
Melhor Scraper de Busca do Google e API SERP - Scraper de Resultados de Busca do Google
Senior Web Scraping Engineer
SERP é um termo comum da indústria usado no campo de SEO e reconhecimento de marca, representando a classificação de cada resultado de pesquisa. Mas como rastrear esses resultados da página de pesquisa do Google?
O Google usa muita ofuscação e técnicas anti-rastreamento, por isso é muito problemático rastrear dados de resultados de pesquisa do Google diretamente. Precisamos aprofundar vários pontos técnicos, como formato de URL, análise de HTML dinâmico e evitar o bloqueio de rastreamento.
Neste artigo, analisaremos o SERP do Google de vários aspectos e ajudaremos você a rastrear os resultados de pesquisa do Google o mais rápido possível!
Continue rolando e obtenha o melhor rastreador SERP do Google agora!
Google SERP: compreensão geral
Sempre que você discutir a raspagem de resultados de pesquisa do Google, provavelmente encontrará a abreviatura "SERP". SERP significa Search Engine Results Page (Página de Resultados do Mecanismo de Busca). É a página que você obtém após inserir uma consulta na barra de pesquisa. Existem 6 categorias principais de SERPs do Google:
- Snippets em destaque
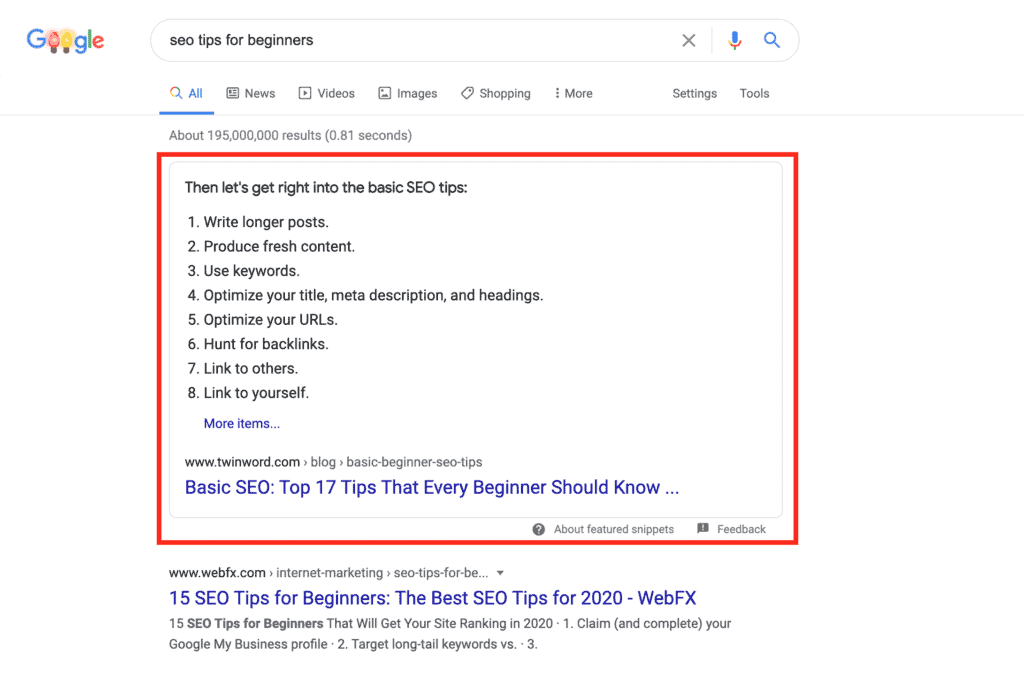
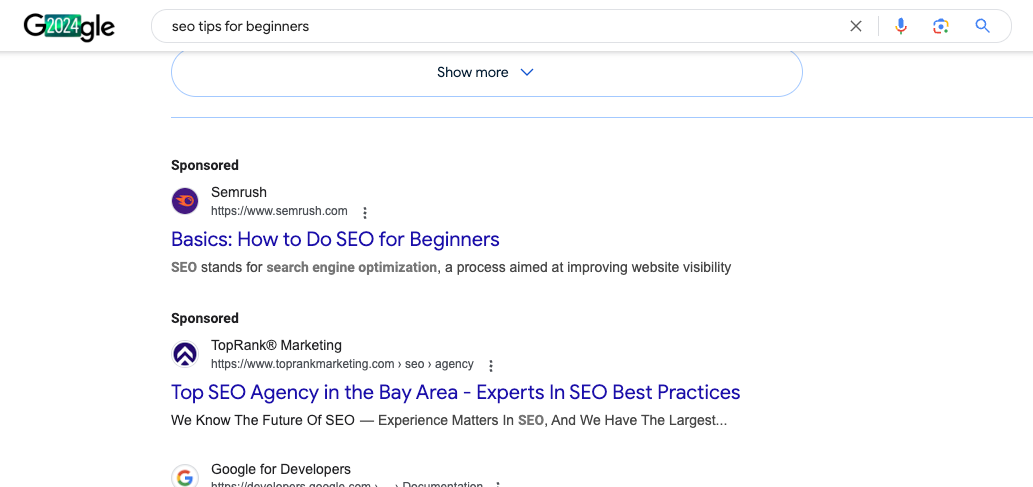
- Anúncios pagos
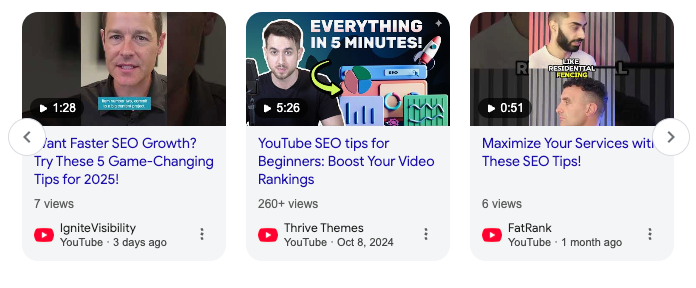
- Carrossel de vídeos
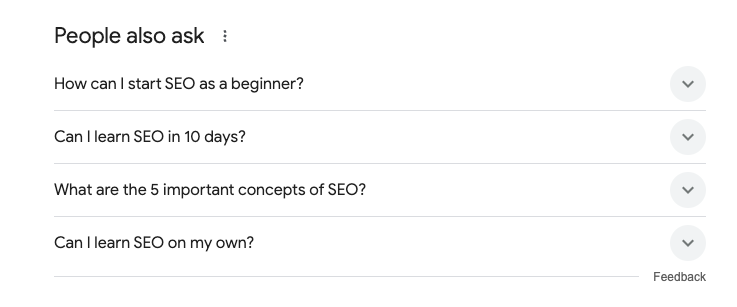
- As pessoas também perguntam
- Conjunto local
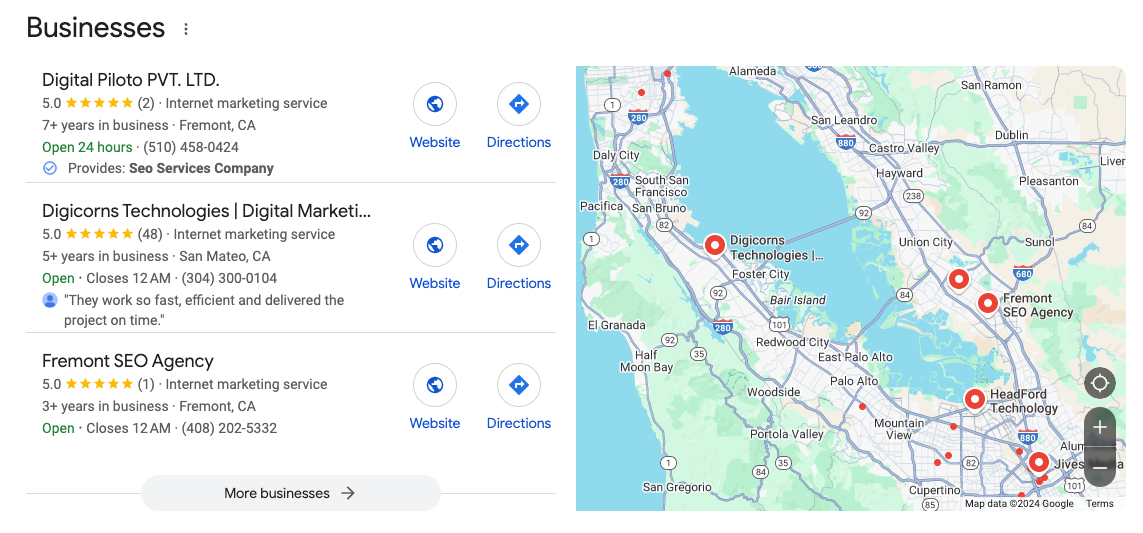
- Pesquisas relacionadas
O que é um rastreador do Google?
O rastreador SERP do Google é uma ferramenta ou software usado para extrair dados das páginas de resultados do mecanismo de busca do Google (SERPs). Esses dados incluem informações sobre os resultados exibidos para uma consulta específica, como título, URL, descrição e outros elementos, como snippets em destaque, anúncios ou pesquisas relacionadas.
Por que raspamos os resultados da pesquisa do Google?
O Google indexa a grande maioria das páginas da web públicas, então rastrear o Google Search nos dá acesso a um conjunto de dados rico. Seja análise de tendências de mercado, insights sobre o comportamento do consumidor ou trabalho de pesquisa em larga escala, essa abordagem oferece uma ampla gama de possibilidades.
Por outro lado, o SEO também é um dos casos de uso importantes para as empresas rastrearem a pesquisa do Google. Ao analisar os resultados da pesquisa, as empresas podem:
- Descobrir as palavras-chave para as quais os concorrentes têm alta classificação;
- Avaliar seu próprio desempenho de classificação;
- Otimizar sua estratégia de conteúdo de acordo com a demanda do mercado para melhorar a visibilidade.
Além disso, os sistemas de snippets do Google (como o Knowledge Graph e os Snippets em Destaque) integram informações de fontes de alta autoridade (como IMDb e Wikipedia). Raspe esses dados dos resultados de pesquisa do Google para obter diretamente informações-chave estruturadas e simplificadas, reduzindo a carga de trabalho da extração manual da fonte de dados original.
É legal raspar os resultados do Google?
Raspar os resultados de pesquisa do Google viola os termos de serviço do Google, pois o Google proíbe explicitamente o acesso automatizado aos seus serviços. Especificamente, os termos do Google afirmam:
"Você não pode usar ferramentas automatizadas, como robôs, spiders ou rastreadores, para acessar o Serviço sem a permissão expressa por escrito do Google."
Mas por favor, não fique nervoso! Você pode obter legalmente dados de pesquisa do Google usando a API Scrapeless SERP.
Desafios ao raspar o SERP do Google
- Medidas anti-raspagem: O Google usa CAPTCHA, bloqueio de IP e limitação de taxa para evitar rastreamento automatizado.
- Conteúdo dinâmico: O Google carrega dinamicamente o conteúdo por meio de JavaScript, e os rastreadores precisam lidar com esses elementos dinâmicos.
- Alterações no layout do SERP: O Google atualiza constantemente as páginas de resultados de pesquisa, fazendo com que os scripts de rastreamento falhem.
- Questões legais e éticas: A raspagem viola os termos de serviço do Google e pode enfrentar riscos legais.
- Complexidade da extração de dados: Elementos dinâmicos em SERPs, como anúncios e snippets em destaque, aumentam a dificuldade de extração de dados.
API Scrapeless SERP - o melhor rastreador SERP do Google
No mundo competitivo de SEO e marketing digital, o acesso a dados precisos e confiáveis do SERP do Google é essencial. É aí que a API Scrapeless SERP entra em ação — uma ferramenta poderosa, acessível e altamente eficiente, projetada para otimizar seus esforços de extração de dados.
A partir de apenas US$ 1 para cada 1K de URLs (inscreva-se para mais descontos), você ficará definitivamente surpreso com nosso preço competitivo. Com planos de preços transparentes e opções de pagamento conforme o uso, o Scrapeless garante que você pague apenas pelo que usa.
Por que a API Scrapeless SERP é eficaz?
O Scrapeless foi criado para lidar com os desafios de raspar as páginas de resultados do mecanismo de busca do Google (SERPs). Com mecanismos avançados de antidetecção, desempenho de alta velocidade e uma taxa de sucesso incrivelmente alta, o Scrapeless garante que sua coleta de dados seja executada sem problemas, sem interrupções ou proibições.
Se você está rastreando classificações de palavras-chave, monitorando concorrentes ou reunindo insights de mercado, o Scrapeless oferece resultados consistentemente precisos.
Vantagens da API de raspagem Scrapeless
- Preço acessível: O Scrapeless foi projetado para oferecer valor excepcional.
- Estabilidade e confiabilidade: Com um histórico comprovado, o Scrapeless fornece respostas de API estáveis, mesmo sob altas cargas de trabalho.
- Altas taxas de sucesso: Diga adeus às extrações malsucedidas e o Scrapeless promete 99,99% de acesso bem-sucedido aos dados do SERP do Google.
- Escalabilidade: Lidere milhares de consultas sem esforço, graças à infraestrutura robusta por trás do Scrapeless.
Como usar a API de pesquisa do Google Scrapeless?
Etapa 1. Faça login no Painel Scrapeless e vá para "API de pesquisa do Google".
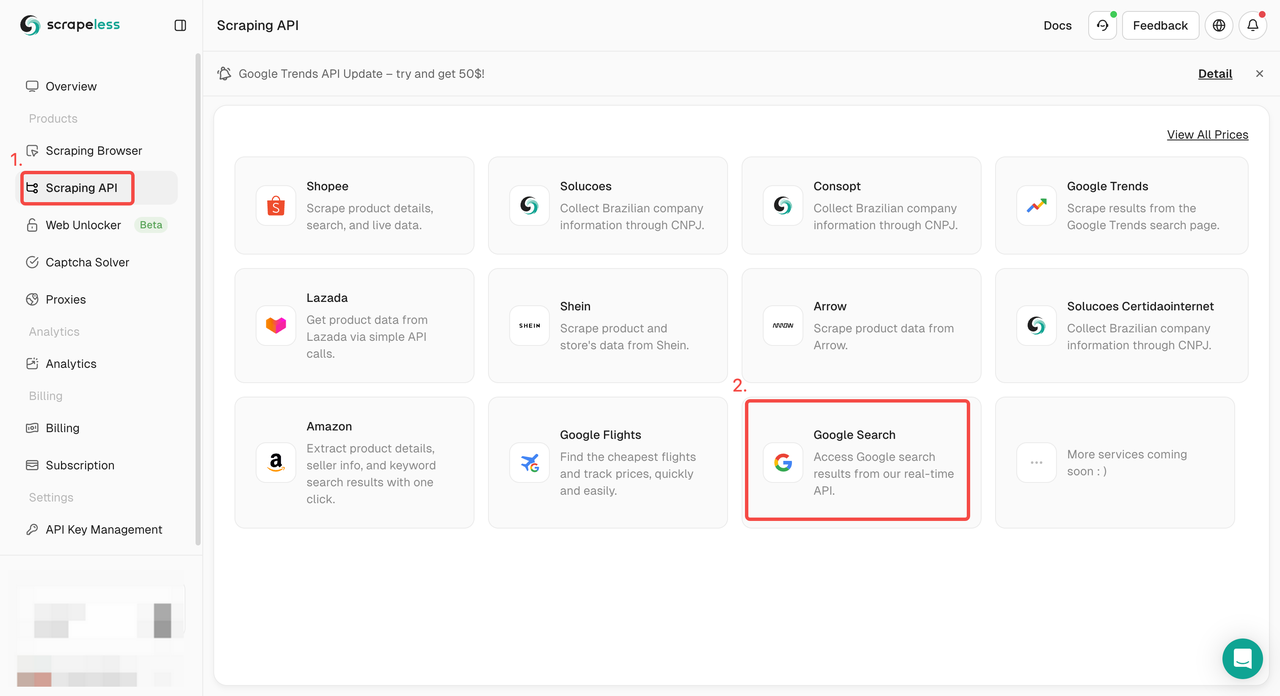
Etapa 2. Configure as palavras-chave, região, idioma, proxy e outras informações necessárias à esquerda. Depois de verificar se tudo está correto, clique em "Iniciar raspagem".
q: O parâmetro define a consulta que você deseja pesquisar.gl: O parâmetro define o país a ser usado para a pesquisa do Google.hl: O parâmetro define o idioma a ser usado para a pesquisa do Google.
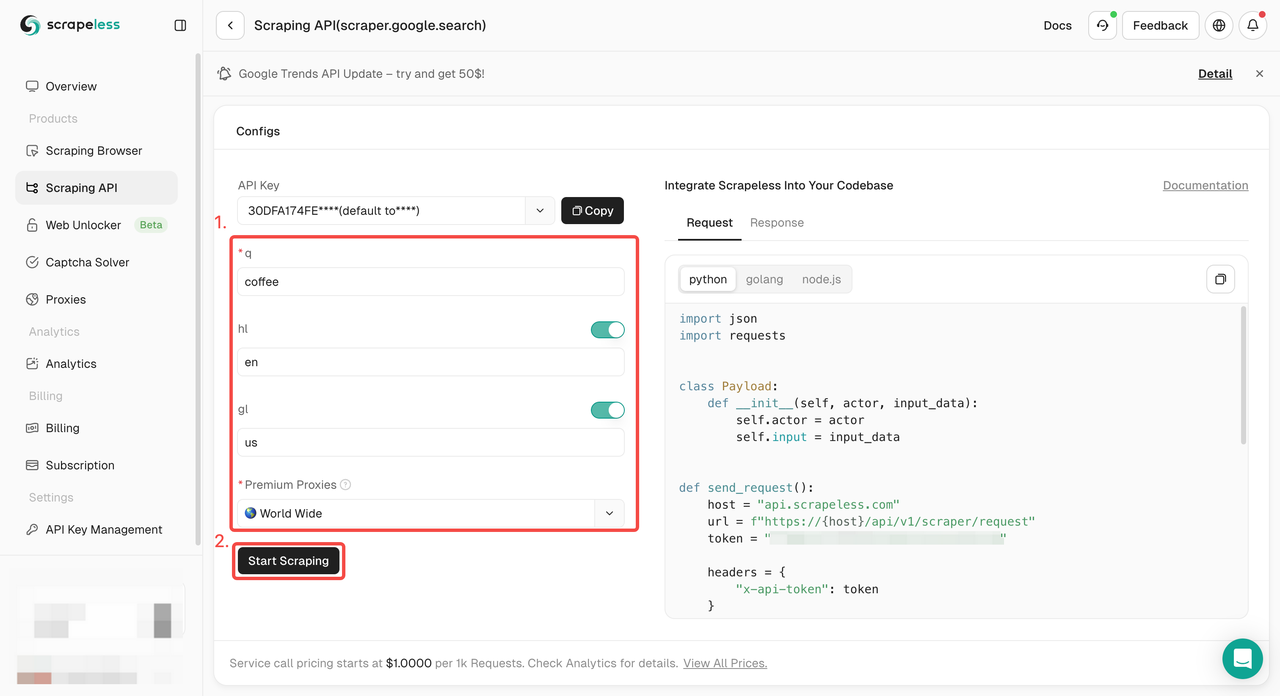
Etapa 3. Obtenha os resultados de rastreamento e exporte-os.
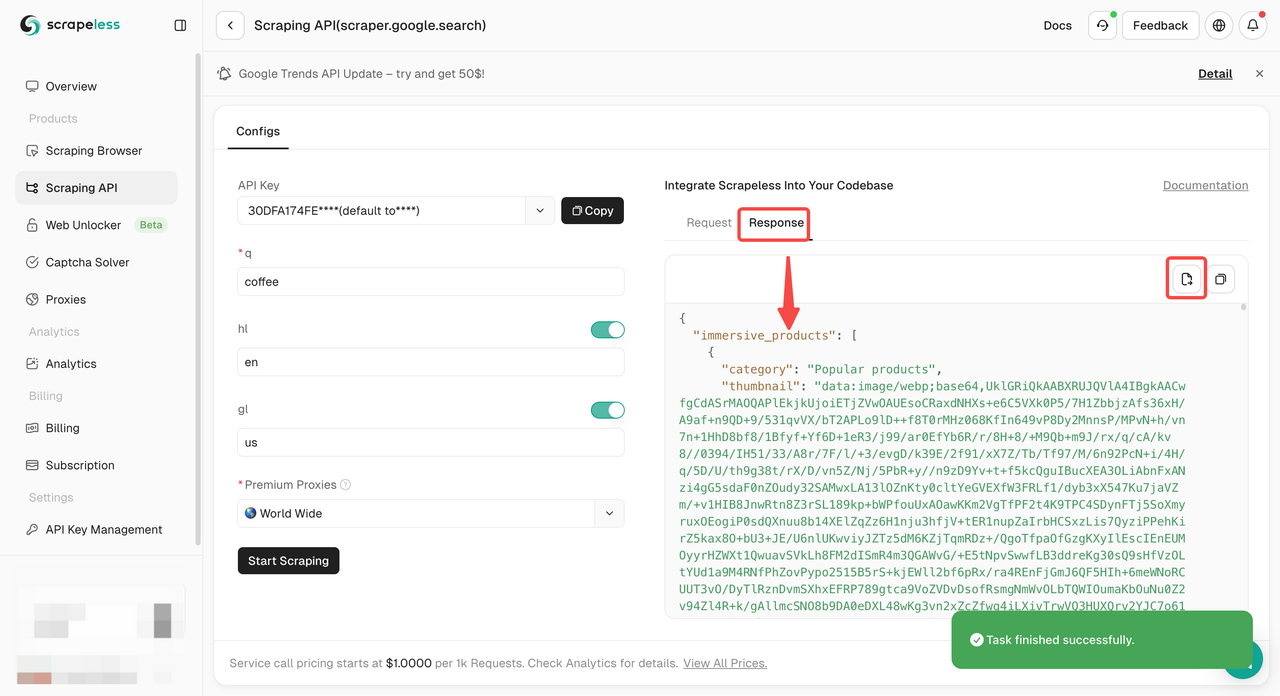
Precisa apenas de um código de exemplo para integrar ao seu projeto? Nós o cobrimos! Ou você pode visitar nossa documentação da API para qualquer idioma que precisar.
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang:
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}5 APIs populares de raspagem do SERP do Google
1. Google Flights
A API do Google Flights permite que você acesse dados de voos do Google Flights, incluindo preços de voos, rotas e disponibilidade. Ajuda empresas e desenvolvedores a agregar e analisar informações de voos para serviços e aplicativos relacionados a viagens.
2. Google Maps
A API do Google Maps fornece acesso a dados de geolocalização, incluindo mapas, detalhes de locais e informações geográficas. Com esta API, você pode raspar dados sobre locais, avaliações e endereços para criar aplicativos ou serviços baseados em localização.
3. Google Notícias
A API do Google Notícias permite o acesso a artigos e manchetes de notícias em tempo real do Google Notícias. É perfeita para monitorar eventos atuais, rastrear tópicos específicos e reunir dados de notícias para análise ou agregação.
4. Google Shopping
A API do Google Shopping permite que você raspe listagens de produtos de comércio eletrônico do Google Shopping, incluindo preços, descrições e disponibilidade. É ideal para sites de comparação de produtos, pesquisa de mercado ou rastreamento de preços.
5. Google Lens
A API do Google Lens fornece recursos de reconhecimento de imagem, permitindo que você raspe e analise objetos, marcos, texto e muito mais. Esta API é útil para criar aplicativos com recursos avançados de processamento e reconhecimento de imagem.
Considerações finais
Neste tutorial, abordamos profundamente:
- O que são SERP do Google e os benefícios do SERP do Google?.
- Como usar o Scrape Google SERP?
Os maiores desafios enfrentados pelos rastreadores do SERP do Google podem ser divididos em três categorias: Analisar páginas HTML complexas. Proibições de IP e verificação de CAPTCHAs.
Não deixe que os desafios da coleta de dados o impeçam! Escolha a API Scrapeless SERP para uma solução econômica, estável e de alto desempenho para todas as suas necessidades de raspagem do SERP do Google.
Pronto para começar?
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


