
Node.JSによるAmazon Webスクレイピング - JavaScriptチュートリアル2025
Expert Network Defense Engineer
Amazonは、市場調査や価格監視に役立つ貴重な製品データを持つ、世界をリードするグローバルなeコマースプラットフォームです。JavaScriptとNode.js、Playwrightを使用することで、このデータを抽出するためのJavaScriptウェブスクレイパーを構築できますが、JavaScriptレンダリング、ボット検出対策、CAPTCHAなどにより、手動でのスクレイピングは困難です。
ScrapelessのAmazonスクレイピングAPIは、CAPTCHA、プロキシ、ウェブサイトのアンロック処理を行うことで、より高速で信頼性の高いソリューションを提供し、検出されることなくリアルタイムで正確なデータの取得を保証します。このチュートリアルでは、両方の方法を説明し、Scrapelessが効率的なAmazonデータスクレイピングに最適な選択肢である理由を示します。🚀
Amazonスクレイピングの課題
Amazonは強力なボット対策を備えているため、スクレイピングにはいくつかの課題があります。
- JavaScriptレンダリング: AmazonはJavaScriptに大きく依存しているため、単純なHTTPリクエストでデータ抽出することは困難です。動的なコンテンツをレンダリングするには、Playwrightなどのツールを使用したJavaScriptスクレイパーが必要です。
- CAPTCHA保護: 頻繁なCAPTCHAチャレンジはスクレイピングを中断し、データ抽出を継続するには解決メカニズムが必要です。
- IPブロックとレート制限: Amazonは同じIPからの繰り返しリクエストを検出してブロックするため、プロキシのローテーションやその他の回避テクニックが必要です。
- 頻繁なウェブサイトの変更: Amazonはウェブサイトの構造を定期的に更新するため、スクレイピングスクリプトが壊れ、継続的なメンテナンスが必要になる可能性があります。
Node.jsを使用したJavaScriptスクレイパーの構築方法
次の例では、JavaScriptを使用してAmazonをスクレイピングし、抽出したデータをローカルのJSONファイルに保存します。
スクラピングの準備
まず、必要なNode.jsウェブスクレイパーツールを設定する必要があります。
この記事では、多くの貢献者を持つ非常に活発なオープンソースプロジェクトであるPlaywrightを使用します。Microsoftによって開発されたPlaywrightは、複数のブラウザ(Chromium、Firefox、WebKit)と複数のプログラミング言語(Node.js、Python、.NET、Java)をサポートしているため、現在最も人気のあるJavaScriptスクレイピングフレームワークの1つです。
Node.jsのバージョンが18以上であることを確認してから、Playwrightをインストールするには、次のスクリプトを実行します。
Bash
# pnpm
pnpm create playwright
# yarn
yarn create playwright
# npm
npm init playwright@latestウェブブロックと頭痛のするプロジェクト構築に悩んでいますか?
Our Communityに参加して、無料トライアルで効果的な解決策を得ましょう!
ステップ1. ターゲットページの検証
スクレイピングの前に、**https://www.amazon.com/**にアクセスしてみてください。初めてサイトにアクセスする場合、CAPTCHAが表示されることがあります。
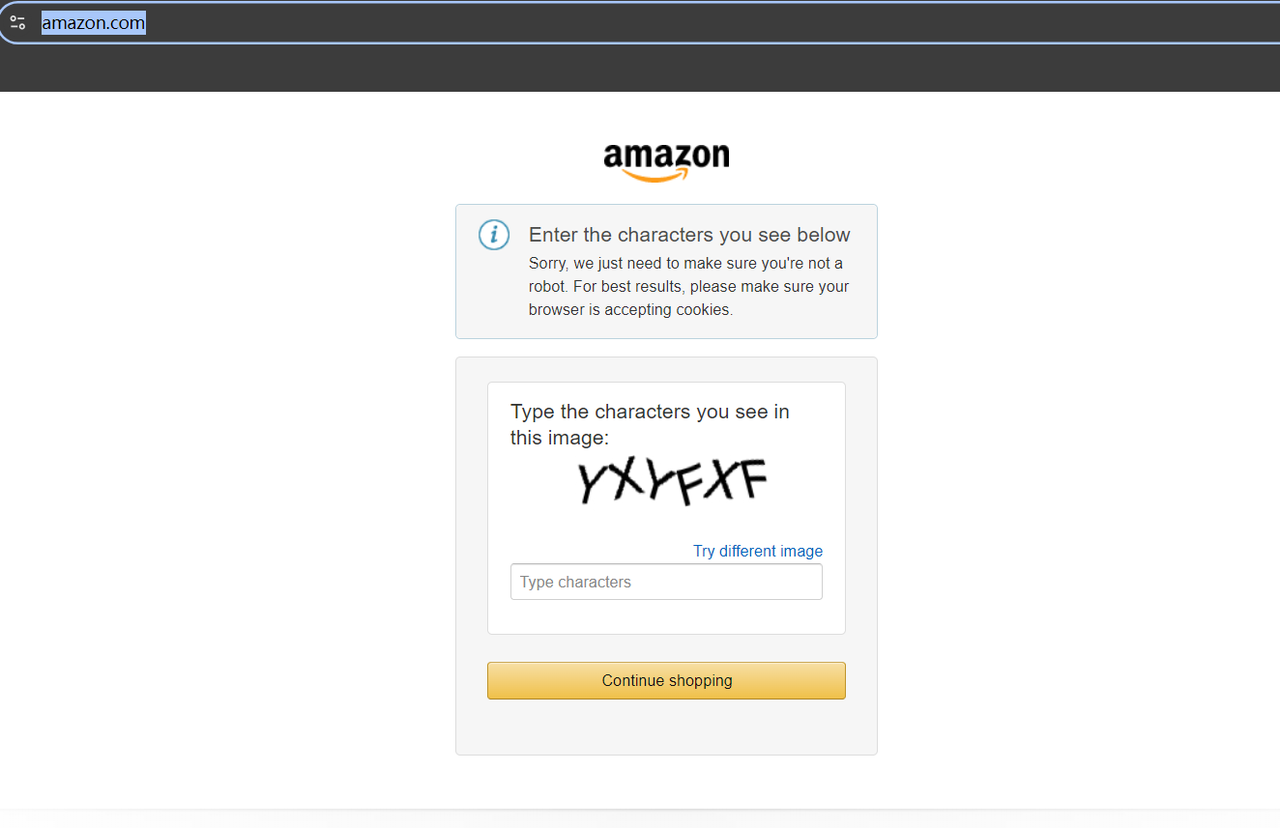
しかし、心配しないでください。CAPTCHA解決ツールを探す手間をかける必要はありません。代わりに、お住まいの地域またはプロキシの場所に合わせて特定のAmazonドメインにアクセスすれば、CAPTCHAはトリガーされません。
たとえば、英国のAmazonドメインであるhttps://www.amazon.co.uk/にアクセスしてみましょう。ページがスムーズに読み込まれることがわかります。次に、検索バーの上部に目的の製品キーワードを入力するか、次のようなURLを介して検索結果に直接アクセスしてみてください。
Bash
https://www.amazon.co.uk/s?k=jacketURLで、/s?k=の後の値は製品キーワードを表します。上記のURLにアクセスすると、Amazonでジャケット関連の製品が表示されます。
次に、開発者ツール(F12)を開いて、ページのHTML構造を調べます。カーソルを使用して要素を強調表示し、後でスクレイピングする必要があるデータを特定します。
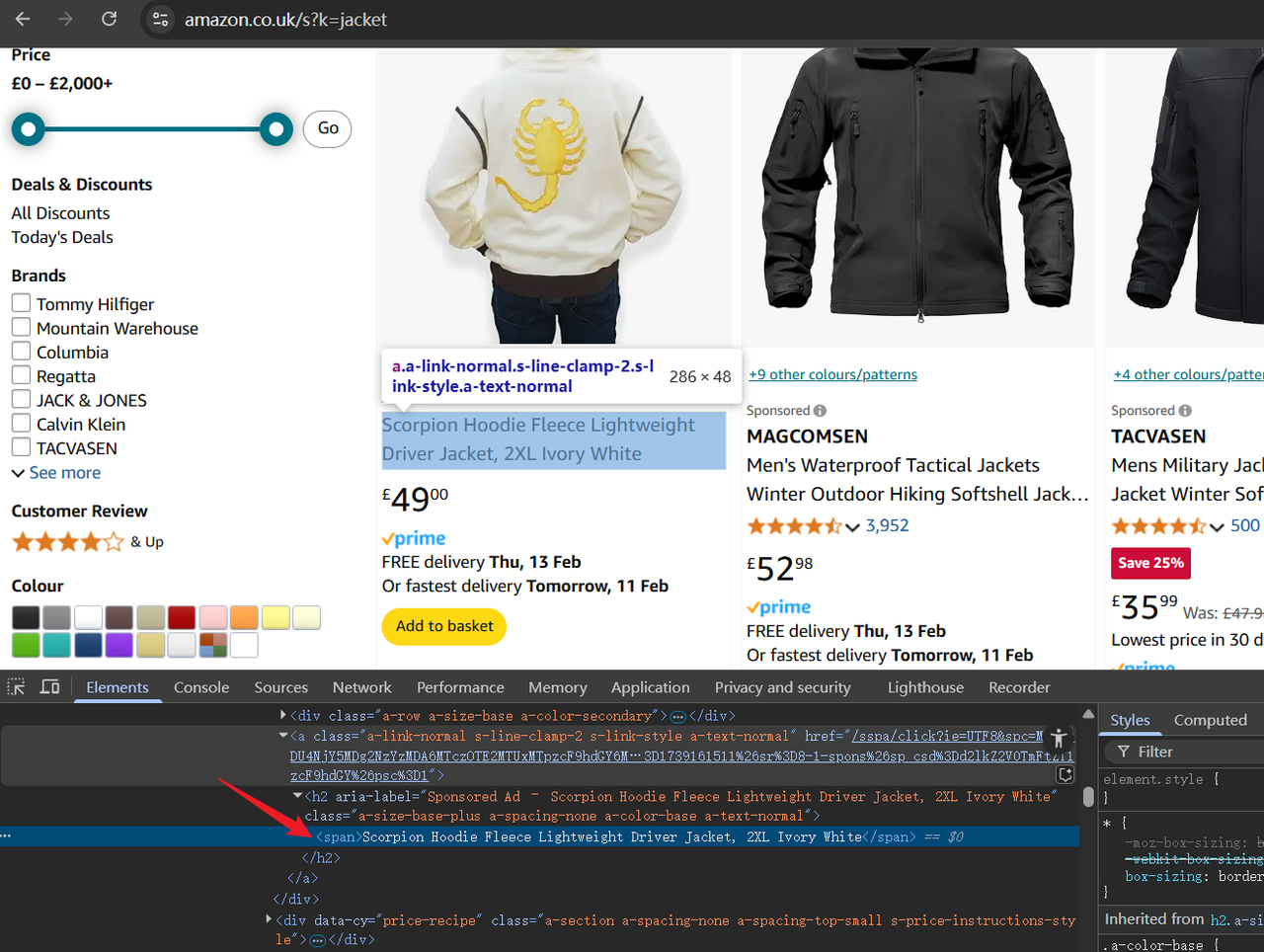
ステップ2. スクリプトの作成
最初に、スクリプトの先頭にコードを追加します。次のコードは、最初のスクリプト引数をAmazon製品キーワードとして受け取り、後でスクレイピングに使用します。
JavaScript
const productName = process.argv.slice(2);
if (productName.length !== 1) {console.error('product name CLI arguments missing!');
process.exit(2);
}次に、次の操作が必要です。
- ブラウザと対話するためにPlaywrightをインポートします。
- Amazonの検索結果ページに移動します。
- アクセスが成功したことを確認するためにスクリーンショットを追加します。
JavaScript
import playwright from "playwright";
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// デバッグ用のスクリーンショットを追加
await page.screenshot({ path: 'amazon_page.png' })次に、page.$$を使用してすべての製品コンテナを取得し、それらをループして関連データを抽出します。このデータはproductDataList配列に保存され、表示されます。
JavaScript
// すべての検索結果コンテナを取得
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 製品詳細の抽出:タイトル、評価、画像URL、価格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
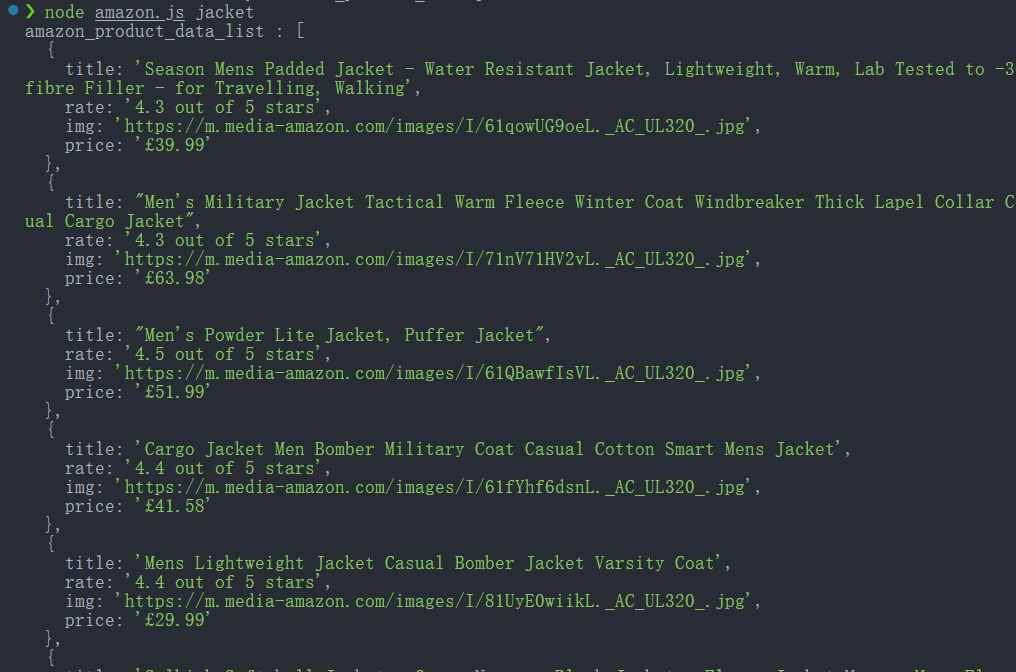
await browser.close();スクリプトは次のように実行します。
Bash
node amazon.js jacket成功すると、コンソールに抽出された製品データが表示されます。
ステップ3. スクラピングされたデータをJSONファイルとして保存する
データをコンソールに出力するだけでは、適切な分析には不十分です。Node.jsのfsモジュールを使用して、抽出されたデータをJSONファイルに保存しましょう。
JavaScript
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')それでは、完全なスクリプトを見てみましょう。
JavaScript
import playwright from "playwright";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// デバッグ用のスクリーンショットを追加
await page.screenshot({ path: 'amazon_page.png' })
// すべての検索結果コンテナを取得
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 製品詳細の抽出:タイトル、評価、画像URL、価格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > a > h2 > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
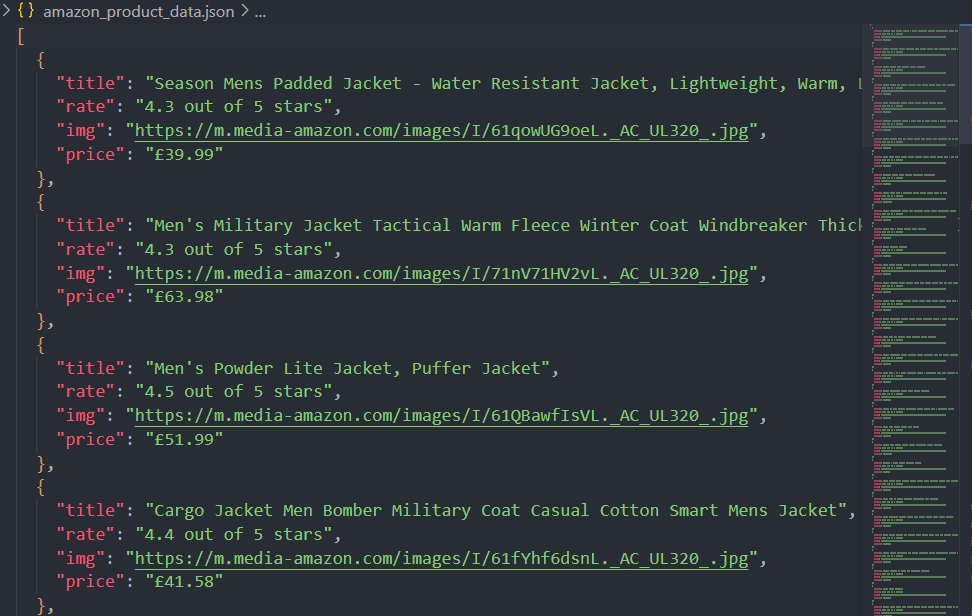
await browser.close();スクリプトを実行した後、データはコンソールに出力されるだけでなく、JSONファイル(amazon_product_data.json)にも保存されます。
Amazonのスクレイピング中にブロックされないようにする
Amazonからのデータのスクレイピングは、厳格なボット対策のために困難になる可能性がありますが、ScrapelessのWeb Unlockerを使用すると、これらの制限を効果的に回避できます。
Amazonは、IPレート制限、ブラウザフィンガープリンティング、CAPTCHA検証などのボット検出テクニックを使用して、自動化されたアクセスを防いでいます。ScrapelessのWeb Unlockerは、住宅用プロキシをローテーションし、実際のユーザーの動作を模倣し、動的コンテンツのレンダリングを処理することで、これらの障害を克服します。
PlaywrightなどのヘッドレスブラウザにScrapelessを統合することで、ユーザーはブロックされることなくAmazonの製品データをスクレイピングでき、シームレスで効率的なデータ抽出プロセスを保証します。
JavaScriptスクレイピングのベストプラクティスと考慮事項
JavaScriptでウェブスクレイパーを構築する際には、効率性を最適化し、動的コンテンツを処理し、一般的な落とし穴を回避することが重要です。重要なベストプラクティスと考慮事項をいくつか紹介します。
- JavaScriptでレンダリングされたページの処理
多くの最新のウェブサイトは、JavaScriptを使用して動的にコンテンツを読み込みます。従来のHTTPリクエスト(AxiosやFetchなど)では、そのようなコンテンツは取得できません。代わりに、Playwright、Playwright、またはSeleniumなどのヘッドレスブラウザを使用して、JavaScriptを多用したページからデータをレンダリングして抽出します。 - 高速スクレイピングのための同時実行の管理
スクレイパーを順番に実行すると遅くなる可能性があります。複数の並列スクレイプタスクを起動することで同時実行を実装し、パフォーマンスを向上させます。Promiseを使用したasync/awaitを使用し、キューシステムを管理して、スクレイプ負荷を効率的にバランスさせます。 - robots.txtとウェブサイトポリシーの尊重
スクレイピングする前に、ウェブサイトのrobots.txtファイルをチェックして、スクレイピングルールを確認します。これらのルールを無視すると、IPブロックや法的問題が発生する可能性があります。また、ユーザーエージェントのローテーションとリクエストの調整を使用して、ターゲットサーバーへの影響を最小限に抑えることを検討してください。 - Webアプリケーションファイアウォール(WAF)の回避
ウェブサイトは、Akamai、Cloudflare、PerimeterXなどのWAFを展開して、自動化されたトラフィックをブロックします。セッションの永続化、ブラウザフィンガープリンティングの回避、CAPTCHA解決ツールなどのテクニックは、検出とブロックを軽減するのに役立ちます。 - 効率的なURL管理と重複排除
訪問済みのURLセットを維持することで、スクレイパーが同じURLを複数回再訪しないようにします。正規化テクニックを実装してURLを正規化し、重複データの収集を防ぎます。 - ページネーションと無限スクロールの処理
ウェブサイトは、コンテンツを動的に読み込むために、ページネーションまたは無限スクロールを使用することがよくあります。ページネーション構造(例:?page=2)を特定するか、ヘッドレスブラウザを使用してスクロールをシミュレートし、すべてのコンテンツを抽出します。 - データ抽出とストレージの最適化
データを抽出した後は、適切にフォーマットし、効率的に保存します。JSON、CSV、またはMongoDBやPostgreSQLなどのデータベースに構造化データを保存して、処理と分析を改善します。 - 大規模スクレイピングのための分散スクレイピング
大規模なスクレイピングタスクの場合は、キューベースのスクレイピングフレームワークまたはクラウドブラウザソリューションを使用して、ワークロードを複数のマシンまたはクラウドインスタンスに分散します。これにより、単一システムのオーバーロードを防ぎ、フォールトトレランスを向上させることができます。
ScrapelessスクレイピングAPIを使用した、より高速で信頼性の高いソリューション
PlaywrightなどのヘッドレスブラウザにScrapelessを統合することで、ユーザーはJavaScriptでスクレイパーを構築して、ブロックされることなくAmazonの製品データを抽出でき、シームレスで効率的なデータ抽出プロセスを保証します。
機能:
✅ 1回のAPI呼び出しだけで、最新のデータに即座にアクセスできます。
✅ 月間1億件以上のリクエストで、毎秒200件以上の同時リクエストに対応。
✅ 各リクエストは平均5秒かかり、キャッシュを使用せずにリアルタイムのデータ取得を保証します。
✅ さまざまなニーズに対応するためにカスタマイズされたスクレイピングルールをサポートします。
✅ Amazonに加えて、他のeコマースプラットフォームもサポートするマルチプラットフォームスクレイピングをサポートします:Shopee、Sheinなど。
✅ 成功した検索のみを支払います。
Scrapelessを選択する理由
- リアルタイムデータ: 最新かつ正確な製品リストを保証します。
- 統合されたウェブサイトのアンロック: 制限とCAPTCHAを自動的にバイパスします。
- 合法性: Scrapelessは、検索結果にアクセスするための法的かつコンプライアンスに準拠した方法を提供します。
- 信頼性: APIは、洗練されたテクニックを使用して検出を回避し、データ収集の中断を防ぎます。
- 使いやすさ: Scrapelessは、Pythonと簡単に統合できるシンプルなAPIを提供しており、検索結果データに迅速にアクセスする必要がある開発者にとって理想的です。
- カスタマイズ可能: オーガニックリスト、広告など、コンテンツの種類を指定するなど、ニーズに合わせて結果を調整できます。
ScrapelessスクレイピングAPIは高価ですか?
Scrapelessは、競争力のある価格(対Zenrows&Apify)で信頼性が高くスケーラブルなウェブスクレイピングプラットフォームを提供し、ユーザーにとって優れた価値を保証します。
- スクレイピングブラウザ: 1時間あたり0.09ドルから
- スクレイピングAPI: 1,000 URLあたり0.8ドルから
- Web Unlocker: 1,000 URLあたり0.20ドル
- CAPTCHAソルバー: 1,000 URLあたり0.80ドルから
- プロキシ: 1GBあたり2.80ドル
購読することで、各サービスで最大20%割引を受けることができます。
ScrapelessのAmazonスクレイピングAPIの実装方法
Amazon製品ページからASIN番号を抽出したい場合、Scrapelessはこれを行うためのシンプルで効果的な方法を提供します。ScrapelessのAmazonスクレイパーAPIを使用することで、他の重要な製品詳細とともにASIN番号を簡単に取得できます。
ステップ1。Scrapelessにログインします。
ステップ2。スクレイピングAPIをクリックしてAmazonを選択し、Shopeeのスクレイピングページに入ります。
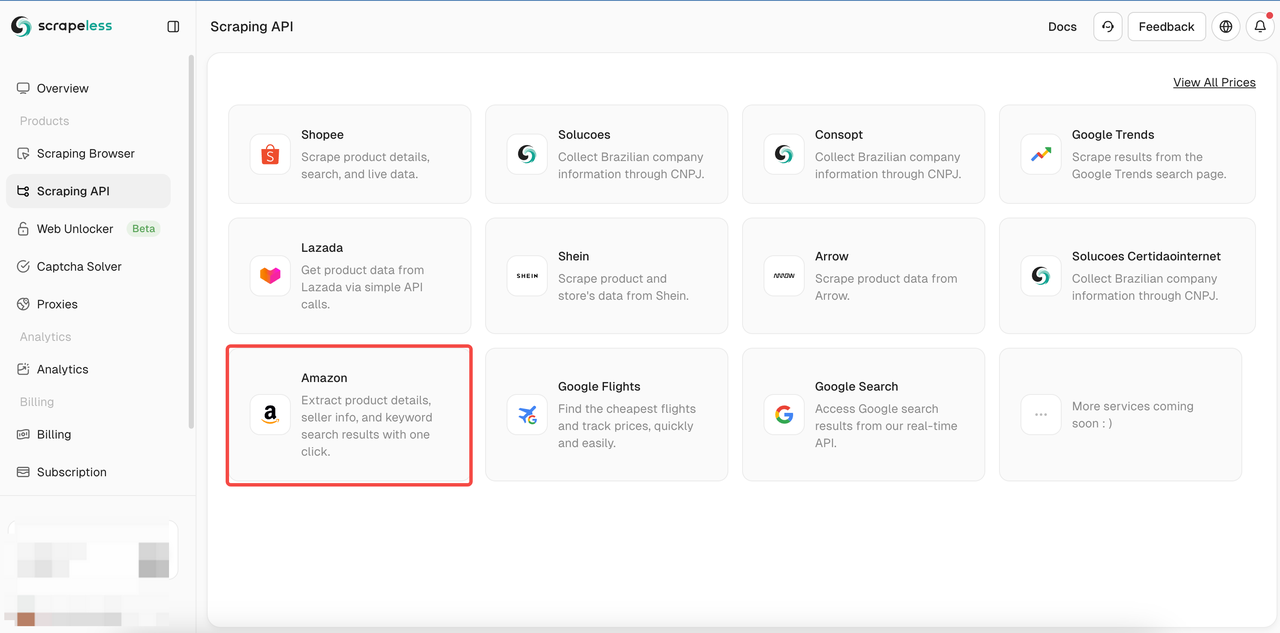
ステップ3。クロールするAmazon製品ページへのリンクを入力ボックスに貼り付けます。そして、クロールするデータの種類を選択します。
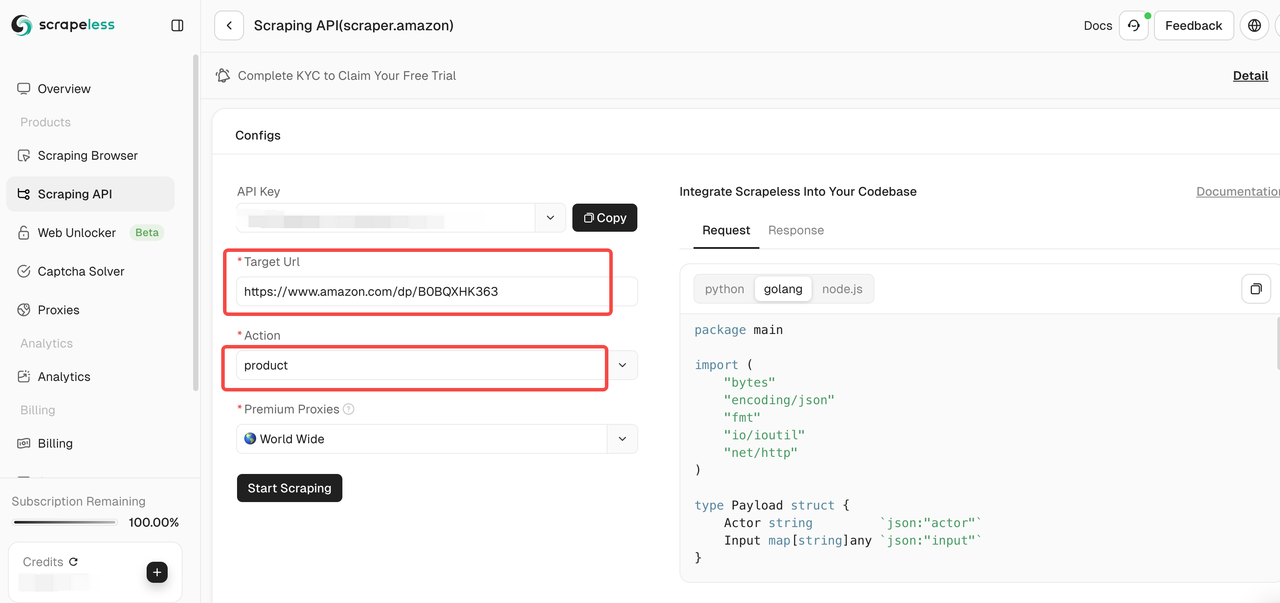
ツールページでは、クロールするデータの種類を選択できます。
- セラー: セラー名、評価、連絡先情報など、セラー情報をクロールします。
- 製品: タイトル、価格、評価、コメントなどの製品詳細をクロールします。
- キーワード: 製品のSEOと市場トレンドの分析に役立つ、製品関連のキーワードをクロールします。
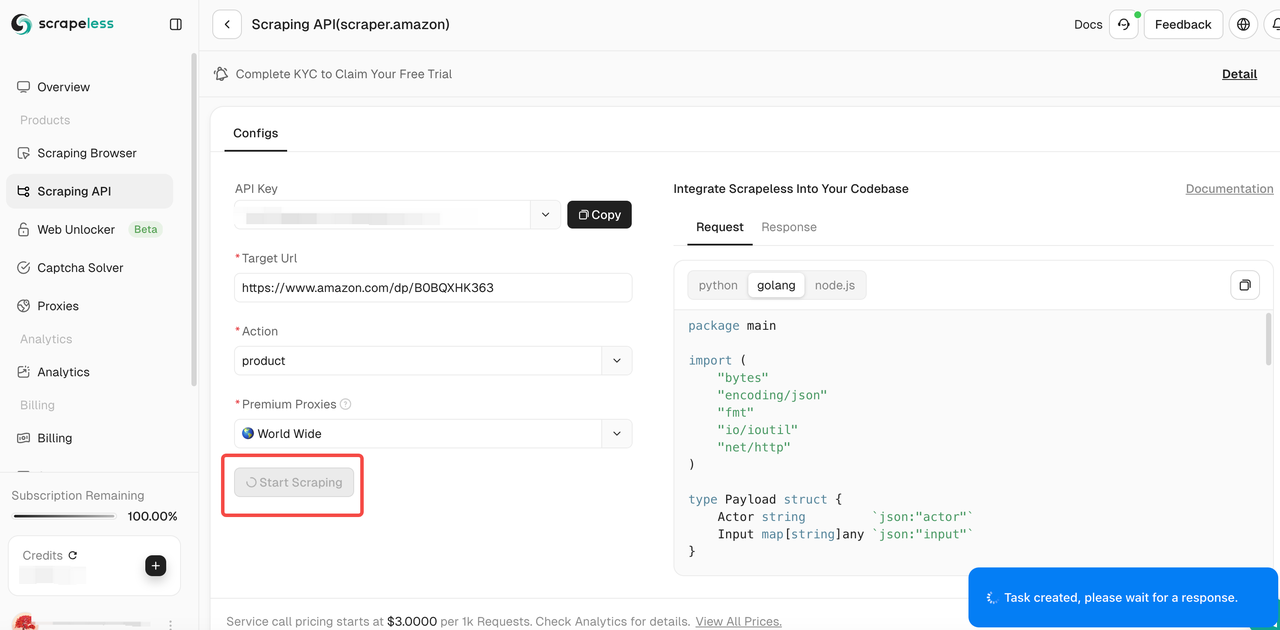
ステップ4。入力リンクと選択したデータの種類が正しいことを確認した後、「開始スクレイピング」ボタンをクリックします。システムはデータのクロールを開始し、ページの右側のパネルにクロールされた結果を表示します。
ステップ5。クロールが完了したら、右側のペインでクロールされたデータを確認できます。結果は、分析しやすい明確な形式で表示されます。
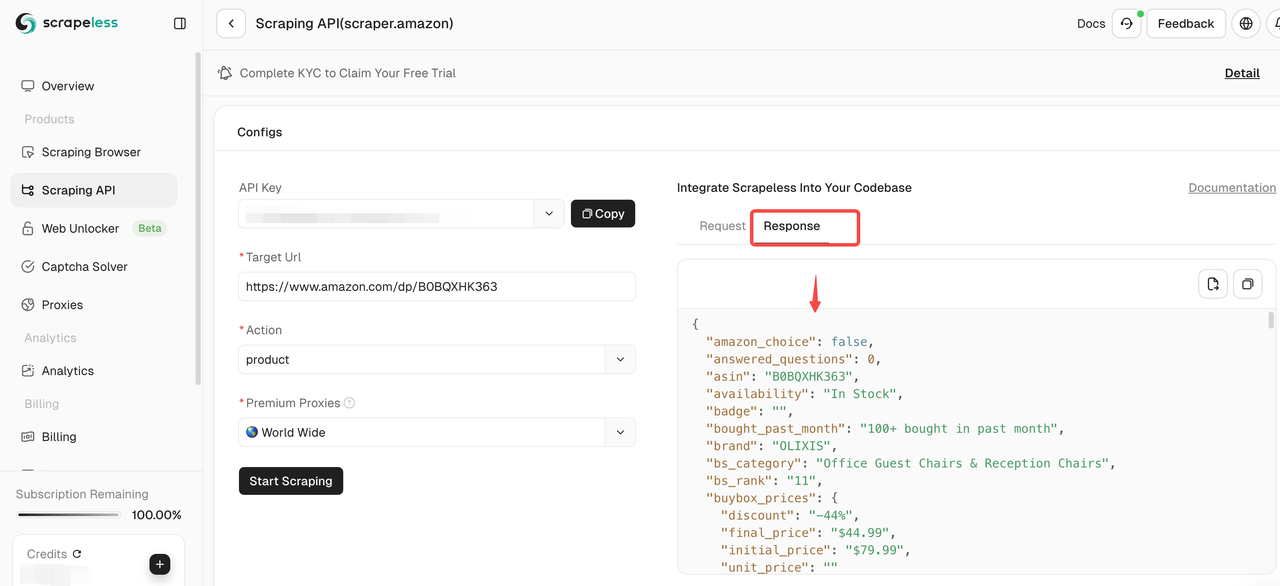
他の製品をクロールする必要がある場合は、「続行」をクリックして新しいAmazonリンクを入力し、上記の手順を繰り返します。
コードをプロジェクトに直接統合することもできます:
Node.js
JavaScript
const https = require('https');
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; // APIトークン
const inputData = {
action: "product",
url: " " // 製品URL
};
const payload = new Payload("scraper.amazon", inputData);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();Python
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " ## APIトークン
headers = {
"x-api-token": token
}
input_data = {
"action": "product",
"url": " " ## 製品URL
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Golang
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " // APIトークン
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"action": "product",
"url": " ", // 製品URL
}
payload := Payload{
Actor: "scraper.amazon",
Input: inputData,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}まとめ:2025年にAmazonをスクレイピングする最良の方法
Node.jsを使用したJavaScriptスクレイパーの構築により、スクレイピングプロセスの完全な制御が可能になりますが、動的コンテンツの処理、CAPTCHAの解決、プロキシの管理、検出の回避などの課題があります。これは、かなりの技術的な努力と継続的なメンテナンスが必要です。
大規模で効率的で検出されないスクレイピングには、ScrapelessのAPIが最適です。ボット検出の複雑さを排除し、データ抽出を簡単かつスケーラブルにします!
🚀 ScrapelessのAmazonスクレイピングAPIを今日お試しくださいして、高速で信頼性が高く、心配のないスクレイピング体験をお楽しみください!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


