scrapeless Cloud Browser 以实现高效抓取,同时支持 自动代理轮换、自定义指纹和 配置文件重用。
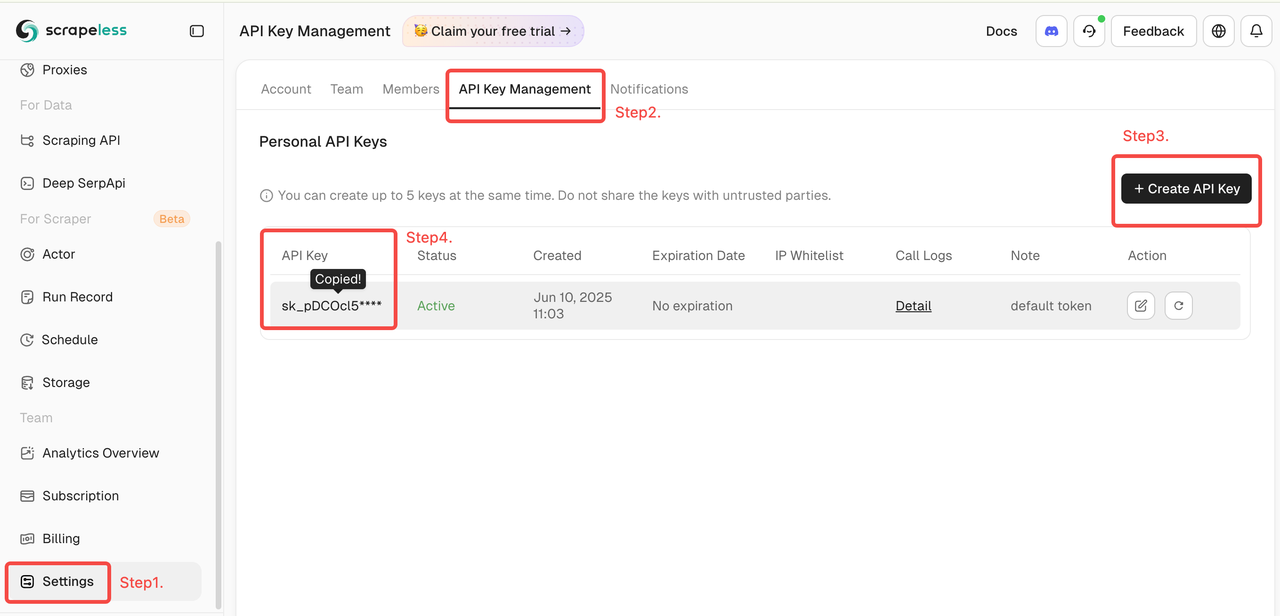
获取你的 Scrapeless 令牌
登录 Scrapeless并获取您的 API 令牌。
1. 快速开始
下面的示例展示了如何快速轻松地将Crawl4AI连接到Scrapeless云浏览器:
有关更多功能和详细说明,请参见介绍。
scrapeless_params = {
"token": "从 https://www.scrapeless.com 获取您的令牌",
"sessionName": "Scrapeless浏览器",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)配置完成后,Crawl4AI通过CDP(Chrome开发者工具协议)模式连接到Scrapeless云浏览器,无需本地浏览器环境即可进行网页抓取。用户还可以进一步配置代理、指纹、会话重用及其他功能,以满足高并发和复杂反机器人场景的需求。
2. 全球自动代理轮换
Scrapeless支持来自195个国家的住宅IP。用户可以使用proxycountry配置目标区域,使请求从特定位置发送。IP会自动轮换,有效避免封锁。
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "您的令牌",
"sessionTTL": 1000,
"sessionName": "代理演示",
# 设置代理的目标国家/地区,通过来自该地区的IP地址发送请求。您可以指定国家代码(例如,美国为US,英国为GB,ANY为任何国家)。查看国家代码以获取所有受支持的选项。
"proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'状态码: {result.status_code}')
print("-" * 20)
print(f'标题: {result.metadata["title"]}')
print(f'描述: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())3. 自定义浏览器指纹
为了模仿真实用户行为,Scrapeless支持随机生成的浏览器指纹,并允许自定义指纹参数。这有效降低了被目标网站检测的风险。
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# 自定义浏览器指纹
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "您的令牌",
"sessionTTL": 1000,
"sessionName": "指纹演示",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'状态码: {result.status_code}')
print("-" * 20)
print(f'标题: {result.metadata["title"]}')
print(f'描述: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())4. 配置重用
Scrapeless 为每个个人资料分配独立的浏览器环境,从而实现持久登录和身份隔离。用户只需提供 profileId 即可重用先前的会话。
python
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "你的令牌",
"sessionTTL": 1000,
"sessionName": "个人资料演示",
"profileId": "你的个人资料 ID", # 在 Scrapeless 上创建个人资料
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'状态代码: {result.status_code}')
print("-" * 20)
print(f'标题: {result.metadata["title"]}')
print(f'描述: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())视频
常见问题
问:我如何记录和查看浏览器执行过程?
答: 只需将 sessionRecording 参数设置为 "true"。整个浏览器执行过程将自动记录。在会话结束后,您可以在 会话历史记录 列表中重播和查看完整活动,包括点击、滚动、页面加载和其他细节。默认值为 "false"。
scrapeless_params = {
# ...
"sessionRecording": "true",
}问:我如何使用随机指纹?
答: Scrapeless 浏览器服务会为每个会话自动生成随机浏览器指纹。用户还可以使用 fingerprint 字段设置自定义指纹。
问:我如何设置自定义代理?
答: 我们内置的代理网络支持 195 个国家/地区。如果用户希望使用自己的代理,可以使用 proxyURL 参数指定代理 URL,例如:http://user:pass@ip:port。
(注意:自定义代理功能目前仅对企业和企业 Plus 订阅用户可用。)
scrapeless_params = {
# ...
"proxyURL": "proxyURL",
}总结
结合 Scrapeless 云浏览器与 Crawl4AI,开发人员可以获得稳定且可扩展的网络抓取环境:
- 无需安装或维护本地 Chrome 实例;所有任务均在云中直接运行。
- 降低被封禁和 CAPTCHA 中断的风险,因为每个会话都是隔离的,并支持随机或自定义指纹。
- 提高调试和可重现性,支持自动会话录制和回放。
- 支持在 195 个国家/地区 自动轮换代理。
- 利用全球 边缘节点服务,提供比其他类似服务更快的启动速度。
这一合作标志着 Scrapeless 和 Crawl4AI 在网络数据抓取领域的重要里程碑。展望未来,Scrapeless 将专注于云浏览器技术,为企业客户提供高效、可扩展的数据提取、自动化和 AI 代理基础设施支持。凭借强大的云能力,Scrapeless 将继续为金融、零售、电子商务、SEO 和营销等行业提供定制化和情景化的解决方案,帮助企业在数据智能时代实现真正的自动化增长。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


