
Como raspar o Google Scholar com Python?
Expert Network Defense Engineer
O Google Scholar é um mecanismo de busca para acessar dados acadêmicos. Com o Google Scholar, você pode recuperar artigos científicos, trabalhos de pesquisa e dissertações. No entanto, a pesquisa acadêmica geralmente requer a coleta e análise de grandes quantidades de dados dos resultados de pesquisa do Google Scholar.
Navegar manualmente por inúmeros resultados é uma tarefa assustadora. É por isso que um scraper confiável do Google Scholar pode ajudar a tornar o processo menos doloroso. Com a automação, você pode raspar o Google Scholar para extrair dados como títulos, autores e citações de cada resultado em uma página do Google Scholar em segundos.
Neste tutorial, você aprenderá como construir um scraper eficaz do Google Scholar fazendo solicitações HTTP usando a API Scrapeless Google Scholar e Python.
Continue rolando para saber mais!
🎓 O que é o Google Scholar Scraper?
Um scraper do Google Scholar é uma ferramenta projetada para extrair dados acadêmicos publicamente disponíveis do Google Scholar, como trabalhos de pesquisa, citações, autores e detalhes de publicação. Ele permite que pesquisadores, acadêmicos e organizações reúnam insights valiosos para análise, rastreamento de tendências e pesquisa acadêmica. No entanto, a raspagem da web do Google Scholar apresenta desafios significativos devido aos seus robustos mecanismos anti-raspagem.
Por que os dados do Google Scholar são valiosos?
- Revisão e Pesquisa: Encontre artigos, teses e livros relacionados à pesquisa ou projetos acadêmicos. Compare diferentes métodos e estruturas teóricas.
- Análise Acadêmica: Identifique tendências e tópicos emergentes em publicações acadêmicas e calcule métricas acadêmicas, como o índice H e a contagem de citações.
- Potencial de Colaboração: Identifique especialistas em um campo específico para potenciais colaborações, conferências ou revisões por pares.
- Desenvolvimento de Produto: Profissionais de P&D podem raspar o Google Scholar para pesquisas aprofundadas, avanços e para rastrear publicações de concorrentes em campos científicos ou tecnológicos relacionados.
Desafios e Soluções de Rastreamento do Google Scholar
O Google Scholar é um poderoso mecanismo de busca acadêmico que fornece um grande número de artigos acadêmicos, patentes, livros e artigos de conferências. No entanto, a raspagem de dados do Google Scholar enfrenta muitos desafios técnicos e legais. Aqui estão os principais problemas que você pode encontrar ao raspar o Google Scholar na web e suas soluções:
| Desafios | Descrição | Soluções |
|---|---|---|
| Bloqueio de IP | Solicitações frequentes causarão bloqueio de IP. | Use um proxy. Rodeie vários endereços IP para evitar que o IP principal seja bloqueado. |
| CAPTCHA | O Google pode pedir aos usuários que insiram um CAPTCHA para confirmar que são humanos. | Escolha um serviço que possa resolver automaticamente CAPTCHAs para você. |
| Limitação da Taxa de Solicitação | Taxas de solicitação excessivas serão detectadas e bloqueadas. | Altere o agente do usuário e espere alguns segundos entre as solicitações para imitar o comportamento humano. |
| Carregamento de Conteúdo Dinâmico | O Google Scholar usa JavaScript para carregar conteúdo dinamicamente. | Use um navegador sem cabeça como Puppeteer ou Selenium para renderizar JavaScript e extrair conteúdo. |
Além disso, existem restrições de API para raspar o Google Scholar. Como o Google Scholar não possui uma API oficial, a raspagem da web do Google Scholar requer a análise direta de páginas da web, o que aumenta a complexidade e a instabilidade.
Felizmente, você pode tentar usar poderosos serviços de API de terceiros. Eles garantem extração de dados conveniente, rápida e precisa. Além disso, entre muitos fornecedores de serviços de API, o Scrapeless também possui serviço de decodificação de CAPTCHA integrado, proxy de rotação e desbloqueador da web.
Passo a Passo: Crie seu Scraper do Google Scholar em Python
A seguir, começaremos a rastrear o Google Scholar usando o scraper do Google Scholar em Python. Você verá como obter dados como título do artigo, informações de publicação e título do artigo.
Passo 1. Configurar o ambiente
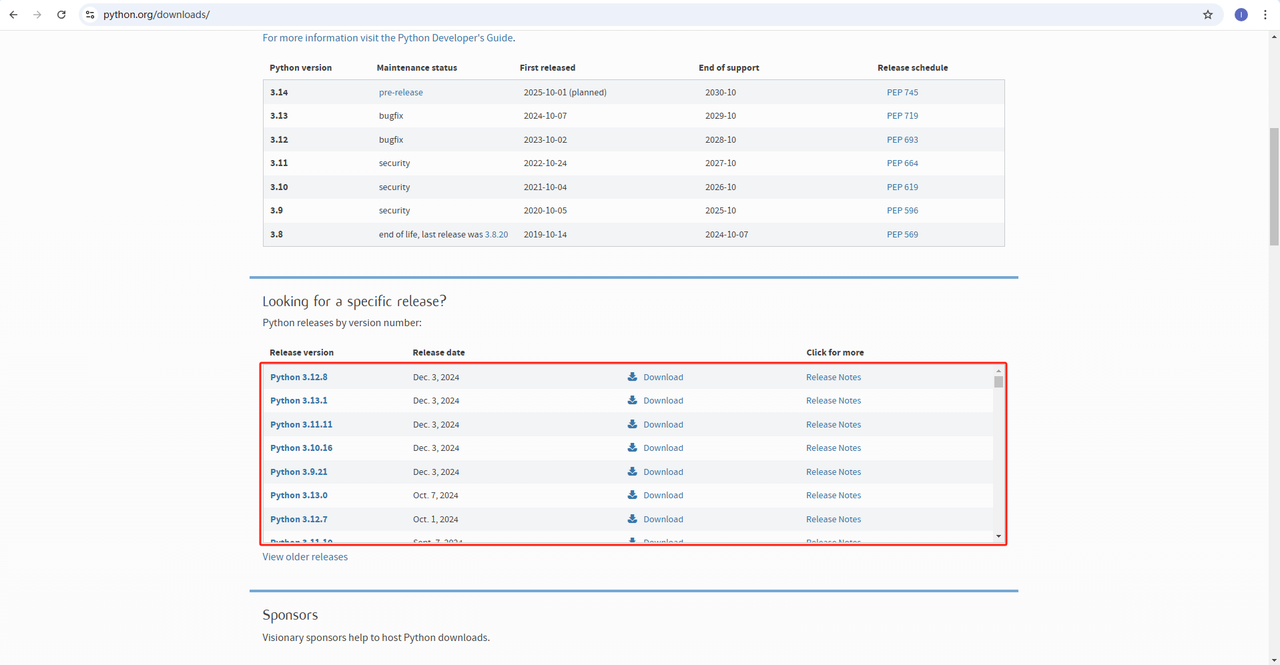
Python: O software https://www.python.org/downloads/ é o núcleo da execução do Python. Você pode baixar a versão que precisamos no site oficial, conforme mostrado abaixo. No entanto, não é recomendado baixar a versão mais recente. Você pode baixar 1.2 versões antes da versão mais recente.
IDE Python: Qualquer IDE que suporte Python funcionará, mas recomendamos o PyCharm. É uma ferramenta de desenvolvimento projetada especificamente para Python. Para a versão do PyCharm, recomendamos a edição gratuita PyCharm Community Edition.
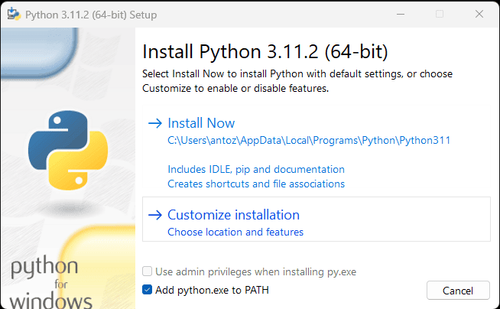
Observação: Se você for um usuário do Windows, não se esqueça de marcar a opção "Adicionar python.exe ao PATH" durante o assistente de instalação. Isso permitirá que o Windows use o Python e os comandos no terminal. Como o Python 3.4 ou posterior o inclui por padrão, você não precisa instalá-lo manualmente.
Agora você pode verificar se o Python está instalado abrindo o terminal ou prompt de comando e inserindo o seguinte comando:
Bash
python --versionPasso 2. Instalar Dependências
É recomendável criar um ambiente virtual para gerenciar as dependências do projeto e evitar conflitos com outros projetos Python. Navegue até o diretório do projeto no terminal e execute o seguinte comando para criar um ambiente virtual chamado google_scholar_env:
Bash
python -m venv google_scholar_envAtive o ambiente virtual com base em seu sistema:
- Windows:
Bash
google_scholar_env\Scripts\activate- MacOS/Linux:
Bash
source google_scholar_env/bin/activateApós ativar o ambiente virtual, instale as bibliotecas Python necessárias para raspagem da web. A biblioteca para enviar solicitações em Python é requests, e a biblioteca principal para raspar dados é BeautifulSoup4. Instale-as usando os seguintes comandos:
Bash
pip install requests
pip install beautifulsoup4Passo 3. Raspar Dados
Abra o Google Scholar em seu navegador e pesquise por "biologia". Abaixo está o resultado da pesquisa:
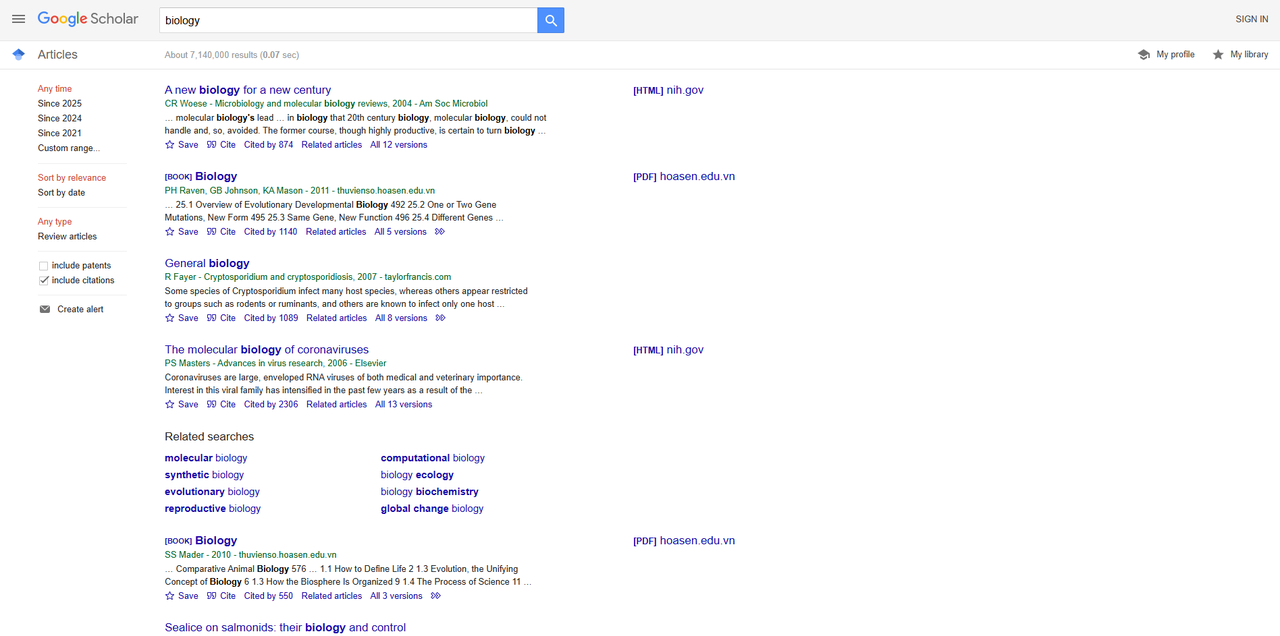
- Raspar Títulos:
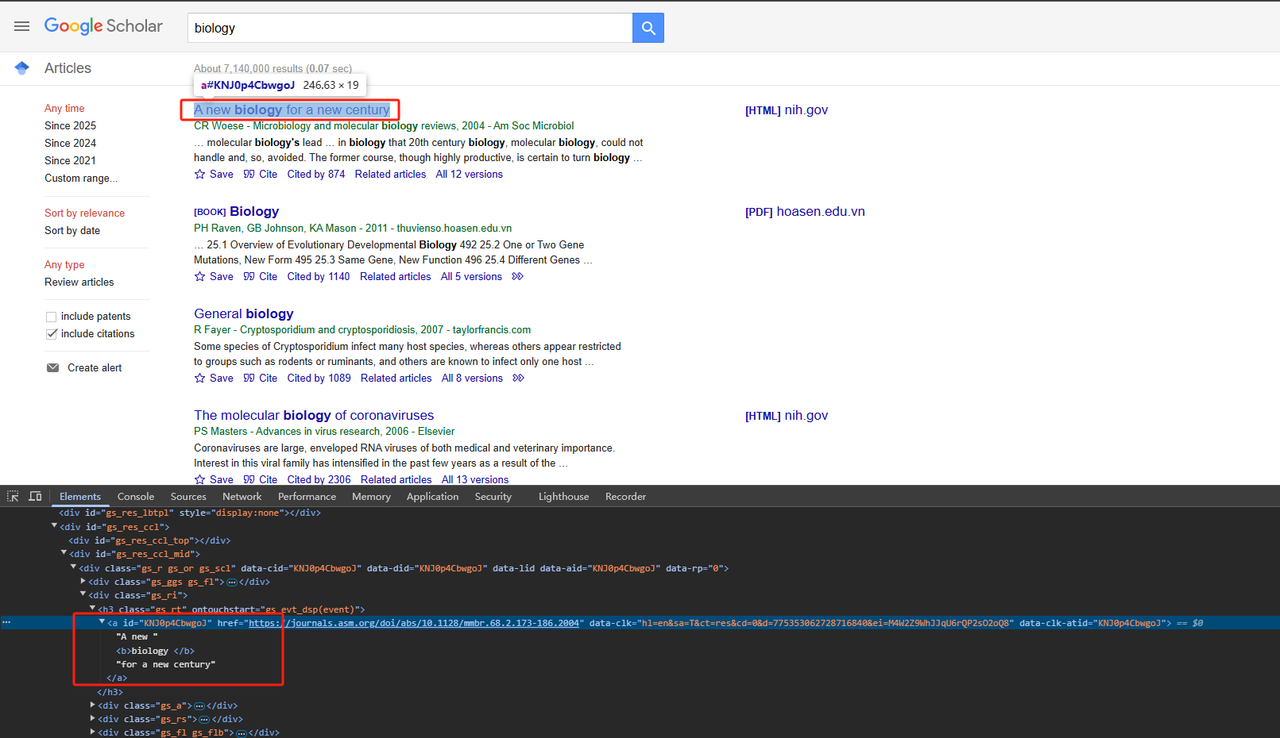
Analise os elementos de página HTML relevantes. O código Python detalhado é o seguinte:
Python
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt a')
return title_element .text.strip()- Raspar Informações de Publicação:
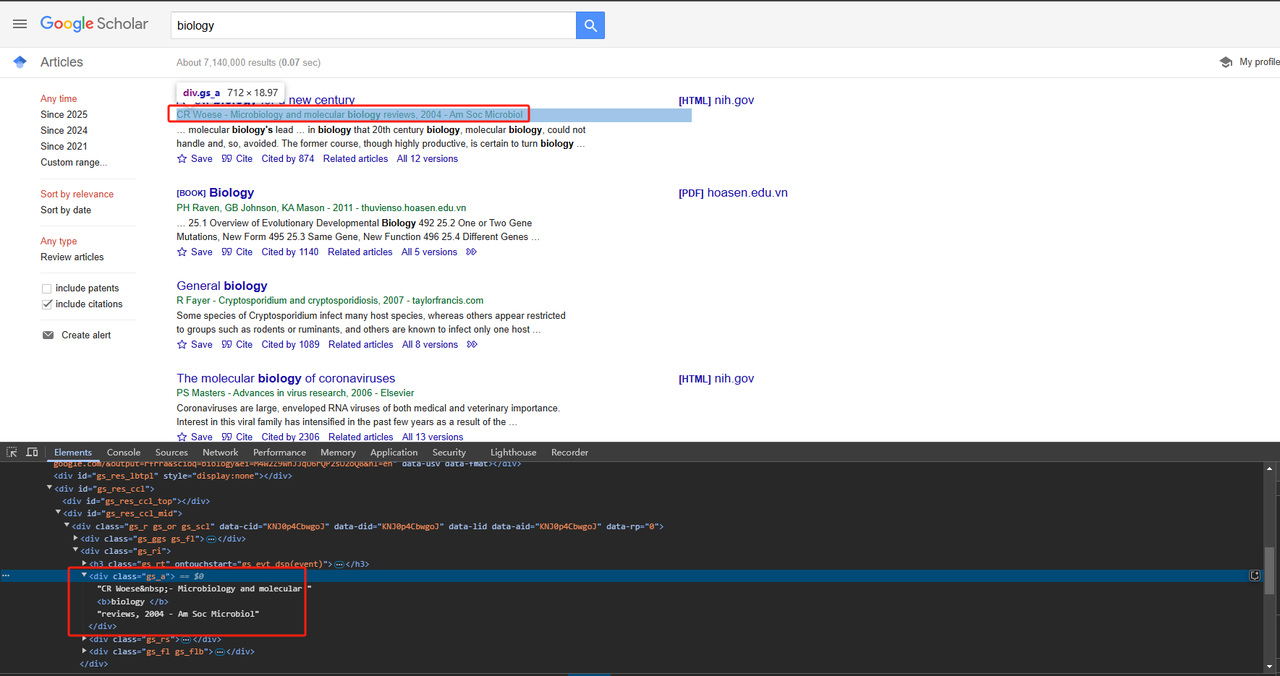
As informações de publicação podem ser raspadas diretamente usando o atributo de classe div. O código Python detalhado é o seguinte:
Python
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
return publication_info_element .text.strip()- Raspar Trechos de Artigo:
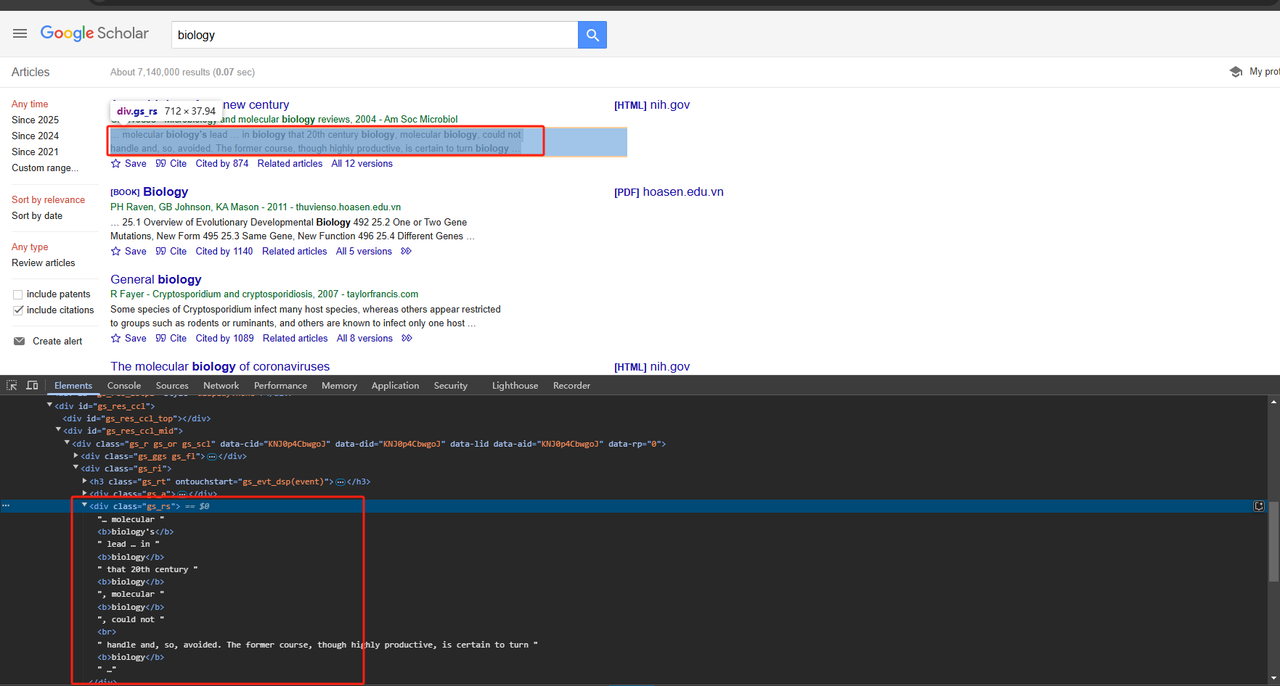
Os trechos de artigo também podem ser raspados diretamente usando o atributo de classe div. O código Python detalhado é o seguinte:
Python
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
return snippet_element .text.strip()Como precisamos raspar todos os dados na página, não apenas um, precisamos percorrer e raspar os dados acima. O código completo é o seguinte:
Python
# Importar bibliotecas necessárias
import time
import requests
from bs4 import BeautifulSoup
import json
# Função para raspar elementos de listagem do google_scholar
def scrape_listings(soup):
return soup.select('div.gs_r.gs_or.gs_scl')
# Função para raspar o título do google_scholar
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt > a')
print(title_element.text)
return title_element.text.strip()
# Função para raspar informações de publicação do google_scholar
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
print(publication_info_element.text)
return publication_info_element.text.strip()
# Função para raspar o trecho do google_scholar
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
print(snippet_element.text)
return snippet_element.text.strip()
# Função principal
def main():
# Fazer uma solicitação à URL do google_scholar e analisar o HTML
url = 'https://scholar.google.com/scholar?hl=en&q=biology'
response = requests.get(url, verify=False)
time.sleep(2)
soup = BeautifulSoup(response.text, 'html.parser')
# Raspar listagens de estudiosos
listings = scrape_listings(soup)
print(listings)
# Iterar por cada listagem e extrair informações de estudiosos
scholar_data = []
for listing in listings:
title = scrape_scholar_title(listing)
publication_info = scrape_scholar_publication_info(listing)
snippet = scrape_scholar_snippet(listing)
# Armazenar informações de estudiosos em um dicionário
scholar_info = {
'title': title,
'publication_info': publication_info,
'snippet': snippet
}
scholar_data.append(scholar_info)
# Salvar resultados em um arquivo JSON
with open('google_scholar_data.json', 'w') as json_file:
json.dump(scholar_data, json_file, indent=4)
if __name__ == "__main__":
main()Passo 4. Resultados de Saída
Um arquivo chamado google_scholar_data.json será gerado em seu diretório PyCharm. A saída é a seguinte:
JSON
[
{
"title": "A new biology for a new century",
"publication_info": "CR Woese\u00a0- Microbiology and molecular biology reviews, 2004 - Am Soc Microbiol",
"snippet": "\u2026 molecular biology's lead \u2026 in biology that 20th century biology, molecular biology, could not \nhandle and, so, avoided. The former course, though highly productive, is certain to turn biology \u2026"
},
{
"title": "Biology",
"publication_info": "PH Raven, GB Johnson, KA Mason - 2011 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 25.1 Overview of Evolutionary Developmental Biology 492 25.2 One or Two Gene \nMutations, New Form 495 25.3 Same Gene, New Function 496 25.4 Different Genes\u00a0\u2026"
},
{
"title": "General biology",
"publication_info": "R Fayer\u00a0- Cryptosporidium and cryptosporidiosis, 2007 - taylorfrancis.com",
"snippet": "Some species of Cryptosporidium infect many host species, whereas others appear restricted \nto groups such as rodents or ruminants, and others are known to infect only one host \u2026"
},
{
"title": "The molecular biology of coronaviruses",
"publication_info": "PS Masters\u00a0- Advances in virus research, 2006 - Elsevier",
"snippet": "Coronaviruses are large, enveloped RNA viruses of both medical and veterinary importance. \nInterest in this viral family has intensified in the past few years as a result of the \u2026"
},
{
"title": "Biology",
"publication_info": "SS Mader - 2010 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 Comparative Animal Biology 576 \u2026 1.1 How to Define Life 2 1.3 Evolution, the Unifying \nConcept of Biology 6 1.3 How the Biosphere Is Organized 9 1.4 The Process of Science 11\u00a0\u2026"
},
{
"title": "Sealice on salmonids: their biology and control",
"publication_info": "AW Pike, SL Wadsworth\u00a0- Advances in parasitology, 1999 - Elsevier",
"snippet": "\u2026 This review examines the voluminous literature on the biology and control of sealice and \nbrings together ideas for developing our knowledge of these organisms. Research on the \u2026"
},
{
"title": "Biology data book",
"publication_info": "PL Altman, DS Dittmer - 1972 - bionumbers.hms.harvard.edu",
"snippet": "Embryos were raised at constant temperature in circulating nalis\" u 10% smaller. For \nadditional information on salmowater, from three hours after fertilization. Age= time from nids, \u2026"
},
{
"title": "The biology of Pseudocalanus",
"publication_info": "CJ Corkett, IA McLaren\u00a0- Advances in marine biology, 1979 - Elsevier",
"snippet": "Publisher Summary Pseudocalanus is typical of most crustaceans in that after hatching at \nan early stage of development it adds successively new segments and appendages. \u2026"
},
{
"title": "Introduction to a submolecular biology",
"publication_info": "A Szent-Gyorgyi - 2012 - books.google.com",
"snippet": "\u2026 Biology is the science of the improbable and I think it is on principle that the body works \nonly with reactions which are statistically improbable. If metabolism were built of a series of \u2026"
},
{
"title": "The biology of mycorrhiza.",
"publication_info": "JL Harley - 1959 - cabidigitallibrary.org",
"snippet": "Since Dr. Rayner published her book on mycorrhiza in 1927 there has not been a comprehensive \naccount of this subject, although the need for a critical re-appraisal of the extensive \u2026"
}
]Implante a API Scrapeless Google Scholar Facilmente
Por que a API Scrapeless Scholar é crucial?
Absolutamente! Você só precisa de um serviço de API que seja acessível, estável e seguro. No entanto, encontrar um que atenda a todos esses critérios é incrivelmente desafiador! Felizmente, a API Scrapeless Google Scholar se destaca entre muitos produtos de API:
- 🔴 Economia de custos: A API do Google Scholar custa apenas US$ 0,80, e com uma assinatura de US$ 49, você obtém um desconto de 10%!
- 🔴 Dados precisos: Nossos desenvolvedores analisam constantemente os algoritmos e restrições de raspagem do Google para garantir que a API seja atualizada e otimizada.
- 🔴 Estável e com alta taxa de sucesso: O Scrapeless garante uma taxa de sucesso de 99% e confiabilidade. A estabilidade e a precisão da raspagem do Google Trends atingiram quase 100%! Atualmente, o tempo médio de resposta é de cerca de 3 segundos, significativamente mais rápido do que a maioria dos provedores de API. Além disso, os dados são retornados em um formato JSON padronizado, tornando-os prontos para uso imediato.
O Scrapeless já conquistou a confiança de mais de 2.000 usuários corporativos! Junte-se ao Discord agora para reivindicar sua avaliação gratuita! Apenas 1.000 vagas estão disponíveis por tempo limitado — aja rápido!
Leitura adicional:
- Como raspar os resultados de pesquisa do Google?
- Como raspar tendências do Google com Python?
- Obtenha a passagem aérea mais barata com o Google Flights Scraper!
Usando passos:
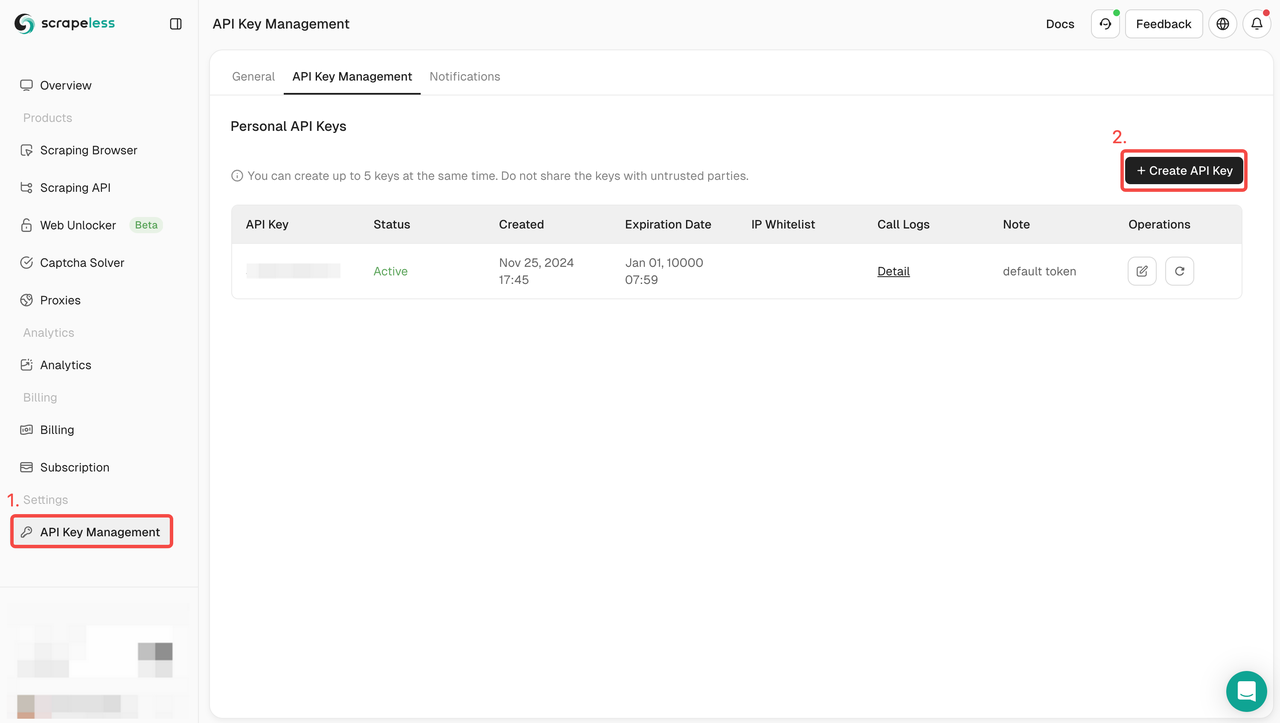
Passo 1. Obtenha o token da API
- Faça login no Painel.
- Navegue até Gerenciamento de chave de API.
- Clique em Criar para gerar sua chave de API exclusiva.
- Você só precisa clicar na chave de API para copiá-la.
Passo 2: Use sua chave de API no código
Agora você só precisa configurar os parâmetros na documentação da API para raspar os dados necessários do Google Scholar.
- Visite a Documentação da API.
- Clique em "Experimente" para o endpoint desejado.
- Configure os parâmetros que você precisa no corpo do código.
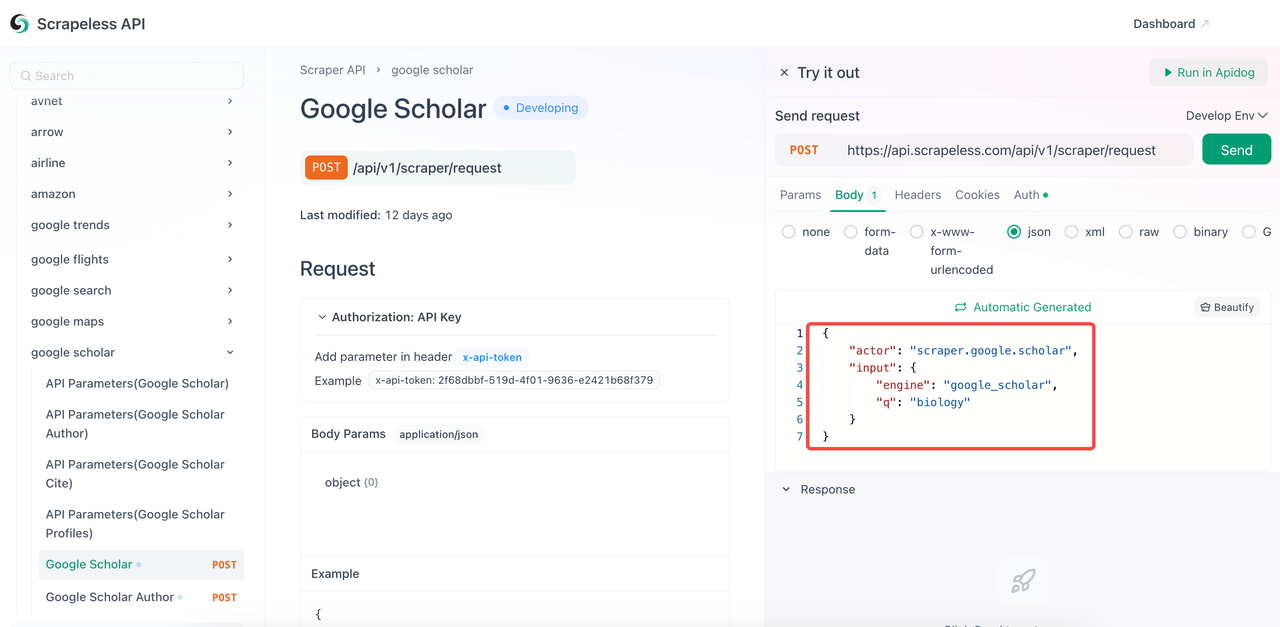
- Substitua a palavra-chave
qpela que você deseja consultar. - O parâmetro
engineé obrigatório e seu valor deve sergoogle_scholar. No entanto, você pode adicionar parâmetros mais específicos, comogoogle_scholar_author. - Parâmetros comuns:
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
engine |
VERDADEIRO | Definido como google_scholar para usar esta API. |
q |
VERDADEIRO | Consulta de pesquisa (por exemplo, "aprendizado de máquina"). |
cites |
FALSO | ID exclusivo para encontrar artigos que citam. |
as_ylo |
FALSO | Filtrar resultados de um ano específico. |
as_yhi |
FALSO | Filtrar resultados até um ano específico. |
hl |
FALSO | Configuração de idioma (padrão: en). |
num |
FALSO | Número de resultados (1-20, padrão: 10). |
- Insira sua chave de API no campo "Autenticação".
- Clique em "Enviar" para obter a resposta de raspagem.
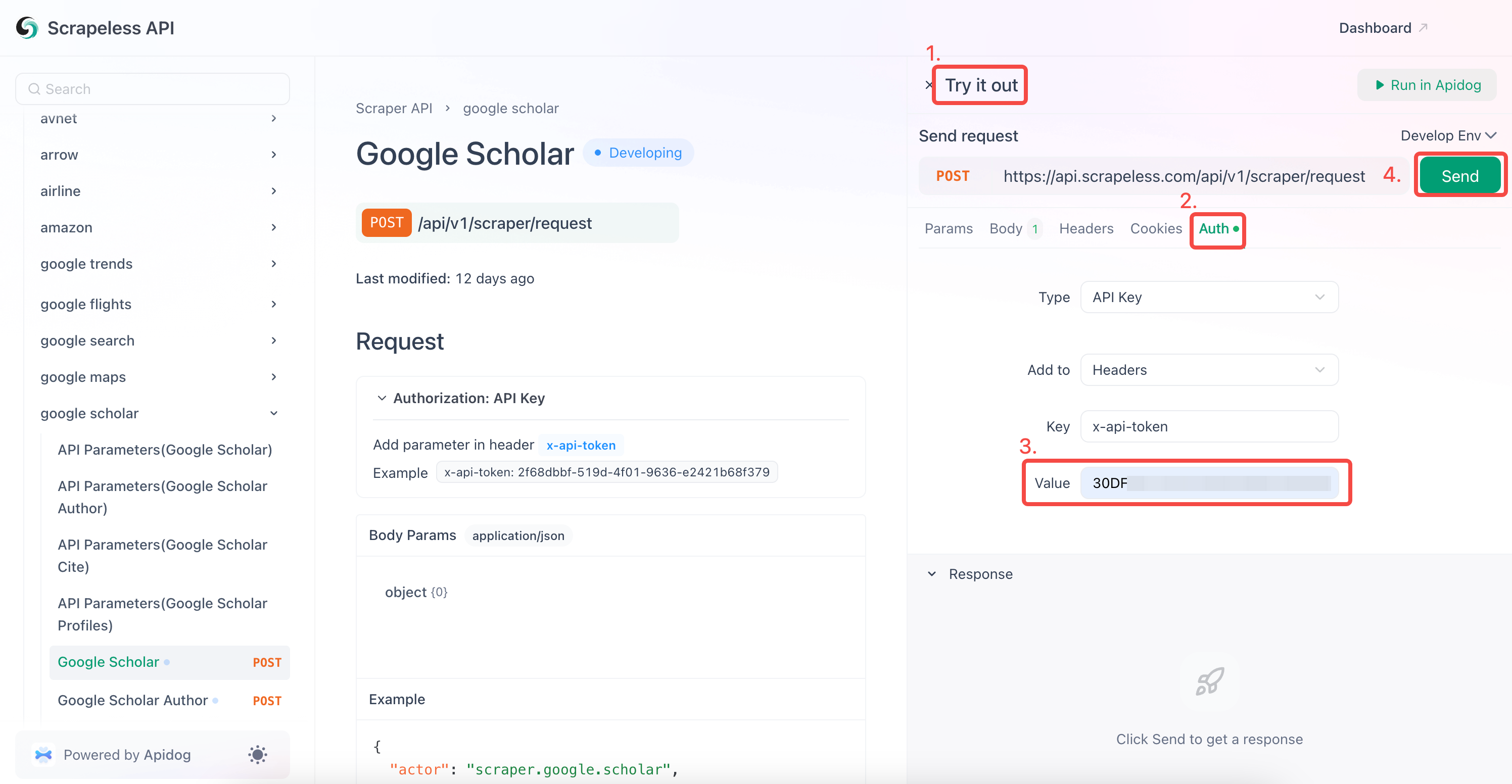
O Scrapeless Google Scholar também suporta rastreamento:
- Autor do Google Scholar
- Citar Google Scholar
- Perfis do Google Scholar
Você também pode integrar diretamente nosso código de referência ao seu programa. Basta substituir your_token pelo token que você solicitou:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = your_token ## substitua pelo seu token de API
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology",
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Erro:", response.status_code, response.text)
return
print("corpo", response.text)
if __name__ == "__main__":
send_request()Crie seu Scraper do Google Scholar Agora!
Raspar o Google Scholar é uma ótima maneira de extrair informações acadêmicas. Se você está procurando maneiras de raspar o Google Scholar ou outros mecanismos de busca com ou sem código, temos uma solução simples e rápida para você.
O Scrapeless oferece uma avaliação gratuita de um mês, onde você pode aproveitar todos os serviços para coletar dados. Como encontrar dados detalhados do Google Scholar? Você pode coletar muitos dados em um curto espaço de tempo com o Scrapeless.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


