
Raspagem Web com Python em 2025
Advanced Data Extraction Specialist
À medida que a necessidade de tomada de decisões baseada em dados continua crescendo, os desenvolvedores estão recorrendo à raspagem de dados na web com ferramentas Python como Beautiful Soup, Scrapy e Selenium para extrair informações de forma eficiente de páginas da web estáticas e dinâmicas. Neste tutorial passo a passo, você aprenderá como usar bibliotecas populares como Requests e Beautiful Soup para raspar os dados de que precisa.
O que é Web Scraping
Web scraping, em sua essência, é o processo de extração automática de grandes quantidades de dados de sites. Diferentemente dos métodos tradicionais de coleta de dados, a raspagem da web utiliza código para interagir com páginas da web, imitando como um humano navegará em um site, mas com muito mais eficiência e velocidade. Python, com seu rico ecossistema de bibliotecas como BeautifulSoup, Scrapy e Selenium, tornou-se uma das linguagens mais populares para raspagem da web devido à sua facilidade de uso e flexibilidade.
O objetivo principal da raspagem da web é converter dados da web não estruturados, frequentemente encontrados em formatos HTML ou JavaScript, em formatos estruturados como CSV, JSON ou bancos de dados, que podem então ser analisados ou integrados em vários aplicativos. Este processo é especialmente útil para indústrias como comércio eletrônico, finanças, pesquisa de mercado e SEO, onde a extração e análise de dados de concorrentes, o acompanhamento de tendências de preços ou a coleta de grandes conjuntos de dados são cruciais para a tomada de decisões.
Raspagem da Web com Python 101
A raspagem da web é uma habilidade essencial para extrair dados publicamente disponíveis da web, e Python é uma das linguagens mais populares para esse trabalho. Na raspagem da web com Python, você normalmente começa enviando solicitações HTTP para um site, recuperando o conteúdo HTML e, em seguida, analisando-o para extrair os dados desejados.
Aqui estão as etapas básicas envolvidas:
1. Enviando Solicitações
Para começar a raspar, você primeiro precisa enviar uma solicitação ao site de destino. Isso é comumente feito usando a biblioteca Requests em Python, que faz solicitações HTTP para servidores web.
import requests
url = 'https://example.com'
response = requests.get(url)
print(response.content)2. Analisando os Dados
Depois de recuperar a página da web, a próxima etapa é analisar o conteúdo HTML para extrair dados relevantes.
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.string
print(title)3. Lidando com Conteúdo Dinâmico
Muitos sites modernos dependem de JavaScript para carregar conteúdo dinamicamente, o que significa que os dados que você deseja podem não aparecer na fonte HTML inicial. Para esses casos, o Selenium é uma ótima ferramenta, pois simula um navegador real e pode interagir com páginas dinâmicas.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com')
content = driver.page_sourceCom essas poucas etapas, você poderá iniciar a raspagem básica da web. Em seguida, daremos uma introdução detalhada: Como raspar um site usando Python (passo a passo)
Como raspar um site usando Python (passo a passo)
Para criar uma ferramenta de raspagem de dados usando Python, você precisa baixar e instalar as seguintes ferramentas.
-
Python: https://www.python.org/downloads/ Este é o software principal para executar Python. Você pode baixar a versão que precisamos do site oficial, como mostrado na figura abaixo. No entanto, é recomendável não baixar a versão mais recente. Você pode baixar 1-2 versões anteriores à versão mais recente.
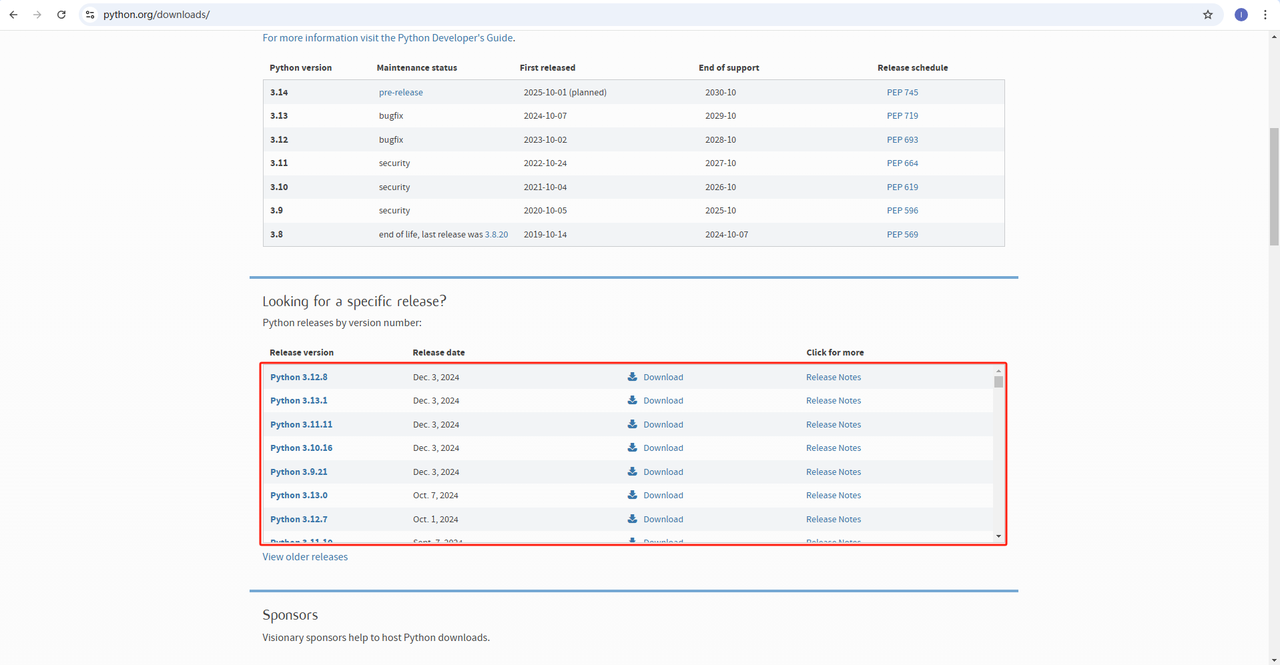
-
IDE Python: Qualquer IDE que suporte Python servirá, mas recomendamos o PyCharm, uma ferramenta de desenvolvimento IDE projetada especificamente para Python. Para a versão PyCharm, recomendamos a edição gratuita PyCharm Community Edition.
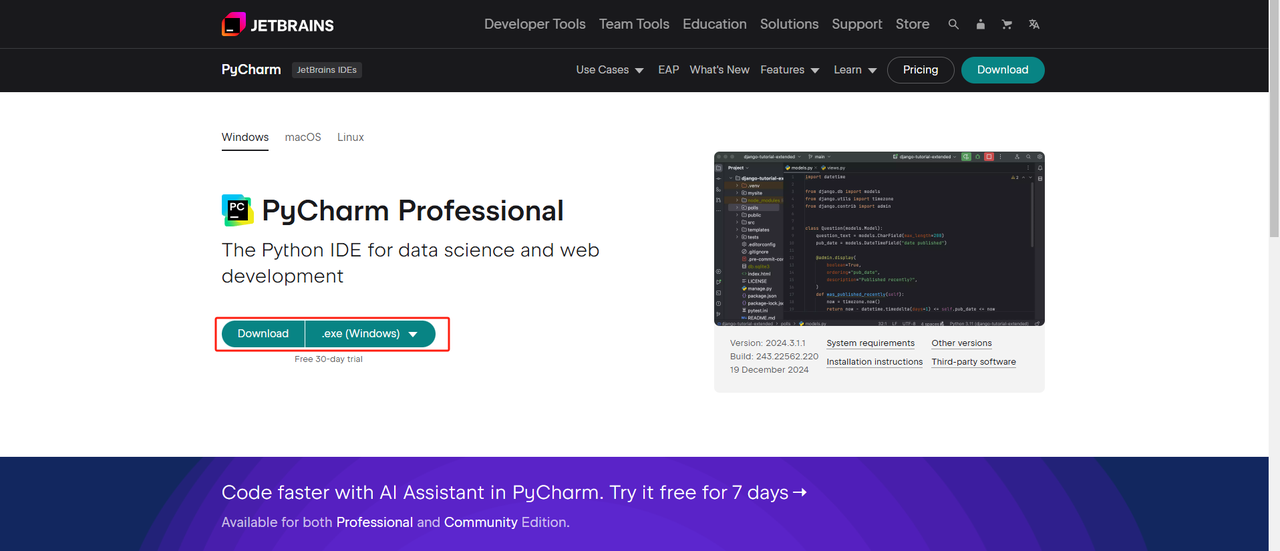
-
Pip: Você pode usar o Python Package Index para instalar as bibliotecas necessárias para executar seu programa com um único comando.
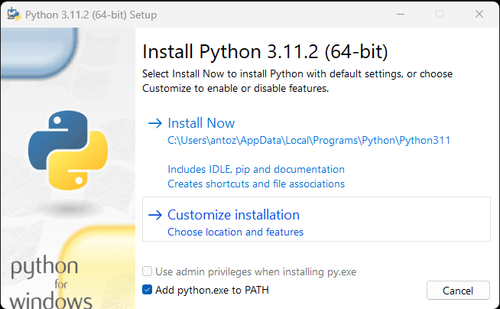
Observação: Se você é um usuário do Windows, não se esqueça de marcar a opção "Adicionar python.exe ao PATH" no assistente de instalação. Isso permitirá que o Windows use o Python e os comandos no terminal. Como o Python 3.4 ou posterior o inclui por padrão, você não precisa instalá-lo manualmente.
Por meio das etapas acima, o ambiente para rastrear dados usando Python foi configurado. Em seguida, podemos usar o PyCharm que instalamos para rastrear dados no site.
Etapa 1: Inicie o PyCharm e selecione Arquivo > Novo Projeto... na barra de menu.
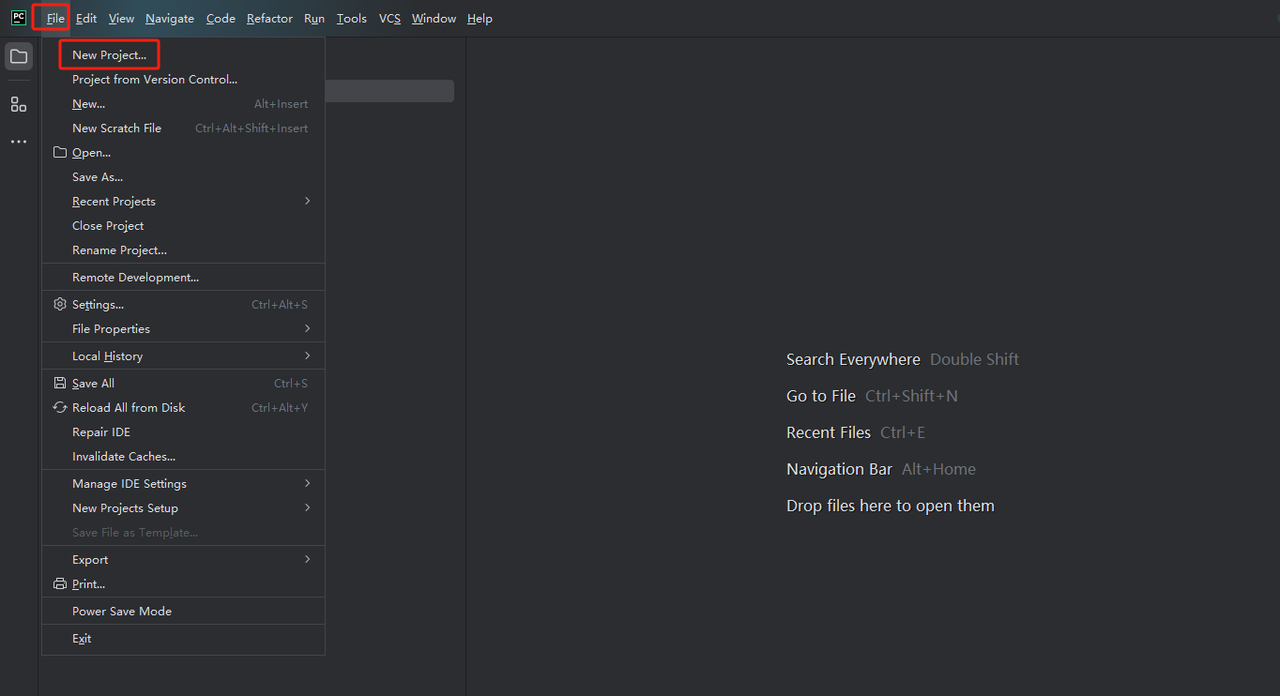
Etapa 2: Em seguida, na janela pop-up, selecione Pure Python no menu à esquerda e configure seu projeto como mostrado abaixo:
Observação: Na caixa vermelha abaixo, selecione o caminho de instalação do Python que você baixou na primeira etapa da configuração do ambiente.
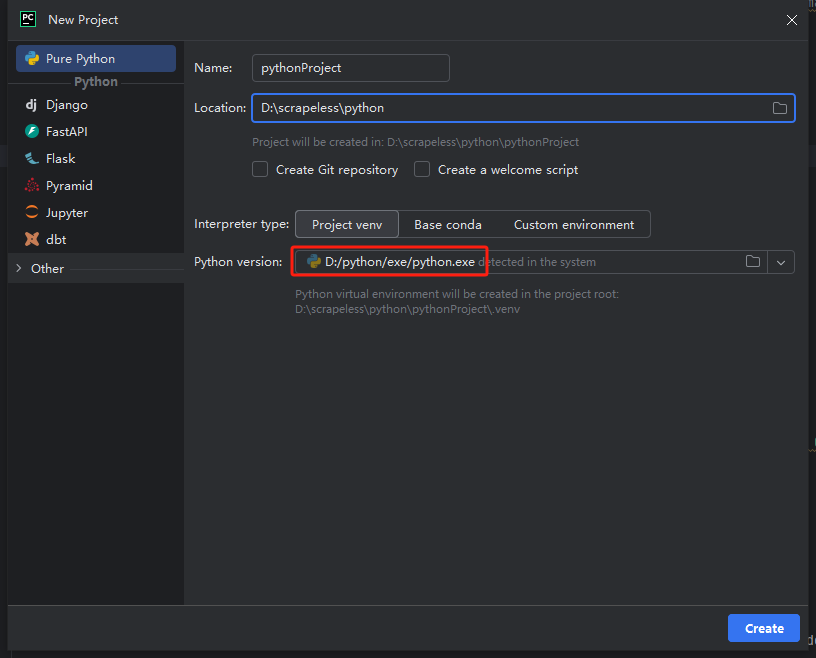
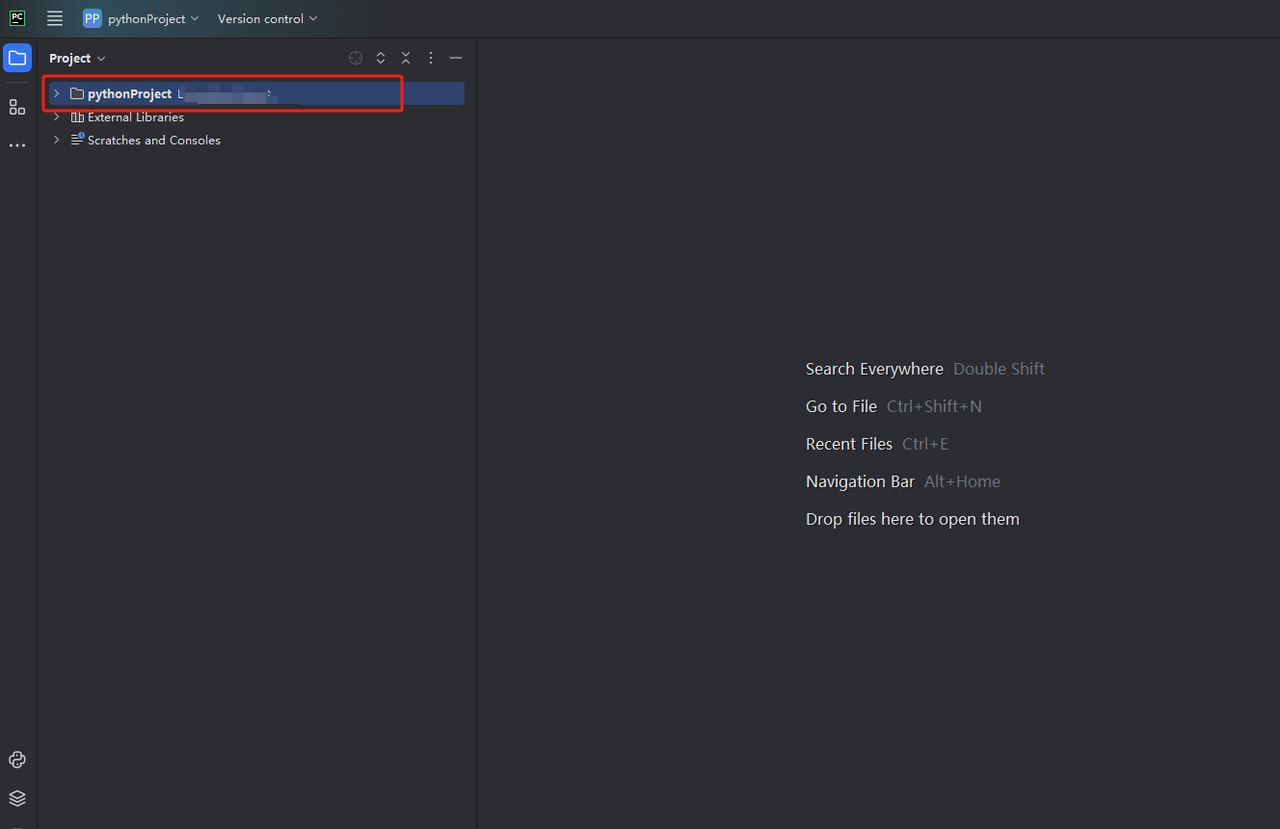
Etapa 3: Você pode criar um projeto chamado python-scraper, marque a opção para criar um script de boas-vindas main.py na pasta e clique no botão Criar. Depois de algum tempo do PyCharm configurando o projeto, você deve ver algo assim:
Etapa 4: Em seguida, clique com o botão direito para criar um novo arquivo Python.
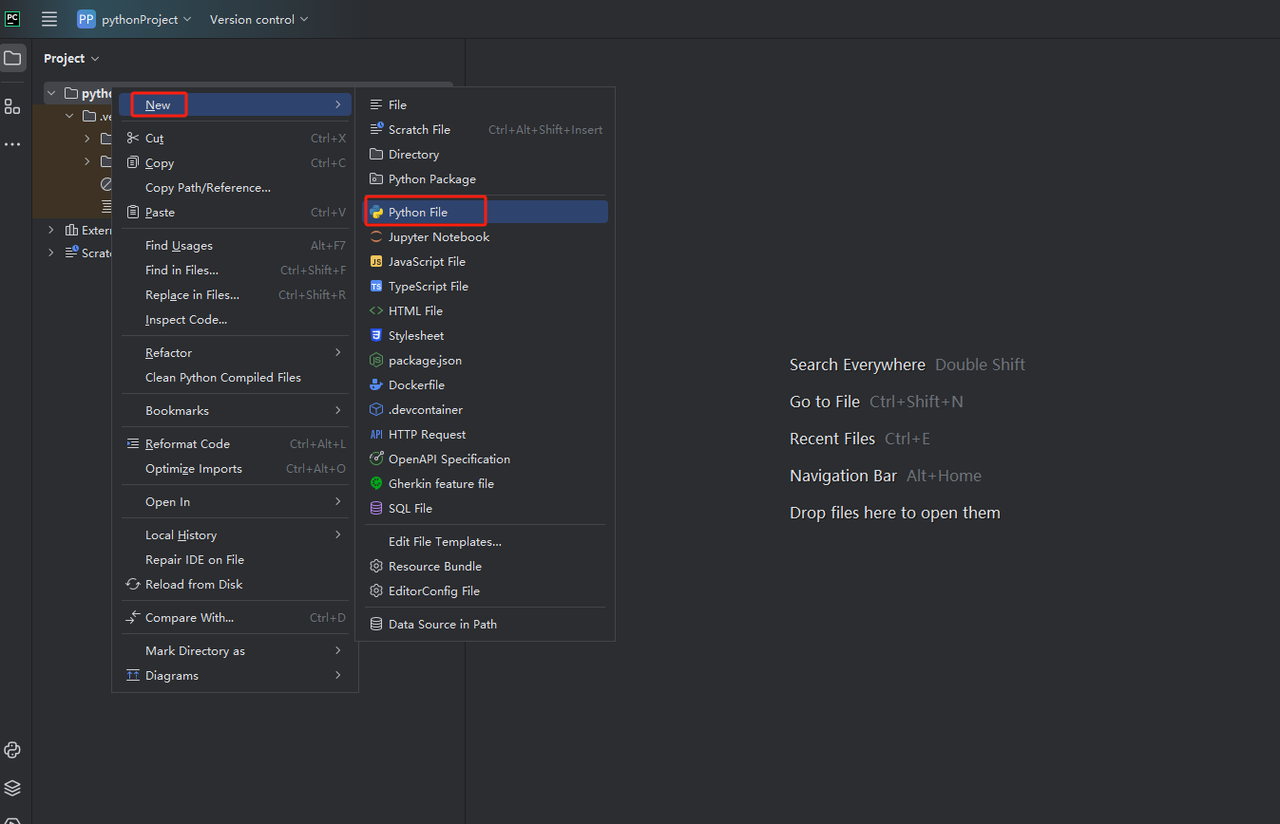
Atualmente, nosso ambiente para rastrear dados foi configurado. A próxima etapa é como rastrear os dados que precisamos na página da web.
1. Antes de realmente rastrear dados, primeiro precisamos fazer alguns trabalhos preliminares, como entender a URL, observar parâmetros etc., e podemos usar as ferramentas de desenvolvedor integradas do navegador para aprender e praticar esses pontos. Vamos usar a Amazon como exemplo para rastrear o preço de um determinado produto e alguns outros dados de que precisamos.
https://www.amazon.com/s?k=computer&page=3
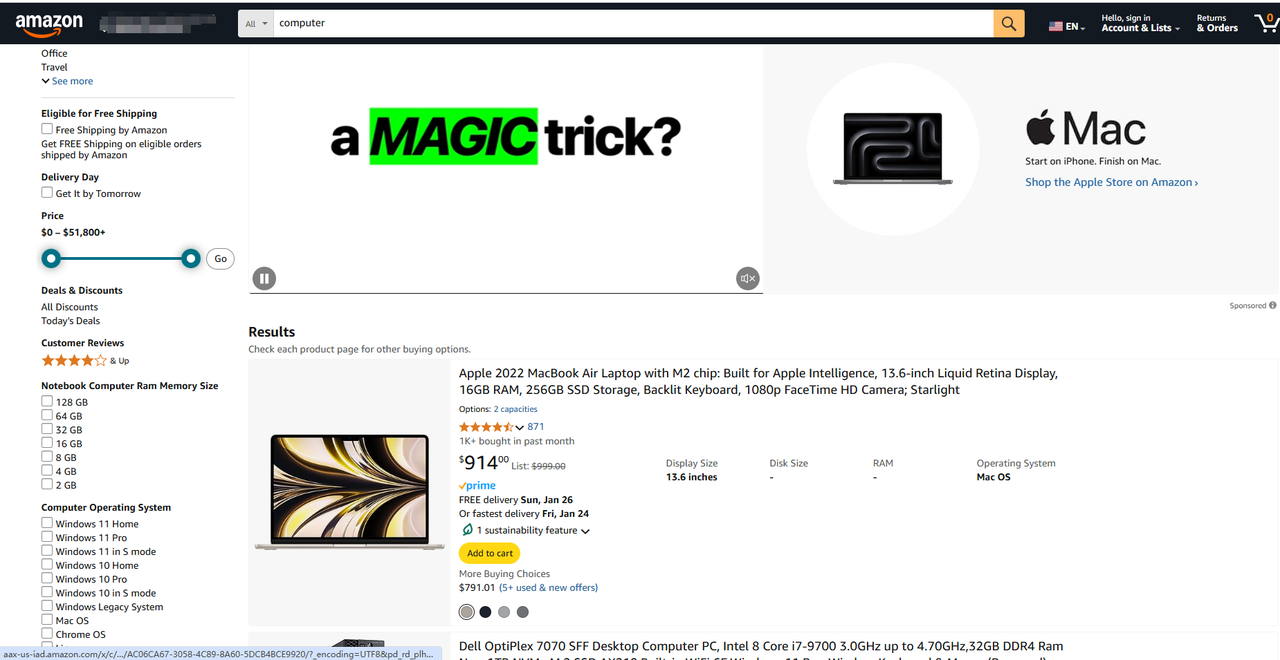
Você pode decompor qualquer um deles em duas partes principais:
- URL base: O caminho para a parte da loja do site. Aqui é https://www.amazon.com/s?k=computer&page=3.
- Localização específica da página: O caminho para um produto específico. A URL pode terminar em .html, .php ou não ter nenhuma extensão.
A URL base é a mesma para todos os produtos do site. A diferença entre cada página é a segunda metade da URL, que contém uma string que especifica qual página do produto o servidor deve retornar. Normalmente, as URLs para o mesmo tipo de página têm um formato semelhante em geral.
Além disso, as URLs também podem conter informações extras:
- Parâmetros de caminho: Esses são usados para capturar valores específicos em métodos RESTful (por exemplo, em https://www.example.com/users/14, 14 é um parâmetro de caminho).
- Parâmetros de consulta: Esses são adicionados ao final da URL após o ponto de interrogação (?). Eles geralmente codificam os valores de filtro a serem enviados ao servidor ao realizar uma pesquisa (por exemplo, em https://www.example.com/search?search=blabla&sort=newest, search=blabla e sort=newest são parâmetros de consulta).
Observe que qualquer string de parâmetro de consulta contém o seguinte: - ?: Isso marca o início.
- key=value Uma lista de parâmetros separados por &: key é o nome de um parâmetro, enquanto value mostra seu valor. A string de consulta contém parâmetros em pares chave-valor separados por caracteres &.
Em outras palavras, as URLs são mais do que apenas strings de localização simples de documentos HTML. Elas também podem conter informações de parâmetros que o servidor pode usar para executar consultas e preencher páginas com dados específicos.
No exemplo, 3 é o parâmetro de caminho e cpmputer é o valor da consulta de pesquisa. Essa URL instruirá o servidor a executar uma consulta de pesquisa paginada e obter todos os resultados contendo a string cpmputer e, em seguida, retornar apenas os resultados da terceira página.
2. Agora você está familiarizado com o site. A próxima etapa é aprofundar-se no código HTML da página, estudando sua estrutura e conteúdo para entender como extrair dados dele.
Todos os navegadores modernos vêm com um conjunto de ferramentas de desenvolvimento avançadas, e a maioria oferece a mesma funcionalidade. Essas ferramentas permitem que você explore o código HTML de uma página da web e trabalhe com ele. Neste tutorial de raspagem da web em Python, você verá o DevTools do Chrome em ação.
Clique com o botão direito em um elemento HTML e selecione Inspecionar para abrir a janela DevTools. Se o menu de clique com o botão direito estiver desativado para um site, faça o seguinte:
- No macOS: Exibir > Desenvolvedor > Selecionar Ferramentas do Desenvolvedor na barra de menu.
- No Windows e Linux: Clique no botão de menu ⋮ no canto superior direito e selecione a opção Mais Ferramentas > Ferramentas do desenvolvedor.
Eles permitem que você inspecione a estrutura do Modelo de Objeto de Documento (DOM) de uma página da web. Isso, por sua vez, pode ajudá-lo a ter uma compreensão mais profunda do código-fonte. Na seção DevTools, insira a opção Elementos para acessar o DOM.
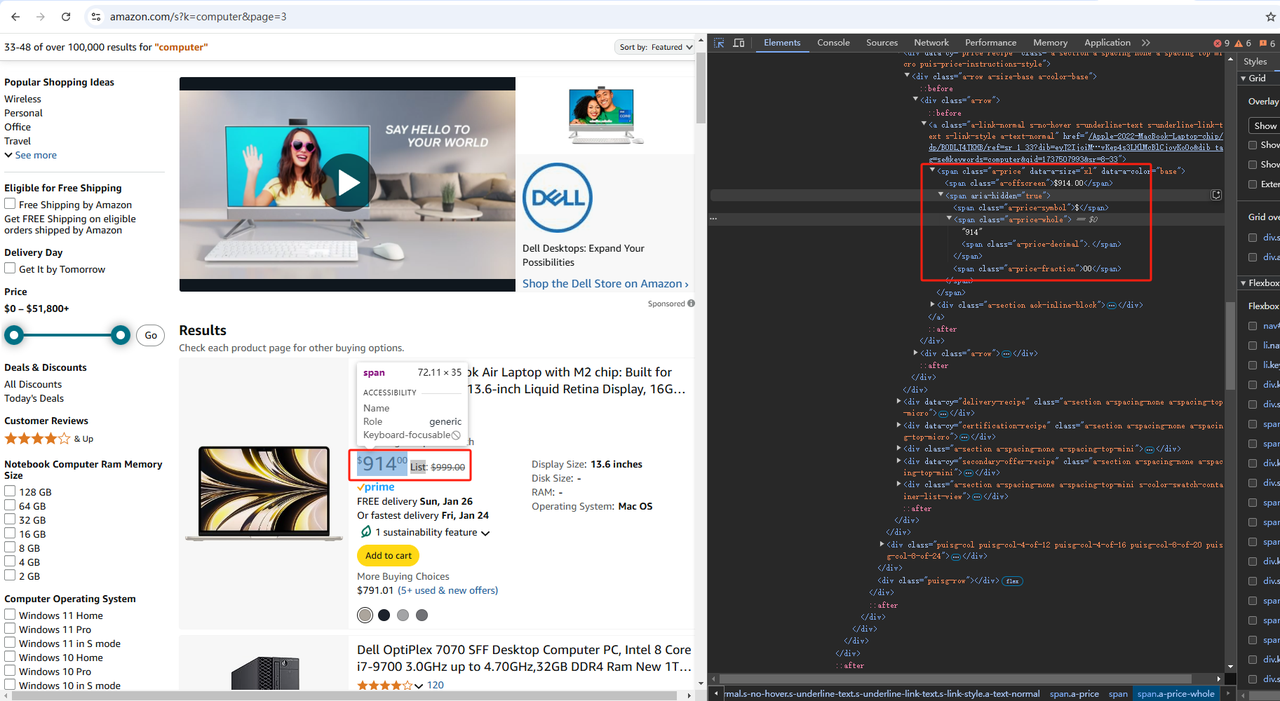
Na Amazon, depois de abrir as ferramentas do desenvolvedor, clicamos em "Elementos", como mostrado na figura acima, e então usamos a seta no lado esquerdo de "Elementos" para clicar em qualquer lugar da página onde queremos obter os dados. Dessa forma, a localização dos dados que precisamos será exibida no código-fonte HTML em "Elementos". Então podemos rastrear dados de acordo com a tag onde está localizado.
Se você achar difícil entender a diferença entre DOM e HTML:
- O código HTML representa o conteúdo do documento da web escrito pelo desenvolvedor.
- O DOM é uma representação de memória dinâmica do código HTML criada pelo navegador. Em JavaScript, você pode manipular o DOM da página para alterar seu conteúdo, estrutura e estilo.
3. Suponha que você queira rastrear dados do seguinte local:
Exemplo
https://www.amazon.com/s?k=computer&page=3
Primeiro, você precisa recuperar o código HTML da página de destino. Em outras palavras, você deve baixar o documento HTML associado à URL da página. Para fazer isso, use a biblioteca requests do Python.
Na guia Terminal do seu projeto PyCharm, execute o seguinte comando para instalar requests:
Terminal
pip install requestsAbra o arquivo scraper.py e inicialize-o com a seguinte linha de código:
scrape.py
import requests# download the HTML document# with an HTTP GET request
response = requests.get("https://www.amazon.com/s?k=computer&page=3")# print the HTML codeprint(response.text)Este trecho de código importa as dependências requests. Em seguida, ele usa a função get() para executar uma solicitação HTTP GET para a URL da página de destino e retorna uma representação Python da resposta contendo um documento HTML.
Você também pode obter o código completo da solicitação Python colando a URL da solicitação da página diretamente aqui: https://curlconverter.com/python/
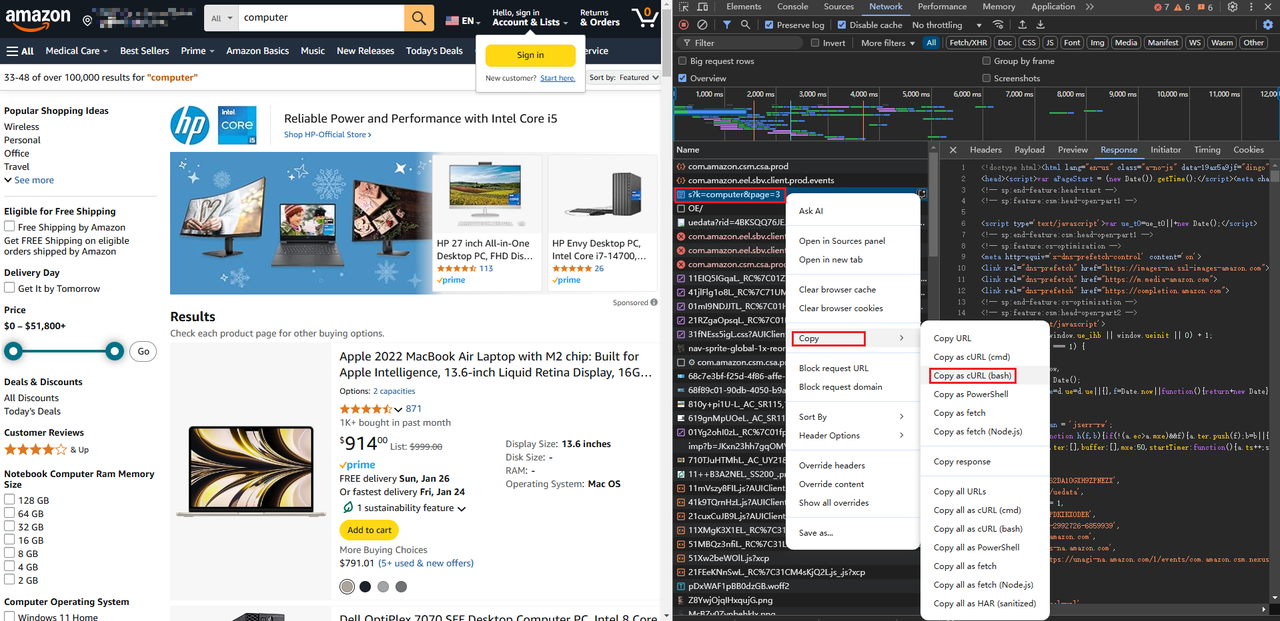
import requests
cookies = {
'session-id': '140-2992726-6859939',
'session-id-time': '2082787201l',
'i18n-prefs': 'USD',
'ubid-main': '132-6184525-8448226',
'lc-main': 'en_US',
'skin': 'noskin',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'no-cache',
'device-memory': '8',
'downlink': '1.5',
'dpr': '1',
'ect': '3g',
'pragma': 'no-cache',
'priority': 'u=0, i',
'rtt': '300',
'sec-ch-device-memory': '8',
'sec-ch-dpr': '1',
'sec-ch-ua': '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-ch-ua-platform-version': '"10.0.0"',
'sec-ch-viewport-width': '1070',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'viewport-width': '1070',
}
params = {
'k': 'computer',
'page': '3',
}
response = requests.get('https://www.amazon.com/s', params=params, cookies=cookies, headers=headers)
print(response.text)No Pycharm, adicione print(response.text) no final do código. Após executar o código, você obterá um código de página HTML como mostrado abaixo.
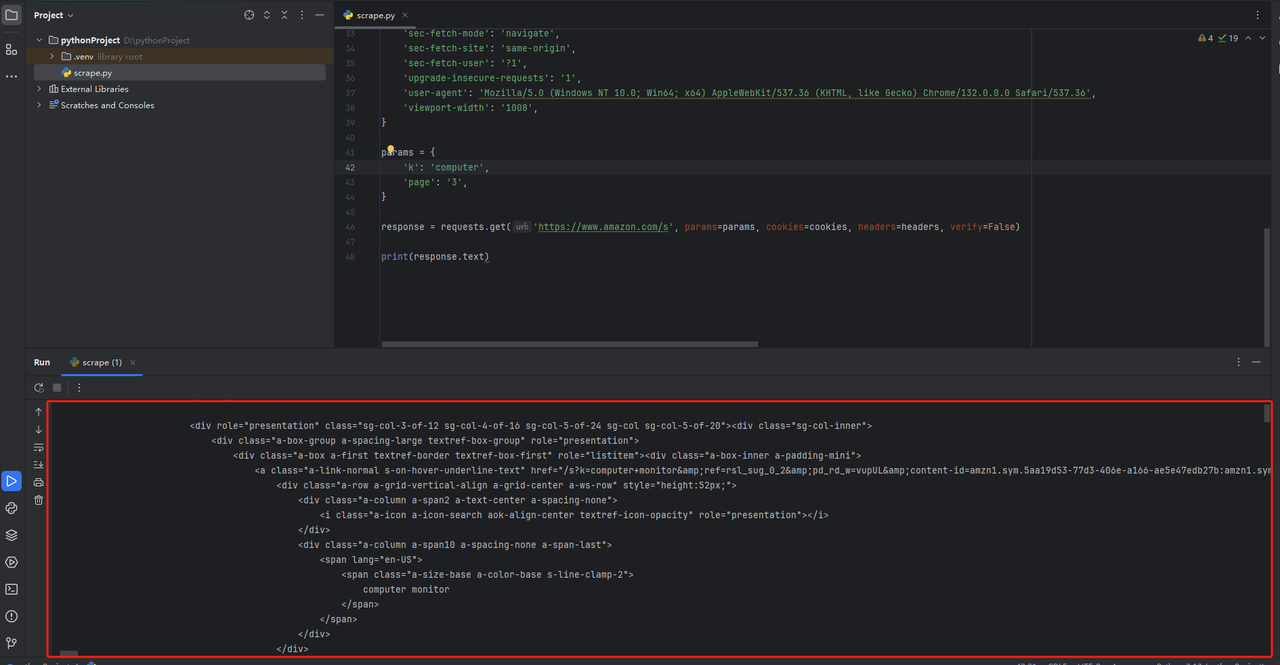
⚠️ Erro Comum: Esquecer a Lógica de Tratamento de Erros!
Uma solicitação GET para um servidor pode falhar por vários motivos. O servidor pode estar temporariamente indisponível, a URL pode estar incorreta ou seu IP pode ter sido bloqueado. Portanto, você pode querer lidar com o erro da seguinte maneira:
response = requests.get("https://www.amazon.com/s?k=computer&page=3")
se a resposta for 2xx
if response.ok:lógica de raspagem aqui...
else:registrar a resposta de erro
em caso de 4xx ou 5xx
print(response)
Dessa forma, o script não travará se houver um erro na solicitação e continuará sendo executado apenas em uma resposta 2xx.
4. Analise o conteúdo HTML com Beautiful Soup
Na etapa anterior, você recuperou um documento HTML do servidor. Se você olhar para ele, verá uma longa sequência de código e a única maneira de entendê-lo é extrair os dados necessários por meio da análise HTML.
Beautiful Soup é uma biblioteca Python para analisar conteúdo XML e HTML, que expõe uma API para explorar o código HTML. Em outras palavras, permite que você selecione elementos HTML e extraia dados deles facilmente.
Para instalar a biblioteca, execute o seguinte comando no seu terminal:
pip install beautifulsoup4Em seguida, use-o para analisar o conteúdo das solicitações recuperadas dessa maneira:
import requests
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
# download the target page
response = requests.get("https://www.amazon.com/s?k=computer&page=3")
# parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")O construtor BeautifulSoup() aceita algum conteúdo e uma string especificando o analisador a ser usado. "html.parser" instrui o Beautiful Soup a usar o analisador HTML.
⚠️ Erro comum: Passando response.text em vez de response.content para BeautifulSoup().
Os atributos do objeto de conteúdo mantêm os dados HTML na forma de bytes brutos da resposta, que são mais fáceis de decodificar do que a representação de texto armazenada no atributo de texto. Para evitar problemas de codificação de caracteres, é melhor usar response.content.
response.textBeautifulSoup()
Deve-se notar que os sites contêm dados em muitos formatos. Elementos únicos, listas e tabelas são apenas alguns exemplos. Se você quiser que sua ferramenta de raspagem Python seja eficaz, precisa saber como usar o Beautiful Soup em muitas situações.
Como mostrado na figura abaixo, nos dados que pesquisamos, se quisermos obter as informações de dados de um determinado produto, podemos precisar analisá-lo camada por camada da tag pai e, em seguida, obter o preço, o nome do produto etc.
[Imagem]
O Beautiful Soup fornece uma variedade de métodos para selecionar elementos HTML do DOM, entre os quais o campo id é o método mais eficaz para selecionar um único elemento. Como o nome sugere, o campo id identifica exclusivamente o nó HTML na página. Mas isso também depende do design da página HMTL do site que queremos rastrear. Se não houver id, podemos precisar obter os dados de que precisamos por meio do conteúdo que seja o mais exclusivo possível.
O atributo data-asin na figura acima representa o código exclusivo do produto. Ao combiná-lo com o atributo role, podemos obter o código no HMTL correspondente a este produto:
target_div = soup.find('div', attrs={'data-asin': 'B0DJXW94BL', 'role': 'listitem'})Se você tiver uma tag com um id, poderá escrever um código como este:
product_search_element = soup.find(id="woocommerce-product-search-field-0")Usamos "find()" para encontrar tags para obter os dados desejados. O uso detalhado do método "find()" é o seguinte:
- Por tag: Use a função find() sem parâmetros:
# get the first <h1> element on the page
h1_element = soup.find("h1")- Por classe: find() via parâmetro class_
# find the first element on the page with "search_field" class
search_input_element = soup.find(class_="search_field")- Por atributos: find() via parâmetro attrs
# find the first element on the page with the name="s" HTML attribute
search_input_element = soup.find(attrs={"name": "s"})Você também pode recuperar nós HTML usando seletores CSS e select(): select_one()
# find the first element identified by the "input.search-field" CSS selector
search_input_element = soup.select_one("input.search-field")Em um elemento HTML de conteúdo de texto, extraia seu texto usando o método get_text():
h1_title = soup.select_one(".beta.site-title").getText()
print(h1_title)⚠️ Erro comum: Não verificar se é None.
Quando find() e select_one() não conseguem encontrar o elemento desejado, eles retornam None. Como as páginas mudam com o tempo, você deve sempre executar uma verificação não-None, assim:
product_search_element = soup.find(id="woocommerce-product-search-field-0")
#making sure product_search_element is present on the pagebefore trying to access its data
if product_search_element is not None:
placeholder_string = product_search_element["placeholder"]O exemplo acima nos permite encontrar o código HTML de um determinado produto. Se quisermos retornar dados mais precisos, como o título do produto, podemos usar o mesmo método para primeiro encontrar a tag onde o título do produto está localizado e, em seguida, obtê-lo da subtag das informações do produto que acabamos de obter.
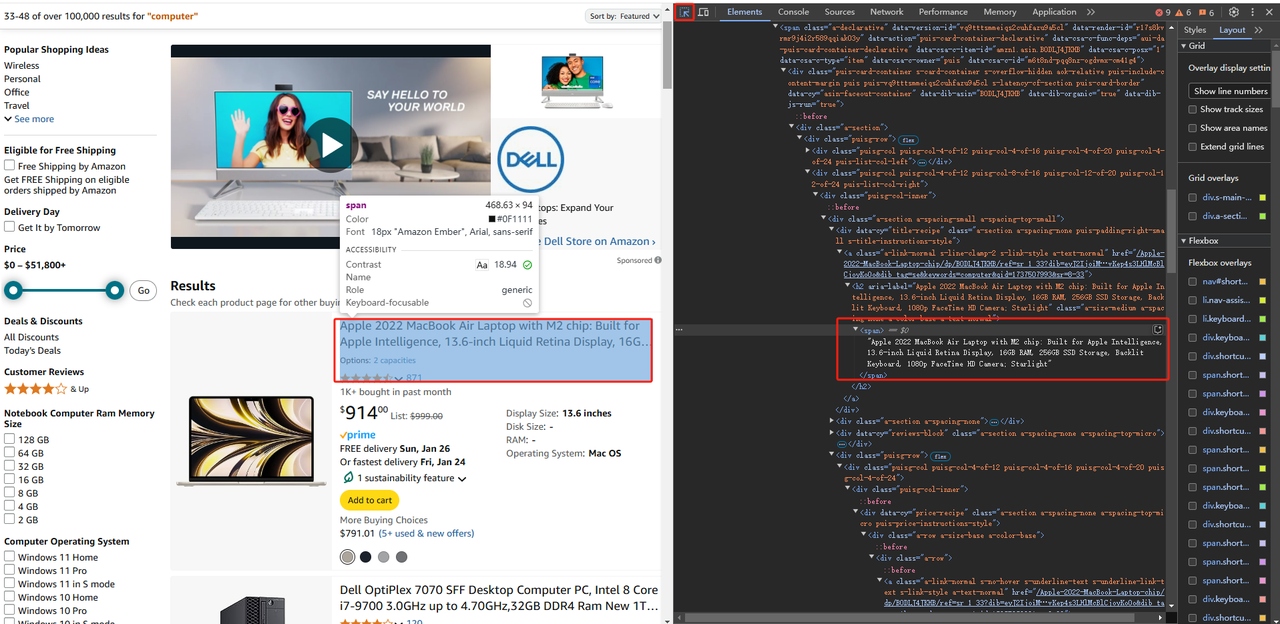
Observando que o título do produto está na tag "span", você pode obter os dados do texto do título obtendo a tag "span" abaixo da tag "h2" abaixo da tag "a":
if target_div:
a_tags = target_div.find_all('a')
for a_tag in a_tags:
h2_tag = a_tag.find('h2')
if h2_tag:
span_tag = h2_tag.find('span')
if span_tag:
print(span_tag.get_text())
else:
print("No matching div found.")Nota: Pode haver vários elementos de tag "a", "h2" e outros semelhantes em diferentes páginas da web, portanto, é melhor usar alguns atributos de tag relativamente exclusivos para obter dados ao usá-los.
O acima é uma pequena demonstração de como usar Python para rastrear dados de páginas da web. Se você quiser ser mais proficiente e obter dados relevantes com mais precisão, pode precisar de muita prática, caso contrário, pode apenas perder nosso próprio tempo.
Uma recomendação de método de rastreamento mais simples: Scrapeless Scraping API
Embora a raspagem com Python seja um método flexível e poderoso, geralmente requer a escrita de muito código e o tratamento de detalhes técnicos complexos. Para aqueles que desejam simplificar o processo de raspagem, a Scrapeless Scraping API fornece uma solução mais conveniente.
-
🚀 Por meio de funções impulsionadas por IA, o Scrapeless permite que os usuários extraiam dados públicos facilmente sem escrever código complexo ou lidar com problemas como proxy e gerenciamento de IP.
-
🌍 Se você precisa acessar mais de 80 milhões de IPs reais ou IPs de data center privados, o Scrapeless pode fornecer serviços de raspagem de dados eficientes e confiáveis.
-
⚡ Sua interface de API simples torna a integração muito fácil, e os usuários podem iniciar rapidamente tarefas de raspagem com configuração simples, economizando muito tempo e esforço de desenvolvimento.
Para usuários que desejam evitar a complexidade dos métodos de raspagem tradicionais, o Scrapeless é, sem dúvida, uma opção mais conveniente que vale a pena recomendar.
Como usar a Scrapeless Scraping API para extração de dados:
Etapa 1. Faça login no Scrapeless Dashboard e vá para "Amazon".
Etapa 2. De acordo com seus requisitos de raspagem, insira a URL correspondente e defina a Ação correspondente, depois clique em Iniciar Raspagem.
Etapa 3. Obtenha os resultados de rastreamento e exporte-os.
Você também pode precisar de:
Como raspar dados do Google Trends com Python?
Como usar o BeautifulSoup para raspagem da web em Python
Como raspar dados do resultado da pesquisa da Amazon: Guia Python 2025
Integre o Scrapeless perfeitamente ao seu projeto
Se você precisar integrar o Scrapeless ao seu projeto, também poderá clicar para visualizar a documentação completa.
Produto
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Vendedor
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Palavras-chave
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Melhores práticas para raspagem da web com Python
A raspagem da web com Python requer um equilíbrio entre eficiência, ética e conformidade legal. Aqui estão algumas melhores práticas para projetos de raspagem da web em Python:
1. Respeite os termos de serviço de um site e os arquivos robots.txt
Um dos aspectos mais importantes da raspagem da web é respeitar os termos de serviço de um site e os arquivos robots.txt. Sempre verifique esses arquivos antes de raspar para garantir que você não está violando as regras do site. Isso ajuda você a evitar problemas legais e garante que suas atividades de raspagem estejam em conformidade com as diretrizes do site.
2. Minimize a carga no servidor do site
Outra melhor prática é minimizar a carga no servidor do site. Raspar dados de forma muito agressiva pode sobrecarregar o servidor, afetando negativamente o desempenho do site e podendo resultar em bloqueio. Ao usar ferramentas de raspagem da web em Python, implemente técnicas como limitação de taxa e atraso de rastreamento para garantir que suas atividades de raspagem não causem interrupções.
3. Certifique-se de que os dados que você coleta são tratados de forma ética e segura
Por fim, certifique-se de que os dados que você coleta são tratados de forma ética e segura. A privacidade de dados é mais importante do que nunca, e respeitar a privacidade dos usuários cujos dados você coleta é fundamental. A adoção de práticas éticas de raspagem da web em Python não apenas manterá suas operações em conformidade, mas também construirá confiança na indústria. Certifique-se de armazenar e processar os dados de forma segura, cumprindo regulamentos de privacidade como o GDPR.
Técnicas Avançadas de Raspagem da Web
À medida que os sites se tornam mais dinâmicos e a tecnologia anti-raspagem continua a se atualizar, a tecnologia de raspagem da web em 2025 exige que os desenvolvedores dominem uma série de habilidades avançadas para garantir a eficiência ao lidar com desafios legais e éticos. Aqui estão algumas técnicas avançadas para raspagem da web moderna:
- Use tecnologia de simulação e automação de navegador
Muitos sites agora usam tecnologia de automação de navegador para melhorar a experiência do usuário, o que também traz novos desafios para a raspagem de dados. Por exemplo, simulando o comportamento do usuário para contornar certas medidas anti-raspagem. Usar ferramentas de automação de navegador como Puppeteer ou Playwright pode simular interações do usuário, o que é particularmente útil para rastrear conteúdo que requer interação (como códigos de verificação ou processos de login). Comparado com métodos tradicionais de raspagem de web estática, essa tecnologia pode lidar melhor com a complexidade dos sites modernos.
- Aproveitar pools de proxy e rotação de IP
Em projetos de raspagem em larga escala, evitar ser bloqueado pelo site de destino é um desafio antigo. Para evitar o bloqueio de IP, os desenvolvedores geralmente usam pools de proxy para contornar os mecanismos anti-raspagem, rotando vários IPs. Usar uma plataforma de automação como Scrapeless pode ajudar a gerenciar um grande número de proxies, reduzir o risco de IPs bloqueados e garantir a estabilidade da raspagem de dados.
- Extração inteligente de dados impulsionada por IA
A inteligência artificial está impulsionando a tecnologia de raspagem de dados. A IA não só pode ajudar a identificar e extrair pontos de dados específicos, mas também identificar imagens, texto e dados estruturados em páginas complexas. Algoritmos de aprendizado de máquina podem ser usados para reconhecimento de imagem e análise de sentimento para melhorar a precisão e a exatidão da raspagem.
- Usar APIs para melhorar a eficiência da raspagem
Para muitas empresas, usar APIs de crawler profissionais é uma maneira eficiente de simplificar o processo de raspagem de dados. APIs como Scrapeless podem fornecer poderosos recursos de gerenciamento de proxy, contorno de CAPTCHA e rotação de IP, o que pode reduzir efetivamente a carga de gerenciamento manual, aumentando a taxa de sucesso da raspagem de dados.
Em resumo, a tecnologia de raspagem da web em 2025 precisará combinar ferramentas de raspagem tradicionais com tecnologias mais avançadas para lidar com os desafios de sites dinâmicos, extração de dados em larga escala e tecnologias anti-raspagem. Usar soluções de API como Scrapeless pode tornar o processo de raspagem mais eficiente, confiável e escalável, ajudando os desenvolvedores a economizar tempo e reduzir a dificuldade técnica.
Raspagem da Web com Scrapeless -- em apenas 3 minutos
Não se preocupe mais com configurações complicadas e medidas anti-raspagem. Com o Scrapeless, você pode facilmente gerenciar proxies, contornar CAPTCHAs e escalar seus projetos de raspagem com facilidade. Comece a experimentar uma extração de dados mais confiável, rápida e segura do que nunca. Experimente o Scrapeless hoje e leve sua raspagem da web para o próximo nível!
FAQs sobre Raspagem da Web com Python
1. A raspagem da web é legal?
A legalidade da raspagem da web depende de vários fatores, incluindo os termos de serviço do site e as leis locais. É crucial revisar o arquivo robots.txt de um site e sua política de uso aceitável antes de raspar para garantir a conformidade. Raspagem não autorizada pode levar a consequências legais, por isso é melhor abordá-la eticamente.
Além disso, o uso de ferramentas como Scrapeless garante a conformidade com os padrões éticos e legais durante a raspagem.
2. Quais são os principais desafios na raspagem da web?
A raspagem da web pode apresentar vários desafios, incluindo lidar com medidas anti-raspagem como CAPTCHAs, bloqueio de IP e carregamento de conteúdo dinâmico. Os sites também podem ter estruturas complexas que dificultam a extração de dados.
3. Como lidar com CAPTCHA ao raspar sites?
Muitos sites usam CAPTCHA para evitar a raspagem automatizada. Para contornar o CAPTCHA, você pode integrar serviços de resolução de CAPTCHA ou usar ferramentas como Selenium para imitar o comportamento humano. No entanto, para uma experiência mais simplificada, plataformas como Scrapeless costumam fornecer recursos para gerenciar CAPTCHA automaticamente, reduzindo a complexidade de raspar esses sites.
Conclusão: Raspagem da Web com Python
À medida que a demanda por raspagem da web explode, a raspagem da web com Python continua sendo um dos meios mais importantes.
No entanto, à medida que a raspagem se torna cada vez mais complexa devido a medidas anti-bot mais avançadas, a necessidade de soluções mais inteligentes e eficientes é óbvia. É aqui que ferramentas como Scrapeless entram em jogo. Ao utilizar a API de raspagem de ponta do Scrapeless, você pode otimizar o processo de raspagem, contornar CAPTCHAs e evitar obstáculos comuns que normalmente retardam a codificação manual. Com o Scrapeless, você pode escalar seus projetos de raspagem com o mínimo de esforço, mantendo alta precisão de dados.
Não deixe que os desafios de raspagem o impeçam - explore o Scrapeless hoje e leve sua raspagem da web para o próximo nível.
Quer simplificar seu processo de raspagem da web?
Comece com o Scrapeless hoje! Aproveite uma avaliação gratuita e descubra como nossas ferramentas poderosas podem economizar seu tempo e esforço. Nenhuma habilidade de codificação necessária — apenas raspagem eficiente e sem complicações!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


