
Como Contornar a Detecção de Anti-Bot com Proxies Estáveis?
Expert Network Defense Engineer
Muitos sites começaram a implementar salvaguardas contra bots, à medida que o web scraping se torna cada vez mais comum. Isso envolve tecnologia complexa que bloqueia softwares automatizados de obter suas informações. Um site pode restringir a quantidade de solicitações que seu web scraper pode fazer ou bloqueá-lo completamente se descobrir sua presença.
Você pode encontrar as maneiras mais populares de como os sistemas anti-bot o detectam e aprender a contorná-los.
Comece a rolar agora!
O que é uma verificação anti-bot?
A tecnologia de verificação anti-bot refere-se a sistemas e técnicas que identificam e bloqueiam atividades automatizadas realizadas por bots. Um bot é um software criado para realizar tarefas online de forma autônoma. Embora o nome "bot" tenha uma conotação negativa, nem todos são assim. Por exemplo, os crawlers do Google também são bots!
Enquanto isso, bots maliciosos representam pelo menos 27,7% de todo o tráfego online mundial. Eles realizam atividades criminosas, como ataques DDoS, spam e roubo de identidade. Na tentativa de proteger a privacidade dos usuários e melhorar a experiência do usuário, os sites buscam evitar esses bots e podem até banir o seu web scraper.
Uma variedade de técnicas, incluindo validação de cabeçalhos HTTP, impressão digital e CAPTCHAs, é utilizada pelos filtros anti-bot para diferenciar usuários reais de programas automatizados.
Por que os sites implementam medidas anti-bot?
Para os proprietários de sites, a tecnologia anti-bot pode ajudá-los a eliminar a maioria das interrupções e desafios:
- Proteção de Dados: Medidas anti-bot evitam a extração não autorizada de informações sensíveis ou proprietárias.
- Confiabilidade do Serviço: Bots podem consumir excessivos recursos do servidor e reduzir a experiência do usuário, e os sistemas anti-bot podem mitigar esses riscos.
- Prevenção de Fraude: Sistemas de verificação anti-bot combatem atividades como criação de contas falsas, revenda de ingressos e fraude publicitária.
- Privacidade do Usuário: Ao bloquear bots não autorizados, esses sistemas ajudam a proteger os dados dos usuários de serem explorados.
Como funciona a tecnologia anti-bot?
Os sistemas anti-bot empregam uma combinação de técnicas para detectar e desencorajar atividades automatizadas:
Validação de Cabeçalhos
A validação de cabeçalhos é uma técnica comum de proteção contra bots. Ela analisa os cabeçalhos das solicitações HTTP recebidas para procurar anomalias e padrões suspeitos. Se o sistema detectar algo irregular, sinaliza as solicitações como vindo de um bot e as bloqueia.
Todas as solicitações do navegador são enviadas com muitos dados nos cabeçalhos. Se alguns desses campos estiverem ausentes, não tiverem os valores corretos ou tiverem uma ordem incorreta, o sistema de verificação anti-bot bloqueará a solicitação.
Análise Comportamental
Os mecanismos de verificação anti-bot analisam interações do usuário, como movimentos do mouse, pressões de tecla e padrões de navegação. Comportamentos artificiais ou altamente repetitivos podem sinalizar uma atividade de bot.
Monitoramento de Endereço IP
Muitos sites empregam bloqueios baseados em localização, o que inclui bloquear solicitações de certas regiões geográficas, para limitar o acesso ao seu conteúdo a países selecionados. Governos utilizam essa estratégia de maneira semelhante para proibir alguns sites dentro de sua nação.
O bloqueio geográfico é aplicado no nível DNS ou de ISP.
Para determinar a localização do usuário e decidir se deve bloqueá-lo, esses sistemas examinam o endereço IP do usuário. Assim, para raspar alvos bloqueados por localização, você precisa de um endereço IP de um dos países permitidos.
Você precisa de um servidor proxy para contornar políticas de bloqueio por localização, e proxies premium geralmente permitem escolher o país em que o servidor está situado. Dessa forma, as consultas do web scraper virão do lugar correto.
Você está cansado de ser bloqueado continuamente durante o web scraping?
O Scrapeless Rotate Proxy ajuda a evitar bans de IP
Obtenha a avaliação gratuita agora!
Impressão Digital do Navegador
A impressão digital do navegador é o processo de identificar clientes da web coletando dados do dispositivo do usuário. Ela pode discernir se a solicitação se origina de um usuário legítimo ou de um scraper ao olhar para vários fatores, como fontes instaladas, plugins do navegador, resolução da tela, entre outros.
A maioria das estratégias de implementação de impressão digital do navegador envolve tecnologia do lado do cliente para coletar dados do usuário.
O script acima coleta dados do usuário para criar a impressão digital.
Esse software anti-bot geralmente antecipa que as solicitações se originem de navegadores. Você precisa de um navegador sem interface para contorná-lo enquanto realiza web scraping; caso contrário, você será reconhecido como um bot.
Desafios CAPTCHA
Os sites utilizam testes de desafio-resposta, ou CAPTCHAs, para determinar se um usuário é humano. As soluções anti-bot utilizam essas técnicas para impedir que scrapers acessem um site ou realizem certas tarefas, já que os humanos conseguem resolver esse problema facilmente, mas os bots encontram dificuldades.
Um usuário deve completar uma determinada atividade em uma página, como inserir o número exibido em uma imagem distorcida ou escolher o grupo de imagens, para responder a um CAPTCHA.
Impressão Digital TLS
Analisar os parâmetros que são transferidos durante um handshake TLS é conhecido como impressão digital TLS. O sistema de verificação anti-bot identifica a solicitação como proveniente de um bot e a bloqueia se esses parâmetros não corresponderem aos que deveriam estar presentes.
Validação de Solicitação
Os sistemas de verificação anti-bot validam solicitações HTTP quanto à autenticidade. Headers suspeitos, strings de user-agent inválidas ou cookies ausentes podem indicar tráfego de bots.
5 Métodos para Evitar a Detecção de Anti-Bots
Pode não ser simples contornar um sistema de verificação anti-bot, mas há certos truques que você pode tentar. A lista de estratégias a considerar é a seguinte:
1. Proxies de Rotação Sem Raspagem
Scrapeless oferece serviços de proxy IP limpo premium globais, especializando-se em proxies residenciais dinâmicos IPv4.
Com mais de 70 milhões de IPs em 195 países, a rede de proxies residenciais da Scrapeless oferece suporte global abrangente de proxy para impulsionar o crescimento do seu negócio.
Apoiamo-nos a uma ampla gama de casos de uso, incluindo raspagem da web, pesquisa de mercado, monitoramento de SEO, comparação de preços, marketing em redes sociais, verificação de anúncios e proteção de marcas, permitindo que você administre seu negócio de forma contínua em mercados globais.
Como obter seus proxies especiais? Por favor, siga meus passos:
- Passo 1. Acesse Scrapeless.
- Passo 2. Clique em "Proxies" e crie um canal.
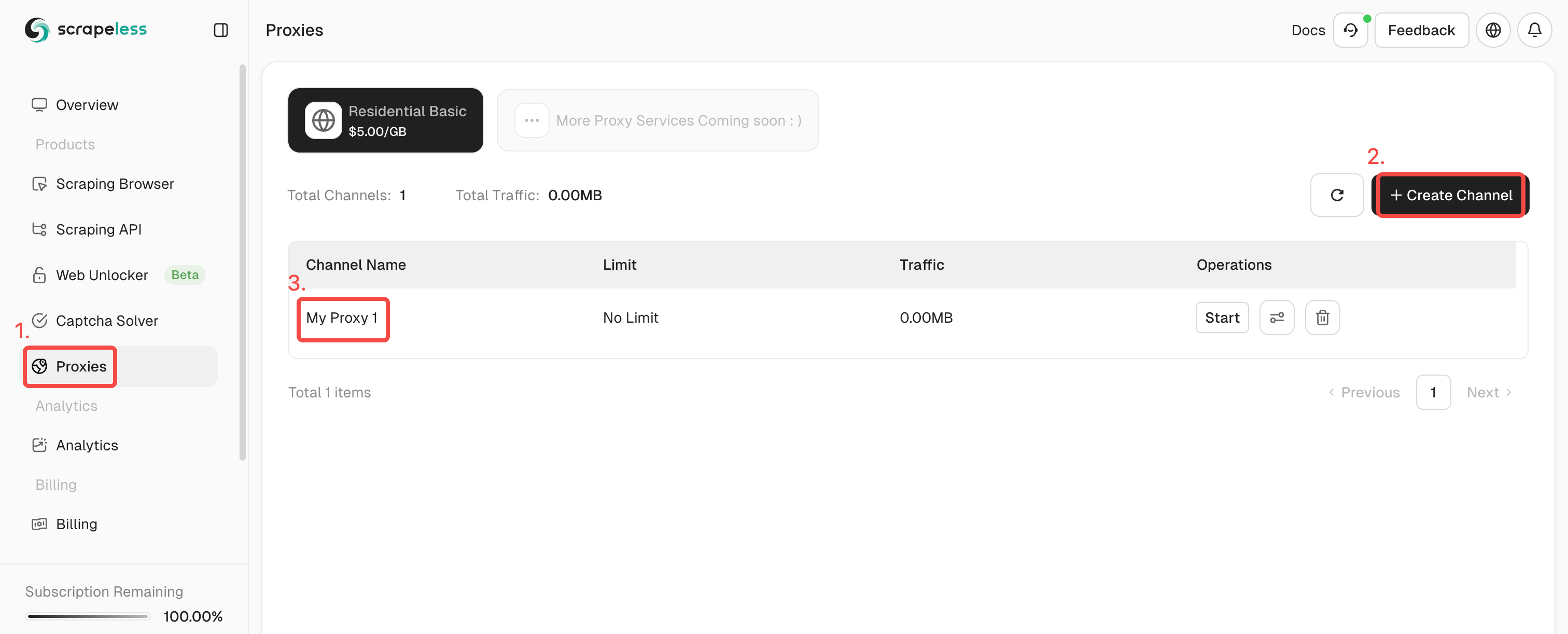
- Passo 3. Preencha as informações necessárias na caixa de operação à esquerda. Depois clique em "Gerar". Após um tempo, você verá o proxy de rotação que geramos para você à direita. Agora basta clicar em "Copiar" para usá-lo.
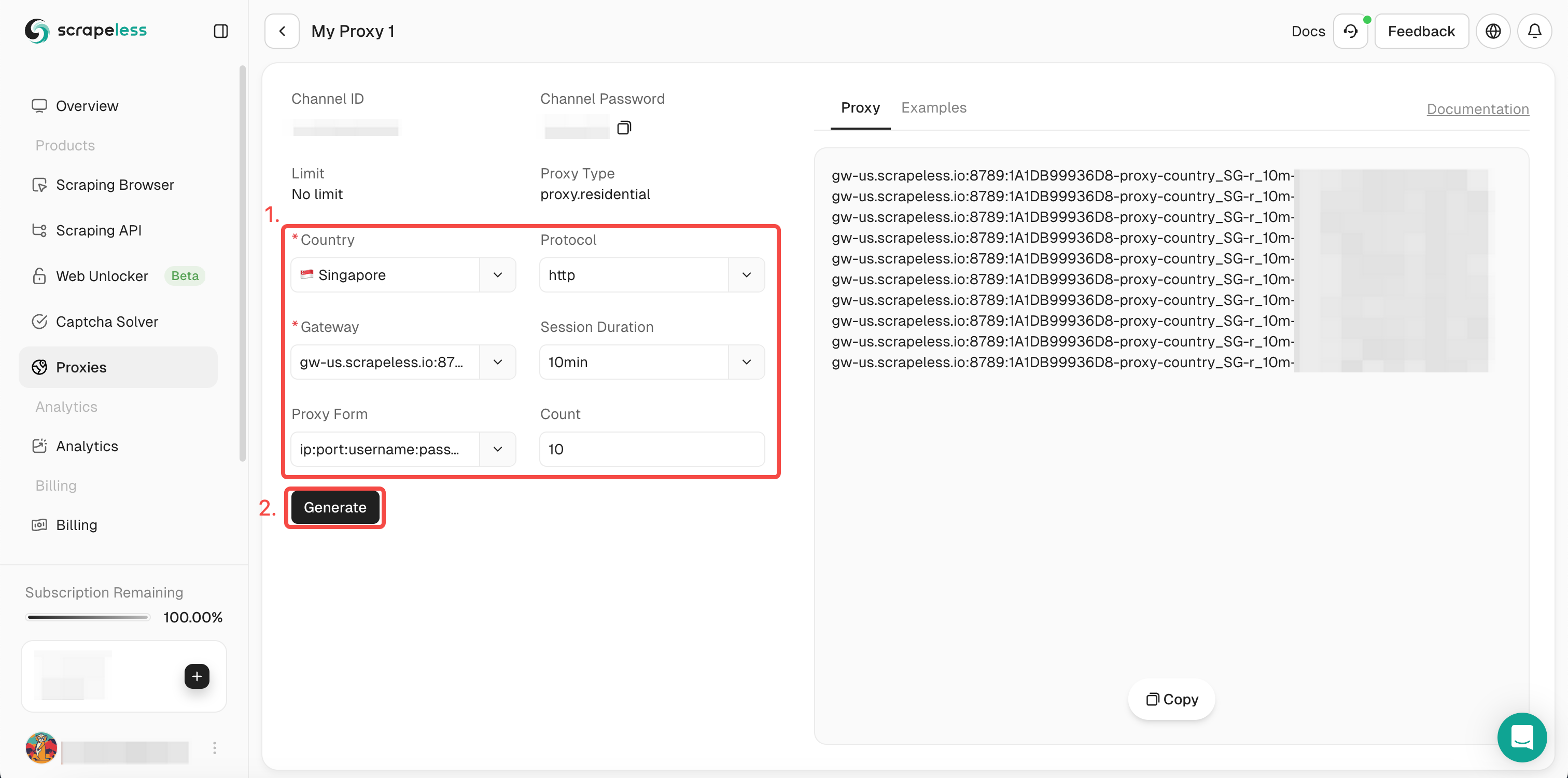
Ou você pode simplesmente integrar nossos códigos de proxy no seu projeto:
- Código:
C
curl --proxy host:port --proxy-user username:password API_URL- Navegador:
- Selenium
Python
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
JavaScript
const puppeteer = require('puppeteer');
(async () => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();2. Respeite o robots.txt
Este arquivo serve como um padrão para websites indicarem se arquivos ou páginas são acessíveis ou inacessíveis para bots. Raspadores da web podem evitar que medidas anti-bot sejam ativadas, aderindo aos critérios especificados. Descubra mais sobre a leitura de arquivos robot.txt para fins de raspagem da web.
Restrinja o número de consultas feitas a partir do mesmo endereço IP: Raspadores da web às vezes fazem muitas solicitações a um website rapidamente. Você pode considerar minimizar a quantidade de consultas provenientes do mesmo endereço IP, pois esse comportamento pode ativar sistemas anti-bot. Examine os métodos para contornar a restrição de taxa ao usar raspagem da web.
3. Adapte seu User-Agent
O cabeçalho HTTP para User-Agent contém uma string que indica o navegador e o sistema operacional de onde a solicitação se originou. As solicitações parecem ser de um usuário comum, uma vez que esse cabeçalho foi modificado. Veja a lista dos User Agents mais populares para raspagem da web.
4. Use um navegador sem interface gráfica
Sem uma interface gráfica, um navegador sem cabeça ainda é controlável. Usando uma ferramenta como essa, você pode evitar que seu raspador seja identificado como um bot, fazendo-o se comportar como um usuário humano—isto é, rolando. Aprenda mais sobre navegadores sem cabeça e quais são adequados para raspagem da web.
5. Agilize o processo com uma API de raspagem online
Usando chamadas de API simples, as APIs de raspagem da web permitem que os usuários raspem websites sem serem detectados por sistemas anti-bot. Por causa disso, a raspagem da web é rápida, simples e eficaz.
Experimente a API de raspagem Scrapeless gratuitamente agora para ver o que a API de raspagem da web mais poderosa disponível tem a oferecer.
Em Resumo
Neste tutorial, você aprendeu muito sobre a detecção de anti-bots. Como contornar a detecção de anti-bots para você é fácil.
Qual método é o melhor para evitar bloqueios?
Com o Scrapeless, uma ferramenta de scraping online com um sofisticado solucionador de CAPTCHA, rotação de IP embutida, capacidade de navegador headless e desbloqueador de sites, você pode evitar todos eles!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


