
Scrapelessを使ったGoogleショッピングからの商品詳細スクレイピング
Advanced Data Extraction Specialist
今日の激しい競争が繰り広げられるグローバルビジネス環境において、ウェブスクレイピング技術は、eコマース企業や小売業者が市場競争力を維持するための中核的な推進力となっています。世界中の数千ものターゲットデータソースから正確な公開データをインテリジェントエージェントネットワークを通じて収集することにより、企業は動的な価格モデルを構築し、在庫管理を最適化し、消費者行動トレンドに関する洞察を得て、最終的にはエンドユーザーに最も競争力のある製品価格システムを提供できます。
このガイドでは、専門ツールを使用してGoogleショッピングプラットフォーム上の公開製品データを合法的に取得する方法を体系的に説明します。データパイプラインの構築を目指す技術チームであっても、市場インテリジェンスサポートを求めるビジネス意思決定者であっても、この資料は実践的かつ戦略的な価値を持つ行動フレームワークを提供します。
Googleショッピングとは?
Googleショッピング(旧称:Google商品検索、Google商品、Froogle)は、ユーザーが幅広い有料サプライヤーから製品を閲覧、比較、購入できるショッピングプラットフォームです。多くのブランドから簡単に好みの製品を選択できるだけでなく、小売業者にも効率的なオンラインプロモーションチャネルを提供します。ユーザーが製品リンクをクリックすると、サプライヤーのウェブサイトに直接誘導されて購入を完了するため、Googleショッピングは企業が製品露出を増やし、売上を促進するための強力なツールとなります。
Googleショッピングの検索結果ページ構造の概要
Googleショッピングを閲覧する際に取得されるデータは、検索、製品、価格の3つの主要な入力パラメーターに依存します。各パラメーターの概要を以下に示します。
- 検索:Googleショッピングの商品リストには、ID、タイトル、説明、価格、在庫状況など、各商品に関する詳細情報が含まれています。
- 製品:他の小売業者での販売状況や製品価格など、単一製品に関する詳細情報を表示します。
- 価格:すべての小売業者からの製品価格と、送料の詳細、総額、小売業者名などの追加情報を表示します。
検索結果ページ
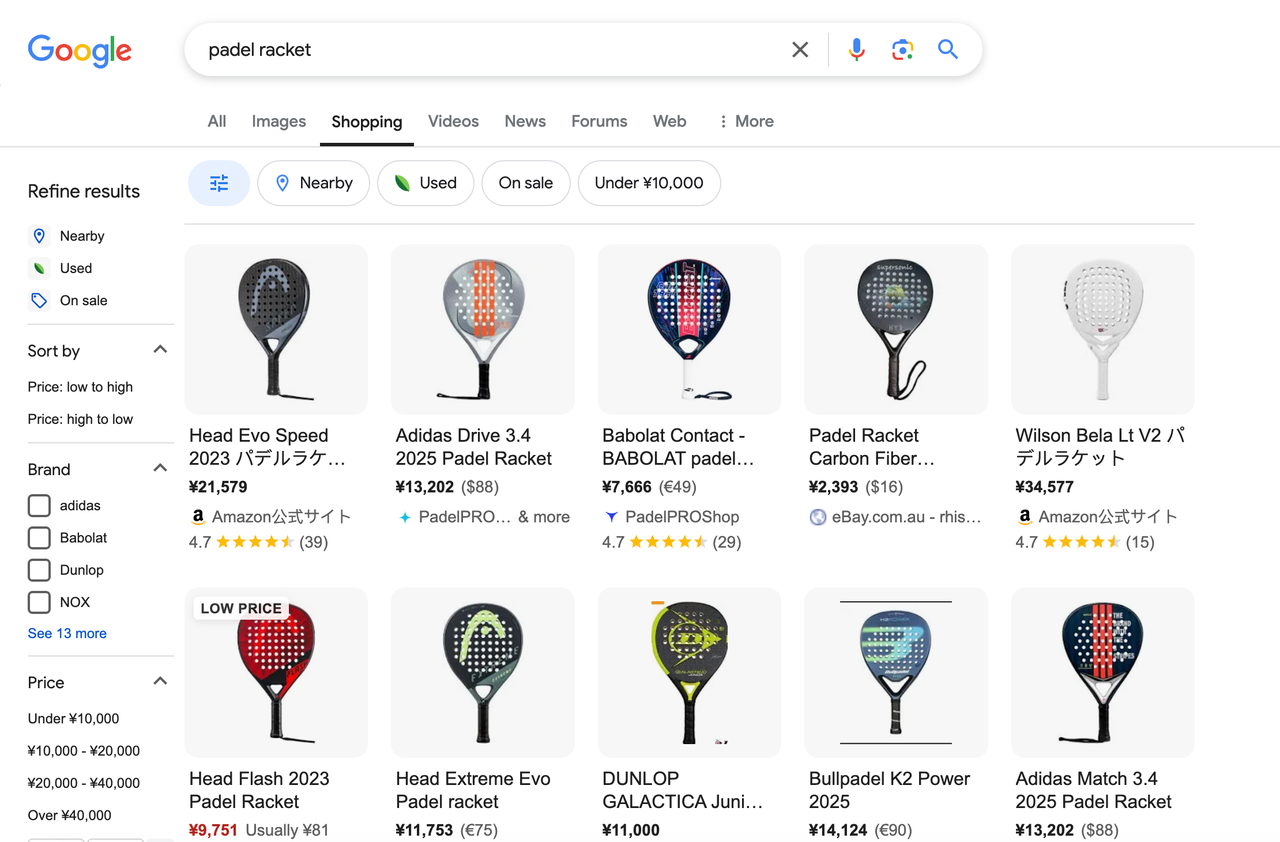
Googleショッピングの検索結果ページには、ユーザーのクエリに関連するすべての製品が表示されます。「パドルラケット」を検索すると、ページには次の要素が表示されます。
- 検索バー:ユーザーはキーワードを入力して商品を検索できます。
- 商品リスト:検索結果のすべての商品に関する詳細情報を表示します。
- フィルター:価格範囲、色、スタイルなどで商品を絞り込むことができます。
- 並べ替えオプション:価格の昇順/降順、人気など、属性で結果を並べ替えることができます。
商品ページ
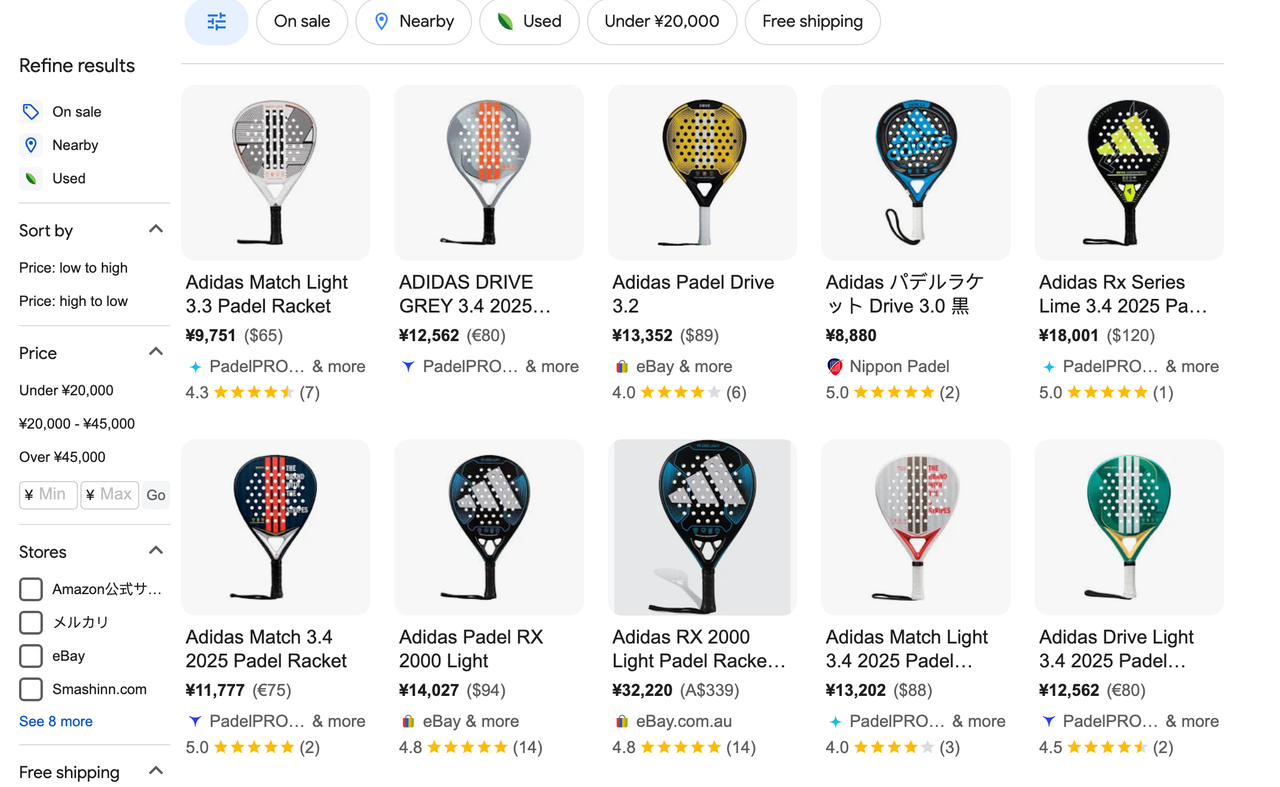
検索結果ページから商品をクリックすると、ユーザーは商品ページに誘導されます。商品ページには次の情報が含まれています。
- 商品名:製品の名前。
- 商品のハイライト:製品の主要機能の概要。
- 商品の詳細:製品の詳細な説明。
- 価格情報:さまざまな小売業者によって提供される価格。
- 商品レビュー:製品の評価と顧客レビューを表示します。
- 価格範囲:さまざまな販売者からの最低販売価格と最高販売価格を表示します。
- 一般仕様:製品の基本的なパラメーターを提供します。
価格ページ
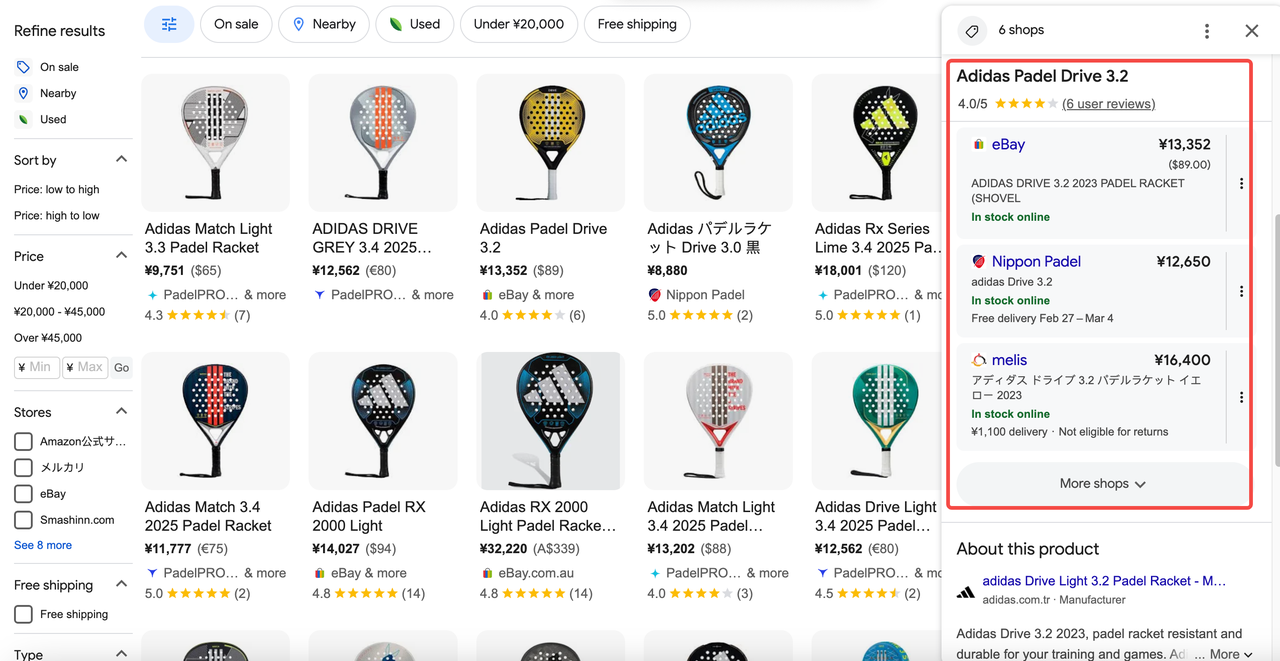
価格ページは、さまざまな小売業者からの製品価格を集約し、小売業者の評判やGoogle保証を提供しているかどうかなどの情報を表示します。このページには次の情報が含まれています。
- 商品名:検索した製品の名前。
- 評価:製品の全体的な評価とレビューの数。
- ストア別の価格:小売業者のオファー、取引、購入リンクを一覧表示します。
- フィルター:小売業者リストに適用できるフィルター。
Googleショッピングの結果をスクレイピングすることは合法ですか?
データのスクレイピングは、いくつかのケースで合法とみなされます。
- 公正使用:一部の法域では、公正使用により、研究、教育、非営利目的などの目的で限定的なデータスクレイピングが許可されています。
- 公開データ:スクレイピングするデータが公開データ(Googleショッピングの商品価格や説明など)である場合、このデータのスクレイピングは問題ないと思われます。
Pythonを使用したGoogleショッピング結果のスクレイピング方法[完全ガイド]
この包括的なガイドでは、Pythonを使用してGoogleショッピングの結果をスクレイピングするプロセスについて説明します。製品の詳細、価格、レビューを収集する場合でも、このチュートリアルでは、スクレイピング環境のセットアップとデータの効率的な収集を開始するための手順を説明します。強力なScrapeless GoogleショッピングAPIを活用してプロセスを簡素化することで、複雑なスクレイピングロジックや法的問題を心配することなく、プロジェクトの構築に集中できます。
[Scrapeless APIの技術的利点]
- 組み込みの反クローラーエンジン(Cloudflare/recaptcha v3をサポート)
- 動的にレンダリングされたコンテンツの自動処理
- 迅速な統合と分析のための標準化されたデータフィールドを提供
- 高い同時クロールとIPブロッキングの回避を保証する効率的なIPプロキシプール
- 最新のGoogleショッピング情報を取得するためのリアルタイムデータ更新
- グローバルプロキシネットワーク、マルチリージョンデータクロールをサポートし、さまざまな市場の製品情報の網羅性を確保
- 高いスケーラビリティ、大規模なデータクロールニーズに対応し、エンタープライズレベルのアプリケーションに適しています
ステップ1:Pythonをセットアップし、必要なライブラリをインストールする
まず、データクロール環境を構築し、次のツールを用意する必要があります。
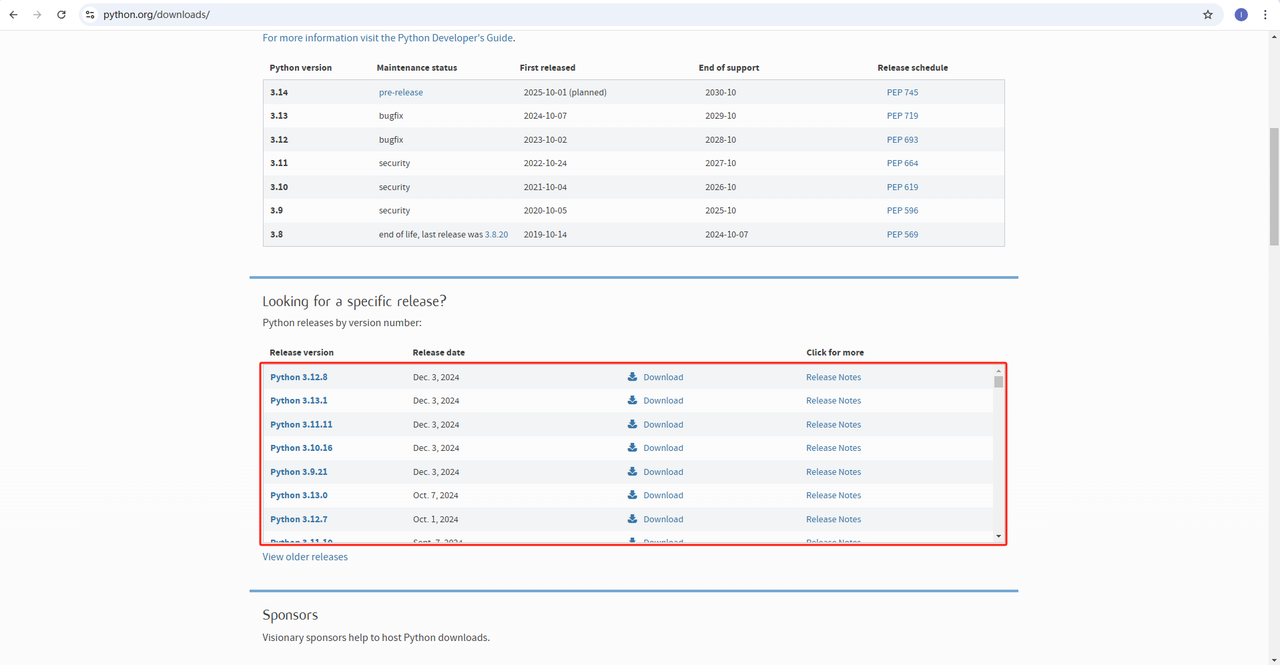
- Python:こちらは、Pythonを実行するためのコアソフトウェアです。下の図に示す公式ウェブサイトのリンクから必要なバージョンをダウンロードできますが、最新バージョンをダウンロードしないことをお勧めします。最新バージョンより1~2バージョン前のバージョンをダウンロードできます。
- Python IDE:PythonをサポートするIDEであればどれでも構いませんが、Python用に特別に設計されたIDE開発ツールソフトウェアであるPyCharmをお勧めします。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
- Pip:Python Package Indexを使用して、プログラムの実行に必要なライブラリを単一のコマンドでインストールできます。
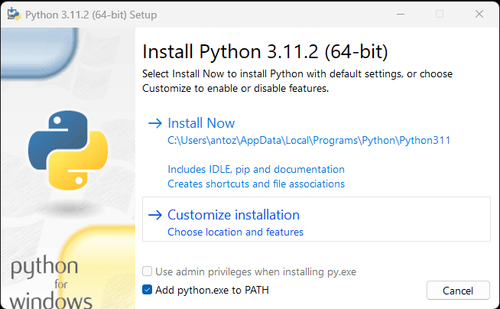
注:Windowsユーザーの場合、インストールウィザードで「python.exeをPATHに追加」オプションを選択することを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
上記の手順により、Googleショッピングデータのクロール環境が設定されます。次に、ダウンロードしたPyCharmとScraperlessを組み合わせてGoogleショッピングデータをクロールできます。
ステップ2:PyCharmとScrapelessを使用してGoogleショッピングデータをスクレイピングする
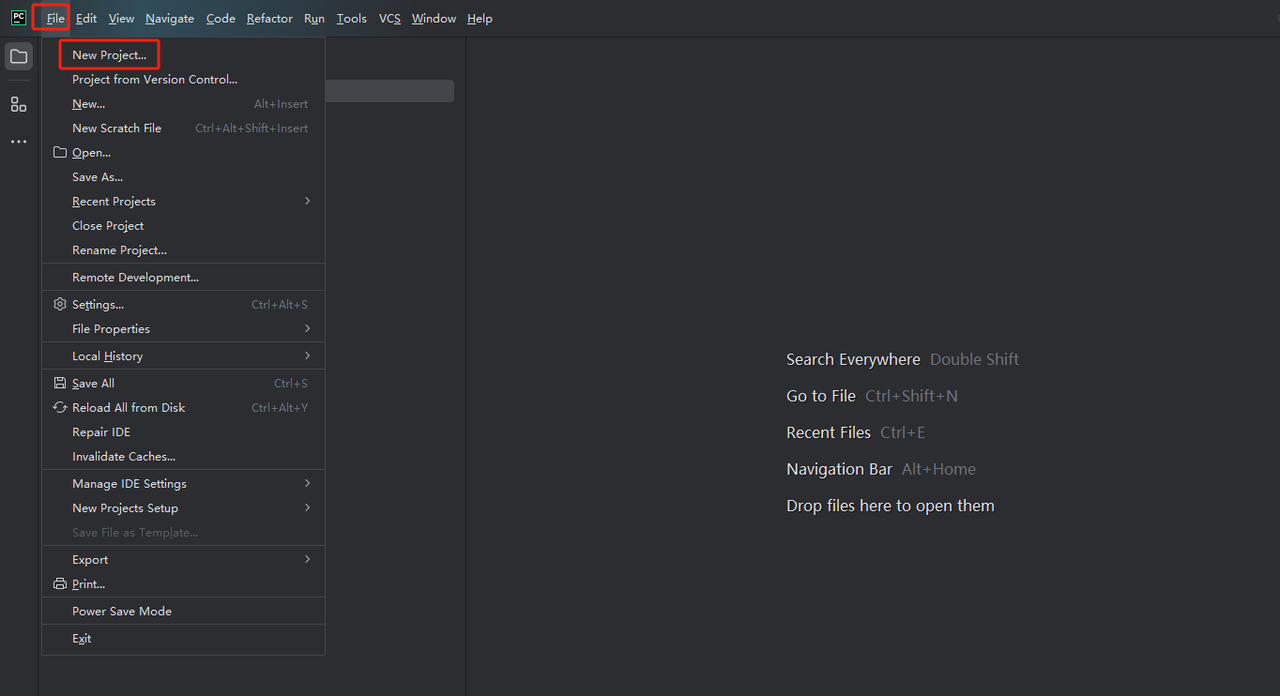
- PyCharmを起動し、メニューバーからファイル>新規プロジェクト…を選択します。
- 次に、表示されるウィンドウで、左側のメニューからPure Pythonを選択し、プロジェクトを次のように設定します。
注:下の赤いボックスで、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択します。
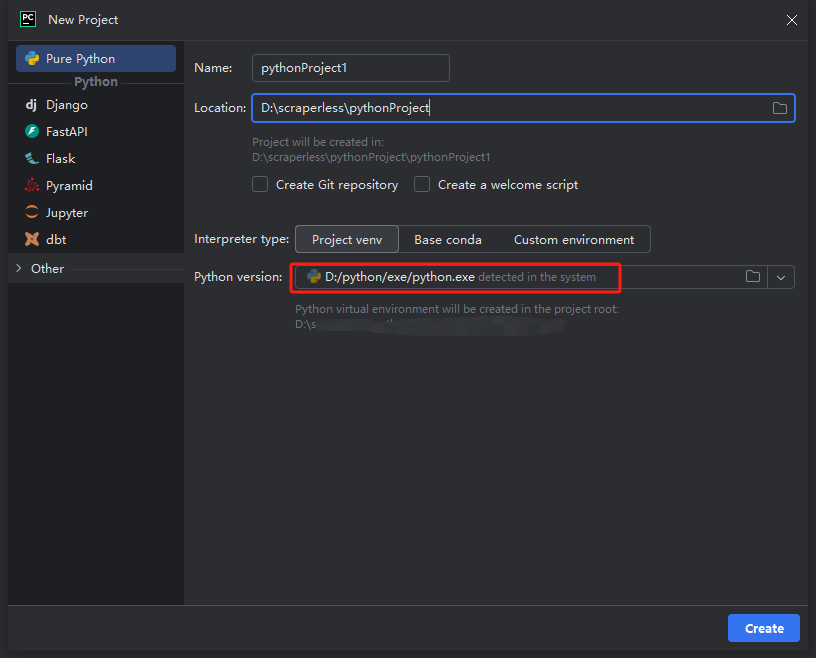
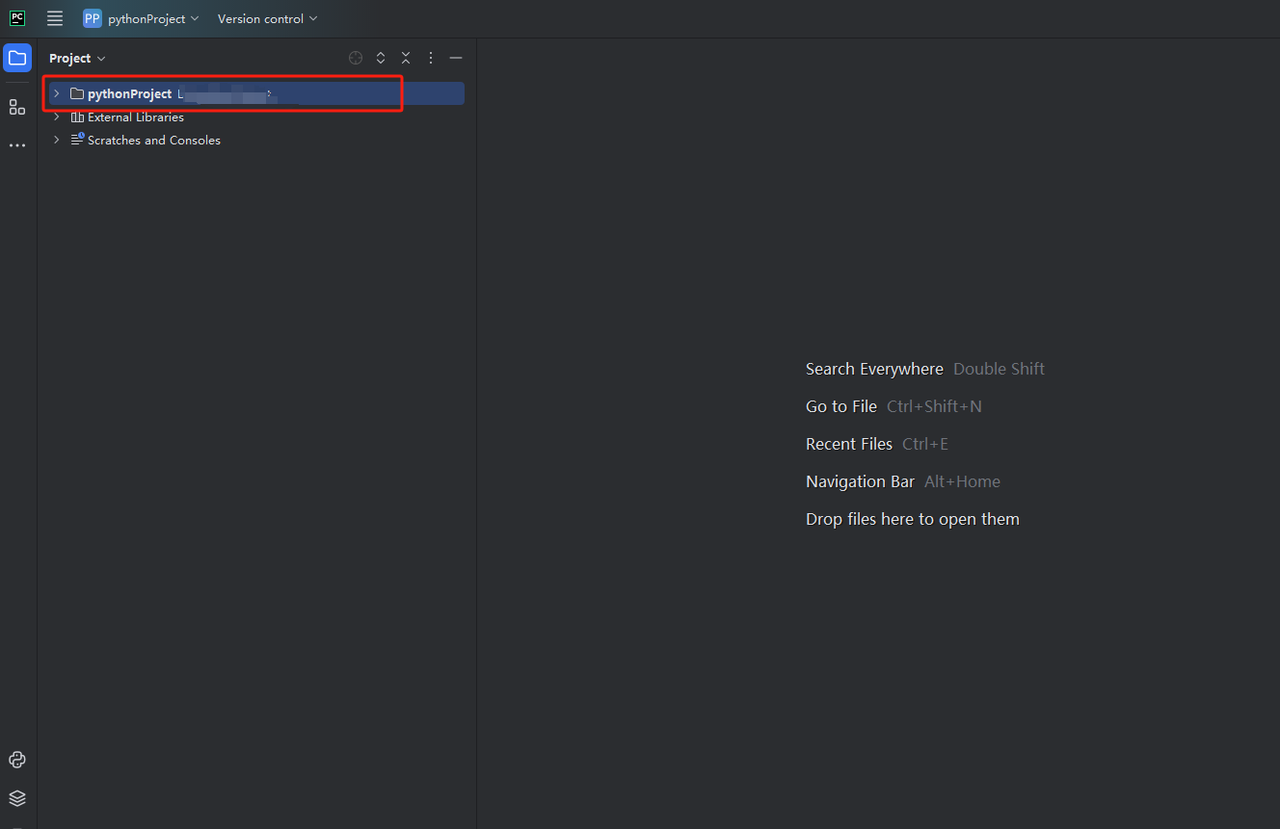
- python-scraperという名前のプロジェクトを作成し、「フォルダ内の「Create main.py welcome script」オプションを選択し、「作成」ボタンをクリックします。PyCharmがしばらくプロジェクトを設定した後、次のようになります。
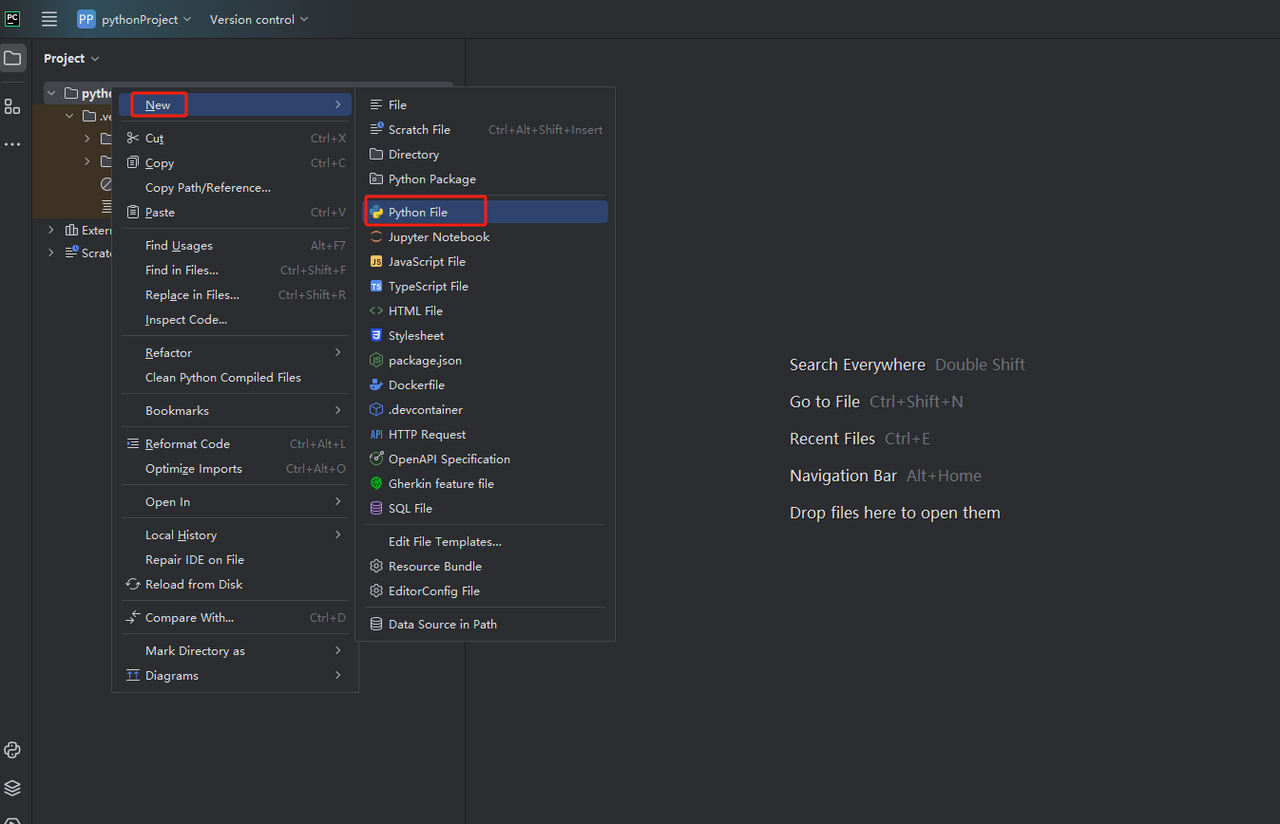
- 次に、右クリックして新しいPythonファイルを作成します。
- すべてが正しく機能していることを確認するために、画面下部のターミナルタブを開き、「python main.py」と入力します。このコマンドを実行すると、「こんにちは、PyCharm」が表示されます。
ステップ3:ScrapelessにサインアップしてAPIキーを取得する
これで、ScrapelessのコードをPyCharmに直接コピーして実行できるため、GoogleショッピングのJSON形式のデータを取得できます。ただし、最初にScrapeless APIキーを取得する必要があります。
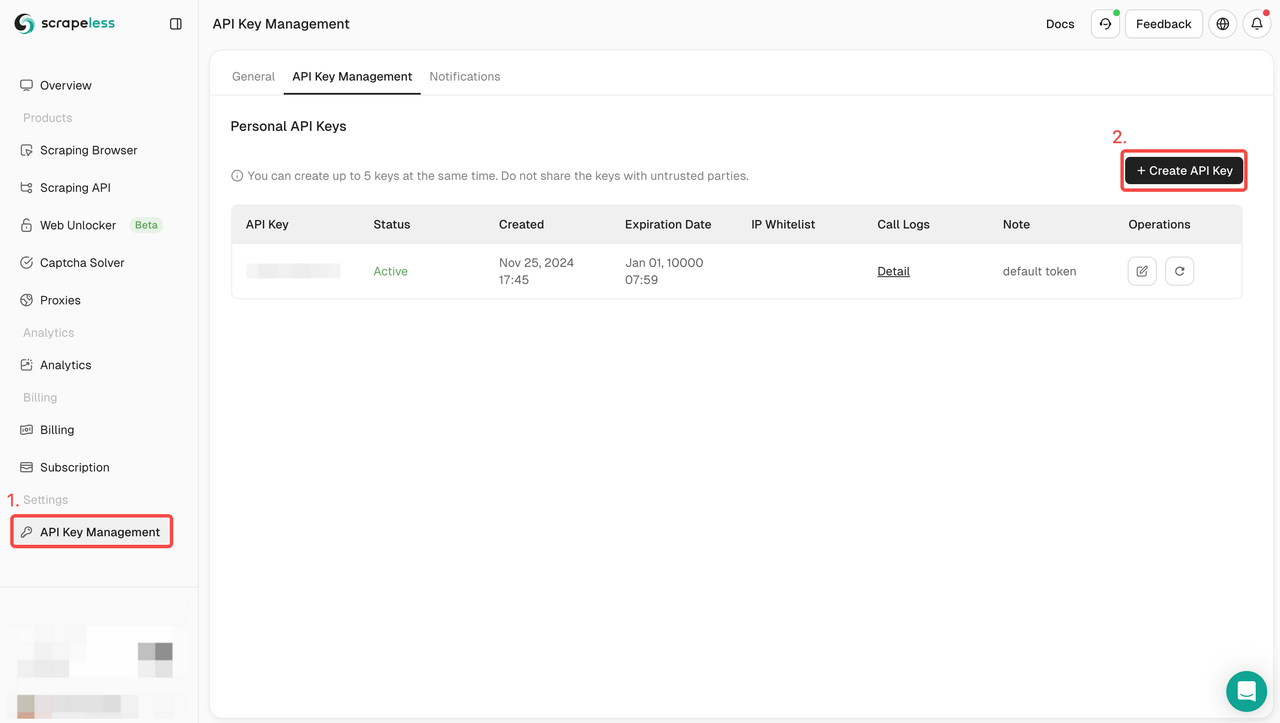
- まだアカウントを持っていない場合は、Scrapelessにサインアップしてください。サインアップ後、ダッシュボードにログインします。
- Scrapelessダッシュボードで、APIキー管理に移動し、「APIキーの作成」をクリックします。APIキーを取得します。マウスを置いてクリックしてコピーします。このキーは、Scrapeless APIを呼び出す際の要求の認証に使用されます。
ステップ4:Scrapeless GoogleショッピングAPIパラメーターを理解する
| パラメーター | 必須 | 説明 |
|---|---|---|
| engine | TRUE | GoogleショッピングAPIエンジンを使用するには、パラメーターをgoogle_shoppingに設定します。 |
| q | TRUE | パラメーターは、検索するクエリを定義します。通常のGoogleショッピング検索で使用するものなら何でも使用できます。 |
| location | FALSE | パラメーターは、検索を開始する場所を定義します。要求された場所と一致する場所が複数ある場合、最も一般的な場所が選択されます。locationパラメーターとuuleパラメーターは同時に使用できません。市レベルで場所を指定することをお勧めします。 |
| uule | FALSE | パラメーターは、検索に使用するGoogleでエンコードされた場所です。uuleパラメーターとlocationパラメーターは同時に使用できません。 |
| gl | FALSE | パラメーターは、Google検索に使用する国を定義します。2文字の国コードです(例:米国はus、英国はuk、フランスはfr)。デフォルトはusです。 |
| hl | FALSE | パラメーターは、Googleマップ検索に使用する言語を定義します。2文字の言語コードです(例:英語はen、スペイン語はes、フランス語はfr)。デフォルトはenです。 |
| tbs | FALSE | (検索対象)パラメーターは、通常のクエリフィールドでは不可能な高度な検索パラメーターを定義します。 |
| direct_link | FALSE | パラメーターは、検索結果に各製品への直接リンクを含めるかどうかを決定します。デフォルトではfalseです。直接リンクが必要な場合は、trueに設定します。このパラメーターは新しいレイアウト(米国および一部の国)にのみ適用されます。 |
| start | FALSE | パラメーターは結果のオフセットを定義します。指定された数の結果をスキップします。ページングに使用されます(例:0(デフォルト)は結果の最初のページ、60は結果の2ページ目、120は結果の3ページ目など)。新しいレイアウトでは、パラメーターは推奨されません。 |
| num | FALSE | パラメーターは、返す結果の最大数を定義します(例:60(デフォルト)は60個の結果を返し、40は40個の結果を返し、100(最大)は100個の結果を返します)。100を超える数は100に、1未満の数は60になります。 |
ステップ5:スクレイピングツールにScrapeless APIを統合する方法
APIキーを取得したら、独自のスクレイピングツールにScrapeless APIを統合できます。Pythonとrequestsを使用してScrapeless APIを呼び出してデータを取得する方法の例を以下に示します。
コード統合例:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_shopping",
"q": "Macbook M3"
}
payload = Payload("scraper.google.shopping", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()「your_token」をScrapeless API KEYに置き換えます。上記のAPIパラメーター情報に従って、スクレイピングコードをカスタマイズすることもできます。
ステップ6:結果データの分析
Scrapeless APIの結果データには、JSON形式の詳細情報が含まれています。以下は結果データの一部例であり、具体的な情報はAPIドキュメントで確認できます。
データスクレイピングのためのその他のeコマースAPIについて
Googleショッピングから製品データをクロールすることに加えて、他のeコマースプラットフォームを通じて市場トレンドを収集および分析して、さまざまなプラットフォームでの製品パフォーマンス、価格変動、売上トレンドを理解することもできます。
- Amazon API:Amazon APIを使用すると、価格、レビュー、在庫を理解するためにAmazonの製品データを効率的にクロールできます。
- Shopee API:Shopeeプラットフォームから製品データを取得し、東南アジア市場における製品需要を深く理解します。
- Shein API:Shein APIを通じて、グローバルファストファッション業界のデータを分析し、消費者の好みとトレンドを理解します。
ビジネスでこれらのeコマースプラットフォームからデータをクロールする必要がある場合、または同様のニーズがある場合は、APIインターフェースが強力なデータクロール機能を提供し、複数のeコマースプラットフォームから簡単に製品データを取得できます。カスタマイズされたソリューションが必要な場合は、営業チームに直接お問い合わせください。お客様の具体的なニーズに基づいて最高のサービスを提供します。
今すぐScrapeless Discordコミュニティに参加しましょう!🎉 Scrapelessの無料トライアルに独占的にアクセスできます。見逃さないでください—リンクをクリックしてください。期間限定のオファーです!
Scrapeless Deep SerpApi:強力なGoogle SERP APIツール
Deep SerpApiは、大規模言語モデル(LLM)とAIエージェント向けに特別に設計された特殊な検索エンジンAPIです。リアルタイム、正確で偏りのない情報を提供し、AIアプリケーションがGoogleなどのデータの取得と処理を効率的に行えるようにします。
✅包括的なデータカバレッジインターフェース:20以上のGoogle SERPシナリオと主流の検索エンジンを網羅。
✅費用対効果:Deep SerpApiは、クエリ1000件あたり0.10ドルからの価格を提供し、応答時間は1〜2秒です。開発者と企業は、効率的かつ低コストでデータを取得できます。
✅高度なデータ統合機能:利用可能なすべてのオンラインチャネルと検索エンジンからの情報を統合できます。
✅24時間以内に更新されたデータでリアルタイムの更新を取得します。
今後のロードマップの一部として、動的なWeb情報をAI駆動型ソリューションにシームレスに統合することを簡素化することにより、AI開発者のニーズを満たすことに全力を注いでいます。目標は、単一の呼び出しでシームレスな検索とデータ抽出を可能にするオールインワンAPIを提供することです。
🎺🎺エキサイティングな発表!
開発者サポートプログラム:Scrapeless Deep SerpApiをあなたのAIツール、アプリケーション、またはプロジェクトに統合してください。[既にDifyをサポートしており、まもなくLangchain、Langflow、FlowiseAI、その他のフレームワークをサポートする予定です]。次に、結果をGitHubまたはソーシャルメディアで共有すると、月額最大500ドルまで、1〜12か月の無料開発者サポートを受けられます。
まとめ
要約すると、Scrapelessを使用してGoogleショッピングの結果をスクレイピングすると、分析、製品調査、比較のための貴重なデータを収集する効果的な方法が提供されます。この記事で概説されている手順に従うことで、必要なツールを簡単にセットアップし、Scrapeless APIをワークフローに統合し、コンプライアントで効率的な方法で関連情報を抽出できます。開発者であっても、Googleショッピングデータを活用したいビジネスオーナーであっても、プロセスはシンプルでスケーラブルです。ウェブスクレイピングに関する法的および倫理的なガイドラインを常に遵守してください。
FAQ
Q1:ページごとの結果数を調整するにはどうすればよいですか?
ページごとに返される結果数を調整するには、limitパラメーターを使用します。たとえば、「limit」:20に設定すると、要求ごとに20個の結果が返されます。
Q2:他のページをクロールするにはどうすればよいですか?
pageパラメーターを使用して他のページをクロールします。たとえば、「page」:2は、2ページ目の結果を返します。
Q3:複数の場所からデータをクロールできますか?
はい、locationパラメーターを使用して国または地域を指定できます。たとえば、「location」:「UK」は、英国のGoogleショッピングの結果をクロールします。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


