
Top 5 Melhores APIs de Web Scraping em 2025
Advanced Data Extraction Specialist
Uma API de web scraping é uma ferramenta poderosa projetada para automatizar a extração de dados de sites na internet. Seu objetivo principal é ajudar empresas, pesquisadores e desenvolvedores a coletar e organizar informações valiosas de várias fontes online. Essas APIs são essenciais para o manuseio eficiente de grandes volumes de dados da web, garantindo que as organizações possam acessar insights precisos e relevantes sem intervenção manual.
Independentemente do seu caso de uso específico para extração de dados, compilamos uma lista das melhores APIs de web scraping disponíveis atualmente. Cada API foi cuidadosamente avaliada com base em seus recursos, custo-benefício e desempenho geral. Se você está procurando melhorar seu SEO, otimizar seu processo de coleta de dados ou conduzir pesquisas abrangentes, essas APIs de web scraping estão equipadas para atender às suas necessidades.
Melhor ferramenta de web scraping em 2025
- Scrapeless – o melhor rastreador web geral
- Scrapy – rastreador open-source avançado
- DYNO Mapper – rastreador visual focado em SEO
- Oncrawl – rastreador web de SEO técnico
- Node Crawler – rastreador web baseado em JavaScript
Agora, vamos mergulhar no motivo pelo qual esses fornecedores de APIs de Web Scraping se destacam e por que você deve considerá-los para suas necessidades de web scraping.
Scrapeless
A API de Web Scraper da Scrapeless é projetada para extrair dados relevantes de sites de destino de forma eficiente. Ela navega automaticamente na web para coletar as informações precisas de que você precisa. Ao combinar a tecnologia AI Agent e a integração Browserless, a Scrapeless cria uma ferramenta de web scraping poderosa sem codificação manual. O AI Agent aprimora o processo de scraping otimizando as tarefas de scraping, enquanto o Browserless lida com a operação do navegador headless, garantindo a coleta suave de dados de sites dinâmicos.
Com o rastreador web da Scrapeless, os usuários têm controle total sobre sua estratégia e escopo de rastreamento. O rastreador segue metodicamente os links a partir de uma página inicial, percorrendo todas as páginas acessíveis de um site até que todas as páginas tenham sido indexadas.
Vantagens:
- Alta taxa de sucesso: oferece extração de dados precisa e confiável com erros mínimos.
- Escalabilidade: lida eficientemente com a coleta de dados em larga escala, tornando-a adequada para sites extensos.
- Recursos baseados em IA: utiliza inteligência artificial para melhorar a eficiência das tarefas de web scraping.
- Integração sem navegador: usa tecnologia de navegação headless para raspar sites dinâmicos e com uso intensivo de JavaScript perfeitamente.
- Coleta ética de dados: segue as melhores práticas em scraping de dados para garantir operações éticas e conformes.
Desvantagens:
- Curva de aprendizado: novos usuários podem precisar de tempo para entender e utilizar completamente todos os recursos avançados da Scrapeless.
Preço:
- Teste Grátis
Como obter uma avaliação gratuita da Scrapeless?
Para obter uma avaliação gratuita da Scrapeless, basta entrar no painel da Scrapeless. Depois de fazer login, você encontrará a opção de solicitar a avaliação gratuita diretamente no painel. É um processo fácil e direto, permitindo que você comece a usar a ferramenta imediatamente.
Quanto custa a API de Scraping da Scrapeless?
A API de Scraping da Scrapeless começa em US$ 1 por 1.000 URLs. Além disso, a Scrapeless oferece uma das APIs SERP mais acessíveis e rápidas disponíveis, com consultas de pesquisa processadas em apenas 1 a 2 segundos. O preço dessas consultas de pesquisa é tão baixo quanto US$ 0,30 por 1.000 consultas, tornando-a uma das soluções mais econômicas do mercado.
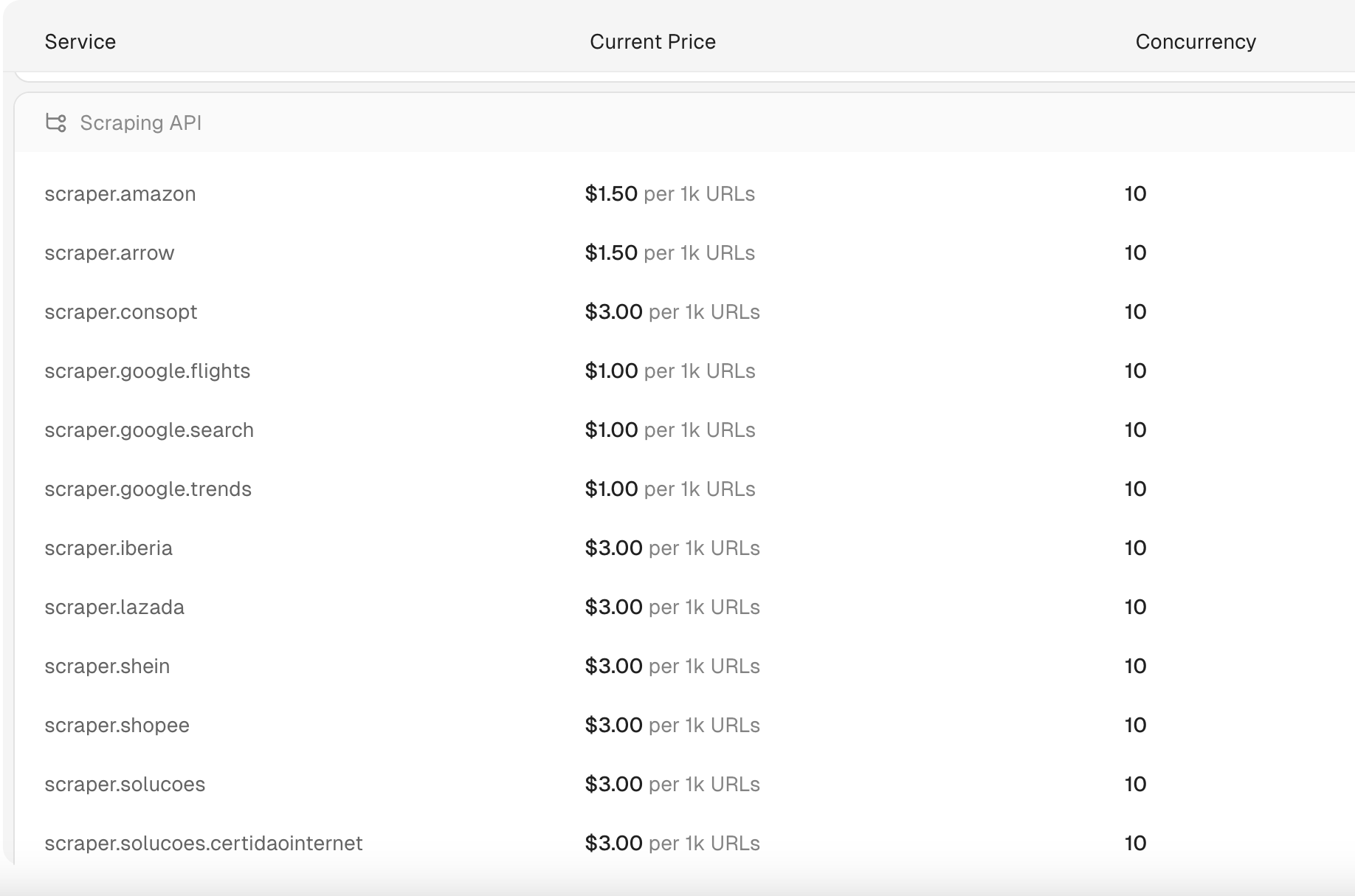
Observação:
- As cobranças são aplicadas por solicitação.
- Somente solicitações bem-sucedidas serão faturadas.
Como usar a API de Scraping da Scrapeless para obter dados da Shopee?
Para usar a API de Scraping da Scrapeless para raspar dados da Shopee, geralmente você precisa seguir as etapas a seguir. Lembre-se de que o web scraping pode envolver questões legais e éticas, portanto, certifique-se de revisar os Termos de Serviço da Shopee e garantir a conformidade com as leis aplicáveis.
Etapa 1. Cadastre-se na API Scrapeless
Por favor, faça login em sua conta Scrapeless. Após o login, você receberá uma chave de API.
Etapa 2. Selecione seu plano de scraping
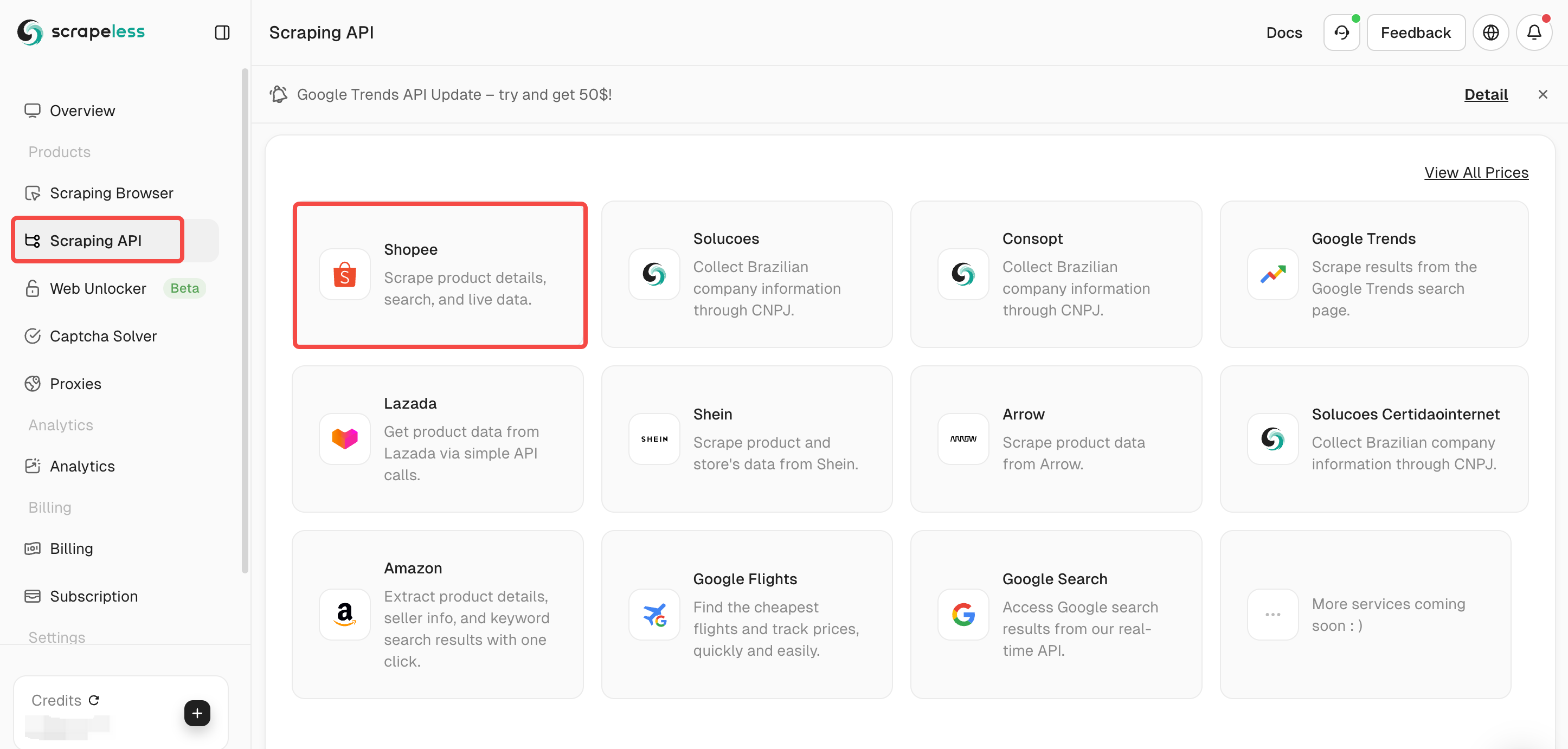
Selecione API de Scraping no painel e, em seguida, selecione Shopee.
A Scrapeless fornece várias APIs de scraping, como Lazada /Shein /Pesquisa Google/Voos Google.
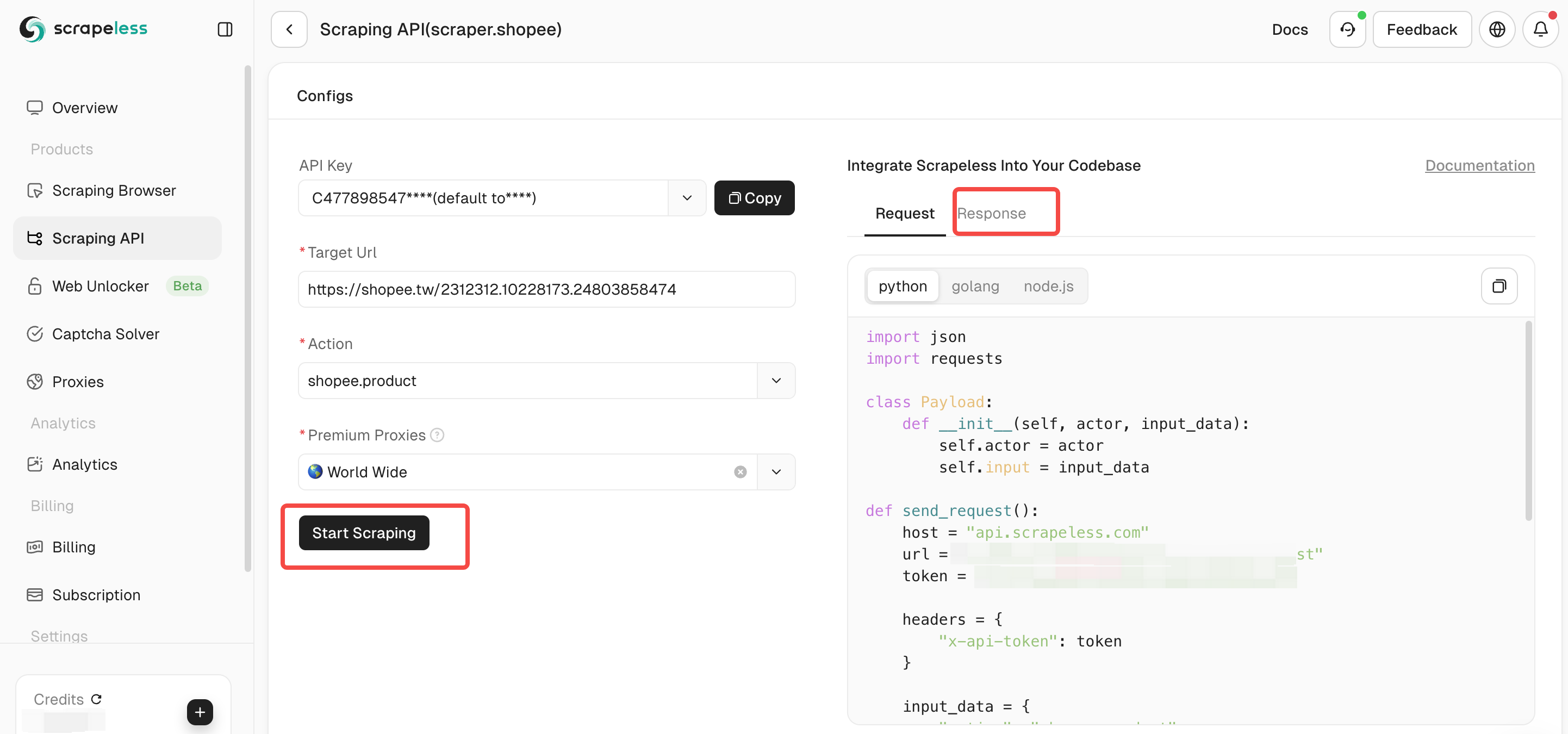
Etapa 3. Configure os parâmetros da sua API de Scraping da Shopee. Em seguida, clique em “Iniciar Scraping” e você poderá ver os dados do resultado de saída no painel direito.
Como integrar a Scrapeless ao seu projeto?
Para integrar a Scrapeless ao seu projeto, você pode melhorar efetivamente sua eficiência de rastreamento. A Scrapeless é comumente usada para tarefas de web scraping e extração de dados. O seguinte é um exemplo de código para integrar a Scrapeless ao seu projeto. Claro, você também pode verificar a documentação completa da Scrapeless:
Produto Shopee
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Busca Shopee
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Live
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.live",
"url": "https://live.shopee.co.th/api/v1/session/{sessionId}"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Rcmd
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.rcmd",
"url": "https://shopee.co.th/api/v4/shop/rcmd_items?bundle=shop_page_category_tab_main&item_card_use_scene=category_product_list_topsales&limit=30&offset=0&shop_id=1195212398&sort_type=13&upstream="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Avaliações Shopee
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.ratings",
"url": "https://shopee.ph/api/v2/item/get_ratings?exclude_filter=1&filter=0&filter_size=0&flag=1&fold_filter=0&itemid=23760784194&limit=6&offset=0&relevant_reviews=false&request_source=2&shopid=29975023&tag_filter=&type=0&variation_filters="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Scrapy
O Scrapy é uma estrutura de rastreamento web open-source popular, construída com Python, projetada para facilitar o web scraping e a extração de dados por meio de APIs de web scraping. Ele fornece aos desenvolvedores as ferramentas para construir rastreadores robustos e escaláveis, aproveitando um sistema bem organizado centrado em "aranhas"—unidades de rastreamento autônomas com instruções específicas para direcionar dados.
Seguindo o princípio "não se repita" (DRY), o Scrapy promove a reusabilidade do código, tornando-o uma escolha eficiente para escalar operações de rastreamento em grande escala. Graças à sua versatilidade, o Scrapy é favorecido por desenvolvedores e cientistas de dados que trabalham em tarefas avançadas de scraping.
Vantagens:
- Biblioteca de scraping open-source: disponível gratuitamente sob a licença BSD, com contribuições de uma comunidade vibrante.
- Ideal para desenvolvedores e cientistas de dados: oferece opções de personalização poderosas e controle total sobre o processo de scraping.
Desvantagens:
- Desafiador para iniciantes: requer um bom conhecimento de Python e conceitos de web scraping, o que pode ser um obstáculo para aqueles que são novos no campo.
- Rico em recursos: pode consumir recursos significativos do sistema, especialmente ao lidar com projetos de scraping em larga escala.
- Não muito amigável para iniciantes: a complexidade e a necessidade de experiência em codificação podem sobrecarregar aqueles que são novos no web scraping.
Preço:
- Grátis
Você pode precisar: Como resolver desafios de web scraping - Guia completo 2025
DYNO Mapper
O DYNO Mapper é um gerador de mapa do site visual intuitivo que rastreia sites seguindo links internos, imitando o comportamento dos bots de mecanismos de pesquisa. Após o rastreamento, ele gera um mapa do site visual que mostra a estrutura do site, ajudando os usuários a entender melhor a navegação do site. A ferramenta suporta vários formatos de saída, incluindo mapas do site visuais interativos, HTML, CSV, XML, PDF, JSON e Excel (XLSX). Além de sua funcionalidade de mapa do site, o DYNO Mapper oferece recursos de inventário e auditoria de conteúdo, juntamente com testes de acessibilidade para garantir a conformidade com os padrões de sites ADA. Ele também se integra perfeitamente às APIs de web scraping para necessidades avançadas de extração de dados, tornando-o um dos melhores rastreadores web para gerenciamento de conteúdo.
Vantagens:
- Vários formatos de saída: fornece flexibilidade ao entregar dados em vários formatos, melhorando a usabilidade das informações.
- Ferramentas de inventário e auditoria de conteúdo: ajuda a otimizar a organização e a otimização do conteúdo do site para melhor desempenho.
Desvantagens:
- Limitações do plano gratuito: o plano gratuito possui recursos restritos, que podem não atender às necessidades de todos os usuários.
- Complexo de dominar: requer tempo e esforço para entender e usar completamente todos os seus recursos avançados.
Preço:
- Teste gratuito disponível, com o plano mais acessível a partir de US$ 39/mês.
Oncrawl
O Oncrawl é uma ferramenta de rastreamento web poderosa, projetada para SEO e análise técnica de sites. Ele oferece auditorias de SEO detalhadas, painéis personalizáveis e soluções escaláveis para sites em larga escala, tornando-se um recurso fundamental para qualquer estratégia de marketing digital. Como um dos melhores rastreadores web, o Oncrawl permite que as empresas analisem e melhorem sua presença online de forma eficiente. Além disso, ele se integra às APIs de web scraping para aprimorar os recursos de extração de dados.
Vantagens:
- Auditorias de SEO completas: fornece insights abrangentes sobre o desempenho de SEO do seu site.
- Painéis e relatórios personalizáveis: os usuários podem personalizar relatórios e painéis para atender às suas necessidades específicas.
Desvantagens:
- Controle de rastreamento limitado para sites menores: pode não oferecer tanta flexibilidade nas configurações de rastreamento para sites menores.
- Curva de aprendizado íngreme: requer tempo para entender e utilizar completamente todos os recursos do Oncrawl.
Preço:
- A partir de US$ 69/mês
Node Crawler
O Node Crawler é uma biblioteca de rastreamento web popular projetada para Node.js, amplamente reconhecida por sua flexibilidade e facilidade de uso. Ao utilizar o Cheerio como seu analisador padrão, ele fornece análise e manipulação de HTML rápida e eficiente. A biblioteca oferece inúmeras opções de personalização, como gerenciamento de fila para lidar com concorrência, limitação de taxa e tentativas automáticas, tornando-a uma ferramenta poderosa para projetos de web scraping.
Graças à sua natureza leve, o Node Crawler garante consumo mínimo de memória, tornando-o ideal para tarefas de alto desempenho, mesmo ao processar grandes volumes de solicitações. Como um dos melhores rastreadores web para desenvolvedores Node.js, ele se integra perfeitamente aos fluxos de trabalho baseados em JavaScript e permite o uso perfeito de APIs de web scraping.
Vantagens:
- Perfeito para desenvolvedores Node.js: integra-se facilmente a ambientes JavaScript, tornando-o a escolha ideal para desenvolvedores familiarizados com Node.js.
- Eficiente e leve: projetado com foco no desempenho, garantindo baixo uso de memória durante as operações, mesmo ao lidar com várias solicitações.
Desvantagens: - Sem renderização JavaScript nativa: ele não suporta renderização JavaScript por padrão, o que pode exigir ferramentas ou configurações adicionais para raspar conteúdo dinâmico.
Preço:
- Grátis
Comparação das melhores ferramentas de web scraping
| Fornecedor | Melhores recursos |
|---|---|
| Scrapeless | Infraestrutura avançada de proxy e IPs residenciais para web scraping e rastreamento web escaláveis e éticos. |
| Scrapy | Uma estrutura Python open-source poderosa para construir rastreadores e scrapers web personalizados. |
| DYNO Mapper | Foca na criação de mapas do site visuais e na realização de auditorias de SEO para otimização e análise de estrutura do site. |
| Oncrawl | Um rastreador web focado em SEO técnico com análise avançada para arquitetura de site, orçamento de rastreamento e arquivos de log. |
| Node Crawler | Um rastreador flexível baseado em JavaScript, construído no Node.js, ideal para sites modernos com conteúdo dinâmico. |
O que é web scraping?
Web scraping é uma técnica usada para extrair dados automaticamente de sites. Este processo envolve várias etapas-chave:
Definição
Web scraping, também conhecido como coleta na web ou extração de dados na web, refere-se ao método automatizado de recuperar e coletar informações de páginas da web. Normalmente, envolve o uso de ferramentas de software ou scripts que podem acessar a internet, baixar páginas da web e extrair dados específicos delas para vários fins, como análise ou armazenamento em bancos de dados.
Como funciona o Web Scraping
- Solicitação: o processo começa com o envio de uma solicitação ao servidor de um site, semelhante à entrada de um URL em um navegador.
- Resposta: o servidor responde entregando a página da web solicitada, que pode conter texto, imagens e outros tipos de dados.
- Análise: a ferramenta de web scraping analisa o conteúdo HTML da página para localizar e extrair pontos de dados específicos, como preços de produtos, informações de contato ou outros detalhes relevantes.
- Armazenamento: finalmente, os dados extraídos são salvos em um formato estruturado, como CSV, Excel ou um banco de dados, para uso posterior.
Aplicações de Web Scraping
O web scraping tem uma ampla gama de aplicações em vários setores:
- Pesquisa de mercado: coleta de informações de preços e produtos competitivos.
- Geração de leads: coleta de detalhes de contato para esforços de vendas e marketing.
- Monitoramento de preços: acompanhamento de mudanças de preços de produtos em diferentes varejistas.
- Agregação de conteúdo: compilação de artigos de notícias ou avaliações de produtos de várias fontes
Diferenças do rastreamento na web
Embora o web scraping e o rastreamento na web sejam conceitos relacionados, eles servem a propósitos diferentes. O rastreamento na web é focado principalmente na descoberta e indexação de páginas da web seguindo links na internet. Em contraste, o web scraping visa especificamente a extração de dados dessas páginas depois que elas foram acessadas.
Conclusão
Em conclusão, selecionar a API de web scraping certa é crucial para empresas e desenvolvedores que procuram extrair e aproveitar dados valiosos da web. As 5 melhores APIs de web scraping em 2025 oferecem uma gama de recursos que atendem a diferentes necessidades — seja escalabilidade, facilidade de uso ou recursos avançados de processamento de dados. Cada uma dessas ferramentas tem seus próprios pontos fortes, tornando-as adequadas para várias aplicações, desde otimização de SEO até pesquisa de mercado e agregação de conteúdo.
FAQ
Como funcionam as APIs de web scraping?
As APIs de web scraping funcionam enviando solicitações a sites de destino em nome do usuário, recuperando dados enquanto gerenciam complexidades como o tratamento de proxy e medidas anti-bot. Os usuários podem acessar dados estruturados sem precisar desenvolver scrapers personalizados.
Posso experimentar essas APIs de web scraping antes de me comprometer?
A maioria das principais APIs de web scraping oferece testes gratuitos ou modelos de preços de pagamento por uso para permitir que os usuários testem sua funcionalidade e eficácia antes de fazer um compromisso financeiro. Por exemplo, a Scrapeless oferece uma avaliação gratuita. Usuários que também participam de testes de novos recursos no Discord da Scrapeless também receberão créditos que podem ser usados em todos os produtos Scrapeless! 🎉
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


