
O que é Web Scraping? Como raspar dados de um site?
Senior Web Scraping Engineer
Web scraping é o processo automatizado de extração de dados de sites, transformando dados web não estruturados ou semi-estruturados em formatos estruturados como CSV ou JSON.
Esta técnica ganhou atenção significativa devido à crescente dependência de dados para tomada de decisões em diversas indústrias, incluindo e-commerce, finanças, marketing e pesquisa.
Utilizar um serviço confiável de web scraping pode aumentar ainda mais a eficiência do processo de extração de dados. Isso é especialmente importante para realizar pesquisas de mercado, impulsionar a geração de leads para equipes de vendas e marketing e fornecer monitoramento de preços para empresas de varejo e viagens competitivas.
O que é web scraping e como raspar um site perfeitamente?
Obtenha o guia detalhado neste artigo!
O que é Web Scraping?
Web scraping envolve o uso de software ou scripts para coletar e processar informações de sites. Ao contrário da coleta manual de dados, o web scraping automatiza o processo de extração, tornando-o mais eficiente e escalável. O objetivo principal é reunir insights acionáveis ou grandes conjuntos de dados para análise, pesquisa ou integração em aplicativos.
O web scraping desempenha um papel fundamental no fornecimento de dados para modelos de aprendizado de máquina, avançando ainda mais o desenvolvimento da tecnologia de inteligência artificial. Ao automatizar o processo de coleta de dados e expandir os dados para coletar informações de uma variedade de fontes, o web scraping ajuda a criar modelos de inteligência artificial poderosos, precisos e bem treinados.
O web scraping é particularmente útil se o site público do qual você deseja obter dados não tiver uma API ou fornecer apenas acesso limitado aos dados da web!
Nesse caso, os métodos tradicionais não conseguem atender às necessidades, e a utilização de serviços externos de web scraping, como o Scrapeless, pode ser uma abordagem estratégica. Esses serviços fornecem soluções mais eficientes e escaláveis. Além disso, para aqueles que procuram recursos avançados, ferramentas como a API e o Scraping Browser do Scrapeless oferecem soluções abrangentes, fornecendo recursos como tratamento de bloqueio, operações automáticas do navegador, gerenciamento de sessões e cookies e extração eficiente de dados.
E, em comparação com outros produtos semelhantes, o Scrapeless também oferece preços mais baratos, garantindo alta estabilidade. Isso alivia o ônus de custo para empresas com orçamentos limitados, mas com necessidades fortes.
Como funciona o Web Scraping?
Web scraping é o processo de automatizar a coleta de dados não estruturados e estruturados. Também é amplamente conhecido como extração de dados da web ou raspagem de dados da web.
Alguns dos principais casos de uso para web scraping incluem monitoramento de preços, inteligência de preços, monitoramento de notícias, geração de leads e pesquisa de mercado, entre outros.
De maneira geral, é usado por indivíduos e empresas que desejam aproveitar os dados da web publicamente disponíveis para gerar insights valiosos e tomar decisões mais inteligentes.
Web scraping manual
Se você já copiou e colou informações de um site, você executou a mesma função que qualquer ferramenta de web scraping, exceto que você executou o processo de raspagem de dados manualmente:
- Identifique o site-alvo
- Colete as URLs das páginas-alvo
- Faça solicitações a essas URLs para obter o HTML da página
- Use localizadores para encontrar informações no HTML
- Salve os dados como um arquivo JSON ou CSV ou outro formato estruturado
Parece ser suficiente para web scraping diário. Infelizmente, se você precisar extrair dados em grande escala, precisa lidar com vários desafios.
Por exemplo, se o layout do site mudar, mantenha as ferramentas de extração de dados e rastreadores da web, gerencie proxies, execute javascript ou contorne anti-bots. Essas são questões técnicas que consomem recursos internos.
Neste momento, precisamos usar ferramentas de automação mais poderosas - Web Scraper
Web scraper
Ao contrário do processo tedioso de extrair dados você mesmo, o web scraping usa aprendizado de máquina e automação inteligente para recuperar milhões ou até bilhões de pontos de dados extraídos da internet.
- O web scraping funciona enviando solicitações HTTP a um site e buscando seu conteúdo HTML.
- O script então analisa a estrutura HTML para localizar e extrair pontos de dados específicos usando tags, atributos ou padrões.
- Métodos avançados podem lidar com conteúdo dinâmico renderizado via JavaScript simulando o comportamento do navegador usando ferramentas como Puppeteer ou Selenium.
Se você mesmo escreve um web scraper ou usa uma ferramenta poderosa de extração de dados da web, precisa saber mais sobre os fundamentos de web scraping ou extração de dados da web!
Diferenças entre Web Scraping e Web Crawling
| Recursos | Web Scraping | Web Crawling |
|---|---|---|
| Objetivo | Extrair dados específicos | Rastrear links da web e construir índice de conteúdo |
| Alcance | Foco em um pequeno número de páginas da web e conteúdo específico | Rastrear um grande número de páginas da web |
| Complexidade técnica | Média, principalmente usada para análise de dados | Alta, precisa gerenciar rastreamento de links e desduplicação |
| Ferramentas comuns | BeautifulSoup, Puppeteer, Scrapy | Scrapy, Apache Nutch, Selenium |
| Aplicações principais | Análise de dados, monitoramento de preços de e-commerce | Indexação de mecanismos de busca, análise de SEO |
O web scraping
Web scraping é um processo focado usado para extrair dados específicos de uma página da web e convertê-los em um formato estruturado, como CSV ou JSON. O objetivo é recuperar informações precisas, como preços, avaliações ou detalhes do produto, para análise ou uso posterior. Os scrapers usam ferramentas como XPath, seletores CSS ou regex para localizar e extrair os dados desejados de forma eficiente.
O web crawling
Web crawling, muitas vezes referido como "spidering", é um processo automatizado de navegação na internet para indexar e coletar páginas da web seguindo links. Os crawlers são normalmente usados para construir grandes conjuntos de dados ou índices, como os de mecanismos de busca. Em alguns projetos, o web crawling é uma etapa preliminar para coletar URLs, que são então processadas por um web scraper para extrair dados específicos.
2 Métodos populares de Web Scraping para raspar um site
Para lhe dar uma compreensão mais clara de como raspar um site, usaremos agora 2 ferramentas de rastreamento populares e poderosas: Scraping API e Scraping Browser para raspar as Tendências do Google.
Scraping API
Com a avançada Scraping API, você pode acessar e raspar facilmente dados do Google Trends sem escrever ou manter scripts de raspagem complexos. Basta chamar a API que fornecemos para obter rapidamente todas as informações de que precisa.
Você pode raspar facilmente categorias de dados do Google Trends como:
- Interesse ao longo do tempo
- Comparação detalhada por região
- Interesse por sub-região
- Consultas relacionadas
- Tópicos relacionados
Vejamos os passos detalhados:
- Passo 1. Faça login no Scrapeless
- Passo 2. Clique em "Scraping API"
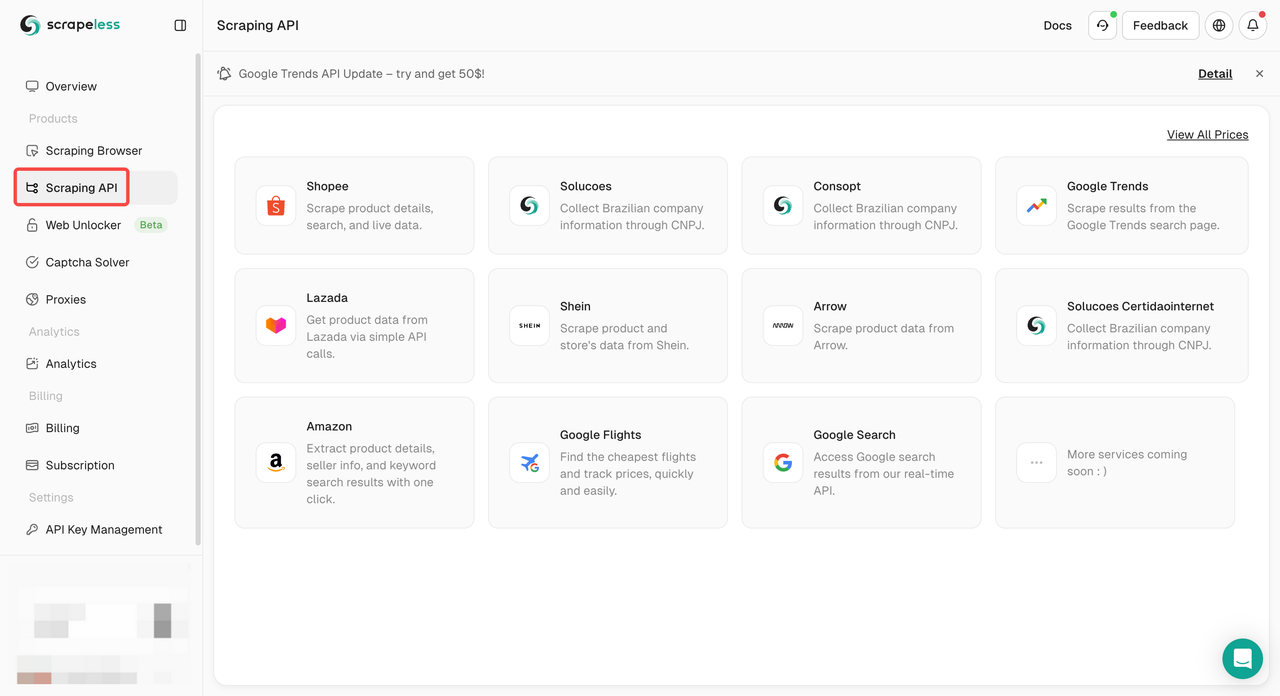
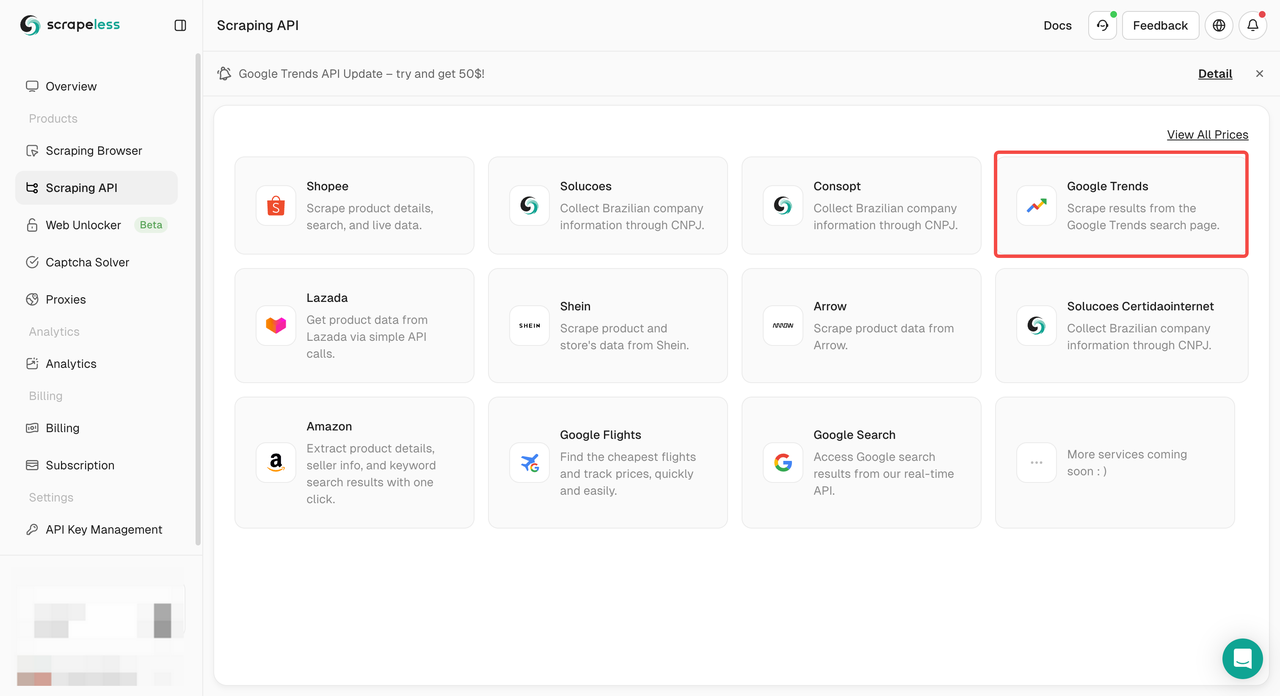
- Passo 3. Encontre nosso painel "Google Trends" e entre nele:
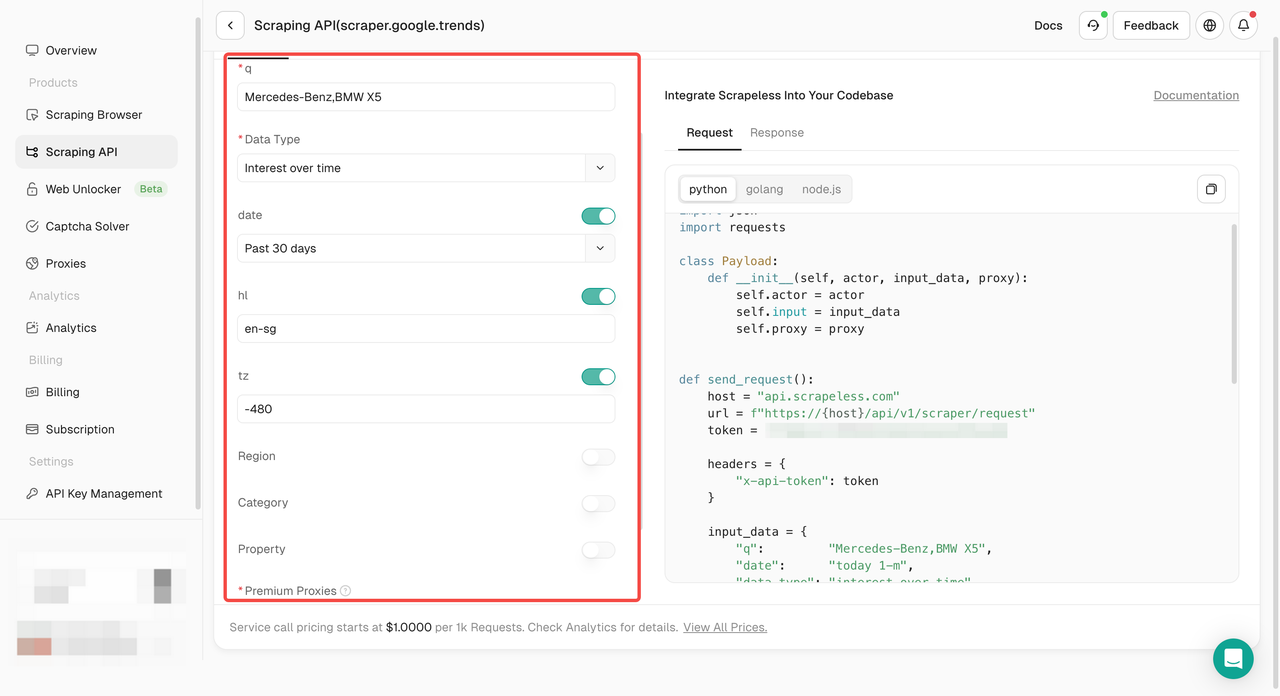
- Passo 4. Configure seus dados no painel de operação esquerdo:
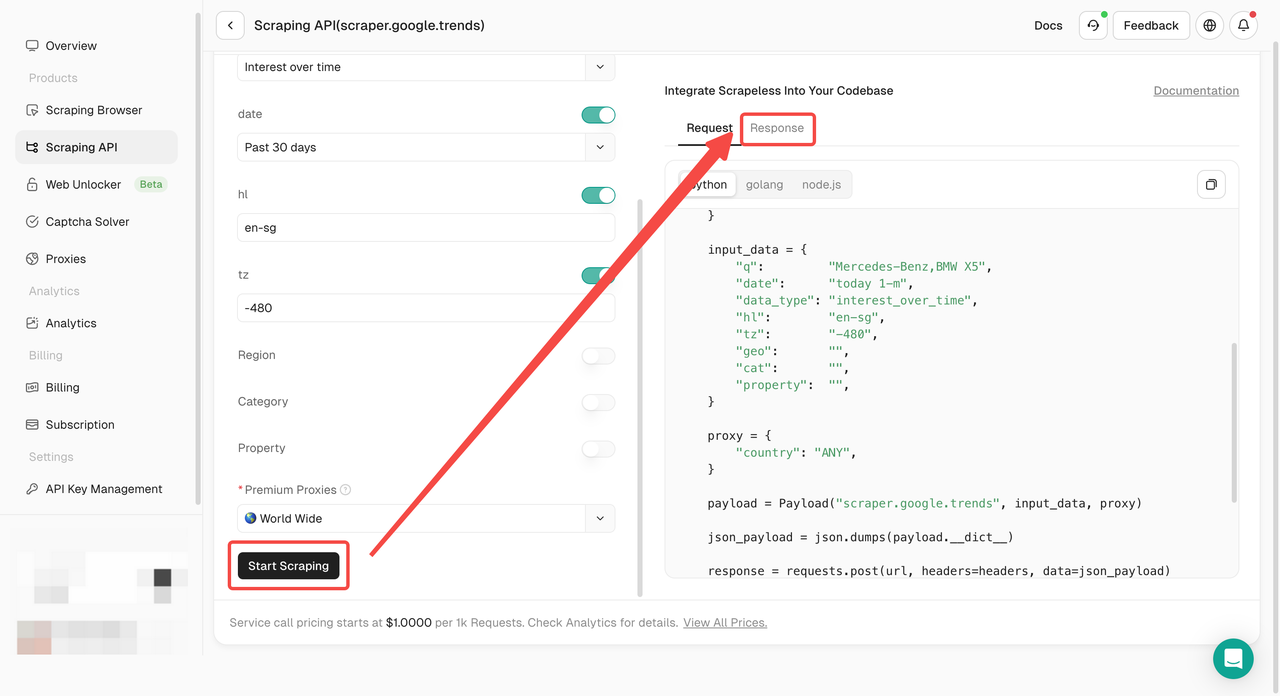
- Passo 5. Clique no botão "Iniciar Raspagem" e você poderá obter o resultado:
Ou você pode implantar nossa API em seu próprio projeto como:
- Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.trends",
"input": {
"keywords": "Mercedes-Benz,BMW X5",
"geo": "",
"time": "today 1-m",
"category": "0",
"property": ""
},
"proxy": {
"country": "US"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.trends",
"input": {
"data_type": "autocomplete",
"q": "Mercedes-Benz"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Scraping Browser
Requisitos:
- Node.js: Certifique-se de que a versão 14 ou superior esteja instalada.
- npm: Gerenciador de pacotes Node para lidar com dependências.
- Serviço Scrapeless Browserless: Use o serviço de navegador fornecido pelo Scrapeless.
Em seguida, acesse o painel do Scraping Browser, navegue até a guia "Configurações" e recupere sua chave API.
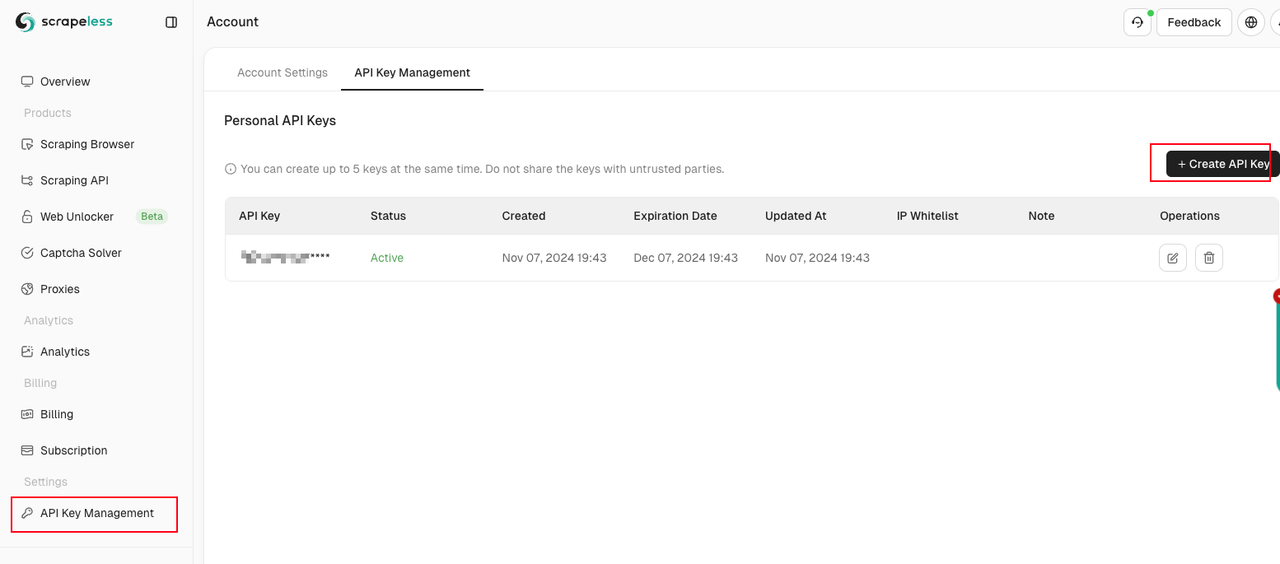
Em seguida, siga nossos passos:
- Instale as dependências necessárias usando:
Bash
npm install- Configure as variáveis de ambiente
Crie um arquivo .env no diretório raiz do projeto e adicione sua chave API da seguinte forma:
Bash
API_KEY=sua_chave_api_scrapeless- Personalize os parâmetros do script
O script está pré-configurado para buscar tendências para "youtube" e "twitter" nos Estados Unidos nos últimos 7 dias. Você pode ajustar as seguintes configurações:
- Palavras-chave: Modifique o parâmetro q na variável
QUERY_PARAMSpara alterar os termos de busca. - Geolocalização: Atualize o parâmetro
geopara definir o local desejado. - Intervalo de datas: Ajuste o parâmetro
datecom base no período que deseja analisar.
- Defina os cookies
Para estabilizar os dados relacionados às mudanças de interesses ao longo do tempo, configure os cookies usando o Puppeteer antes de visitar o site:
JavaScript
const cookies = JSON.parse(fs.readFileSync('./data/cookies.json', 'utf-8'));
await browser.setCookie(...cookies);Para gerar o arquivo cookies.json, faça login no Google Trends por meio do seu navegador e exporte os cookies no formato JSON. Se não tiver certeza de como fazer isso, considere usar uma extensão do navegador projetada para exportação de cookies.
- Execute o script usando o Node.js:
Bash
node index.jsPara que pode ser usado o Web Scraping?
Inteligência de Preços
Sim, a inteligência de preços é o maior caso de uso para web scraping.
Extrair informações de produtos e preços de sites de comércio eletrônico e, em seguida, transformá-las em inteligência é um componente vital das empresas modernas de comércio eletrônico que procuram tomar melhores decisões de preços/marketing com base em dados.
Benefícios dos dados de preços da web e da inteligência de preços:
- Precificação dinâmica
- Otimização de receita
- Monitoramento da concorrência
- Monitoramento de tendências de produtos
- Conformidade com a marca e MAP
Pesquisa de mercado
A pesquisa de mercado é crítica e deve ser impulsionada pelas informações mais precisas. Com a raspagem de dados, você obtém acesso a dados raspados da web de alta qualidade, alto volume e alto insight em todas as formas e tamanhos que estão impulsionando a análise de mercado e a inteligência de negócios em todo o mundo.
- Análise de tendências de mercado
- Precificação de mercado
- Otimização de pontos de entrada
- Pesquisa e desenvolvimento
- Monitoramento da concorrência
Dados alternativos financeiros
Descubra alfa e crie valor do zero com dados da web personalizados para investidores.
A tomada de decisões nunca foi tão inteligente e os dados nunca foram tão perspicazes - os dados raspados da web são cada vez mais usados pelas principais empresas do mundo, dado seu incrível valor estratégico.
- Extrair insights de arquivamentos da SEC
- Avaliar os fundamentos da empresa
- Integração de sentimento público
- Monitoramento de notícias
Imobiliário
A transformação digital do setor imobiliário nas últimas duas décadas tem o potencial de interromper os negócios tradicionais e dar origem a novos players poderosos no setor.
Ao incorporar dados imobiliários raspados da web em operações diárias, agentes e corretoras podem se defender da concorrência online de cima para baixo e tomar decisões inteligentes no mercado.
- Avaliar os valores dos imóveis
- Monitorar as taxas de vacância
- Rendimentos de aluguel estimados
- Entender a direção do mercado
Monitoramento de notícias e conteúdo
A mídia moderna pode criar um valor excepcional ou uma ameaça existencial para o seu negócio em um único ciclo de notícias.
Se sua empresa depende da análise de notícias em tempo hábil ou é uma empresa que frequentemente aparece nas notícias, a raspagem de dados de notícias é a solução definitiva para monitorar, agregar e analisar as notícias mais importantes do seu setor.
- Decisões de investimento
- Análise da opinião pública online
- Monitoramento da concorrência
- Campanhas políticas
- Análise de sentimento
Geração de leads
A geração de leads é uma atividade crítica de marketing/vendas para todas as empresas.
Em um relatório da Hubspot de 2024, 65% dos profissionais de marketing inbound disseram que gerar tráfego e leads é seu maior desafio. Felizmente, a extração de dados da web pode ser usada para obter listas estruturadas de leads da web.
Monitoramento de marca
No mercado competitivo atual, proteger sua reputação online é uma prioridade máxima.
Se você vende produtos online e precisa aplicar uma política de preços rigorosa, ou apenas deseja saber como as pessoas veem seus produtos online, o monitoramento de marca usando web scraping pode fornecer essas informações.
Automação de negócios
Em alguns casos, acessar dados pode ser complicado. Talvez você precise extrair dados de seus próprios sites ou dos sites de seus parceiros de forma estruturada.
Mas não há uma maneira fácil de fazer isso internamente, então é uma jogada inteligente criar uma ferramenta de raspagem e raspar os dados diretamente. Em vez de tentar descobrir isso com sistemas internos complexos.
Monitoramento de MAP
O monitoramento de Preço Mínimo Anunciado (MAP) é uma prática padrão para garantir que os preços online de uma marca sejam consistentes com sua política de preços.
Monitorar manualmente os preços é impossível devido ao grande número de revendedores e distribuidores.
É por isso que o web scraping é tão conveniente, pois você pode facilmente acompanhar os preços de seus produtos.
Como raspar um site gratuitamente?
Há uma variedade de soluções gratuitas de web scraping disponíveis para raspar conteúdo automaticamente e extrair dados da web. Essas soluções variam de soluções simples de raspagem de apontar e clicar para não profissionais a aplicativos mais poderosos e centrados em desenvolvedores, com opções extensas de configuração e gerenciamento.
Scraping API e Scraping Browser se tornarão as ferramentas mais poderosas que estão alinhadas com o desenvolvimento da sociedade da internet. Eles possuem desbloqueador da web, proxy e CAPTCHA integrados, etc., tornando sua raspagem da web mais conveniente e rápida.
São necessárias apenas operações simples de configuração para obter os dados mais precisos imediatamente.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


