
Naver製品をScrapeless Scraping APIでスクレイピングする方法は?
Senior Web Scraping Engineer
オンラインショッピングの普及に伴い、全小売売上の24%が今やeコマース市場から来ています。2025年までに、世界のeコマース小売売上は$7.4兆に達することが予測されています。
naverは、韓国最大の検索エンジンでありテクノロジーの巨人で、国のデジタルライフの中心です。eコマースやデジタル決済からウェブトゥーン、ブログ、モバイルメッセージングに至るまで、他のプラットフォームに比べて幅広い縦のデータをユーザーからキャッチします。
Naverのアーキテクチャは、予測可能なパターンを打破し、不一致を検出し、ほとんどのシステムよりも迅速に適応するように設計されています。もしあなたのスクレイピング戦略が静的なスクリプトやブルートフォースプロキシに依存しているなら、それはすでに時代遅れです。成功したNaverショップのデータスクレイピングは、防御を回避するだけではなく、セッションの動作の調整、タイミングの論理、プラットフォームの期待に合わせることが求められます。
Naver Shopから製品データを迅速に、大規模に、かつ最小コストでスクレイピングするにはどうすれば良いのでしょうか?
このガイドは、現代のNaverスクレイピングの課題に直面しているビジネスチーム、データ所有者、リーダーのためのものです!
💼 なぜNaverデータをスクレイピングするのか?
- 競争力のある価格戦略: Naverショッピングのデータスクレイピングを利用して競合の価格を収集し、市場で先手を打つことができます。
- 在庫最適化: 在庫レベルをリアルタイムで監視し、欠品を減らし効率を向上させます。
- 市場トレンド分析: 現れるトレンドや消費者の嗜好を特定し、提供物を調整します。
- 魅力的な製品リスト: 詳細な説明、画像、仕様を抽出して魅力的なリストを作成します。
- 価格監視と調整: 価格の変動や割引を追跡し、プロモーションを最適化します。
- 競合分析: 競合の製品提供、価格、プロモーションを分析し、優位に立つ方法を探ります。
- データ駆動マーケティング: ターゲットを絞ったキャンペーンのための消費者行動の洞察を集めます。
- 顧客満足度の向上: レビューや評価を監視して製品を改善し、満足度を高めます。
💡 Naverからどのような製品データを抽出できますか?
価格、在庫状況、説明、レビュー、割引をスクレイピングすることで、包括的で最新のデータを保証します。強力なNaverスクレイピングツールは以下を抽出可能です:
| フィールド | フィールド | フィールド |
|---|---|---|
| ✅ 製品名 | ✅ 顧客評価 | ✅ プロモーション |
| ✅ 製品の特徴 | ✅ 説明 | ✅ 画像 |
| ✅ レビュー | ✅ 配送オプション | ✅ カテゴリー |
| ✅ サブカテゴリー | ✅ 製品ID | ✅ ブランド |
| ✅ 配送時間 | ✅ 返品ポリシー | ✅ 在庫状況 |
| ✅ 価格 | ✅ 売り手情報 | ✅ 有効期限 |
| ✅ 店舗の場所 | ✅ 成分 | ✅ 割引価格 |
| ✅ 元の価格 | ✅ バンドルオファー | ✅ 最終更新日 |
| ✅ 在庫保持単位 (SKU) | ✅ 重量/ボリューム | ✅ 割引率 |
| ✅ 単価 | ✅ 栄養情報 |
⚠️ Naverから製品情報をスクレイピングする際の困難とは?
Naverからデータをスクレイピングする方法を考える前に、各企業はまず次の6つの主要な課題を考慮する必要があります:
1. 安定したエントリーポイントやセッション管理の欠如
匿名のスクレイピングは危険信号です。Naverは一貫したユーザー行動を要求します。認可された領域内でのユーザー活動を反映したセッションシミュレーションなしでは、あなたの行動は疑わしく、脆弱であり、すぐに捨てられてしまいます。
2. JavaScriptレンダリングの課題
JavaScriptはNaver上の重要なコンテンツと応答時間を制御しています。もしあなたの抽出ツールがJSを正確にレンダリングできない、または読み込み後の変化を検出できない場合、あなたのデータは不完全で、古く、または見えないものになります。この複雑さを無視すると、意思決定者のための洞察が歪む隠れた失敗につながる可能性があります。
3. セッション検証、地域ロック、CAPTCHAのアップグレード
すべての自動化の層にはリスクが伴います!
- 1つの層が失敗すると、あなたのセッションは期限切れになります。
- 2つの層が失敗すると、疑いが生じます。
- 3つの層が失敗すると、あなたはフラグが立てられ、ブロックされます。
丈夫なセッションシミュレーション戦略、地域IPのローテーション、ユーザー向けの課題(CAPTCHAを含む)の自動処理がなければ、あなたのインフラはカードの家のようになってしまいます。
4. Naver Shopのレイアウト変更およびインターフェースの再設計
Naverの変更は微妙で、頻繁で、予測不可能です!昨日効果的だったことが、今日には効果がないかもしれません。ページネーションの論理、タグの移動、またはロードの再構成の変更は、あなたのスクレイピングツールに深刻な影響を与える可能性があります。チームは常に再作業を強いられ、システムは検出、応答、自動修復しなければなりません—さもなければリソースが枯渇するリスクがあります。
5. レート制限とブロック
大規模なデータをスクレイピングする際には、短時間内のリクエスト数とデータ量に注意してください。賢明なデータ抽出の専門家は、常にページ操作、行動シミュレーション、多様なアクセスプロトコルに焦点を当てています—これらは大量データ取得のための基本的な設定です。
6. 韓国のデータプライバシーと法的規制
単一の盲点が何百万も費用を要する可能性があります!現地のデータスクレイピング要件や知的財産法を理解せずに海外からNaverデータをスクレイピングすると、企業は評判及び法的リスクにさらされます。スクレイピングを行う前に十分な調査を行うことを強く推奨します。
🤔 なぜScrapelessを使用してNaver製品データを抽出するのか?
Scrapelessは高度なウェブデータスクレイピング技術を採用し、さまざまなビジネスニーズに応じた高品質で正確なデータ抽出を確保します—市場分析や競合価格戦略から在庫管理や消費者行動分析まで。私たちのサービスは、小売業者、Eコマースプラットフォーム、マーケットアナリストのためのシームレスなソリューションを提供し、急速に変化する消費財市場(FMCG)についての深い洞察をもたらします。
私たちのNaverスクレイピングAPIを使用すれば、市場動向を簡単に追跡し、価格戦略を最適化し、急速に進化する食料品業界で競争力を維持できます。ビジネスの成長と革新を推進するための実用的なインサイトを提供することをお任せください。
主な特徴
1️⃣ 超高速かつ信頼性が高い:安定性を損なうことなく迅速にデータを取得します。
2️⃣ 豊富なデータフィールド:製品詳細、販売者情報、価格、評価などを含みます。
3️⃣ インテリジェントプロキシローテーションシステム:IPベースのアクセス制限を効果的に回避するためにプロキシIPを自動的に切り替えます。
4️⃣ 高度なフィンガープリンティング技術:ブラウザ特性やユーザーインタラクションパターンを動的にシミュレートし、洗練されたアンチスクレイピングメカニズムを回避します。
5️⃣ 統合されたCAPTCHA解決:reCAPTCHAやCloudflareチャレンジを自動的に処理し、スムーズなデータ収集を保証します。
6️⃣ 自動化:迅速に更新に対応する完全自動化されたスクレイピングプロセス。
⏯️ PLAN-A. APIでNaver製品データを抽出
- ストアIDと製品IDを設定するだけです。
- Scrapeless Naver APIは、Naver Shopから価格、販売者情報、レビューなどの詳細な製品データを抽出します。
- データをダウンロードして分析できます。
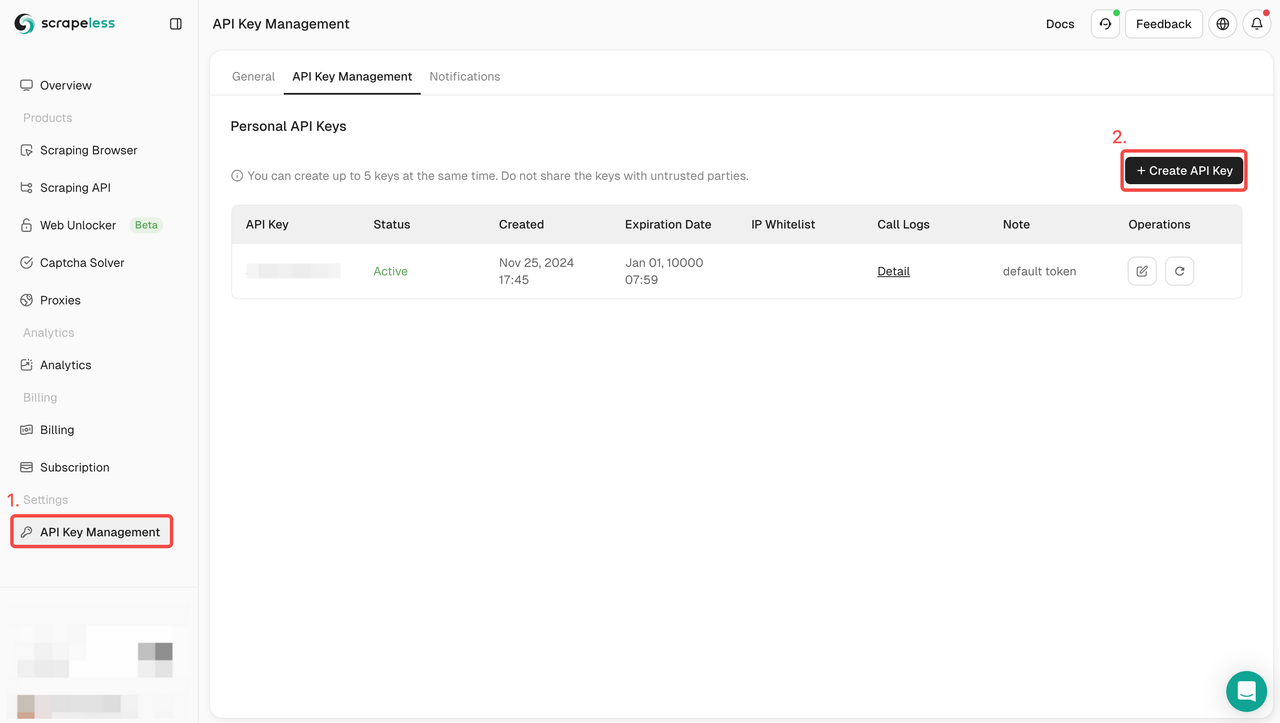
ステップ1: APIトークンを作成
始めるには、ScrapelessダッシュボードからAPIキーを取得する必要があります:
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、ユニークなAPIキーを生成します。
- 作成が完了したら、APIキーをクリックしてコピーします。
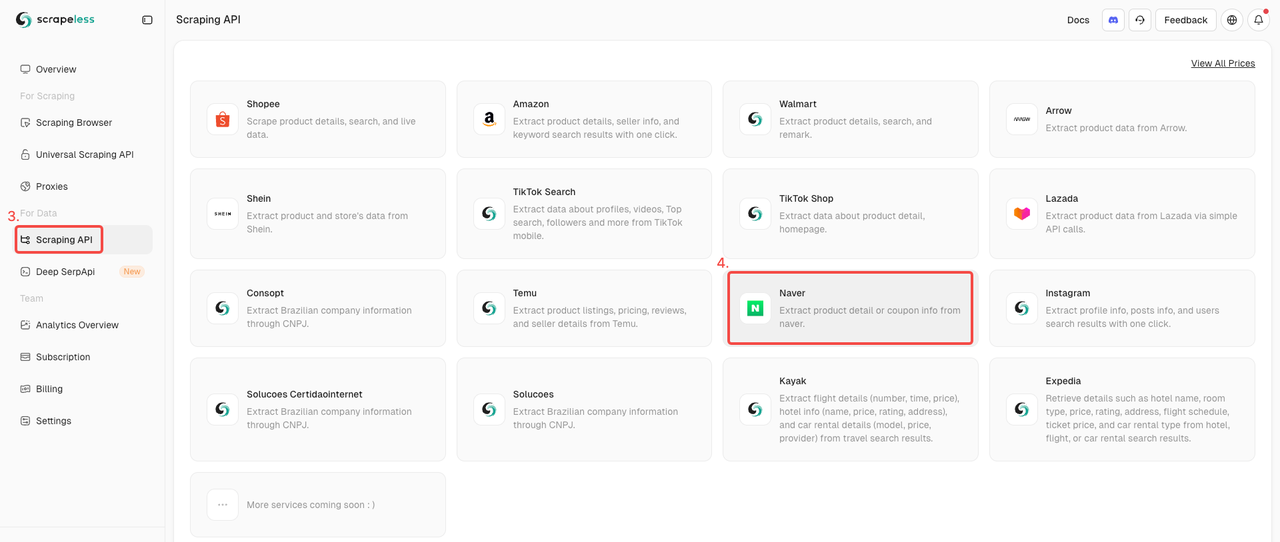
ステップ2. Naver Shop APIを起動
- データ収集用のスクレイピングAPIを見つけます。
- Naver Shopアクターをクリックして、製品データのスクレイピングの準備をします。
ステップ3: 目標を定義
NaverスクレイピングAPIを使用して製品データをスクレイピングするには、2つの必須パラメータを提供する必要があります:storeIdとproductId。channelUidパラメータはオプションです。
製品URLの中で直接製品IDとストアIDを見つけることができます。例えば:
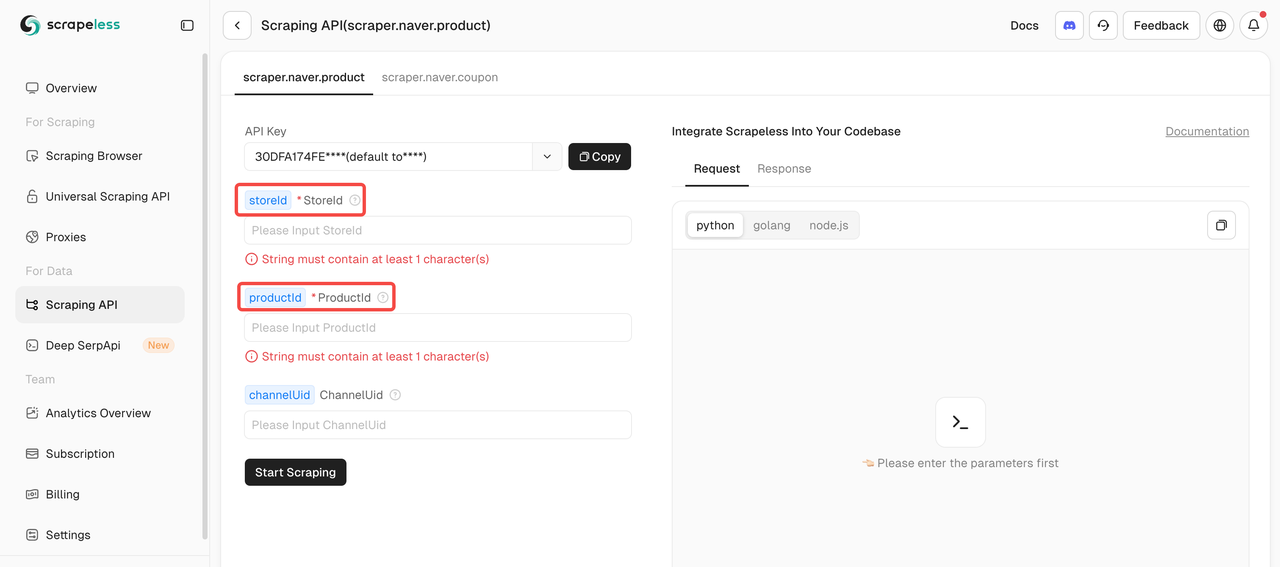
製品URLの中で直接製品IDとストアIDを見つけることができます。例として[바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등]を見てみましょう:
- ストアID:barudak
- 製品ID:4469033180
私たちはウェブサイトのプライバシーを厳重に保護します。このブログ内のすべてのデータは公開されており、クローリングプロセスのデモンストレーションのためにのみ使用されます。私たちは情報やデータを保存しません。
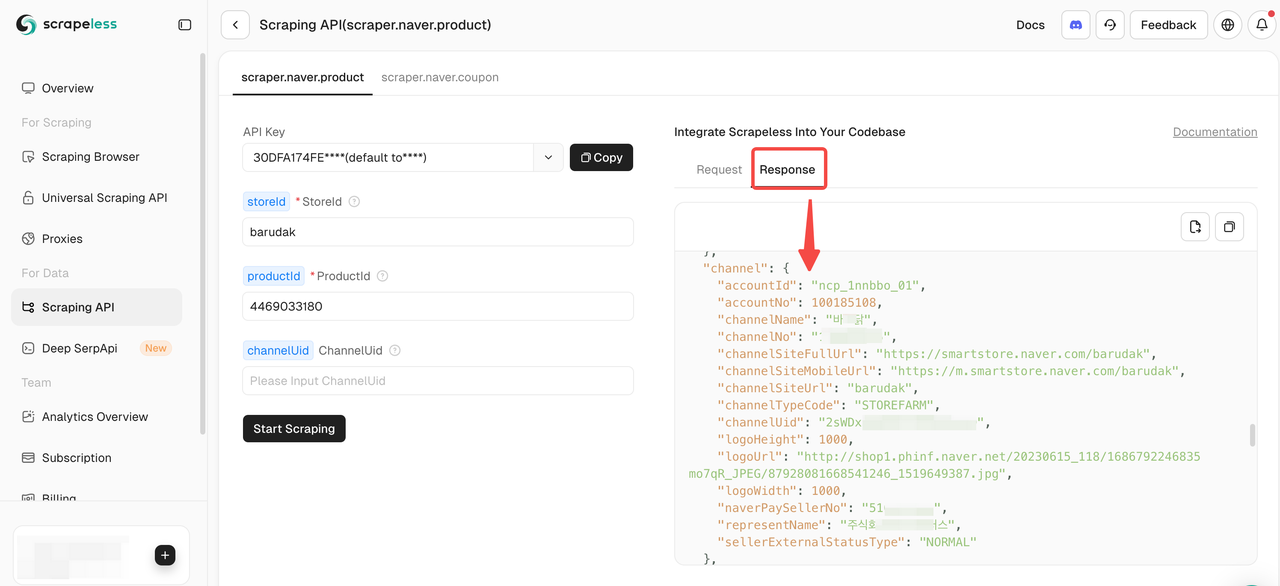
ステップ4: Naver製品データのスクレイピングを開始
必要なパラメータを入力したら、簡単にスクレイピングを開始して包括的な製品データを取得できます。
以下はNaver商品データを抽出するためのサンプルコードスニペットです。YOUR_SCRAPELESS_API_TOKENを実際のAPIキーに置き換えてください:
Python
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## Optional
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("エラー:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()⏯️ PLAN-B. Scraping Browserを用いてNaver商品データを抽出する
あなたのチームがプログラミングを好む場合、ScrapelessのScraping Browserは優れた選択肢です。これはすべての複雑な操作をカプセル化し、動的ウェブサイトからの効率的で大規模なデータ抽出を簡素化します。PuppeteerやPlaywrightなどの人気ツールとシームレスに統合します。
ステップ1: Scrapeless Scraping Browserとの統合
Scraping Browserに入った後、左側の設定パラメータを入力するだけで、スクレイピングスクリプトが自動的に生成されます。
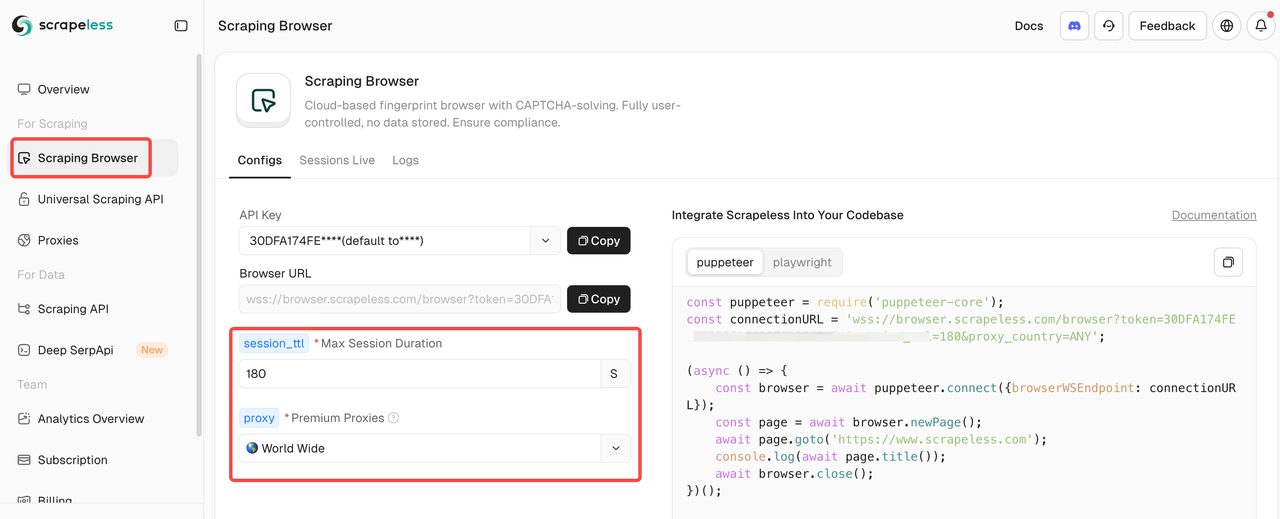
統合コードの例を示します(JavaScript推奨):
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=" YourAPIKey"&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Scrapelessは自動的にプロキシをマッチさせるため、追加の設定やCAPTCHA処理は不要です。プロキシローテーション、ブラウザフィンガープリンティング管理、堅牢な同時スクレイピング機能と組み合わせることで、Scrapelessは検出されることなくNaver商品データの大規模なスクレイピングを保証し、IPブロックやCAPTCHAの課題を効率的に回避します。
ステップ2: エクスポート形式の設定
次に、スクレイピングしたデータをフィルタリングおよびクリーンアップする必要があります。分析を容易にするために、結果をCSV形式でエクスポートすることを検討してください:
JavaScript
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSVファイルが保存されました: naver_product_data.csv');
await browser.close();
})();こちらが参考用のスクレイピングスクリプトです:
JavaScript
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { parse } = require('json2csv');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YourAPIKey&session_ttl=180&proxy_country=KR';
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
// 実際にクロールしたいNaver商品ページのURLに置き換えてください
const url = 'https://smartstore.naver.com/barudak/products/4469033180';
await page.goto(url, { waitUntil: 'networkidle2' });
// 簡単な例: 商品のタイトル、価格、説明などをクロールします(実際のページ構造に応じて調整してください)
const productData = await page.evaluate(() => {
const title = document.querySelector('h3._2Be85h')?.innerText || '';
const price = document.querySelector('span._1LY7DqCnwR')?.innerText || '';
const description = document.querySelector('div._2w4TxKo3Dx')?.innerText || '';
return {
title,
price,
description
};
});
console.log('商品データ:', productData);
// CSVにエクスポート
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSVファイルが保存されました: naver_product_data.csv');
await browser.close();
})();おめでとうございます。Naver商品データのクロールプロセスを成功裏に完了しました!
まとめ
Naverデータのスクレイピングは戦略的な投資です!しかし、チームがプログラミングを使ってスクレイピングする際には、適応システムを実装し、セッション動作を調整し、プラットフォーム規制と韓国のデータ法を厳守する必要があります。Naverの動的なアーキテクチャと競争するためには、プロキシ、CAPTCHAソルバーの設定、リアルユーザー操作のシミュレーションなどの労働集約的なタスクが求められます。
実際、メンテナンスに多くの時間を費やす必要はありません!これを達成するためには、ブラウザ自動化ツールやAPIを含む堅牢なテクノロジースタックを活用し、ウェブブロックを気にすることなく、スケーラブルでコンプライアンスに準拠したNaver製品データの抽出を任意の規模で行うことが重要です。
今すぐ無料トライアルを始めましょう! 1,000リクエストがわずか$3で、ウェブ上で最も安い価格です!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


