
検索エンジンスクレイピング用SERP APIトップ6|究極のリスト2025
Specialist in Anti-Bot Strategies
2025年最高のSERPデータAPI6選
さまざまなSERPスクレイピングAPIを選択してテストする際には、次のテスト手順が各APIのパフォーマンス評価に役立ちます。
- クロール速度とレスポンスタイム
- ブロック回避テスト
- データ整合性テスト
- APIエラーと処理能力
- ユーザー負荷と同時処理能力
トップ1. Scrapeless

なぜScrapelessが最高のSERPスクレイピングツールなのか?少しバイアスがかかっていることは承知しています。しかし、Scrapelessは強みをもってより信頼性があります。
Scrapelessは無料版をサポートしています。 Discordに参加して利用しましょう!Scrapeless SERP APIは、検索エンジンからのデータ抽出プロセスを簡素化するために設計された革新的なソリューションです。当社の高度なスクレイピングAPIを使用すると、複雑なクロールスクリプトを作成または保守することなく、必要なデータにアクセスできます。シンプルなAPIコールで、貴重な情報にすぐにアクセスできます。
- 長所と短所
| 長所 | 短所 |
|---|---|
| Scrapelessは強力なブロック回避とフィンガープリンティング対策機能を備えています。 | 市場投入までの時間が短い |
| 高い同時クロール能力を提供し、リクエスト頻度とIP使用頻度をインテリジェントに調整できます | 各APIコールのコストは$0.001から始まり、大量のデータの場合は$0.0008未満になります |
ScrapelessはGoogle、Bing、Yahooなど、多くの主要なエンジンをクロールできます。また、専任サービスもサポートしており、お客様のニーズをお知らせください。
- ユースケース
Scrapelessは、特に検索エンジンのブロックをバイパスする必要があるタスクにおいて、困難で厳格な反クローラー対策が施されたウェブサイトのデータをクロールする必要があるユーザーに非常に適しています。すべてのSEO企業、市場調査機関、大量の競合データを取得する必要があるユーザーにとって理想的な選択肢です。
包括的なスクレイピングAPIツールをお探しですか?
Scrapelessを使用して、シームレスなスクレイピングエクスペリエンスをお楽しみください。
今すぐテスト!
トップ2. ZenSerp
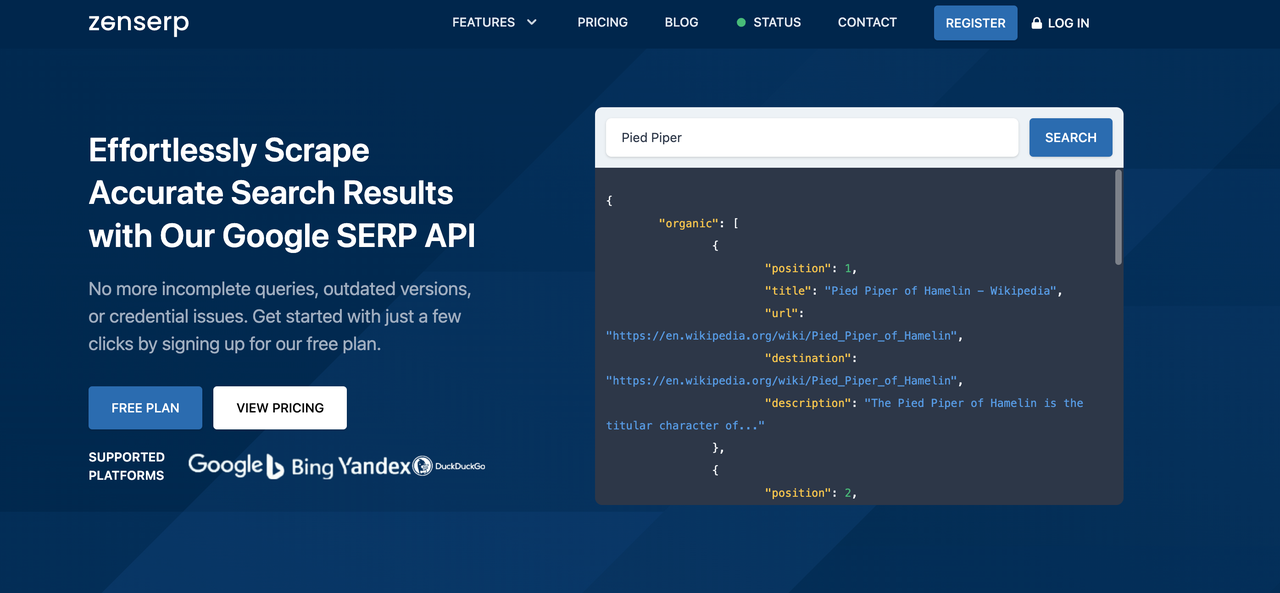
ZenSerpは、さまざまな検索エンジンからデータ収集を目的としたさまざまなAPIを提供するサービスです。このAPIの使用は非常に簡単で、ウェブサイトにはPlaygroundもあり、ウェブサイト上で直接APIリクエストを設定して実行できます。生成されたリクエストのコードも確認できますが、生成時にエラーが発生する場合があります。
- 長所と短所
| 長所 | 短所 |
|---|---|
| 検索結果にアクセスするためのAPIを提供します | その他のサービスと比較して無料トライアルが制限されており、包括的なテストに必要な十分なデータを提供できない場合があります |
| $49.99から利用可能な価格プラン | 生成されたコードにエラーが含まれている場合があり、特に初心者にとっては使用が困難または不可能になる可能性があります |
| 平均レスポンスタイム4.73秒と高速です |
- ユースケース
このSERPスクレイピングツールは、SEO分析、ランキング監視、大規模なクロールタスクに適しています。開発者や中規模企業が利用することを好みます。
トップ3. SerpWow
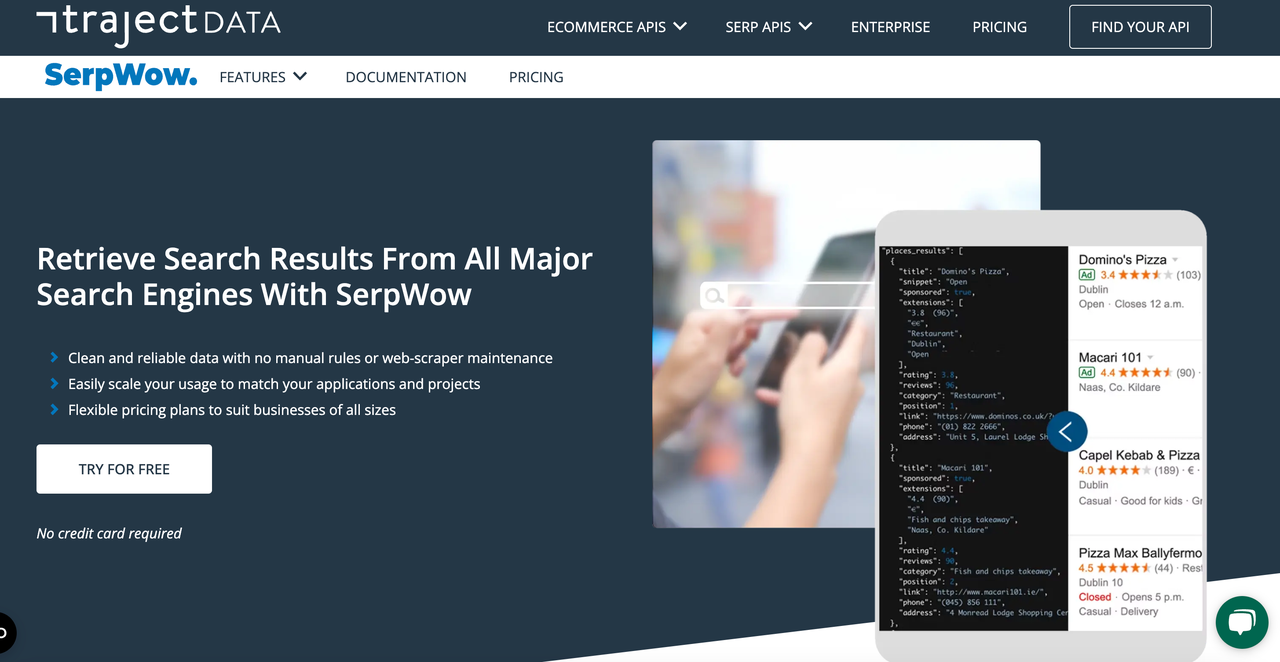
SerpWowは、リアルタイムで高精度な検索エンジン結果データをスクレイピングすることに重点を置いた、シンプルで使いやすいSERPスクレイピングAPIであり、安定したパフォーマンスと強力なスクレイピング機能を提供します。全体的に、このSERP APIの使用方法は他のほとんどのAPIと同様です。さらに、ウェブサイトには分かりやすいドキュメントと例が提供されています。
- 長所と短所
| 長所 | 短所 |
|---|---|
| トライアルでは100リクエストが許可されており、有料プランにコミットする前にサービスをテストする機会が提供されます。 | JSONレスポンスには、異種で冗長な非構造化データが含まれています。 |
| 最低料金プランは1,000リクエストあたり$25から始まります。 | 平均レスポンスタイムは12.08秒で、検討したサービスの中では中程度です。 |
- ユースケース
低レイテンシと高頻度のクロールを必要とするSEO監視やキーワードランキング分析に適しています。中小企業やSEO開発者が選択する場合があります。
トップ4. DataForSEO
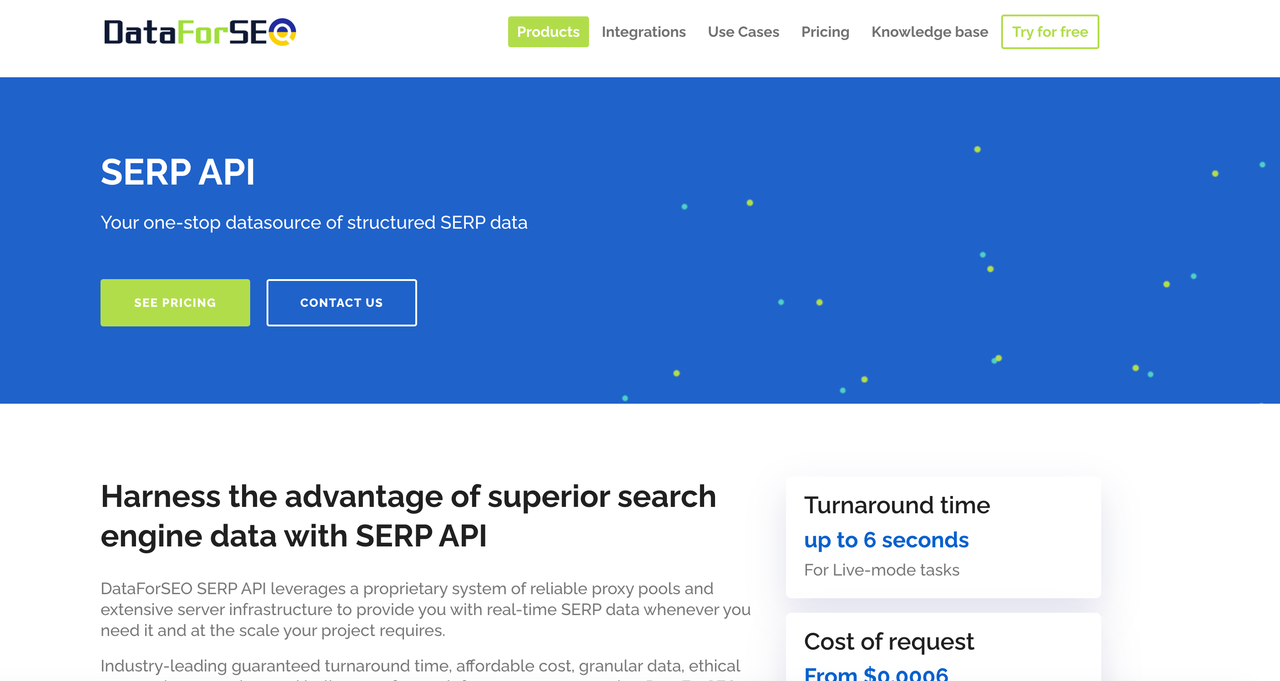
DataForSEO SERPスクレイパーAPIは、オーガニック検索結果と有料検索結果の両方を含むリアルタイムのSERPデータをJSON形式で取得します。Google SERPからデータをスクレイピングするためのAPIが含まれています。
このSERPスクレイピングツールのSERP APIは非常に便利です。APIキーではなく、ログインとパスワードに基づいて生成されたキーを介して提供されます。
- 長所と短所
残念ながら、多くの不要な情報が含まれています。このサービスの主な長所と短所を検討しましょう。
| 長所 | 短所 |
|---|---|
| 500リクエストのトライアルが利用可能 | 平均レスポンスタイムは6.75秒です |
| JSONレスポンス形式は便利です | JSONレスポンスに結果のセグメンテーションがありません |
| 包括的なデータ取得 | 企業以外のアクセスにはサポートへの連絡が必要です |
- ユースケース
高精度で大規模なSEOクロールを必要とするデータに適用できます。大企業やSEO企業、特にビッグデータサポートが必要な市場調査やSEO最適化タスクに適しています。
トップ5. HasData

HasDataは、データ抽出、ウェブ自動化、データ処理タスクを簡素化するツールとインフラストラクチャを提供するウェブスクレイピングおよび自動化プラットフォームです。Google SERP APIを含むさまざまな抽出APIを提供しています。ただし、テストによると、このAPIも最も遅いAPIの1つです。
- 長所と短所
| 長所 | 短所 |
|---|---|
| 低価格($29から) | 一部のあまり一般的ではないプログラミング言語をサポートしていません |
| ページスクリーンショットへのリンクを含むJSON形式のレスポンス | 組み込みの分析またはレポートツールがありません |
| 30日間の無料トライアル、200のGoogle SERPリクエストが許可されています | ドキュメントは煩雑で、生のAPI使用の明確な例が不足しており、多くの場合、そのライブラリに依存しています |
- ユースケース
このSERP APIは、中小企業や開発者が中規模の検索エンジンデータスクレイピングを実行するのに適しており、特にスクレイピングタスクの柔軟なカスタマイズを必要とするユーザーに適しています。
トップ6. Scrape-IT
Scrape ITは、シンプルで効率的なウェブデータクロールに焦点を当てたAPIです。複雑な機能を必要とせず、高効率のクロールを求めるユーザーに適しています。
- 長所と短所
| 長所 | 短所 |
|---|---|
| ドキュメントは非常に明確で、ほとんどすべての言語でコードスニペットが含まれています | 同時に複数のリクエストを行うと、APIのレスポンスが遅れることがあります |
| 平均レスポンスタイム5秒 | |
| GoogleとBingをサポートし、主流のSEOクロールタスクに適しています |
- ユースケース
Scrape ITは、JavaScriptレンダリングとブロック回避メカニズムに明確な利点があり、特に動的コンテンツのクロールに高い要求があるユーザーに適しています。
総合的な結論
| 属性 | 速度 | スケーラビリティ | ドキュメント | 安定性 | 価格 | 結論 |
|---|---|---|---|---|---|---|
| Scrapeless | 4.6 | 4.7 | 4.7 | 4.8 | 4.8 | 🌟🌟🌟🌟🌟 |
| ZenSerp | 4.8 | 4.8 | 4.6 | 4.7 | 4.6 | 🌟🌟🌟🌟 |
| SerpWow | 4.0 | 4.7 | 4.5 | 4.7 | 4.5 | 🌟🌟🌟🌟 |
| DataForSEO | 4.3 | 4.6 | 4.6 | 4.8 | 4.7 | 🌟🌟🌟 |
| HasData | 4.0 | 4.5 | 4.7 | 4.7 | 4.8 | 🌟🌟🌟 |
| Scrape It | 4.3 | 4.5 | 4.5 | 4.4 | 4.7 | 🌟🌟🌟 |
最高のSERP APIツール - Scrapeless:使用方法
正確で信頼性の高いGoogle SERPデータへのアクセスは常に困難です。そこでScrapeless SERP APIが登場します。これは、データ抽出作業を合理化するために設計された、強力で手頃な価格で非常に効率的なツールです。
当社の競争力のある価格にきっと驚かれることでしょう!1,000 URLあたりいくらですか?たったの$1です(購読してさらなる割引を受けましょう)!
なぜScrapeless SERP APIを選択する必要があるのか?
Scrapelessは、Googleの検索エンジン結果ページ(SERP)のスクレイピングの課題に対処するために特別に構築されています。高度な検知回避メカニズム、高速なパフォーマンス、そして非常に高い成功率により、Scrapelessは、中断やBANなしでデータ収集がスムーズに実行されるようにします。
キーワードランキングの追跡、競合他社の監視、市場調査の収集などを行う場合でも、Scrapelessは常に正確な結果を提供します。
- 費用対効果が高い: Scrapelessは、優れた価値を提供するように設計されています。
- 一貫したパフォーマンス: 実績のある実績により、Scrapelessは、高いワークロード下でも安定したAPIレスポンスを提供します。
- 驚異的な成功率: スクレイピングの失敗に別れを告げましょう。ScrapelessはGoogle SERPデータへの99.99%の成功率を約束します。
- スケーラブルなソリューション: Scrapelessを支える堅牢なインフラストラクチャのおかげで、数千のクエリを簡単に処理できます。
Scrapeless Google検索APIの使い方
ステップ1. Scrapelessダッシュボードにログインし、「Google検索API」に移動します。
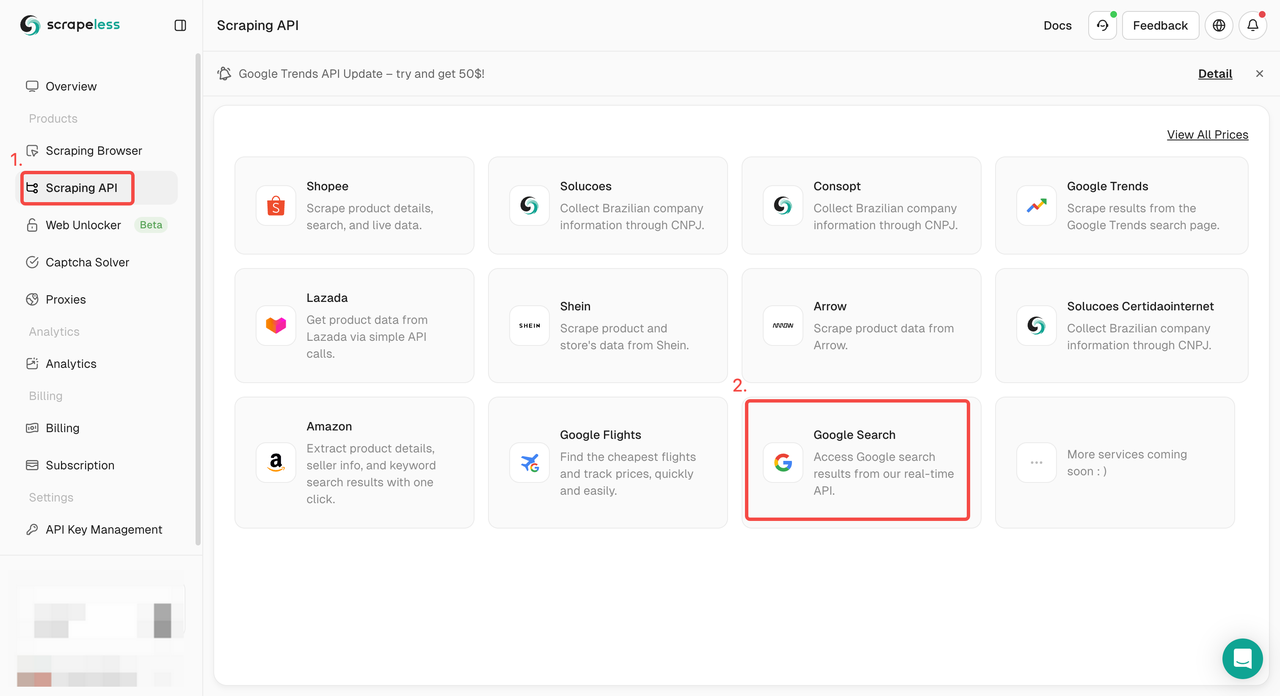
ステップ2. 左側で必要なキーワード、地域、言語、プロキシなどの情報を設定します。すべてが問題ないことを確認したら、「スクレイピング開始」をクリックします。
q:検索するクエリを定義するパラメーターです。gl:Google検索に使用する国を定義するパラメーターです。hl:Google検索に使用する言語を定義するパラメーターです。

ステップ3. クロール結果を取得してエクスポートします。
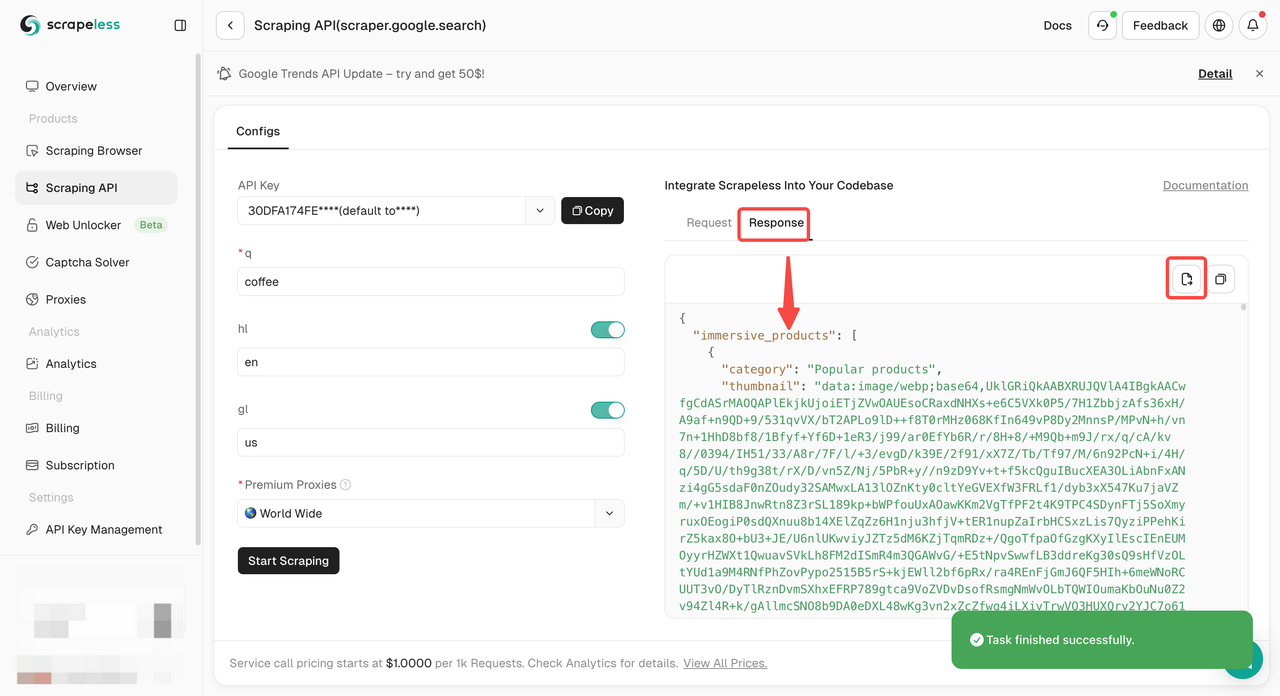
プロジェクトに統合するためのサンプルコードが必要ですか?ご安心ください!または、必要な言語のAPIドキュメントをご覧ください。
- Python:
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang:
go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}検索エンジンスクレイピングとは?
検索エンジンスクレイピング(SERPスクレイピングとも呼ばれます)とは、自動化された手段によって検索エンジン結果ページ(SERP)のデータを取得することです。通常、これには、検索エンジンによって返されるタイトル、説明、URL、ランキング、有料広告、画像、ビデオ、その他のタイプの検索結果が含まれます。このデータをスクレイピングすると、次のことが役立ちます。
- 競合他社のSEO戦略を監視する
- キーワードランキングと検索トレンドを分析する
- 市場調査とユーザー行動分析を行う
- 検索エンジン最適化(SEO)の提案を提供する
検索エンジンによってブロックまたは検知回避されないようにするには、通常、プロキシプール、IPローテーション、ブラウザフィンガープリントシミュレーションなどのテクノロジーを使用する必要があります。
ScrapelessはローテートプロキシとIPサービスと統合されています。
この特別なSERPデータAPIを今すぐ入手!
SERP APIによって抽出されるデータの種類
SERP APIは、検索エンジンから高品質の検索結果データをクロールして提供することに重点を置いています。ユーザーが詳細なSEO分析とランキング監視を行うために役立つ、次のタイプのデータを主に抽出します。
- 検索結果ランキングデータ
SerpデータAPIは、オーガニックランキング(自然検索結果)と有料広告(Google広告)の位置を含む、検索結果におけるキーワードの具体的なランキング順位を提供します。
- ウェブページのタイトルと説明
各検索結果のタイトルと説明をクロールすることは、SEO最適化にとって非常に重要であり、検索結果におけるページ構造とキーワード密度を分析するのに役立ちます。
- URLアドレス
各検索結果ページのURLを提供し、ユーザーはランキングページのSEOパフォーマンスと、それが競合他社のページであるかどうかを分析できます。
- 検索エンジンの機能
Serp APIは、「おすすめスニペット」、画像、ビデオ、ニュースクリップなど、検索エンジンの機能に関連するデータを抽出できます。このデータは、SEO戦略とコンテンツ最適化にとって重要です。
- SERP分析データ
SERP機能、検索意図分析、検索広告、画像/ビデオ検索結果などを含め、ユーザーは特定のキーワードの検索エンジンのパフォーマンスを完全に理解するのに役立ちます。
- ジオターゲティングデータ
Serp APIは、特定の地理的位置によるデータのクロールもサポートしており、異なる地域と言語環境での検索エンジンのランキングデータを取得できます。これは、グローバルまたはローカライズされたSEO分析に非常に適しています。
- 検索エンジン広告データ
検索エンジン広告のランキング、表示された広告コピー、広告主情報などを提供し、ユーザーは有料広告の効果を理解するのに役立ちます。
まとめ
このブログの6つのSERP APIは、さまざまな条件で役立ちます。
- BrightDataとOxylabs:大規模で需要の高いタスクでうまく機能します。
- Apify:小規模で柔軟なスクレイピングに最適です。
- Serp API:SEOデータスクレイピングに優れたツールです。
Scrapelessは最高のSERPデータAPIの選択肢です! 複雑な反クローラーメカニズムをバイパスする必要がある高度なユーザー、特に非常に高い反クローラー圧力に直面するスクレイピングタスクに適しています。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


