
Pythonを使ってLazadaの商品データをスクレイピングする方法
Specialist in Anti-Bot Strategies
Lazada製品スクレイピングとは?
Lazadaは様々な業者が商品を販売するオンラインマーケットプレイスであり、このデータのスクレイピングは、価格監視、市場調査、在庫管理、競合分析など、様々な用途に役立ちます。
Lazadaは、安全な決済手段、カスタマーレビュー、配送システムなど、様々な機能を提供しており、顧客の購入とドアツードアの配送を容易にしています。
Lazadaウェブスクレイピングとは、自動化ツールやスクリプトを使用してLazadaウェブサイトからデータを取得するプロセスです。
スクレイピングとは、商品詳細(名称、価格、説明、写真など)、販売者情報、ユーザーレビュー、評価など、Lazadaウェブページから特定の情報を取得する行為です。ただし、オンラインスクレイピングは法的問題の対象となる可能性があり、許可なくデータのスクレイピングを禁止するウェブサイトの利用規約もあります。
なぜLazadaウェブクロールが必要なの?
- 価格監視と比較: Lazadaの商品データをクロールすることで、企業や消費者は価格変動を追跡し、類似商品の価格動向を分析し、最適な購入時期を見つけることができます。
- 市場分析: Lazadaのデータをクロールすることで、企業はベストセラー商品、ユーザーレビュー、商品ランキングなどの市場動向を取得できます。これにより、販売戦略の最適化、市場需要の予測、より正確なマーケティングプランの策定に役立ちます。
- 商品情報収集: 大規模な商品カタログを管理する必要があるEC企業や代理店にとって、Lazadaの商品データ(商品名、説明、価格、在庫情報など)をクロールすることで、商品データの入力と更新を迅速化し、効率を向上させることができます。
- 競合分析: Lazadaにおける競合他社の商品リスト、価格戦略、プロモーションをクロールすることで、企業は競合他社の市場ポジショニングを理解し、より競争力のある事業計画を策定できます。
- コメントと評価分析: ユーザーコメントと評価は、消費者の意思決定において重要な基盤となります。この情報をクロールすることで、企業は商品に対する消費者フィードバックを分析し、製品やサービスを改善し、ユーザーエクスペリエンスを向上させることができます。
- 商品価格比較プラットフォームの構築: 一部のスタートアップやテクノロジープラットフォームは、Lazadaのデータをクロールして価格比較ウェブサイトやアプリケーションを構築する必要があります。これにより、ユーザーは様々なプラットフォームの価格や割引情報を簡単に比較できます。
- 自動化された在庫管理: 商業者はLazadaのデータをクロールすることで、特定の商品在庫や価格が変更されたかどうかを自動的に確認し、製品戦略を適時に調整できます。
- ビジネスチャンスの探索: Lazadaの売れ筋商品や未開拓の商品分野をクロールすることで、潜在的なビジネスチャンスを発見し、新たな事業展開を開拓することができます。
なぜPython言語を使用してLazadaデータをクロールするの?
- 強力なクローラエコシステム
Pythonには、次のような豊富なクローラ関連ライブラリとフレームワークがあります。
requests: シンプルで使いやすい、静的ウェブページデータを取得するためのHTTPリクエスト送信に適しています。BeautifulSoup: 軽量なHTMLパーサーライブラリで、ウェブページコンテンツの抽出が容易です。Scrapy: 高性能なクローラフレームワークで、効率的な分散クロールとデータ管理をサポートします。Selenium: 動的なウェブページコンテンツを処理するために使用され、自動化されたブラウザ操作をサポートします。
これらのツールは、Lazadaウェブクロールの様々なシナリオに容易に適応できます。
- 豊富なデータ処理能力
Pythonは、次のような強力なデータ処理と分析ツールを提供します。
pandas: 効率的なデータテーブル操作ツールで、クロールされたデータの保存と処理が容易です。csvとjson: 一般的なデータ保存形式を組み込みでサポートし、結果の出力も容易です。NumPyとmatplotlib: データの統計と視覚化のための強力なツールです。
これらのツールにより、データクロールから分析までをワンストップで完了させることが可能です。
- 動的なウェブページ処理能力
Lazadaの動的に読み込まれるコンテンツについては、SeleniumやPlaywrightなどのツールと組み合わせたPythonを使用することで、リアルユーザーの行動をシミュレートし、JavaScriptレンダリングの制限を回避できます。さらに、クラウドブラウザサービス(Browserlessなど)を使用することで、動的ウェブページ処理の効率をさらに向上させることができます。
- 高い拡張性
Pythonは優れた拡張性を持ち、プロキシプール管理ツール(proxy-rotatorなど)、CAPTCHA解決ツール(anticaptchaなど)、データストレージサービス(MySQLやMongoDBなど)と容易に統合して、大規模なクロールニーズに対応できます。
Lazada製品データを簡単にスクレイピングする方法はありますか?
PythonのLazadaスクレイパーを構築する際は、ブロックされるのを回避する必要がありますが、これは困難な作業のように思えます。幸いなことに、簡単にLazada製品をスクレイピングできる使いやすい方法があります!
Scrapeless - 最適なLazadaスクレイピングAPI
Scrapelessは、正確で安全、かつスケーラブルなデータ抽出を必要とする企業や開発者を対象とした高度なウェブスクレイピングプラットフォームです。LazadaやAmazonなどのECプラットフォームを含む様々なソースからのデータ収集プロセスを簡素化する高度なソリューションを提供します。
その強力な設計により、Scrapelessは独自のスクレイピングツールの構築とメンテナンスを行う必要性を排除し、CAPTCHA解決、アンチボットシステム、IPローテーションなどの複雑な課題を容易に処理できます。商品詳細、価格動向、カスタマーレビューなど、どのようなデータの収集が必要であっても、Scrapelessは信頼性が高く効率的な方法でデータニーズに対応します。
Scrapeless LazadaスクレイピングAPIの展開方法
- ステップ1. Scrapelessにログインします。
- ステップ2. 「Scraping API」をクリックします。
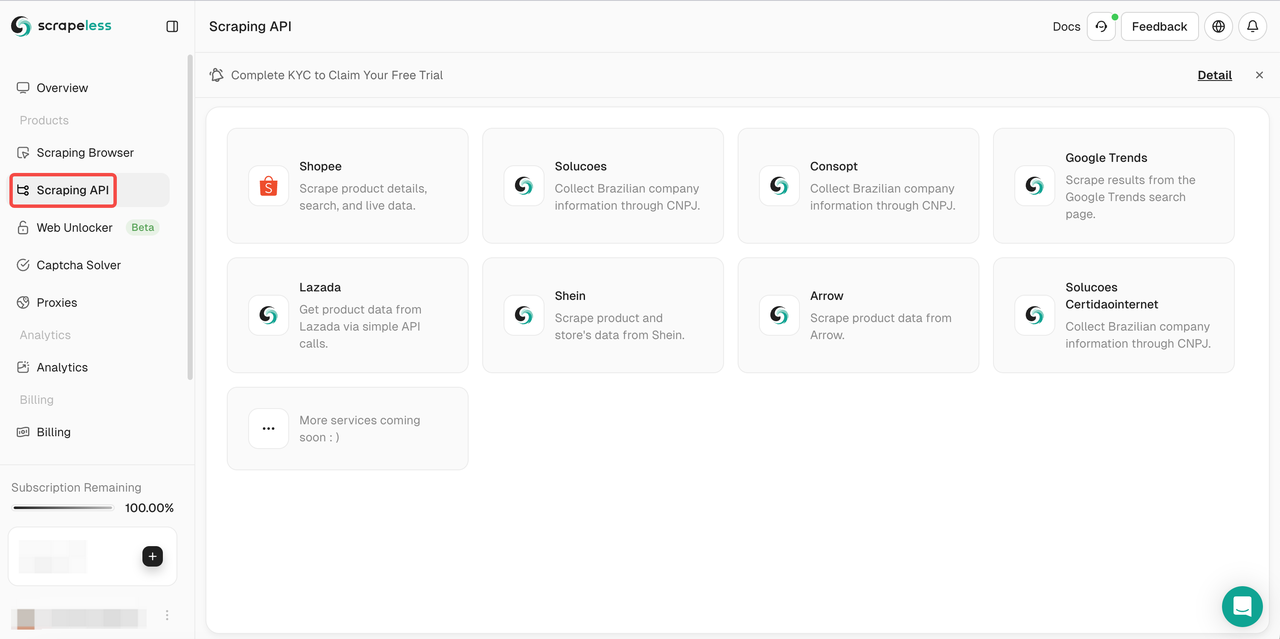
- ステップ3. Lazadaを選択し、Lazadaスクレイピングページを入力します。
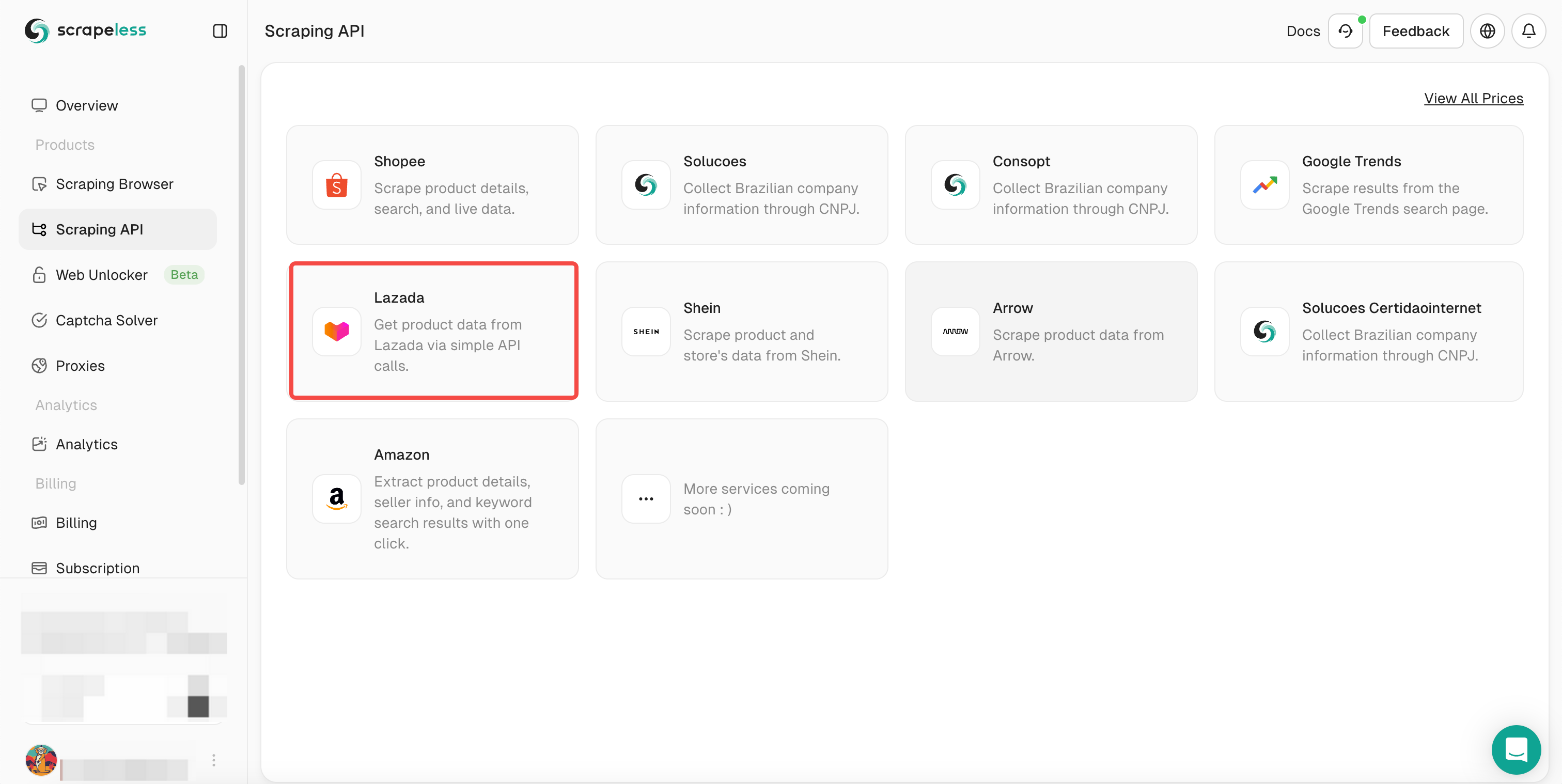
- ステップ4. アクションリストを下にスクロールし、クロールするデータ条件設定を選択します。次に、「Start Scraping」をクリックします。
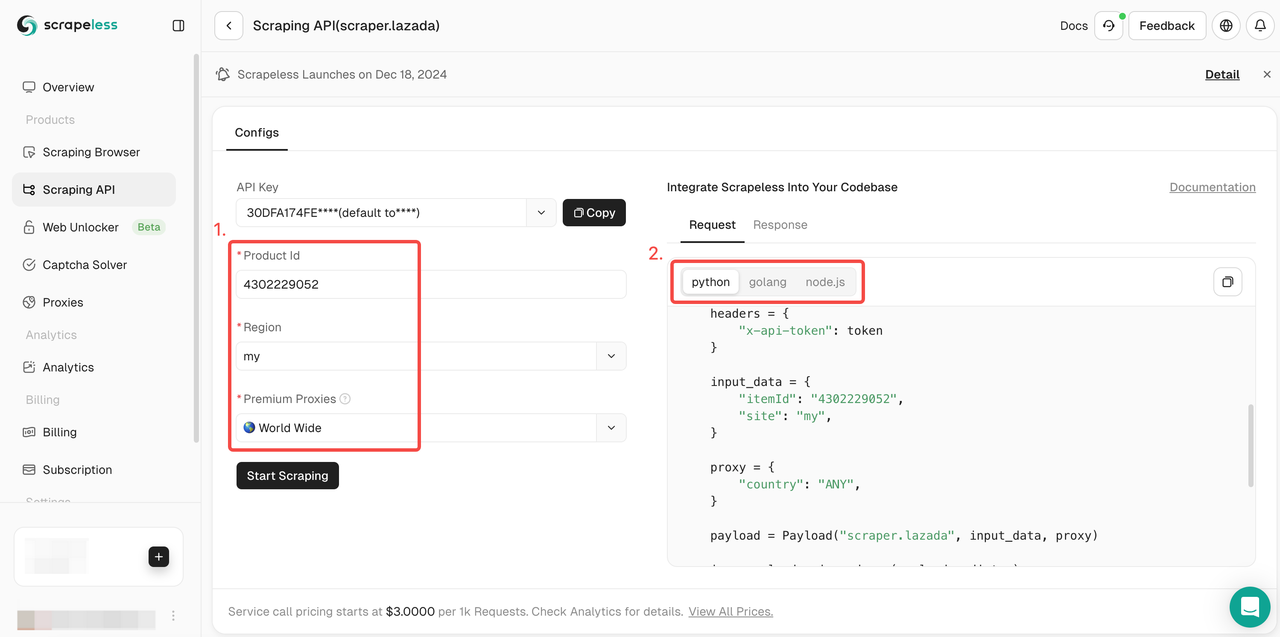
- ステップ5. 数秒でクロールが成功します。対応する構造化データが右側に表示されます。
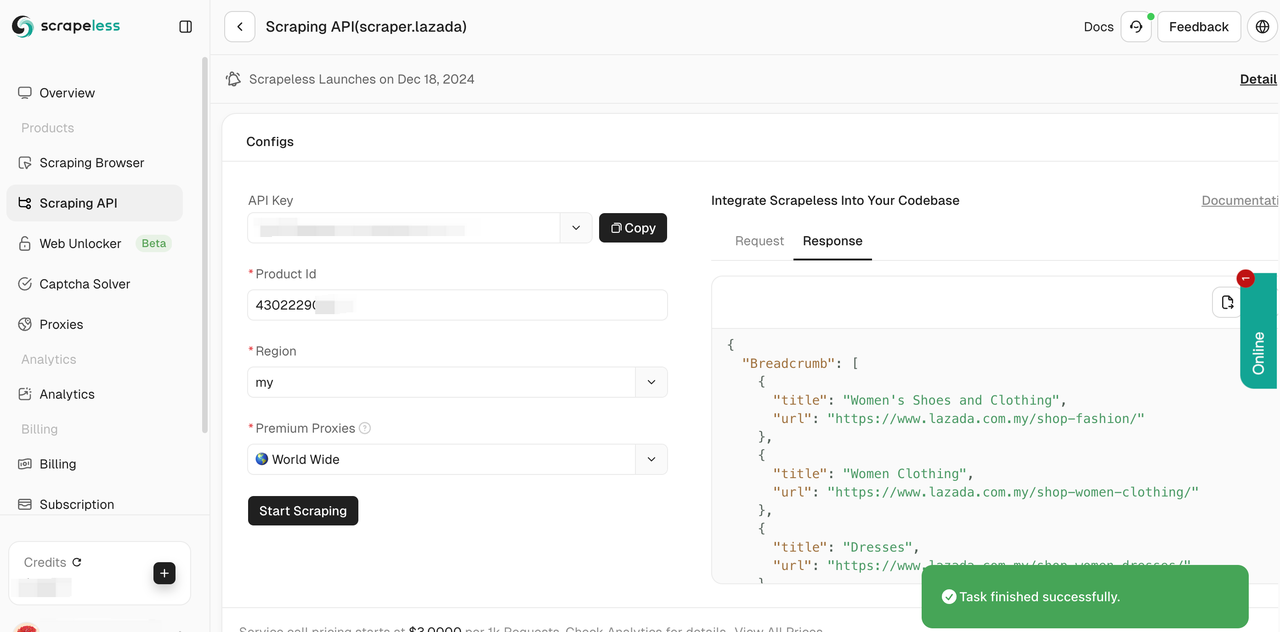
また、参照コードをプロジェクトに統合し、大規模なデータスクレイピングを展開することもできます。ここではPythonを例としていますが、クライアントではGolongとNodeJSも使用できます。
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #あなたのAPIトークン
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #商品IDを入力
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Pythonを使用してLazada製品データを取得する方法
ステップ1: 環境設定
必要なPythonライブラリをインストールします。主に、HTTPリクエストを送信するためのrequestsと、HTMLを解析するためのBeautifulSoupが必要です。サイトが動的コンテンツを使用している場合は、SeleniumまたはBrowserlessなどのクラウドブラウザサービスを使用できます。必要なライブラリは次のようにインストールします。
Bash
pip install requests beautifulsoup4 seleniumステップ2: Lazadaウェブサイトの検査
ブラウザでLazadaを開き、スクレイピングするページ(例:商品一覧または検索結果)を見つけます。開発者ツール(F12)を使用してページ構造を検査し、商品名、価格、リンクなどの商品データのタグとクラスを特定します。
ステップ3: HTTPリクエストの送信
静的ページの場合は、requestsライブラリを使用してGETリクエストを送信します。実際のブラウザを模倣するために、User-Agentなどのヘッダーを含めます。
Python
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://www.lazada.com.my/shop-mobiles/'
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f" ")ステップ4: HTMLコンテンツの解析
BeautifulSoupを使用して、適切なHTMLタグとクラスを特定することで商品情報を抽出します。
Python
products = soup.find_all('div', class_='c16H9d') # 実際のクラス名に置き換えます
for product in products:
name = product.text
print(f"Product Name: {name}")ステップ5: 動的コンテンツの処理
ページコンテンツがJavaScriptを使用して動的に読み込まれている場合は、Seleniumまたはクラウドブラウザを使用して完全なコンテンツをレンダリングします。
Python
from selenium import webdriver
driver = webdriver.Chrome() # ChromeDriverがインストールされていることを確認してください
driver.get('https://www.lazada.com.my/shop-mobiles/')
# コンテンツの読み込みを待ってスクレイピングします
elements = driver.find_elements_by_class_name('c16H9d')
for element in elements:
print(f"Product Name: {element.text}")
driver.quit()ステップ6: アンチボット対策の管理
Lazadaはボットをブロックするテクニックを使用している可能性があります。検出を回避するには、次の戦略を使用します。
- プロキシローテーション: IPアドレスの禁止を回避するために、プロキシをローテーションします。
- User-Agentスプーフィング: ヘッダーのUser-Agentをランダム化します。
- クラウドブラウザ: Browserlessなどのサービスは、高度な検出システムの回避に役立ちます。
ステップ7: データの保存
将来使用するために、スクレイピングされたデータをCSVファイルまたはデータベースに保存します。
Python
import csv
with open('lazada_products.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Product Name', 'Price', 'URL']) # 例:ヘッダー
# 商品の詳細を追加しますまとめ
Lazada製品データのスクレイピングは、EC業界の企業にとって大きな機会を提供します。取得したデータは、市場調査、競合分析、価格最適化、その他様々なデータ駆動型戦略的イニシアチブにとって貴重なリソースとなります。
ScrapelessスクレイピングAPIを使用すると、Lazada製品のスクレイピングをシンプルかつ効率的に行うことができます。CAPTCHAバイパスとIPスマートローテーションにより、ウェブサイトのブロックを回避し、容易にデータスクレイピングを実現できます。
さらに読む:
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


