
How to Scrape Amazon Datas via Scrapeless?
Advanced Data Extraction Specialist
Want to gain a competitive advantage on Amazon? Whether you're tracking prices, analyzing product trends, or conducting market research, the key to staying ahead is effectively scraping Amazon data. But extracting useful information from Amazon can be tricky—especially with frequent changes to site structure, anti-bot measures, and IP blocking. That's where the Amazon Scraping API comes in. In this guide, we'll show you how to scrape Amazon product data using Python, making it easier than ever to collect valuable data and information from the world's largest e-commerce platform.
What is an Amazon Scraping API?
Amazon web Scraping API is like a remote server that helps you collect Amazon data. The operation is simple - you send a request to the API endpoint containing the target URL and other parameters such as geolocation. The API then visits the website for you.
Amazon supports crawling the following data types:
1. Product:
-
Product information: The content that can be crawled includes basic information such as product name, description, price, image URL, ASIN (Amazon Standard Identification Number), brand, etc.
-
Sales data: Such as product ranking, sales volume and comments, etc.
2. Seller:
- Seller information: You can get the seller's name, merchant ID and related information of the products they sell.
- Seller ranking: By crawling products from different sellers, you can analyze the market performance of each seller and their competitiveness in a specific category.
3. Keywords:
- Keyword search results: You can crawl related product lists and their detailed information based on specific keywords (such as "laptop" or "anime figure").
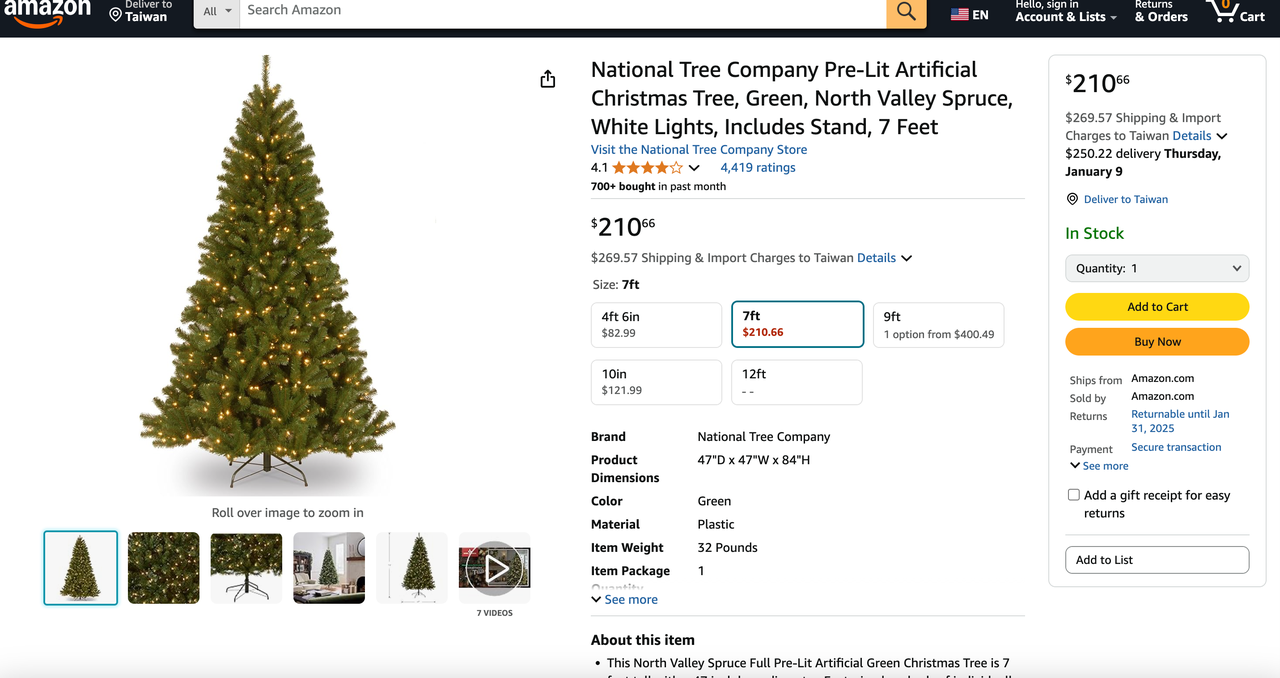
Common use cases for Amazon scraping
Amazon scraping serves various purposes for businesses and marketers:
1. Price Monitoring: By scraping product prices, businesses can track competitor pricing and adjust their own strategy accordingly.
2.Product Research: Scraping reviews, ratings, and product details helps identify trending items and understand customer preferences.
3. Sales Optimization: Marketers scrape product descriptions and promotions to improve content and create effective campaigns.
4. Stock Level Tracking: Scraping real-time product availability data helps businesses monitor inventory levels and demand.
5. Customer Sentiment Analysis: Reviews scraped from Amazon offer insights into customer satisfaction and areas for improvement.
In essence, Amazon scraping streamlines competitive analysis, product research, and marketing strategies.
Key challenges in scraping Amazon (e.g., CAPTCHA, rate limits)
- CAPTCHA Challenges
Amazon uses CAPTCHA verification to prevent automated crawling, especially when a large number of rapid requests are detected. Such verification requires users to confirm that they are human, which prevents automated tools from successfully obtaining data.
Amazon has a request frequency limit. If you access its website too frequently, the system will automatically delay the response or temporarily block further requests. This makes the crawling process slow and unstable.
TIPS: For most ordinary users, Amazon usually allows between dozens and hundreds of requests per minute. Exceeding this frequency may experience delays or temporary blockages. Amazon may set stricter limits for frequent crawling requests.
- IP Blocking
Highly frequent crawling may cause Amazon to temporarily block IP addresses. If the IP address is marked as an abnormal source, the crawling operation will be completely blocked, and you need to change the IP or use a proxy pool to bypass this limit. Generally speaking, 5-10 requests per second may cause risks.
- Dynamic Content Loading
Amazon page content is usually loaded dynamically through JavaScript, which means that additional processing of the page rendering process is required when crawling. Traditional HTML crawling methods often cannot directly obtain dynamically loaded data.
- Frequent Layout Changes
The page layout of the Amazon website changes frequently, which brings challenges to the crawling script. The crawling tool needs to be constantly updated to adapt to the updates and changes of the page to ensure the accuracy and stability of data extraction.
Setting Up Your Python Environment
Before you start writing code in Python, you must first set up your development environment. This step ensures that you have all the tools and libraries you need to write and execute Python code. In this section, we'll walk you through the process of installing Python, setting up a virtual environment, and configuring an integrated development environment (IDE) to streamline your workflow.
To use Python, you need to download the following configurations
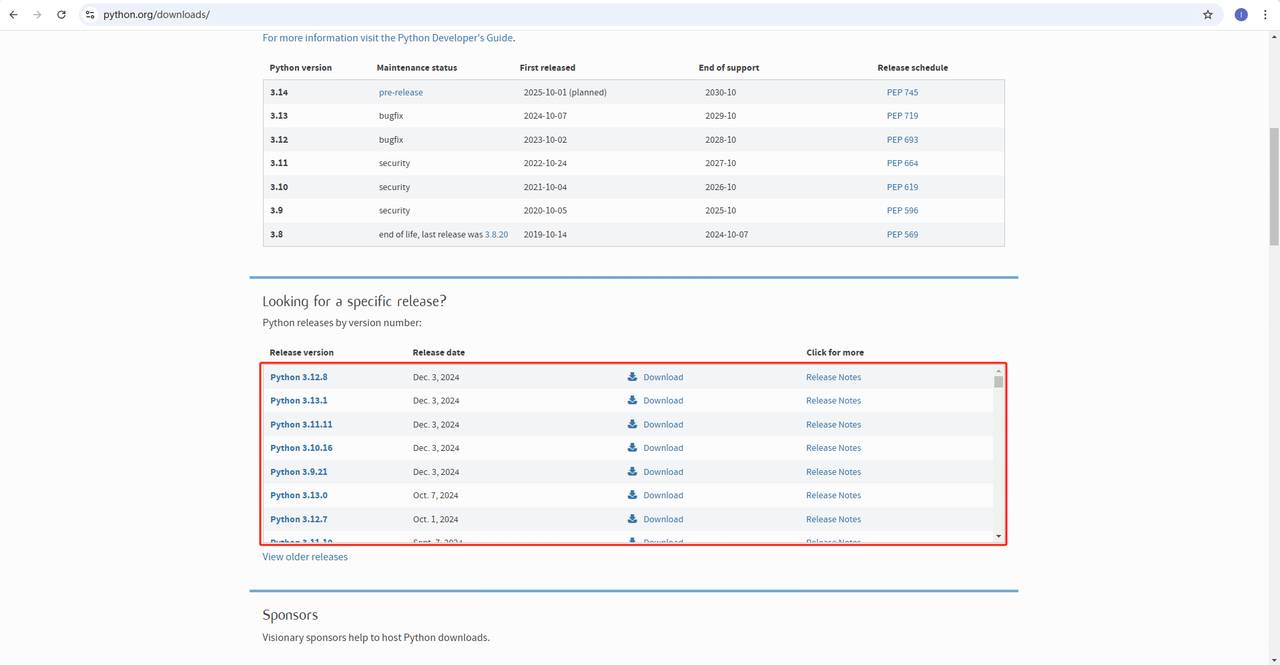
1.python: https://www.python.org/downloads/ This is the core software for running Python. You can download the version we need from the official website as shown below, but it is recommended not to download the latest version. You can download the first 1-2 versions of the latest version.
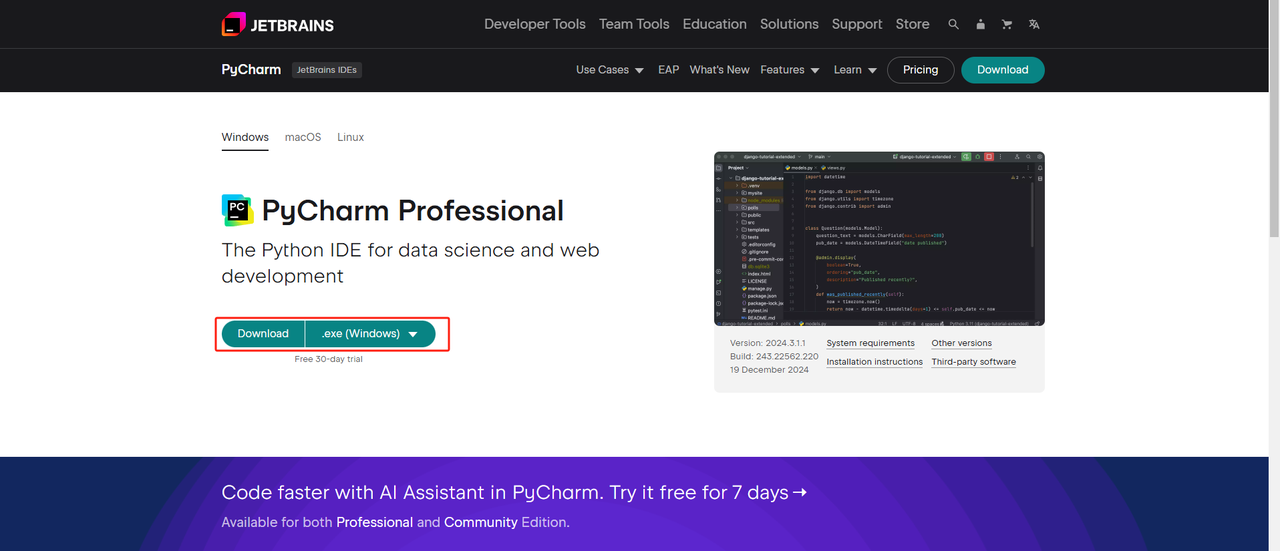
2. Python IDE: Any IDE that supports Python will do, but we recommend using PyCharm, which is an IDE development tool software designed specifically for Python. For the PyCharm version, we recommend using the free PyCharm Community Edition.
3.pip: You can use the Python Package Index (PyPi) to install libraries with a single command.
Note: If you are a Windows user, don't forget to check the option Add python.exe to PATH in the installation wizard. This way, Windows will be able to use python and commands in the terminal. FYI: Since Python 3.4 or later includes it by default, you don't need to install it manually.
Initialize a Python project
Launch PyCharm and select File > New Project... option on the menu bar.

It will then open a popup window. Select Pure Python from the left menu and then set up your project as follows:
Note: In the red box below, select the installation path of Python that we downloaded in the first step of environment configuration.
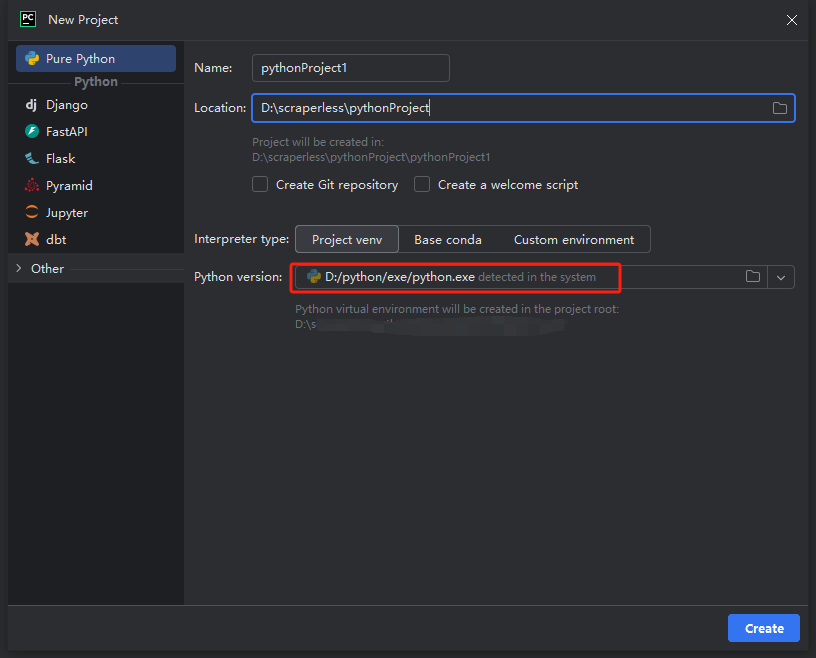
You can create a project called python-scraper, check the "Create a main.py welcome script option" in the folder, and click the Create button.
After waiting for a while while PyCharm sets up your project, you should see the following:
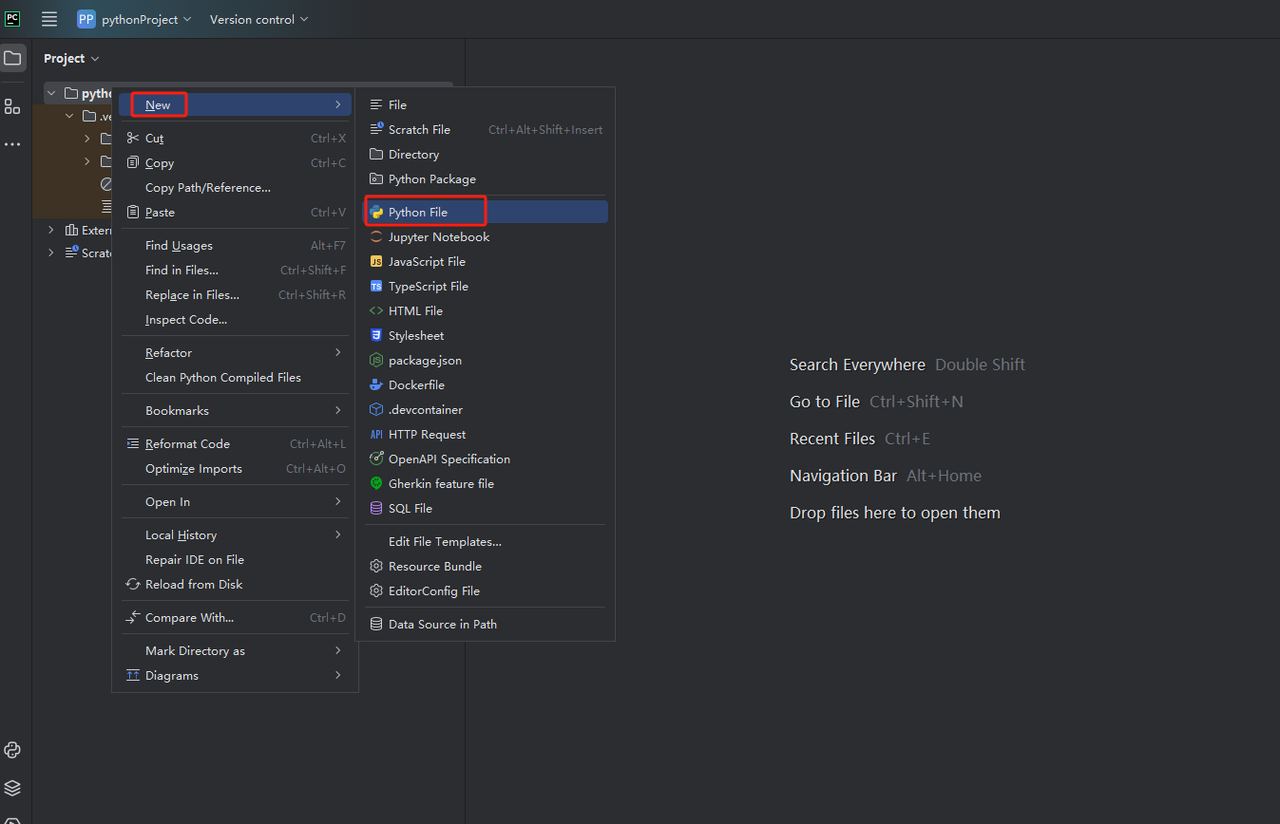
Then, right click to create a new Python File.
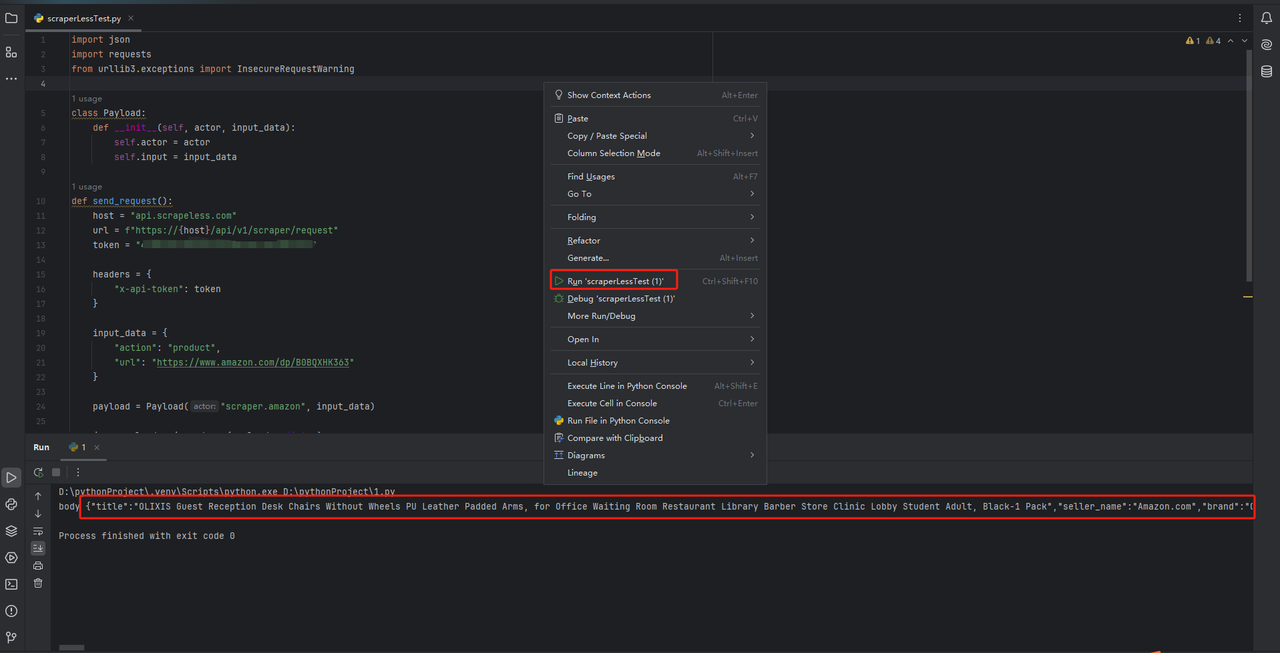
To verify that everything is working properly, open the Terminal tab at the bottom of the screen and type: python main.py. After launching this command, you should get: Hi, PyCharm.
You can directly copy the code in scraperless to pycharm and run it, so that we can get the json format data of Amazon products.
Step-by-Step Guide: Scraping Amazon Product Data
As we mentioned above, after configuring the environment required for web scraping amazon, you can integrate the Scrapeless python code.
How to Scrape Amazon Product Data
You can directly visit the Scrapeless API documentation to get more complete API code information, and then integrate the Scrapeless Python code into your project.
Request samples - Product
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)How to Scrape Amazon Seller info
Likewise, just by integrating Scrapeless API code into your scraping setup, you can bypass Amazon scraping barriers and scrape Amazon seller information.
Request samples - Seller
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))How to Scrape Amazon Keywords Search Results
Follow the steps above to integrate Request samples - Keywords into your project to get Amazon Keywords Search Results.
Request samples - Keywords
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Through simple integration and configuration, Scrapeless helps you obtain Amazon data in a more efficient way. You can easily crawl key data on the Amazon platform, including product, seller and keyword information, thereby improving the accuracy and real-time nature of data analysis.
FAQs About Scraping Amazon Data
1. Is it legal to scrape Amazon data?
Scraping public product information (such as titles, descriptions, prices, and ratings) is legal, while scraping private account data may raise privacy issues. In addition, using scraped data for market research or competitive analysis is generally considered "fair use."
2. What data can be scraped from Amazon?
Using the Amazon scraping API, you can extract data related to products, sellers, reviews, etc. This includes product name, price, ASIN (Amazon Standard Identification Number), brand, description, specifications, category, user reviews and their ratings.
3. How to effectively crawl Amazon data?
Effective ways to crawl Amazon data include using automated scripts or APIs and following Amazon's terms of service. To avoid being blocked, it is recommended to reduce the request frequency and control the load reasonably. In addition, using a captcha solution can increase the success rate of crawling.
Conclusion: Best Amazon Scraping API Provider
Through the introduction of this article, you have mastered how to use Python to efficiently crawl product data on Amazon. Whether it is obtaining product details, price information, or review data, the power and flexibility of Python makes automated crawling easier and more efficient. However, when crawling large-scale data, you may encounter challenges with anti-crawler mechanisms. At this time, Scrapeless, as an intelligent web crawling solution, can help you bypass these obstacles and ensure a smoother and more efficient crawling process. If you want to improve the speed and stability of data crawling, you might as well try using Scrapeless to further optimize your crawling workflow.
Join the Scrapeless Discord Community! 🚀 Connect with fellow data enthusiasts, get exclusive tips on scraping faster and smarter, and stay updated on our latest features. Whether you're a beginner or a pro, there's a place for you here. Click the link and start engaging today! 👾 Join Now
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


