
O que é um navegador headless e o melhor navegador headless para scraping
Specialist in Anti-Bot Strategies
Neste artigo, você aprenderá o que é um navegador headless, para que ele é usado, o que é o Chrome headless e quais outros navegadores são mais populares no modo headless. Também discutiremos as principais limitações dos testes de navegador headless.
Continue lendo!
Por que 20 milhões de desenvolvedores confiam em nós?
Como você navega pelo complexo mundo dos navegadores headless? Você precisa de um guia experiente que tenha passado por muitas dificuldades e vencido. É aí que entramos!
Na Scrapeless, exploramos técnicas de web scraping e automação há anos. Nossa equipe passou mais de 15.000 horas pesquisando várias soluções de navegador headless, desde soluções antigas como o PhantomJS até as mais novas, como o Playwright.
Vimos em primeira mão como um navegador headless pode fazer ou quebrar um projeto. Depuramos e corrigimos inúmeros problemas, otimizamos o desempenho para operações de scraping em larga escala e até desenvolvemos soluções personalizadas quando as opções prontas para uso simplesmente não funcionavam.
Se você deseja automatizar testes, fazer scraping de dados em escala ou apenas aprender os detalhes da navegação headless, podemos ajudar!
O que é um navegador Headless?
Primeiro, vamos entender o que são essas poderosas ferramentas invisíveis e como elas funcionam!
Um navegador headless é como um ninja do mundo da web – furtivo, eficiente e poderoso. Essencialmente, é um navegador da web que não possui uma interface gráfica do usuário (GUI). É principalmente usado por engenheiros de testes de software porque um navegador sem GUI não precisa desenhar conteúdo visual e, portanto, roda mais rápido. Uma das maiores vantagens dos navegadores headless é que eles podem ser executados em servidores sem suporte a GUI.
Imagine o Chrome ou o Firefox, mas você não consegue ver os dados da página sendo carregados e exibidos, você o controla totalmente por meio de código ou interface de linha de comando.
Você já duvidou do poder desses navegadores? Não se engane mais! Eles podem executar quase todas as funções dos navegadores tradicionais:
- Renderizar páginas da web
- Executar JavaScript
- Gerenciar cookies e sessões
- Lidar com solicitações de rede
A única diferença é: eles fazem tudo isso sem exibir nada na tela. Isso os torna perfeitos para automação, testes e tarefas de extração de dados.
Componentes principais de um navegador headless
Observação: Ao usar um navegador headless, preste atenção especial ao mecanismo JavaScript. As diferenças nos mecanismos JS podem às vezes levar a comportamentos inesperados, especialmente ao lidar com aplicativos web modernos.
- Mecanismo do navegador: O componente principal que interpreta HTML, CSS e JavaScript. Os mecanismos comuns incluem Blink (Chrome), Gecko (Firefox) e WebKit (Safari).
- Mecanismo JavaScript: Responsável pela execução do código JavaScript. Exemplos incluem V8 (Chrome) e SpiderMonkey (Firefox).
- Mecanismo de renderização: Em um navegador headless, este componente ainda lida com o layout da página, mas não produz saída visual.
- Pilha de rede: Lida com todas as comunicações de rede, incluindo solicitações e respostas HTTP.
- API ou interface de comando: Os navegadores headless não fornecem uma GUI, mas fornecem uma API ou interface de linha de comando para controle e interação.
- DOM (Document Object Model): Uma representação programática da estrutura de uma página da web.
Usos principais dos navegadores headless
- Rastejamento da web: usado para rastrear conteúdo dinâmico e páginas que precisam executar a renderização de JavaScript. Por exemplo: rastrear informações de produtos, preços gerados dinamicamente, etc.
- Teste automatizado: testar o comportamento da interface do usuário de aplicativos da web, mas sem abrir a janela real. Comumente usado em processos CI/CD para verificar funções de front-end.
- Monitoramento de desempenho: detectar o tempo de carregamento da página da web, desempenho de renderização, etc.
- Geração de screenshots e exportação de PDF: gerar screenshots de páginas da web ou convertê-las em PDFs.
- Monitoramento de sites: detectar se o site está funcionando conforme o esperado e se há erros ou alterações.
Desvantagens e Limitações
- Desafios de depuração: A falta de feedback visual pode tornar alguns problemas mais difíceis de diagnosticar. Requer uma abordagem de depuração diferente dos navegadores convencionais.
- Intensidade de recursos: Embora mais eficientes que os navegadores completos, eles ainda podem consumir muitos recursos para operações em larga escala.
- Renderização incompleta: Alguns elementos visuais ou animações complexos podem não ser renderizados corretamente.
- Detecção por sites: Sites avançados podem detectar e bloquear navegadores headless. Tecnologia adicional é necessária para imitar o comportamento de um navegador "real".
- Curva de aprendizado: Requer conhecimento de programação e compreensão de tecnologias web. Cada solução de navegador headless possui sua própria API e recursos que precisam ser dominados.
Como os navegadores Headless diferem dos navegadores regulares: 5 diferenças principais
| Atributo | Navegador Headless | Navegador Regular |
|---|---|---|
| Interface do Usuário | Sem interface do usuário (invisível) | Interface do usuário completa (janelas, menus, etc.) |
| Interatividade | Não pode ser interagido diretamente com o mouse ou teclado | Os usuários podem operar diretamente (clicar, digitar, etc.) |
| Desempenho | Leve, pois não renderiza gráficos ou exibe conteúdo da página | Mais pesado, pois renderiza gráficos e animações da página |
| Casos de Uso | Teste de automação, web scraping, monitoramento, etc. | Navegação, operações e interações do dia a dia |
| Consumo de Recursos | Relativamente baixo, adequado para servidores ou ambientes de script | Relativamente alto, requer mais recursos do sistema |
5 navegadores Headless populares
Top 1. Scrapeless Scraping Browser - o melhor navegador headless de 2025
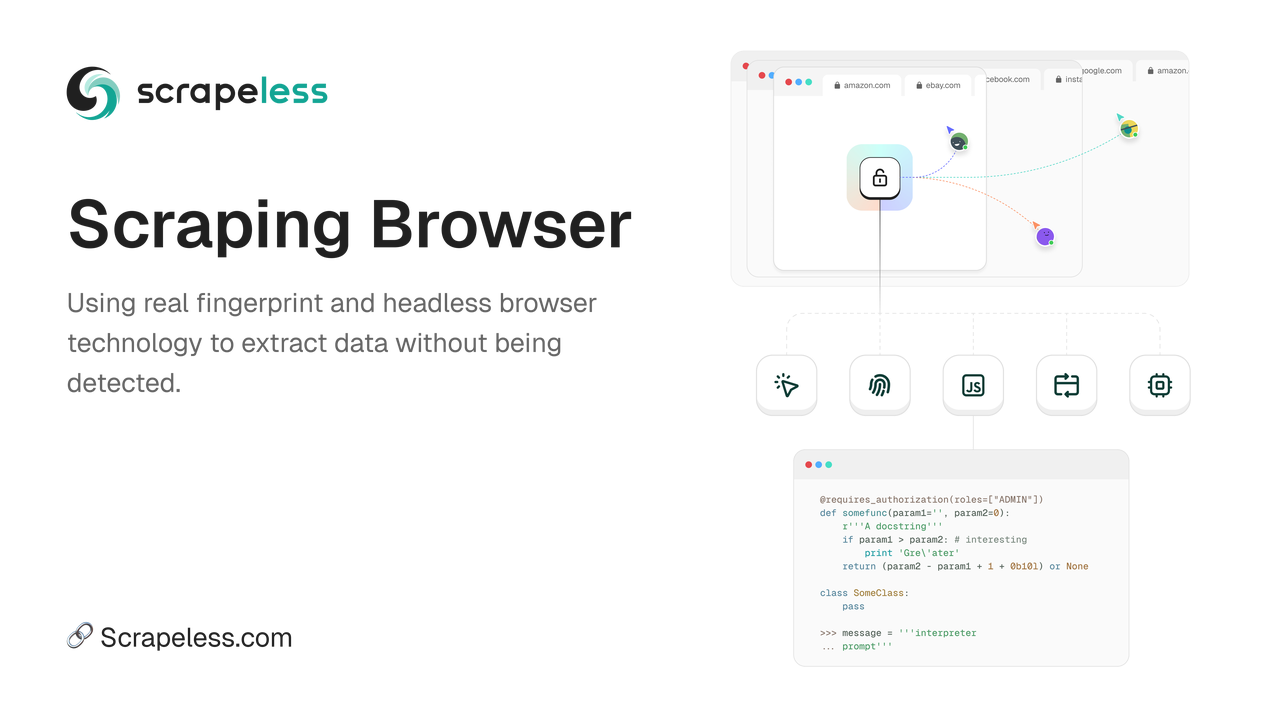
O Scrapeless Scraping Browser é um navegador headless de alto desempenho para scraping, projetado para otimizar o processo de extração de dados de sites dinâmicos. Ele permite que os desenvolvedores operem e supervisionem navegadores headless de forma eficiente sem a necessidade de servidores dedicados, tornando a automação da web e a coleta de dados mais acessíveis.
Passos de uso:
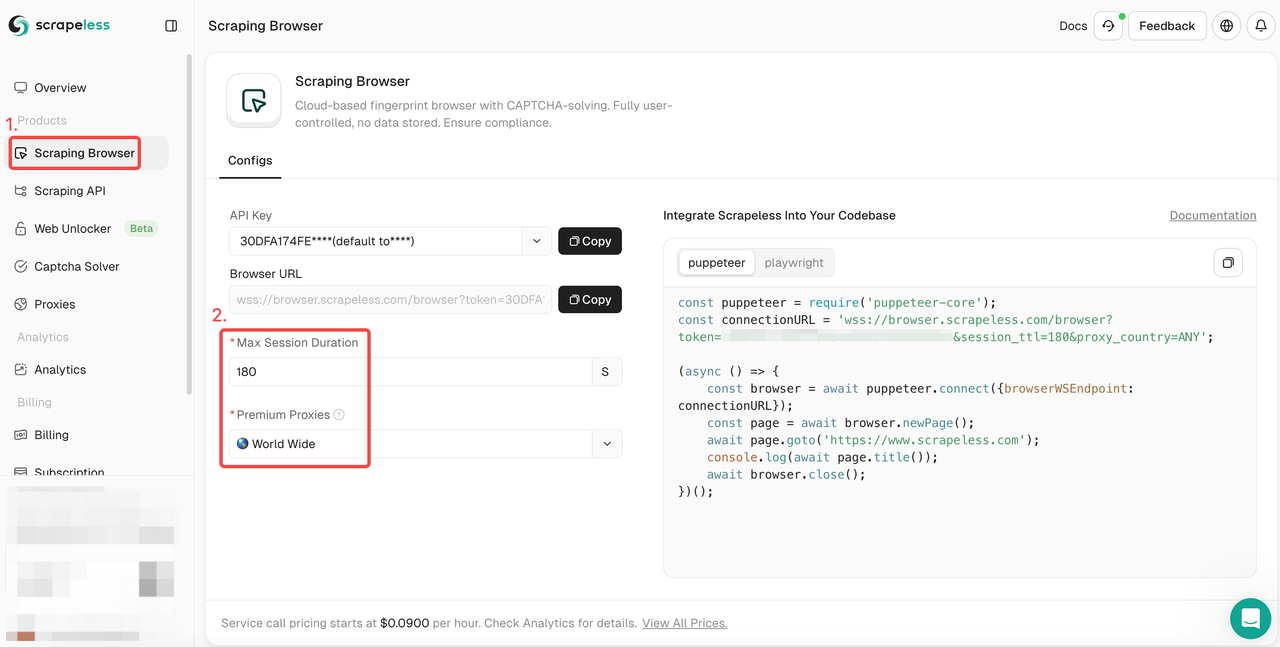
- Passo 1. Faça login em Scrapeless
- Passo 2. Entre no "Scraping Browser"
- Passo 3. Defina os parâmetros de acordo com suas necessidades.
- Passo 4. Copie os códigos de exemplo para integrar ao seu projeto:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Quer obter mais detalhes? Nossa documentação irá ajudá-lo muito:
Puppeteer:
- Instale as bibliotecas necessárias
Primeiro, instale puppeteer-core, uma versão leve do Puppeteer projetada para se conectar a uma instância de navegador existente:
Bash
npm install puppeteer-core- Escreva código para se conectar ao navegador de scraping
No seu código Puppeteer, conecte-se ao Scraping Browser usando o seguinte método:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Dessa forma, você pode aproveitar a infraestrutura do Scraping Browser, incluindo escalabilidade, rotação de IP e acesso global.
- Exemplos:
Aqui estão algumas operações Puppeteer comuns após a integração com o Scraping Browser:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Screenshot
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
- Instale as bibliotecas necessárias
Primeiro, instale playwright-core, uma versão leve do Playwright que se conecta a uma instância de navegador existente:
Bash
npm install playwright-core- Escreva código para se conectar ao navegador de scraping
No código Playwright, conecte-se ao Scraping Browser usando o seguinte método:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Isso permite que você aproveite a infraestrutura do Scraping Browser, incluindo escalabilidade, rotação de IP e acesso global.
- Exemplos
Aqui estão algumas operações Playwright comuns após a integração com o Scraping Browser:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Screenshot
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Artigo relacionado: Melhor navegador de scraping de IA para raspar e monitorar dados de qualquer site
Top 2. Playwright
Desenvolvido pela Microsoft, o Playwright fornece uma única API para gerenciar navegadores baseados em Chromium, Firefox e WebKit. Ele pode ser usado para automatizar vários navegadores com uma API de alto nível. Antes de configurar o Playwright para testes de navegador headless, certifique-se de ter a versão mais recente do Node.JS e npm instalados em seu sistema.
Playwright ganhou rapidamente popularidade na comunidade de automação, em grande parte devido aos seus recursos exclusivos:
- Suporte multi-navegador (Chrome, Firefox, Safari).
- Mecanismo de espera automática poderoso.
- Poderosas capacidades de interceptação de rede.
- Suporte para várias linguagens (JavaScript, Python, .NET, Java).
Top 3. Puppeteer
Desenvolvido pelo Google, o Puppeteer fornece uma API de alto nível para controlar o Chrome ou Chromium via DevTools Protocol. É a escolha preferida de muitos desenvolvedores JavaScript.
- Integração profunda com Chrome/Chromium
- API abrangente para controle do navegador
- Suporte integrado para gerar PDFs e screenshots
Top 4. Selenium
Selenium é uma ferramenta gratuita e de código aberto que é ótima para automação. Ele suporta vários navegadores rodando em diferentes sistemas operacionais. O Selenium Web Driver fornece suporte aprimorado para páginas web dinâmicas, o que pode fornecer excelentes resultados usando o Selenium Headless. Além disso, você pode usar o Headless Chrome ou Headless Firefox para executar o Selenium headless.
- Suporte para múltiplas linguagens de programação
- Compatível com vários navegadores (Chrome, Firefox, Safari, Edge)
- Enorme ecossistema de ferramentas e extensões
Top 5. Cypress
O Cypress se destaca nos testes de ponta a ponta de aplicativos web, especialmente aplicativos de página única. Embora o Cypress se concentre principalmente em testes de ponta a ponta, ele é popular por sua abordagem amigável ao desenvolvedor e poderosas capacidades de depuração.
- Recarregamento ao vivo
- Depuração de viagem no tempo
- Use acesso nativo ao DOM e à camada de rede
O que são testes Headless Chrome?
Se você é um desenvolvedor, provavelmente está familiarizado com os testes acionados pela interface do usuário, que garantem que os aplicativos funcionem corretamente ao longo do tempo. No entanto, um dos principais desafios dos testes acionados pela interface do usuário é a estabilidade, especialmente quando os testes falham em interagir de forma consistente com o navegador.
Os testes de navegador headless oferecem uma solução para esse problema. Ao contrário dos testes acionados pela interface do usuário, ele permite testes de ponta a ponta sem carregar a interface do usuário do aplicativo. Essa abordagem não apenas acelera o processo de teste, mas também garante a interação direta com a página, reduzindo a instabilidade. Como resultado, os testes se tornam mais rápidos, mais confiáveis e altamente eficientes.
Quando você deve usar testes de navegador headless?
Os testes de navegador headless são especialmente úteis em cenários em que os recursos são limitados ou quando as tarefas de automação precisam ser executadas de forma eficiente. Aqui estão alguns casos de uso comuns:
- Interação HTML automatizada
Simule ações do usuário, como envios de formulários, cliques em botões e seleções de menus suspensos. Os navegadores headless permitem que você verifique as respostas a essas interações de forma eficaz. - Teste de execução de JavaScript
Teste a execução de JavaScript em páginas da web para validar conteúdo dinâmico. Isso é particularmente útil para aplicativos com extensa renderização do lado do cliente. - Web Scraping
Ignore medidas básicas anti-scraping, carregue conteúdo dinâmico e extraia dados de páginas da web. Os navegadores headless são ideais para tarefas de scraping envolvendo renderização front-end complexa. - Monitoramento de rede e testes de desempenho
Monitore solicitações de rede, analise tempos de carregamento e identifique gargalos de desempenho, tornando-o valioso para otimização do desempenho do site. - Lidando com solicitações Ajax
Garanta que as páginas que dependem de Ajax para o carregamento de dados sejam exibidas corretamente, capturando e processando essas solicitações. - Gerando screenshots de páginas da web
Crie screenshots para identificar problemas de layout ou conteúdo durante os testes, gerar documentação ou realizar verificações visuais de páginas da web.
Considerações finais
Que dia ótimo! Ao atracar o navio de navegação headless, ficou claro que estávamos na vanguarda de uma revolução na automação da web e na extração de dados.
Os testes de navegador headless são uma maneira mais rápida, confiável e eficiente de testar aplicativos web em um navegador. No entanto, quando você testa com um navegador de desktop real, ele fornece uma representação verdadeira do seu site.
Você pode ser headless e real ao mesmo tempo? Claro! O Scrapeless Scraping Browser combina o melhor dos dois mundos. Ele permite que você automatize páginas da web facilmente.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


