Loading...
🎯 カスタマイズ可能で検出回避型のクラウドブラウザ。自社開発のChromiumを搭載し、ウェブクローラーやAIエージェント向けに設計されています。👉今すぐ試す
すべてのWebスクレイピング開発者向けに作成された最も包括的なガイド。
Scrapelessは、大手企業から信頼されるAIを搭載した堅牢でスケーラブルなWebスクレイピングと自動化サービスを提供します。 私たちのエンタープライズグレードのソリューションは、プロジェクトのニーズを満たすように調整されており、全体にわたって専用の技術サポートがあります。 強力な技術チームと柔軟な配達時間を使用すると、データを成功させるためにのみ請求し、制限をバイパスしながら効率的なデータ抽出を可能にします。
あなたのビジネスの成長を促進するために今すぐお問い合わせください。
連絡先の詳細を提供すると、すぐに製品のデモと紹介を提供します。 GDPR標準に準拠して、お客様の情報が機密のままであることを確認します。
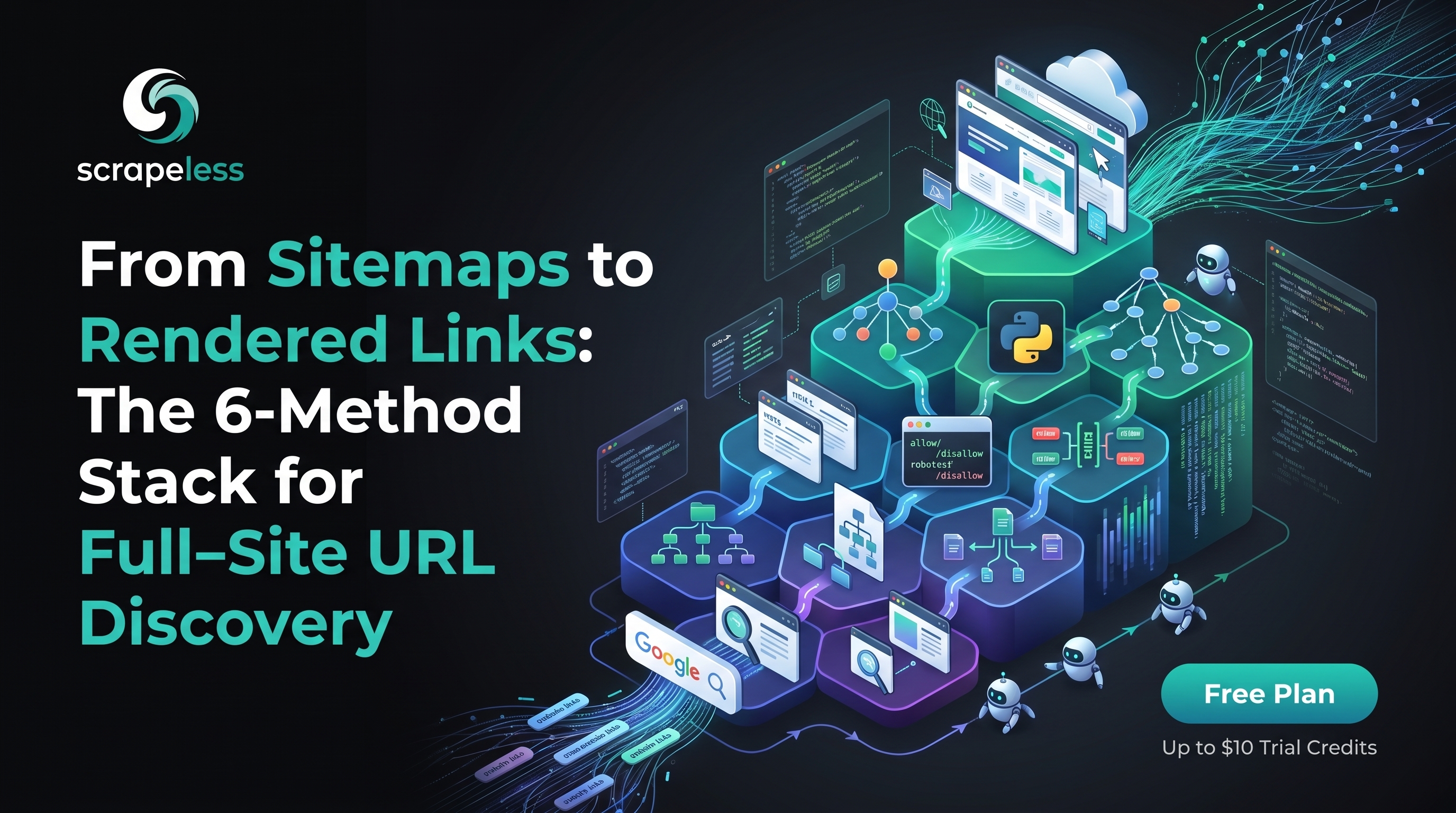
このガイドは、単一の手法では完全なURLインベントリを取得できないことを示しています。Googleのsite:オペレーターは迅速な推定を提供し、サイトマップはパブリッシャーが登録した内容を示し、幅優先のHTTPクローラーはリンクされた孤児を見つけ、クラウドブラウザーはJavaScriptで描画されたリンクをレンダリングします。そして、コストと完全性の順に6つの手法を説明します。無料のsite:検索から完全なスタックアプローチまで、robots.txtを読み取りサイトマップの場所と制限ルールを確認し、サイトマップツリーを再帰的に辿り、すべてのURLでrobots.txtを尊重するPython BFSクローラーを実行し、JavaScriptを多く使用するホストをクライアントサイドのリンク発見のためにScrapeless Scraping Browserにエスカレートさせます。その結果は、技術的なSEO監査、コンテンツ移行、リンク切れのスウィープ、価格監視、LLMコーパスの取り込み、競争的なコンテンツマッピングをカバーする層状の重複排除された統合となります。これは、完全なURL発見にはサイトマップ、クローラー、レンダリングを補完的な手法として扱う必要があることを証明しています。
このガイドは、「無料」の公共データは決して無料ではなく、計測されていないものであったと主張します。オープンウェブは、クローラーがコンテンツを持ち去り、出版社はその見返りとしてリファラルトラフィックを得るという暗黙の取引に基づいて機能していました。しかし、AIの回答エンジンはクリックを送信することなくページを読み取ることで、この取引を破壊しました。そして、ペイ・パー・クロール(HTTP 402およびCloudflareのインフラストラクチャを通じて実装された)は、その読み取りが何の価値があるかを市場が再評価することを表しており、データのコストをインフラストラクチャ(プロキシ、レンダリング、エンジニアリング)からアクセス料金にシフトさせます。運用上の解決策は哲学的ではなく、規律あるものでなければなりません。発見(広範囲で低頻度のマッピング)を更新(狭範囲で高頻度の更新)から分離し、リクエストごとのコストではなく、利用可能な更新ごとのコストを追跡し、初回の試みで成功するクリーンなレンダリングに投資することで、データチームは各アクセス料金を正確に一度だけ支払い、メータリングされたウェブは予算の大惨事ではなく、解決可能な経済問題になります。

このガイドは、ElixirのBEAMランタイムがウェブスクレイピングのために安価な同時実行を可能にすることを示しています。これは、スレッドプールの調整なしに、数千の軽量プロセスを生成してURLに分散させることができます。このネイティブな同時実行は、二層のエスカレーションパターンと組み合わされています。HTTP層は、Req、HTTPoison、Crawlyを使用し、195か国以上のScrapelessの住宅プロキシを経由してサーバー生成されたページにアクセスします。一方、ブラウザ層は、JavaScriptが重く、ボット対策が施されたターゲットをScrapeless Scraping Browserにエスカレートさせ、ElixirからSystem.cmd/3を介して呼び出される最小限のPythonレンダリングヘルパーを使用します。その結果、同時カタログクローリング、スケジュールされた監視、地理特定のスナップショット、起動時スケールでのRAG取り込みを処理できる生産品質のスクレイピングスタックが完成します。すべては、BEAMにChrome DevTools Protocolを直接話させることなく実現されます。

公共データは理論上はオープンですが、実際には制限されています:1ページを読むのは簡単ですが、JavaScriptとボット防止策の背後にある40カ国から1日で10,000ページを読むのはインフラの問題です。スケールでそれを行える人とそうでない人との間のこのギャップ―データそのものではなく―が競争優位が集中する場所であり、AIシステムはそれを引き継ぎ増幅します。解決策は、195以上の国にわたる住宅プロキシ、検出回避のクラウドレンダリング、統一APIインターフェースなど、公共の原則を実際にアクセス可能にするインフラであり、小さなチームがそれを責任を持って使用して、競争の場を平等にすることです。

このガイドは、エージェント指向の商取引を支える三層のAI経済スタックについて説明します。エージェントがツールやデータにアクセスできるツールプロトコル(MCP)、人間を介さずに価値を決済できる機械ネイティブの支払いプロトコル(x402、エージェント商取引プロトコル、エージェント支払いプロトコル)、そして自律的な購入決定を実際のウェブ上の真実に基づいて維持する信頼できるデータレイヤーです。重要な洞察は、データの質が荷重支持の基盤であることです。古い価格や空のJavaScriptレンダリングページで支払うエージェントは、静かに高価に失敗します。これが、Scrapeless Scraping Browser(JavaScriptをレンダリングし、地域ごとに住宅用エグレスをピン留めし、ボット対策システムを打破する)が、依然として人間のために構築されたウェブの大部分にアクセスしたいエージェント指向商取引システムにとって必需品である理由です。

このガイドは、高品質なLLMおよびRAGコーパスを構築するには、生のHTMLではなくクリーンなテキスト抽出が必要であることを示しており、4段階のPythonパイプラインを通じて手順を説明しています。具体的には、google_searchまたはsitemapsを介してURLを発見し、各ページをアンチデテクションのクラウドブラウザでレンダリングしてから、scrape_markdownでクリーンなMarkdownを抽出し、そのMarkdownを500〜1000トークンのオーバーラッピングウィンドウに分割し、各チャンクを取得のためのベクターデータベースに埋め込みます。その結果、汚れた公共ウェブページを生産グレードのコーパスに変換するスケーラブルなシステムが実現され、トークンコストが70%削減され、取得品質が飛躍的に向上します。これを実現するために、サイトごとのアダプターやフィンガープリントの調整は必要ありません。

Googleマップは最も豊富なローカルビジネスディレクトリを保持していますが、大規模に抽出するにはアンチデetectionレンダリングと住宅用プロキシルーティングが必要です。このガイドでは、カテゴリー検索を重複のないCRM準備済みのリードリストに変えるための4段階のワークフローを解説します。具体的には、google_searchを使った発見とレンダリングされたマップのスクロール、セマンティックセレクタからの構造化フィールドの抽出、ビジネスウェブサイトからの情報の充実、評判による質の向上です。これにより、手動の調査やサイトごとのアダプターなしで実現します。
このガイドは、cURLを使用してJSONを送信するには、2つの独立したコンポーネント—JSONリクエストボディとContent-Type: application/jsonヘッダー—が必要であることを示し、これを実現する2つの方法:従来の -d フラグに明示的な -H ヘッダーを追加する方法と、両方のヘッダーを自動的に設定するモダンな --json ショートカット(curl 7.82.0+)を説明します。一般的な間違い(シェルのクオート、ヘッダーの忘れ、ファイル処理)をカバーし、パブリックエコーエンドポイントに対する実例、およびScrapeless MCP APIへの実際の呼び出しを通じて、ターミナルで機能するcurlコマンドがどのようにプロダクションコードに直接翻訳されるかを示します。



