
最強AIスクレイピングブラウザ:あらゆるウェブサイトからデータのスクレイピングと監視
Specialist in Anti-Bot Strategies
ウェブスクレイピングは、ビジネスや製品が遅れをとらないために不可欠です。ウェブデータは、平均価格から最新の必須機能まで、潜在的な消費者についてほぼすべてを教えてくれます。
どのようにクロール負担を軽減し、作業効率を向上させることができますか?
高品質なデータを取得するには、最高のウェブスクレイピングツールを使用することが不可欠であるため、仕事に最適なツールを入手する必要があります。
ウェブスクレイピングについてすべて学び、最高のスクレイピングブラウザを入手するには、今すぐこの記事を読み始めてください!
なぜデータスクレイピングが不可欠なのか?
古い情報は、企業が資源を非効率的に配分したり、最新の収益機会を逃したりする原因となります。ホリデー前の週の消費財価格データに迅速にアクセスし、翌月の価格設定を策定する必要があることは間違いありません。
ウェブデータは、売上と生産性を大幅に向上させるのに役立ちます。現代のインターネットは非常に活発で、ユーザーは毎日2.5京バイトもの膨大なデータを生成しています。スタートアップ企業であっても、数十年の歴史を持つ大企業であっても、インターネットデータの有用な情報は、競合他社から潜在顧客を引きつけ、製品の購入を促すのに役立ちます。
しかし、膨大な量の潜在顧客データがあるということは、データを手動で抽出するのに一生かかっても追いつけない可能性があることを意味します。また、手動でのデータ抽出には様々な課題があります!
データのスクレイピングと監視における課題
1. アンチスクレイピング対策
多くのウェブサイトでは、スクレイピング活動を検出してブロックするための様々なテクニックが展開されています。これらの対策は、データ保護と不正使用防止のために実施されています。
- CAPTCHA: これは、人間とボットの活動を区別するために設計されたパズルです。CAPTCHAの一般的な形式には、歪んだテキスト、画像認識タスク、またはクリックして選択するアクションが含まれます。
- レート制限: ウェブサイトでは、サーバーの過負荷を防ぐために、特定の期間に単一のIPアドレスからのリクエスト数を制限することがあります。短時間に多くのリクエストを送信すると、IPがブロックされる可能性があります。
- IPブロック: ウェブサイトは、リクエストが行われたIPアドレスを追跡することがよくあります。スクレイピング動作を検出した場合、そのIPからのアクセスをブロックまたは制限することがあります。
- JavaScriptレンダリング: 多くの最新のウェブサイトでは、コンテンツを動的に読み込むためにJavaScriptを使用しています。従来のスクレイピング方法(RequestsやBeautifulSoupなどのライブラリを使用)では、このようなコンテンツのスクレイピングに苦労することがあります。
- ブラウザフィンガープリンティング: ウェブサイトは、画面解像度、インストールされているプラグイン、その他の特性など、ブラウザの動作とフィンガープリントを分析することで、非人間のトラフィックを検出できます。
CAPTCHAやアンチボット検出によってブロックされてイライラしていませんか?
Scrapelessは99.9%のウェブサイトをアンロックします
無料でお試しください!
2. 動的で複雑なウェブサイト構造
ウェブサイトは、JavaScriptを介してデータを動的に読み込むフレームワークを使用して構築されることがよくあります。これらの動的なウェブサイトは、ページの読み込み後にコンテンツを読み込むためにAJAXリクエストを使用することが多く、従来の方法ではスクレイピングが困難です。
- JavaScriptヘビーなサイト: ニュースサイトやソーシャルメディアプラットフォームなどのウェブサイトからのコンテンツのスクレイピングには、JavaScriptをレンダリングする機能が必要になることがよくあります。これがないと、コンテンツはページのHTMLソースコードで使用できない可能性があります。
- 無限スクロール: 無限スクロール(例:ソーシャルメディアやeコマースサイト)を使用するウェブサイトでは、ユーザーがスクロールダウンすると、より多くのコンテンツが読み込まれます。これは、必要なすべてのデータがいつ読み込まれたか、そしてそれを効率的に抽出する方法を決定する際に課題となります。
- 複雑なHTML構造: 複雑なHTML構造(例:ネストされた要素、不規則なタグ名、または一貫性のないレイアウト)を持つウェブサイトでは、コンテンツの解析が困難になる可能性があります。
3. アンチボットソリューション
ウェブサイトでは、データ保護のために高度なアンチボットソリューションがますます展開されており、スクレイピングをより困難な作業にしています。
- デバイスフィンガープリンティング: ウェブサイトでは、ブラウザのフィンガープリント、ネットワーク構成、さらにはマウスの動きを分析するなど、高度なテクニックを使用してボットのような動作を検出できます。
- 行動分析: 一部のウェブサイトでは、マウスの動き、クリック、スクロール動作など、ユーザーのインタラクションを追跡してボットの動作を検出します。スクレイパーが非人間の行動をとると、アンチボット対策がトリガーされる可能性があります。
スクレイピングブラウザの動作方法
ステップ 1. HTTPリクエストの送信
ステップ 2. ウェブページのレンダリング
ステップ 3. ウェブページのナビゲーション
ステップ 4. データの抽出
ステップ 5. 動的コンテンツの処理
ステップ 6. セッションとCookieの管理
ステップ 7. アンチスクレイピングメカニズムへの対処
ステップ 8. エラーと障害の処理
ステップ 9. データの保存と出力
なぜスクレイピングブラウザは課題を回避できるのか?
スクレイピングブラウザは、主に次の重要な技術に依存することで、ウェブサイトの監視とブロックを効果的に回避できます。
1. 組み込みCAPTCHAソルバー
スクレイピングブラウザはCAPTCHA解決サービスを統合しており、ウェブサイトのCAPTCHAチャレンジを自動的に識別して解決できます。
2. IPローテーション
IPローテーションにより、スクレイピングブラウザはリクエスト送信元のIPアドレスを頻繁に変更できるため、単一のIPアドレスが短時間に大量のリクエストを行うことを防ぐことができます。ローテーションプロキシを使用すると、各リクエストは異なるIPアドレスを使用できるため、IPブロックを回避できます。
3. ユーザーエージェントのランダム化
ユーザーエージェントのランダム化により、スクレイピングブラウザは異なるブラウザ、デバイス、およびオペレーティングシステムからのリクエストをシミュレートできるため、クローラーとして識別されるリスクを軽減できます。ユーザーエージェント文字列を絶えず変更することで、クローラーは、単一の自動化ツールではなく、異なるユーザーからのリクエストのように見せることができます。
4. リアルフィンガープリンティング
スクレイピングブラウザは、識別を回避するためにフィンガープリントを変更または偽造するのではなく、実際のユーザーのブラウザフィンガープリントをシミュレートします。リアルフィンガープリントを使用すると、同じデバイスとブラウザを使用してウェブサイトにアクセスする他のユーザーと同様に、クローラーを通常のユーザーのように動作させることができます。
最高のAIスクレイピングブラウザ - Scrapeless
Scrapelessスクレイピングブラウザは、高性能なサーバーレスプラットフォームを提供します。動的なウェブサイトからデータ抽出のプロセスを効果的に簡素化します。開発者は、専用のサーバーなしでヘッドレスブラウザを実行、管理、監視できるため、効率的なウェブ自動化とデータ収集が可能になります。
なぜScrapelessはウェブスクレイピングに最適なのか?
Scrapelessスクレイピングブラウザは、195か国以上をカバーする7,000万以上の住宅IPアドレス、強力なウェブアンロッカー、そして非常に安定したCAPTCHAソルバーを備えたグローバルネットワークを備えています。信頼性が高くスケーラブルなウェブスクレイピングソリューションが必要なユーザーに最適です。
Scrapelessスクレイピングブラウザの使い方
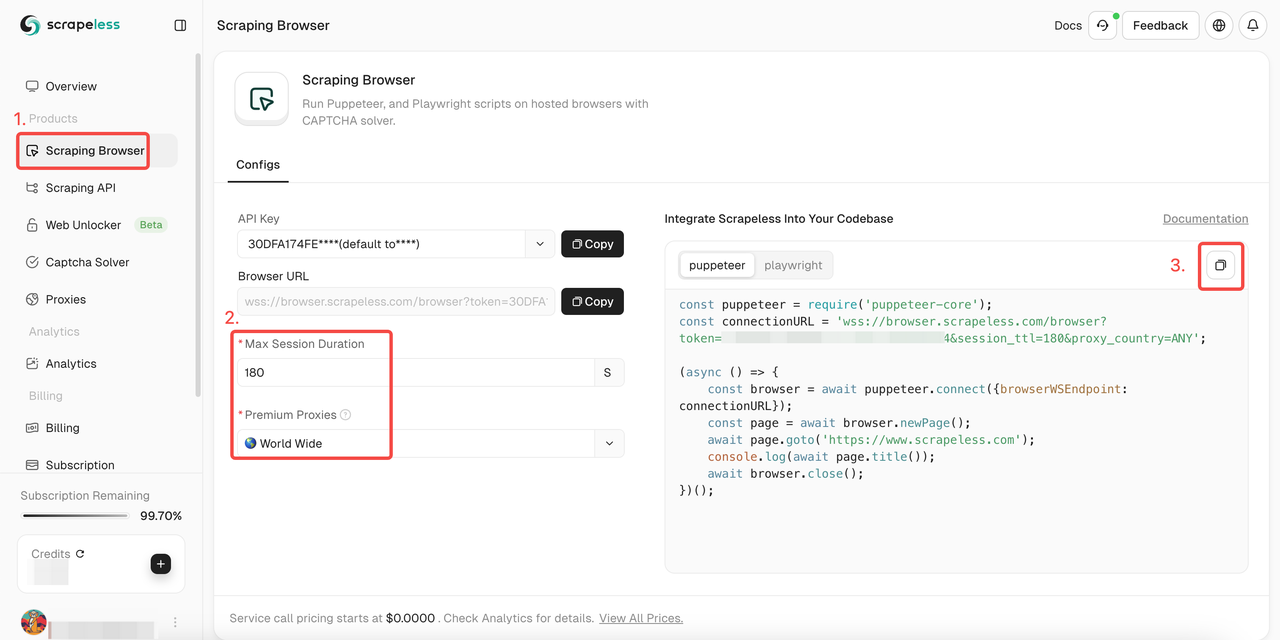
- ステップ1. Scrapelessにサインインする
- ステップ2. 「スクレイピングブラウザ」を入力する
- ステップ3. 必要に応じてパラメーターを設定する
- ステップ4. プロジェクトに統合するためのサンプルコードをコピーする:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();詳細を知りたいですか?ドキュメントが役に立ちます!
Puppeteer:
ステップ1. 必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するように設計されたPuppeteerの軽量バージョンであるpuppeteer-coreをインストールします。
Bash
npm install puppeteer-coreステップ2. スクレイピングブラウザに接続するためのコードの記述
Puppeteerコードで、次の方法を使用してスクレイピングブラウザに接続します。
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();これにより、スケーラビリティ、IPローテーション、グローバルアクセスなど、スクレイピングブラウザのインフラストラクチャを活用できます。
例:
スクレイピングブラウザと統合した後の一部の一般的なPuppeteer操作を以下に示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
ステップ1. 必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するPlaywrightの軽量バージョンであるplaywright-coreをインストールします。
Bash
npm install playwright-coreステップ2. スクレイピングブラウザに接続するためのコードの記述
Playwrightコードで、次の方法を使用してスクレイピングブラウザに接続します。
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();これにより、スケーラビリティ、IPローテーション、グローバルアクセスなど、スクレイピングブラウザのインフラストラクチャを活用できます。
例
スクレイピングブラウザと統合した後の一部の一般的なPlaywright操作を以下に示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();ウェブスクレイパーを選択する際に考慮すべき8つの要素
- データ抽出機能: 優れたウェブスクレイピングツールは、様々なデータ形式をサポートし、静的HTMLページやJavaScriptを使用した動的なウェブサイトなど、様々なウェブページ構造からコンテンツを抽出できます。
- 使いやすさ: ツールの学習曲線、ユーザーインターフェース、および利用可能なドキュメントを評価します。ツールを使用する人は、ツールの複雑さを理解する必要があります。
- スケーラビリティ: 大規模なデータ抽出を処理するツールの能力を考慮します。パフォーマンスと、増加するデータ量またはリクエストに対応する能力という点でのスケーラビリティは重要です。
- 自動化機能: 利用可能な自動化の程度を確認します。スケジューリング機能、CAPTCHAの自動処理、Cookieとセッションの自動管理機能を探します。
- IPローテーションとプロキシサポート: ツールは、ブロックされないように強力なIPローテーションとプロキシ管理サポートを提供する必要があります。
- エラー処理と復旧: 接続の切断や予期しないサイトの変更など、ツールがどのようにエラーを管理するかを調べます。
- 他のシステムとの統合: データベース、クラウドサービス、またはデータ分析ツールなどの他のシステムやプラットフォームとシームレスに統合するかどうかを判断します。APIとの互換性も大きな利点です。
- データクレンジングと処理: 生データから使用可能な情報へのワークフローを合理化するために、組み込みまたは簡単に統合できるデータクレンジングと処理機能を探します。
結論
ウェブスクレイピングロボットは、ウェブサイトによって容易に識別され、ブロックにつながります!スムーズなデータ抽出プロセスを取得するにはどうすればよいですか?
Scrapelessスクレイピングブラウザは、組み込みのウェブアンブロッカー、CAPTCHAソルバー、ローテーションIP、およびインテリジェントプロキシにより、ウェブサイトのブロックを簡単に回避し、データスクレイピングを実現できます!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


