
スクレイプレススクレイピングブラウザ: AIのための高同時実行自動化ソリューション
Advanced Data Extraction Specialist
はじめに:Scrapeless スクレイピングブラウザの同時実行能力のアップグレード
私たちは、Scrapeless の開発者および創設チームとして、AI自動化の未来に対する真摯な情熱に駆動されています。私たちの使命は、真に「AIのために設計された」自動化ブラウザを創造することです。過去数年間、Browserless.ioから多くのクラウドベンダーが「ブラウザ・アズ・ア・サービス」(BaaS)を立ち上げたことで、市場はAIエージェントが新たなインタラクション媒体、つまりAI専用に設計されたクラウドベースのブラウザを緊急に必要としていることを証明しました。例えば、Auto-GPTはBooking.comで最適なフライトを自律的に検索したり、Googleフォームに自動でアンケートの回答を提出したりできます。同様に、ChainGPTのインテリジェントなカスタマーサービスシステムは、リアルタイムでeコマースのバックエンドにログインし、注文データを取得し、複数のステップの操作を完了します。これらの機能の背後には、高い同時実行性と「人間のような」シミュレーションの極端な追求があります。
しかし、既存のソリューションはしばしば2つの重要な点でつまずいていることが観察されています:
1. 高同時実行スケーリング: 数百または数千のプロキシタスクが同時にサイトをターゲットにすると、単一のノードがすぐにボトルネックになります。
2. 現実的なブラウジング行動: フィンガープリン卜回転、TLS特性、マウスの軌跡などの多次元の偽装が不正確であると、eコマースプラットフォームやソーシャルメディアのリスク管理システムによって即座にフラグを立てられる可能性があります。
これらの課題を念頭に置きながら、私たちは製品設計段階で2つの主要な分野に焦点を当てました:
-
クラウド弾力性のあるスケーリング: Scrapelessは、ピークトラベルでもゼロキューイングとゼロタイムアウトを確保し、数十から無制限の同時セッションへのシームレスなスケーリングをサポートします。
-
フルスタック人間のような保護: Chromiumカーネルを深くカスタマイズすることで、Scrapelessは多次元のフィンガープリン卜難読化、制御可能なTLSハンドシェイク戦略、進化的なマウス/キーボードシミュレーションを実現し、ターゲットサイトが異常を検知することをほぼ不可能にしています。
これがさらに驚くべき点は、最高のパフォーマンスを提供する一方で、業界基準ソリューションの70%にコストを削減し、開発者が大規模なテストや長期間のタスクに対して60%〜80%の経費を節約できるようにしていることです。数千のSKUを日常的にスクレイピングして監視する必要がある場合でも、数千のカスタマーサービスボットを複数のサイトに運用する必要がある場合でも、Scrapelessは最も信頼性が高く、コスト効率の良いインフラを提供します。
次のセクションでは、Scrapelessスクレイピングブラウザの価格優位性、コア機能、将来のロードマップについて掘り下げ、"AIのためのブラウザ"時代の究極の選択肢である理由を包括的に理解できるようにします。
Scrapeless スクレイピングブラウザ価格比較分析
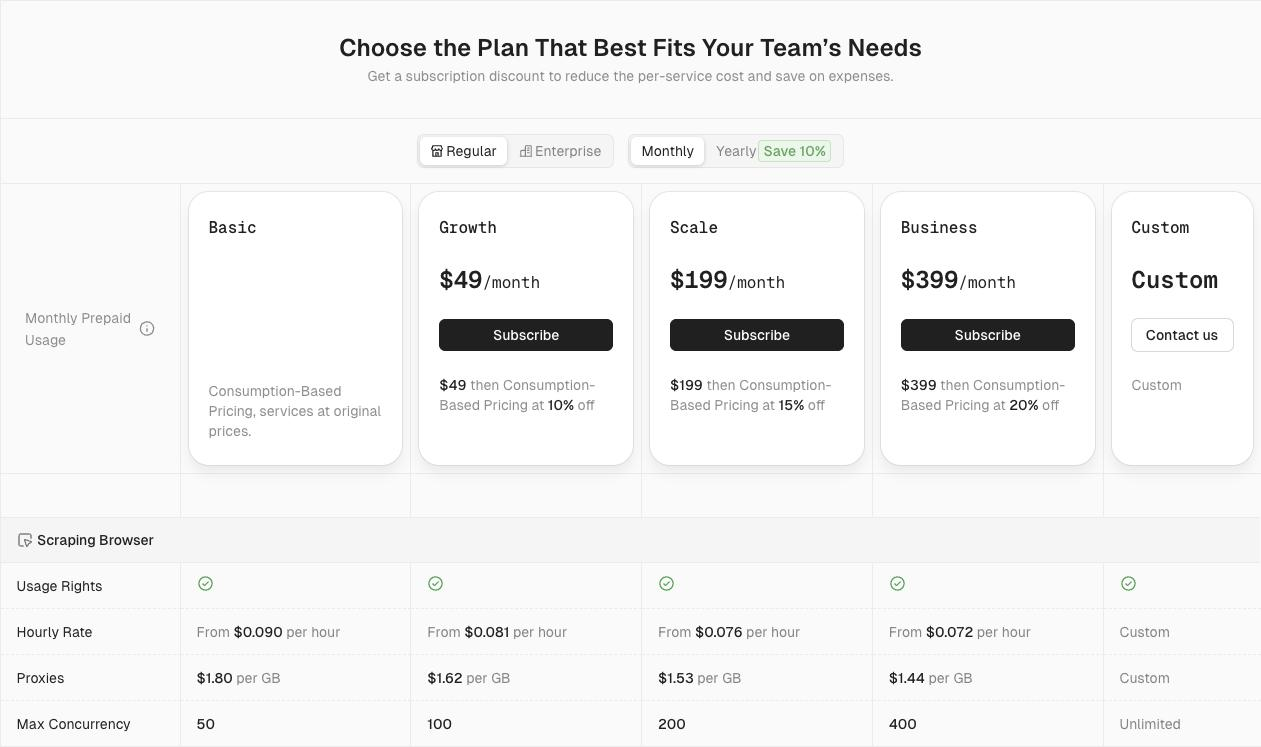
1. 時間単位料金とプロキシ料金の比較
以下は、競合製品の時間単位料金とプロキシ料金の価格帯の比較です。ユーザーがScrapelessのコストパフォーマンスの優位性を迅速に理解できるように、概算価格帯を抽出しました。
表:価格帯比較
| ツール名 | 時間単位料金範囲(USD/時間) | プロキシ料金範囲(USD/GB) | 同時実行サポート | 備考 |
|---|---|---|---|---|
| Scrapeless | $0.063 – $0.090 / 時間(同時実行数と使用量によって変動) | $1.26 - $1.80 / GB | 50 / 100 / 200 / 400 / 600 / 1000 / 無制限 | - カスタムプロキシサポート - Cloudflare、reCAPTCHA、AWS WAF用の無料CAPTCHA解決; 将来的にはImagetotext CAPTCHAサポート予定 - 実際の使用量に基づいて料金が変動 |
| Browserbase | $0.10 – $0.198 / 時間(2-5GBの無料プロキシが含まれる) | $10 / GB(無料枠後) | 3(基本) / 50(高度) | - カスタムプロキシサポート |
| Brightdata | $0.10 / 時間 | $9.5 / GB(標準);$12.5 / GB(プレミアムドメイン) | 無制限 | - カスタムプロキシ非対応 - 実際の同時実行セッションは以下の要因で影響を受ける可能性があります: - アカウントプランと使用制限 - 利用可能な帯域幅とシステムリソース - 請求設定とクレジット残高 |
| Zenrows | $0.09 / 時間 | $2.8 - $5.42 / GB | 最大 100 | - カスタムプランは $2.8 / GB から利用可能 - ビジネスプランは最大 100 の同時接続をサポート |
| Browserless | $0.084 – $0.15 / 時間(「ユニット」単位で請求) | $4.3 / GB | 3 / 10 / 50 | - カスタムプロキシをサポート - 1000 の hCaptcha と reCaptcha の解決ごとに $7 - 各「ユニット」は 0.00833 時間のブラウザ時間に相当 - Cloudflare バイパスが無料で含まれています |
2. 同時シナリオでの価格比較
Scrapeless の価格優位性をより直感的に示すため、典型的な使用シナリオを通じて比較します。
ケース 1: 単一リクエスト (1 ブラウザインスタンス)
ユーザーが 1 時間のリクエスト(例: ChatGPT へのログイン)を開始し、1GB のトラフィックを消費することを仮定します。
Scrapeless(標準パッケージ料金に基づく):
- 時間単価: $0.072
- プロキシ料金: $1.44
- 合計コスト = 0.072 + 1.44 = $1.512
競合他社(Brightdataを例に):
- 時間単価: $0.10
- プロキシ料金: $9.5(標準)
- 合計コスト = 0.10 + 9.5 = $9.6
コスト優位性: Scrapeless はコストの約 84.25% を節約します。
ケース 2: 大規模同時シナリオ (100 ブラウザインスタンス)
Scrapeless のユーザーが、複数のウェブサイトからリアルタイムでデータをスクレイピングし、動的なランキングレポートを生成する LLM ベースのマーケティングランキング監視システムを構築しています。彼らの現在のビジネス要件は、100 のブラウザインスタンスを同時に実行し、1 時間持続し、40GB のトラフィックを消費することを要求しています。
Scrapeless(標準パッケージ料金に基づく):
- 時間単価: 0.072 × 100 = 7.2
- プロキシ料金: 1.44 × 40 = 57.6
- 合計コスト = 7.2 + 57.6 = $64.8
競合他社(Zenrowsを例に):
- 時間単価: 0.09 × 100 = 9
- プロキシ料金: 2.8 × 40 = 112
- 合計コスト = 9 + 112 = $121
コスト優位性: Scrapeless はコストの約 46.45% を節約します。
このユーザーは、プロジェクトの初期段階でメインストリームのブラウザ自動化ツールの詳細な価格とパフォーマンスの比較を行いました。彼らは、大規模同時タスクを処理する際に多くの競合他社が次のような問題を抱えていることを発見しました:
- 不十分な高同時実行性のサポート: ほとんどのツールは、100 インスタンスの要件を満たせない低い最大同時実行制限を持っています。ユーザーの将来的な同時実行ニーズは 500 を超える可能性があり、市場にはこのレベルの需要に対応できる製品がほとんどありません。
- 高額な追加料金: 一部の製品は高同時実行タスクに対して追加料金を請求するため、全体的なコストが急騰します。
- 限られた技術サポート: CAPTCHA やスクリーピング対策に直面した際、一部のツールは組み込みの解決策を欠いており、開発の複雑さが増します。
包括的な評価の結果、ユーザーは最終的に Scrapeless Scraping Browser を選択しました。彼らは、Scrapeless が費用の大幅な優位性(コストのほぼ 47% を節約)を提供するだけでなく、データスクレイピングシステムの効率性と信頼性を確保することも述べました。
Scrapeless Scraping Browser: AI エージェント向けのクラウドベースのブラウザ自動化
Scrapeless Scraping Browser は、データスクレイピング、AI エージェント、およびプロキシ システム用に設計されたクラウドベースのブラウザ自動化ツールです。Chrome カーネルレベルでの深いシミュレーション技術を通じてリアルブラウザ環境を提供し、動的なフィンガープリンテイングの難読化と TLS フィンガープリンターの偽装をサポートして、人間に近いユーザー行動を確保します。さらに、完全にユーザー制御されており、データをストレージしないため、コンプライアンスとプライバシー保護を保証します。
技術的な利点
1. リアルブラウザ環境
- Chrome カーネルサポート: 実ユーザーの行動をシミュレートする完全なブラウザ環境を提供します。
- TLS フィンガープリンターの偽装: TLS フィンガープリンターを偽造することで従来のスクリーピング対策を打破し、通常のブラウザとして偽装します。
- 動的フィンガープリンターの難読化: ブラウザ環境変数(例: User-Agent、Canvas、WebGL)を動的に調整し、人間のような行動を強化し、高度なスクリーピング対策を回避します。
2. クラウド展開とスケーラビリティ
- クラウドアーキテクチャ: 完全にクラウドベースで、ローカルリソースの必要性を排除し、シームレスなグローバル分散展開を可能にします。
- 高い同時実行性のサポート: 無制限の並列タスクをサポートし、大規模なデータスクレイピングや複雑な自動化シナリオに適しています。
- 簡単な統合: コードのリファクタリングを必要とせず、既存の自動化フレームワーク(例: Playwright、Puppeteer)とシームレスに統合されます。
3. AI エージェント向けに特化して設計
- 自動プロキシサポート: AI エージェントが複雑なブラウザ自動化タスクを実行するのを助けるために強力なプロキシ機能を提供します。
- 柔軟な呼び出し: マルチタスクの並列処理をサポートし、知能プロキシシステムや AI 駆動のアプリケーションを構築するための理想的なツールです。
コア機能
Scrapeless Scraping Browserのコア競争力は、その強力な機能と柔軟性にあります。特に以下の3つの分野で優れています:
(1) CAPTCHA解決能力
Scrapeless Scraping Browserは、高度なCAPTCHA解決機能を備えており、reCAPTCHAやCloudflare Turnstileなどの主流のCAPTCHAタイプを自動的に処理します。
- 業界をリードする成功率 : Scrapelessは、98%以上の成功率を誇る非常に効率的なCAPTCHAソリューションを提供します。
- 追加料金なし : 競合他社がCAPTCHA解決に追加料金を課す中、Scrapelessはこの機能をベースサービスに統合しており、追加費用は発生しません。
- リアルタイム処理 : CAPTCHA解決エンジンはミリ秒単位でタスクを完了し、スムーズなタスク実行を保証します。
(2) ツール統合サポート
- 包括的な自動化ツールのサポート : Scrapelessは、PuppeteerやPlaywrightなどの人気のブラウザ自動化ツールをサポートしており、開発者が迅速に統合できるようにしています。
- AI統合能力 : Scrapelessは、Browser Use、Computer Use、およびLangChainとの深い統合を計画しており、大規模言語モデル(LLM)のさらなる可能性を探求し、AI駆動の動的ウェブインタラクションのユースケースを拡大します。
- 使いやすさ : 詳細なドキュメントと例コードが提供されており、ユーザーが迅速に始められるよう支援しています。
(3) 同時処理サポート
- 柔軟な同時処理能力 : Scrapelessは、50から無制限までの同時処理をサポートしており、小規模タスクから大規模自動化ニーズに対応しています。
- 追加料金なし : 競合他社が高同時処理シナリオに対して追加料金を課すことが多い中、Scrapelessは透明で柔軟な料金モデルを提供しています。
Scrapeless Scraping Browserの未来計画
今後、Scrapeless Scraping Browserは、基本的なスクレイピングから複雑なAI駆動の自動化まで、多様なニーズに応じてコア機能を最適化し、ユーザーにさらに強力なツールを提供し続けます。以下は、アップデートのための重点分野です:
1. コア機能の強化
- フィンガープリント設定 : タイムゾーン、言語、User-Agent、画面解像度などの環境変数の柔軟な設定をサポートし、人間らしい動作を強化します。
- プロキシルーティングルール : ドメインや場所に基づいて異なるプロキシにトラフィックを指向できるカスタムプロキシルーティング機能を導入します。セッション管理のためのセッションAPIも提供します。
2. デバッグとモニタリング
- ライブビュー : プレイグラウンドでリアルタイムビューを提供し、簡単なデバッグとタスクの引き継ぎを行えます。
- セッション管理 : セッションリプレイ、インスペクター、およびメタデータクエリをサポートし、タスクモニタリング機能を向上させます。
3. ファイルハンドリング
- アップロード : Playwright、Puppeteer、またはSeleniumを使用して、ターゲットウェブサイトにファイルを簡単にアップロードできます。
- ダウンロード : ダウンロードしたファイルは自動的にクラウドに保存され、ファイル名にUnixタイムスタンプが追加されます(例:sample-1719265797164.pdf)ので、競合を避けることができます。
- 取得 : ファイルはAPIを介して迅速に取得でき、データスクレイピングやレポート生成などのシナリオに適しています。
4. コンテキストAPIと拡張機能サポート
- コンテキストAPI : ログインやマルチステップ自動化シナリオを最適化するために、コンテキストセッションの持続性を導入します。
- 拡張機能サポート : 自分自身のChrome拡張機能を読み込むことで、ブラウザセッションを強化します。
5. メタデータクエリ
- カスタムタグを使用して、メタデータでセッションをクエリできます。
6. SDKとAPIのアップグレード
- セッションAPI : タスク操作を簡素化するためのセッション管理機能を提供します。
- CDPイベント最適化 : ページHTMLの取得、要素のクリック、スクロール、スクリーンショットの取得などの機能を含むCDPサポートを拡張します。
概要
現在のブラウザ自動化ツールは、AI駆動のシナリオを強化する際に多くの課題に直面しています:
- 高同時処理のボトルネックがタスク失敗を引き起こします。
- 不十分な人間らしい動作は、自動化を検出するための対スクレイピングメカニズムを容易にします。
- 高コストが大規模タスクの実行可能性を制限します。
- 複雑な統合は急な学習曲線を生み出し、非効率をもたらします。
Scrapeless Scraping Browserは、「AIのためのブラウザ」を3つの主要なイノベーションで再定義します:
- クラウドエラスティックスケーリング : 数十から無制限の同時セッションまでシームレスにスケーリングをサポートし、高スループットの可能性を完全に解放します。
- フルスタック人間らしい保護 : Chromiumカーネルの深いカスタマイズがフィンガープリンターの難読化、TLSハンドシェイク戦略、および進行的な行動シミュレーションを提供し、対スクレイピングの制限を容易に回避します。
- 比類のないコスト効率と互換性 : 他のソリューションと比較して60%〜80%のコスト削減を実現し、PlaywrightやPuppeteerとの互換性を維持し、開発のハードルを低くします。
私たちは、AIを中心とした次世代技術の探求にも積極的に取り組んでいます。開発者やチームから、私たちの製品に対する最適化の提案や機能リクエストをお寄せいただけることを心より歓迎します。あなたのフィードバックは非常に重要であり、Scrapeless Scraping Browserを継続的に改善し、さらに良い体験を提供する手助けとなります。
Scrapelessについてもっと知る
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


