
Best Lazada Data Scraper API 2025 - Powerful & Effective
Expert Network Defense Engineer
Lazada is one of the leading e-commerce platforms in Southeast Asia. With an average of about 150 million users per month, Lazada operates in Indonesia, Malaysia, Singapore, Vietnam, Thailand, and the Philippines. The platform offers over 300 million products, ranging from electronics to fashion. Studying Lazada’s product data can help you analyze the Southeast Asian market.
In this article, we will take a deep dive into how to scrape Lazada’s product data.
All you need to do is pass Scrapeless API the URL of Lazada that you want to scrape.
Are you ready?
Let's start reading!
Why Scrape Lazada Data?
- Market Intelligence and Competitor Analysis
Lazada hosts millions of products, with real-time pricing and stock information. Scraping Lazada data enables businesses to track competitors’ prices, promotions, product availability, and customer reviews. This information helps companies make strategic decisions to adjust their own pricing, promotions, and inventory management.
- Product Research and Trend Analysis
By collecting data from Lazada, businesses can monitor emerging product trends, customer preferences, and seasonal demand patterns. This information can guide product development or help sellers optimize their offerings to meet consumer demand.
- Pricing and Stock Monitoring
Lazada's prices and stock availability fluctuate frequently due to market demand, seasonal sales, and competitor activity. By scraping this data, businesses can track these fluctuations, adjust their pricing strategies, and implement dynamic pricing models to stay competitive.
- SEO and Digital Marketing
Product data, including titles, descriptions, and customer reviews, can be crucial for optimizing e-commerce websites, PPC campaigns, and SEO strategies. By analyzing Lazada listings, businesses can identify the most effective keywords and phrases used in successful product listings, helping them to improve their visibility online.
- Automated Data Collection
Lazada product data is constantly changing, and collecting this information manually can be time-consuming and inefficient. Using a Lazada Data Scraper API helps automate the process, ensuring that businesses can continuously monitor data without significant manual intervention.
Challenges of Scraping Lazada Data
While scraping data from Lazada offers valuable insights, there are several challenges that businesses and developers must overcome:
- Anti-Scraping Measures
Like many e-commerce platforms, Lazada employs anti-scraping technologies to prevent unauthorized scraping of its data. This includes techniques like CAPTCHA, IP blocking, rate-limiting, and using dynamic web content (AJAX) that is harder to scrape. Overcoming these obstacles requires advanced tools and techniques, such as rotating proxies, headless browsers, and user-agent masking.
- Data Structure Complexity
Lazada’s data is often presented in dynamic web pages, making it difficult to extract without sophisticated scraping techniques. The data is spread across multiple layers of the website, requiring scrapers to navigate complex DOM structures and extract the relevant information. A reliable API simplifies this process by providing structured data in a format that is easy to analyze.
- Legal and Compliance Issues
Scraping data from any website, including Lazada, must comply with the platform’s terms of service and privacy policies. Violating these terms can result in being blocked from the site or facing legal consequences. It’s important to ensure that the data scraping is done in a responsible and lawful manner, adhering to the platform’s policies.
- Data Volume and Scalability
Lazada offers millions of products across multiple categories, and scraping such a large volume of data can put a significant load on your infrastructure. It requires robust and scalable scraping solutions capable of handling large-scale data collection efficiently.
Does Lazada allow web scraping?
If you are looking to scrape data from Lazada, you may wonder if Lazada allows web scraping and whether it is legal. So, does Lazada allow web scraping?
In general, Lazada's terms of service do not prohibit web scraping. Respecting the website's policies is essential, therefore, our Lazada Scraper is fully legal and prioritizes ethical data extraction.
We can scrape all publicly available data from Lazada, such as product name, description, brand, seller, category, image, price, condition review, product URL, shipping information, etc. With this data, you can analyze the market and popular products to understand which products are popular and loved by buyers. If you are a seller, then you can use this data to add similar products to your store and increase sales.
So, if you are a seller on Lazada or planning to sell your products on Lazada, scraping data from the website and analyzing Lazada's trends and popular products can definitely help you succeed as a seller.
A good scraper API can greatly reduce our workload and improve our work efficiency. How to judge whether a scraper API is good? Which one is the best Lazada scraper API?
Keep reading now!
Scrapeless - the best Lazada data scraper API
Scrapeless Lazada Scraping API is an innovative solution designed to simplify the process of extracting data from Lazada.
With our advanced Scraping API, you can access the data you need without writing or maintaining complex scraping scripts. A simple API call will instantly access Lazada's product detail data.
How to call our Lazada API? Please follow my guides:
- Step 1. Log in to Scrapeless
- Step 2. Click the "Scraping API"
- Step 3. Find our "Lazada" API and enter it:
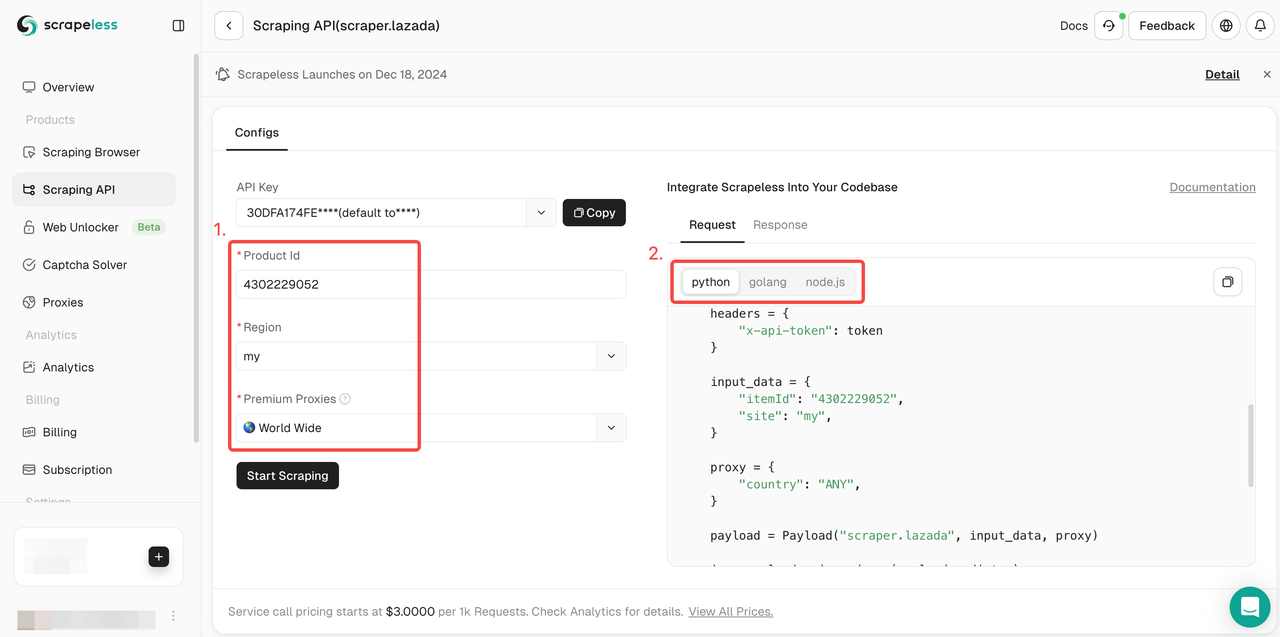
- Step 4. Fill in the complete information of the product you want to crawl in the operation box on the left. Then select the expression language you want:
- Step 5. Click "Start Scraping", and the product's crawling results will appear in the preview box on the right:
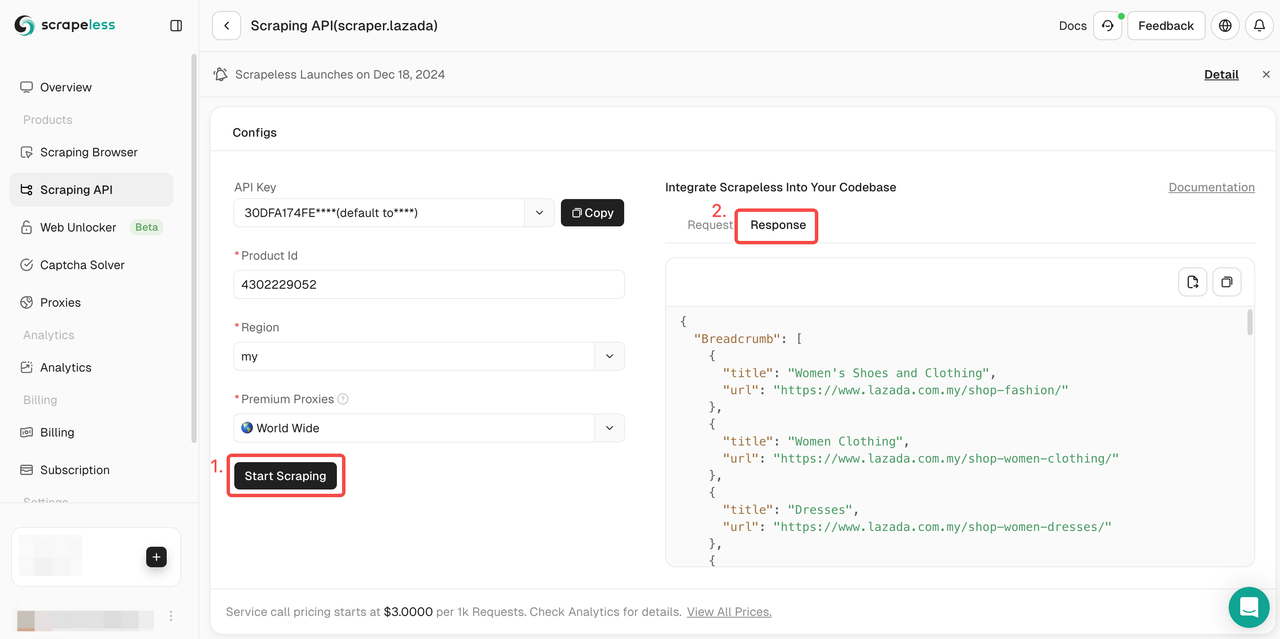
Now you just need to click the copy button in the upper right corner to completely copy all product data!
Or you can choose to deploy our sample codes to your own project:
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #your API token
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #Input the product ID
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()- Golong
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " # your API token
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": " ", #Input the product ID
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}- Node.JS
JavaScript
const https = require('https');
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; # your API token
const inputData = {
"itemId": " ", # input the product ID
"site": "my",
};
const proxy = {
country: "ANY",
}
const payload = new Payload("scraper.lazada", inputData, proxy);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();How to judge a Lazada scraper API?
The best Lazada Data Scraper API should help overcome many of the challenges listed above while providing businesses with comprehensive and accurate product data.
Here's what makes a great Lazada data scraper API:
- Real-Time data extraction
- Bypass anti-scraping mechanisms
- Data Parsing and Structuring
- Customizable filtering
- Scalability and Speed
- User-Friendly Interface and Documentation
Use Cases for Best Lazada Data Scraper API
- E-commerce Sellers
Track competitors’ prices and inventory to adjust your own listings and pricing strategies. Automate price checks to stay competitive in the marketplace.
- Market Research Firms
Conduct detailed product and market trend analysis by scraping product information, customer reviews, and ratings to generate insights into consumer behavior.
- SEO and Digital Marketing Agencies
Optimize product descriptions, keywords, and titles for better search rankings by analyzing top-performing Lazada listings.
- Affiliate Marketers
Monitor product performance and affiliate opportunities by scraping product data and analyzing reviews and ratings.
The Bottom Line
Scraping Lazada can provide us with comprehensive and detailed product data content, helping us obtain timely market information. If you want to crawl Lazada and extract product data in the fastest and easiest way, Scrapeless Lazada Scraping API is your best choice! You only need to call the API interface without complicated coding process.
In addition, the price of Scrapeless API can meet all your calling needs without worrying about a large amount of money investment.
Start using Scrapeless API now!
You may also like:
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


