
Como aprimorar o Crawl4AI com o Scrapeless Cloud Browser
Specialist in Anti-Bot Strategies
Neste tutorial, você aprenderá:
- O que é o Crawl4AI e o que ele oferece para raspagem de dados da web
- Como integrar o Crawl4AI com o Navegador Scrapeless
Vamos começar!
Parte 1: O Que É o Crawl4AI?
Visão Geral
Crawl4AI é uma ferramenta de rastreamento e raspagem da web de código aberto projetada para se integrar perfeitamente com Modelos de Linguagem de Grande Escala (LLMs), Agentes de IA e pipelines de dados. Ela permite a extração de dados em alta velocidade e em tempo real, mantendo-se flexível e fácil de implantar.
Principais recursos para raspagem de dados da web com IA incluem:
- Construído para LLMs: Gera Markdown estruturado otimizado para Geração Aumentada por Recuperação (RAG) e ajuste fino.
- Controle flexível do navegador: Suporta gerenciamento de sessão, uso de proxy e ganchos personalizados.
- Inteligência heurística: Usa algoritmos inteligentes para otimizar análise de dados.
- Totalmente de código aberto: Sem necessidade de chave de API; implantável via Docker e plataformas de nuvem.
Saiba mais na documentação oficial.
Casos de Uso
O Crawl4AI é ideal para tarefas de extração de dados em larga escala, como pesquisa de mercado, agregação de notícias e coleta de produtos de e-commerce. Ele pode lidar com sites dinâmicos e pesados em JavaScript e serve como uma fonte de dados confiável para agentes de IA e pipelines de dados automatizados.
Parte 2: O Que É o Navegador Scrapeless?
O Navegador Scrapeless é uma ferramenta de automação de navegador sem servidor baseada em nuvem. Ele é construído em um núcleo Chromium profundamente personalizado, suportado por servidores distribuídos globalmente e redes de proxy. Isso permite que os usuários executem e gerenciem perfeitamente numerosas instâncias de navegador headless, facilitando a criação de aplicações de IA e Agentes de IA que interagem com a web em escala.
Parte 3: Por Que Combinar Scrapeless com Crawl4AI?
O Crawl4AI se destaca na extração estruturada de dados da web e suporta raspagem baseada em padrões e parsing dirigido por LLM. No entanto, ainda pode enfrentar desafios ao lidar com mecanismos avançados de anti-bot, como:
- Navegadores locais sendo bloqueados por Cloudflare, AWS WAF ou reCAPTCHA
- Gargalos de desempenho durante a raspagem concorrente em larga escala, com inicialização lenta do navegador
- Processos de depuração complexos que dificultam o rastreamento de problemas
O Scrapeless Cloud Browser resolve esses pontos problemáticos perfeitamente:
- Bypass anti-bot com um clique: Lida automaticamente com reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF e mais. Combinado com o poder de extração estruturada do Crawl4AI, aumenta significativamente as taxas de sucesso.
- Escalabilidade concorrente ilimitada: Lança 50–1000+ instâncias de navegador por tarefa em segundos, removendo os limites de desempenho de raspagem local e maximizando a eficiência do Crawl4AI.
- Redução de custo de 40%–80%: Comparado a serviços em nuvem similares, os custos totais caem para apenas 20%–60%. A precificação pay-as-you-go torna acessível até mesmo para projetos de pequena escala.
- Ferramentas de depuração visual: Use Repetição de Sessão e Monitoramento de URL ao Vivo para assistir às tarefas do Crawl4AI em tempo real, identificar rapidamente as causas das falhas e reduzir a sobrecarga de depuração.
- Integração sem custo: Compatível nativamente com Playwright (usado pelo Crawl4AI), exigindo apenas uma linha de código para conectar o Crawl4AI à nuvem — sem necessidade de refatoração de código.
- Serviço de Nó de Borda (ENS): Múltiplos nós globais oferecem velocidade de inicialização e estabilidade 2–3× mais rápidos do que outros navegadores em nuvem, acelerando a execução do Crawl4AI.
- Ambientes isolados e sessões persistentes: Cada perfil Scrapeless roda em seu próprio ambiente com login persistente e isolamento de identidade, prevenindo interferência entre sessões e melhorando a estabilidade em larga escala.
- Gerenciamento flexível de impressões digitais: O Scrapeless pode gerar impressões digitais de navegador aleatórias ou usar configurações personalizadas, reduzindo efetivamente os riscos de detecção e melhorando a taxa de sucesso do Crawl4AI.
Parte 4: Como Usar o Scrapeless no Crawl4AI?
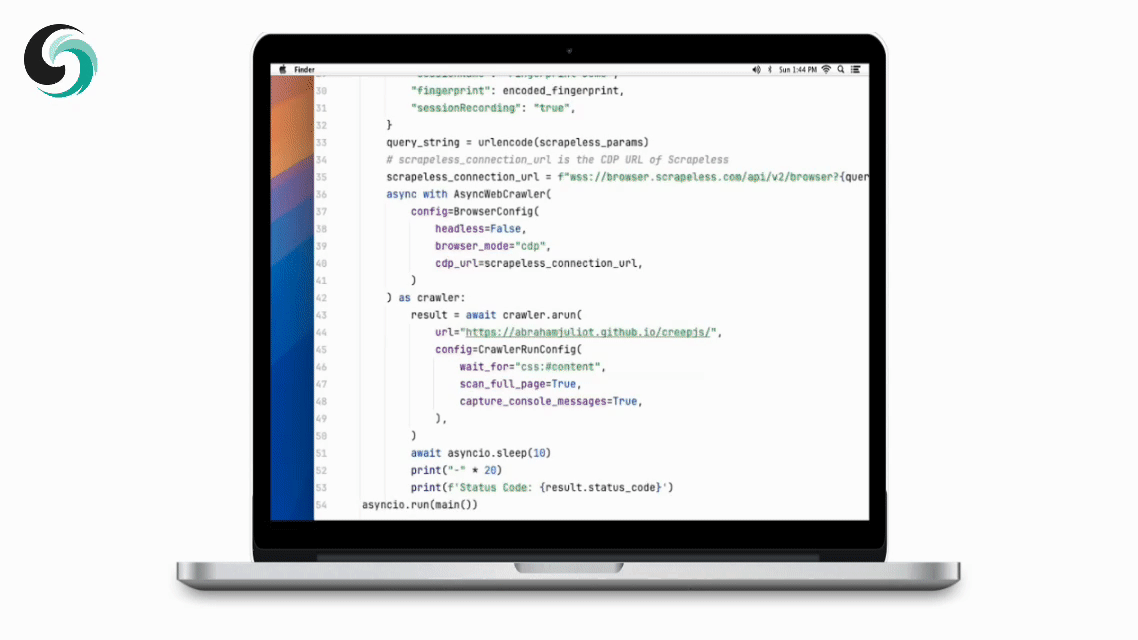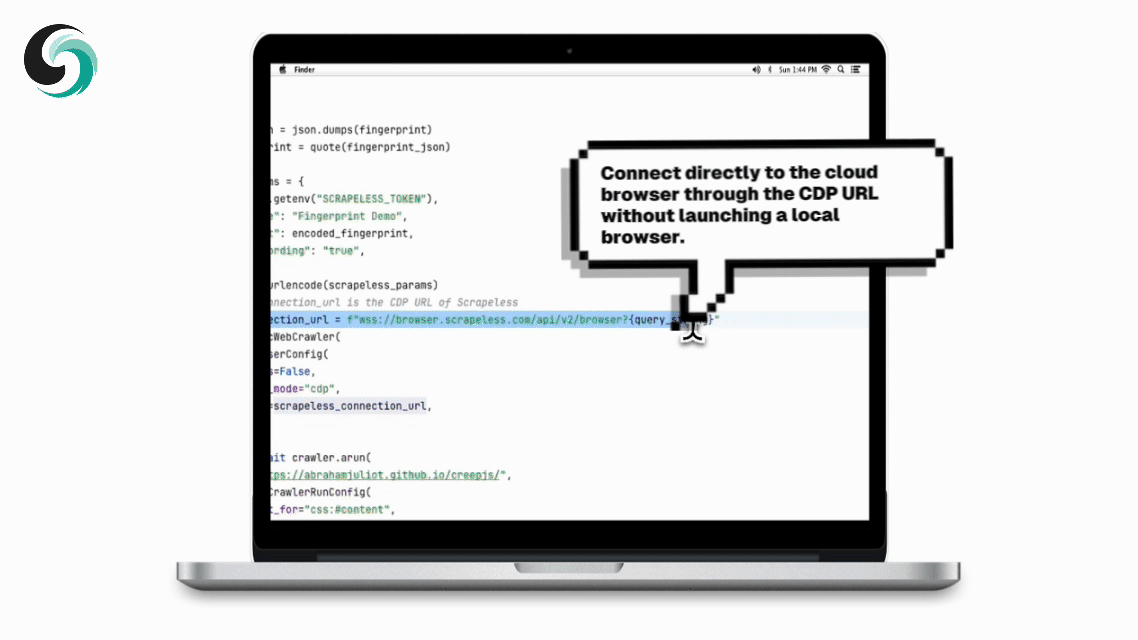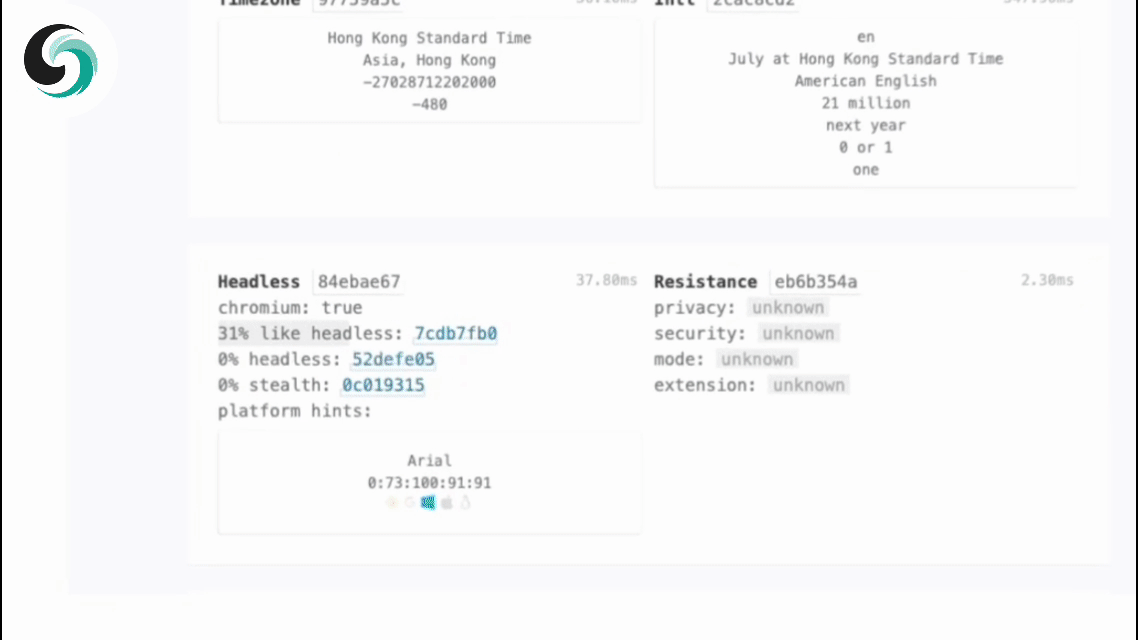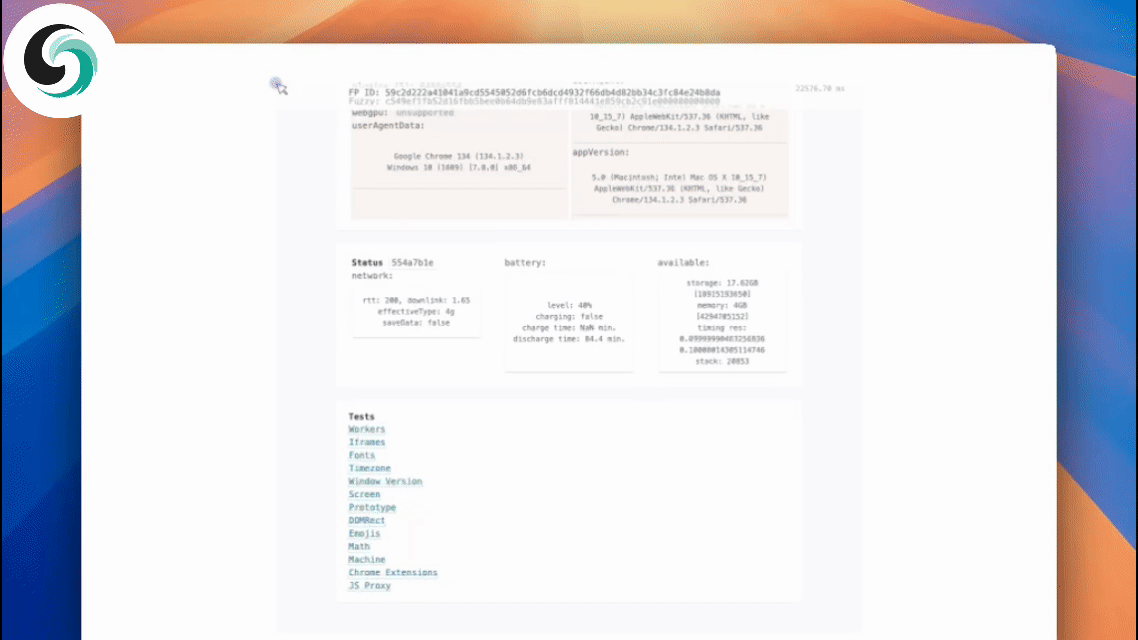
O Scrapeless fornece um serviço de navegador em nuvem que normalmente retorna um CDP_URL. O Crawl4AI pode se conectar diretamente ao navegador em nuvem usando esse URL, sem precisar iniciar um navegador localmente.
O exemplo a seguir demonstra como integrar perfeitamente o Crawl4AI com o Navegador Scrapeless Cloud para raspagem eficiente, apoiando rotação automática de proxy, impressões digitais personalizadas e reutilização de perfis.
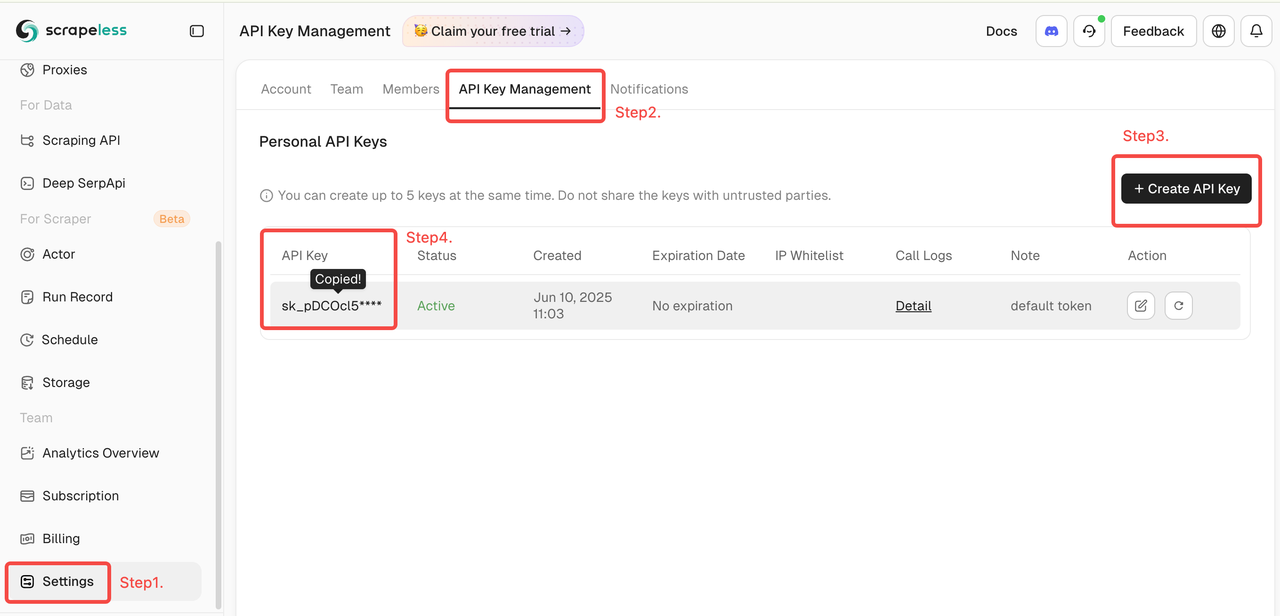
Obtenha Seu Token Scrapeless
Faça login no Scrapeless e obtenha seu Token de API.
1. Início Rápido
O exemplo abaixo mostra como conectar rapidamente e com facilidade o Crawl4AI ao Scrapeless Cloud Browser:
Para mais recursos e instruções detalhadas, consulte a introdução.
scrapeless_params = {
"token": "obtenha seu token em https://www.scrapeless.com",
"sessionName": "Navegador Scrapeless",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)Após a configuração, o Crawl4AI se conecta ao Scrapeless Cloud Browser via modo CDP (Chrome DevTools Protocol), permitindo raspagem da web sem um ambiente de navegador local. Os usuários podem configurar ainda mais proxies, impressões digitais, reutilização de sessões e outros recursos para atender às demandas de alta concorrência e cenários complexos de anti-bot.
2. Rotação Automática de Proxy Global
O Scrapeless suporta IPs residenciais em 195 países. Os usuários podem configurar a região alvo usando proxycountry, permitindo que solicitações sejam enviadas de locais específicos. Os IPs são automaticamente rotacionados, evitando efetivamente bloqueios.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "seu token",
"sessionTTL": 1000,
"sessionName": "Demonstração de Proxy",
# Define o país/região alvo para o proxy, enviando solicitações via um endereço IP daquela região. Você pode especificar um código de país (ex.: US para os Estados Unidos, GB para o Reino Unido, ANY para qualquer país). Veja os códigos de país para todas as opções suportadas.
"proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Código de Status: {result.status_code}')
print("-" * 20)
print(f'Título: {result.metadata["title"]}')
print(f'Descrição: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())3. Impressões Digitais do Navegador Personalizadas
Para imitar o comportamento real do usuário, o Scrapeless suporta impressões digitais de navegador geradas aleatoriamente e também permite parâmetros personalizados de impressão digital. Isso reduz efetivamente o risco de ser detectado por sites alvo.
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# personalizar impressão digital do navegador
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "seu token",
"sessionTTL": 1000,
"sessionName": "Demonstração de Impressão Digital",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Código de Status: {result.status_code}')
print("-" * 20)
print(f'Título: {result.metadata["title"]}')
print(f'Descrição: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())4. Reutilização de Perfil
Scrapeless atribui a cada perfil seu próprio ambiente de navegador independente, possibilitando logins persistentes e isolamento de identidade. Os usuários podem simplesmente fornecer o profileId para reutilizar uma sessão anterior.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "seu token",
"sessionTTL": 1000,
"sessionName": "Demonstração de Perfil",
"profileId": "seu profileId", # criar perfil no scrapeless
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Código de Status: {result.status_code}')
print("-" * 20)
print(f'Título: {result.metadata["title"]}')
print(f'Descrição: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())Vídeo
FAQ
Q: Como posso gravar e visualizar o processo de execução do navegador?
A: Basta definir o parâmetro sessionRecording como "true". Toda a execução do navegador será gravada automaticamente. Após o término da sessão, você pode reproduzir e revisar toda a atividade na lista Histórico de Sessões, incluindo cliques, rolagens, carregamentos de página e outros detalhes. O valor padrão é "false".
scrapeless_params = {
# ...
"sessionRecording": "true",
}Q: Como posso usar impressões digitais aleatórias?
A: O serviço de Navegador Scrapeless gera automaticamente uma impressão digital de navegador aleatória para cada sessão. Os usuários também podem definir uma impressão digital personalizada usando o campo fingerprint.
Q: Como faço para definir um proxy personalizado?
A: Nossa rede de proxy embutida suporta 195 países/regiões. Se os usuários desejarem usar seu próprio proxy, o parâmetro proxyURL pode ser usado para especificar a URL do proxy, por exemplo: http://user:pass@ip:port.
(Nota: A funcionalidade de proxy personalizado está atualmente disponível apenas para assinantes Enterprise e Enterprise Plus.)
scrapeless_params = {
# ...
"proxyURL": "proxyURL",
}Resumo
Combinar o Navegador Cloud Scrapeless com Crawl4AI fornece aos desenvolvedores um ambiente de web scraping estável e escalável:
- Não é necessário instalar ou manter instâncias locais do Chrome; todas as tarefas são executadas diretamente na nuvem.
- Reduz o risco de bloqueios e interrupções de CAPTCHA, uma vez que cada sessão é isolada e suporta impressões digitais aleatórias ou personalizadas.
- Melhora a depuração e reprodutibilidade, com suporte para gravação automática de sessões e reprodução.
- Suporta rotação automática de proxy em 195 países/regiões.
- Utiliza o Serviço de Edge Node global, proporcionando velocidades de inicialização mais rápidas do que outros serviços similares.
Esta colaboração marca um importante marco para Scrapeless e Crawl4AI no espaço de scraping de dados da web. Daqui em diante, a Scrapeless se concentrará na tecnologia de navegador em nuvem, oferecendo a clientes empresariais extração de dados eficiente e escalável, automação e suporte à infraestrutura de agentes de IA. Aproveitando suas poderosas capacidades em nuvem, a Scrapeless continuará a oferecer soluções personalizadas e baseadas em cenários para indústrias como finanças, varejo, e-commerce, SEO e marketing, ajudando empresas a alcançarem um verdadeiro crescimento automatizado na era da inteligência de dados.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


