
Go言語によるWebクローラー:ステップバイステップチュートリアル2025
Senior Web Scraping Engineer
Go言語による大規模なウェブスクレイピングプロジェクトの多くは、Golangウェブクローラーを使用してURLの発見と整理から始まります。このツールを使用すると、最初のターゲットドメイン(「シードURL」とも呼ばれる)をナビゲーションし、ページ上のリンクを再帰的に訪問して、さらに多くのリンクを発見できます。
このガイドでは、実例を使用してGolangウェブクローラーを構築および最適化する方法を学習します。また、始める前に、いくつかの役立つ補足情報も提供します。
では、早速今日の楽しい内容を見てみましょう!
ウェブクロールとは?
ウェブクロールは、本質的に、有用なデータを抽出するためにウェブサイトを体系的にナビゲーションすることを伴います。ウェブクローラー(しばしばスパイダーと呼ばれる)はウェブページを取得し、そのコンテンツを解析し、インデックス作成やデータ集約などの特定の目標を達成するために情報を処理します。詳しく見ていきましょう。
ウェブクローラーはHTTPリクエストを送信してサーバーからウェブページを取得し、レスポンスを処理します。クローラーとウェブサイトの間の丁寧なハンドシェイクのように考えてください。「こんにちは、データを少し使ってもよろしいでしょうか?」
ページが取得されると、クローラーはHTMLを解析して関連データを抽出します。DOM構造はページを管理しやすいチャンクに分割するのに役立ち、CSSセレクターは必要な要素を正確に摘み取る精密なピンセットのように機能します。
ほとんどのウェブサイトはデータを複数のページに分散しています。クローラーは、ステロイドを摂取したデータ飢餓ボットのように見えないようにレート制限を尊重しながら、このページネーションの迷路をナビゲーションする必要があります。
2025年におけるウェブクロールにGolangが最適な理由
ウェブクロールがレースだとしたら、Golangはガレージに置きたいスポーツカーです。その独自の機能により、最新のウェブクローラーのための最適な言語となっています。
- 並行処理: Golangのゴルーチンを使用すると、複数のリクエストを同時に実行でき、「並列処理」と言うよりも速くデータをスクレイピングできます。
- シンプルさ: この言語のクリーンな構文とミニマリストな設計により、複雑なクロールプロジェクトに取り組む場合でも、コードベースを管理しやすくなります。
- パフォーマンス: Golangはコンパイルされるため、非常に高速に実行されます。大規模なウェブクロールタスクを苦労せずに処理するのに最適です。
- 堅牢な標準ライブラリ: HTTPリクエスト、JSON解析などを組み込みでサポートしているGolangの標準ライブラリは、スクラッパーをゼロから構築するために必要なものをすべて提供します。
ぎこちないツールで苦労するのではなく、カフェインを摂取したゴファーのようにデータを駆け巡りましょう。Golangは速度、シンプルさ、パワーを組み合わせ、ウェブを効率的かつ効果的にクロールするための究極の選択肢となっています。
ウェブサイトのクロールは合法ですか?
ウェブクロールの合法性は、一概に言えません。どのように、どこで、なぜクロールするかによります。公開データのスクレイピングは一般的に許容されますが、利用規約に違反したり、アンチスクレイピング対策を回避したりすると、法的トラブルにつながる可能性があります。
法律に従うためには、いくつかの黄金律があります。
- robots.txt のディレクティブを尊重する。
- 機密情報または制限された情報のスクレイピングを避ける。
- ウェブサイトのポリシーについて不明な点がある場合は、許可を求める。
最初のGolangウェブクローラーを構築する方法?
事前準備
- 最新バージョンのGoがインストールされていることを確認してください。公式のGolangウェブサイトからインストールパッケージをダウンロードし、指示に従ってインストールしてください。
- 好みのIDEを選択してください。このチュートリアルでは、Golandをエディターとして使用します。
- 快適に使用できるGoウェブスクレイピングライブラリを選択してください。この例では、chromedpを使用します。
Goのインストールを確認するには、ターミナルで次のコマンドを入力します。
PowerShell
go versionインストールが成功すると、次の結果が表示されます。
PowerShell
go version go1.23.4 windows/amd64作業ディレクトリを作成し、内部で次のコマンドを入力します。
go modを初期化します。
PowerShell
go mod init crawlchromedp依存関係をインストールします。
PowerShell
go get github.com/chromedp/chromedpcrawl.goファイルを作成します。
これで、ウェブスクレイパーコードの記述を開始できます。
ページ要素の取得
Lazadaにアクセスし、ブラウザの開発者ツール(F12)を使用して、必要なページ要素とセレクターを簡単に特定します。
- 入力フィールドとその横にある検索ボタンを取得します。
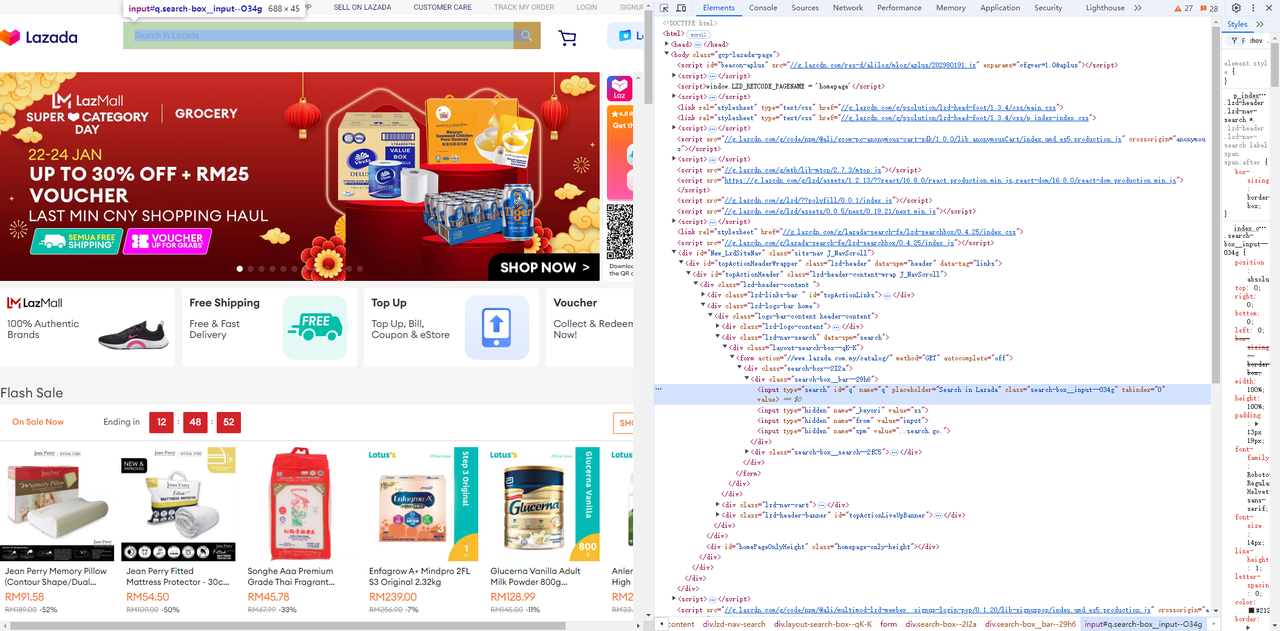
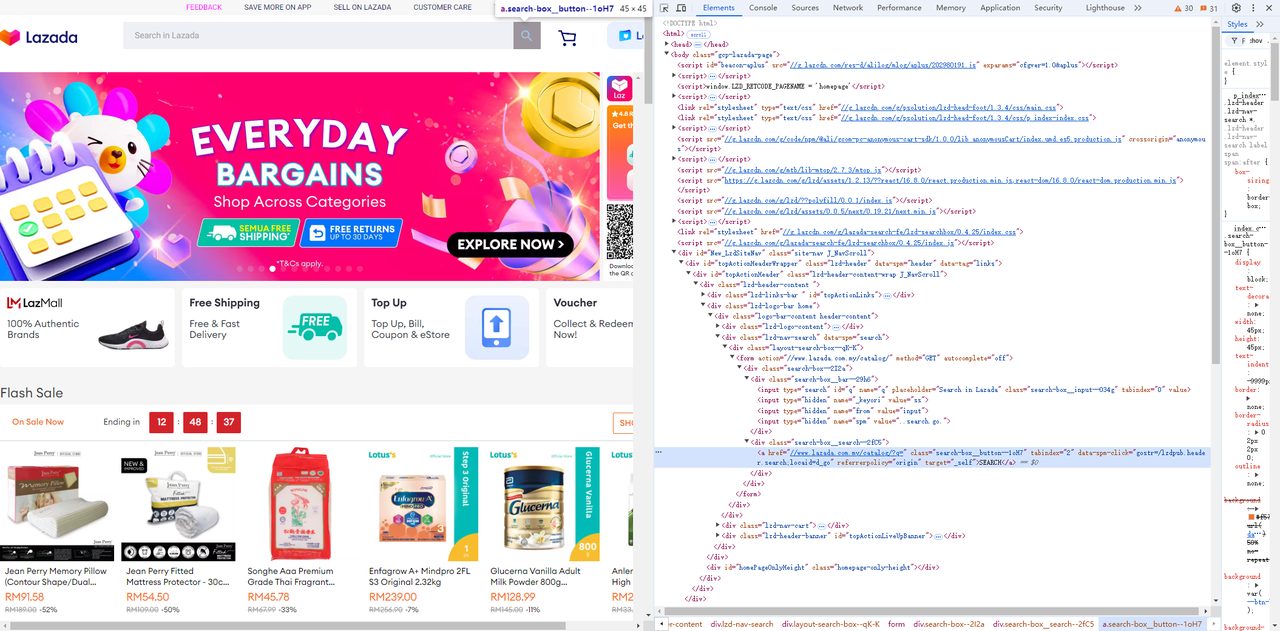
Go
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// 入力要素が表示されるのを待つ
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// 検索する商品を入力する。
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// 検索をクリックする
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}- 商品リストから価格、タイトル、画像要素を取得します。
-
商品リスト
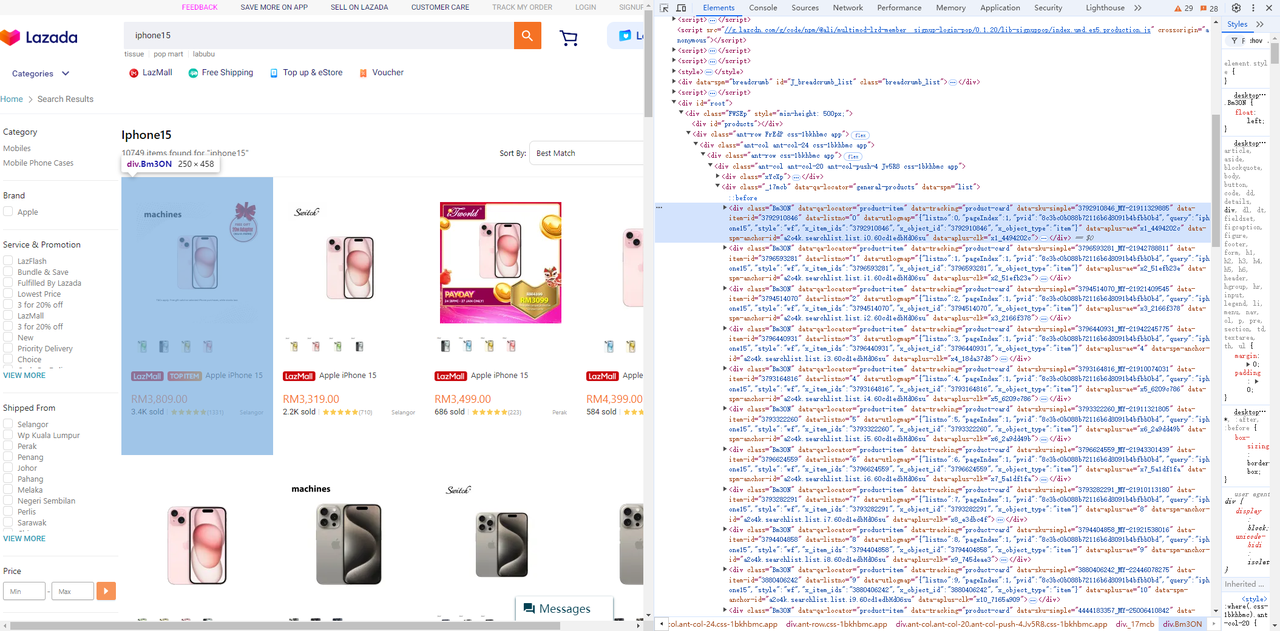
-
画像要素
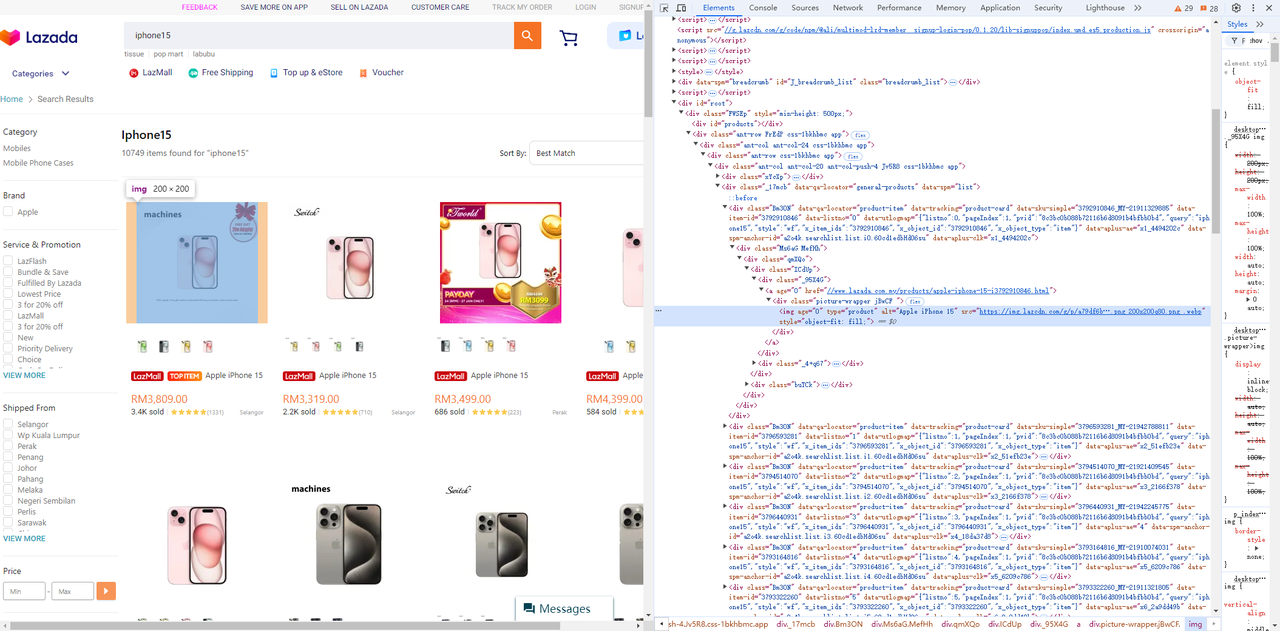
-
タイトル要素
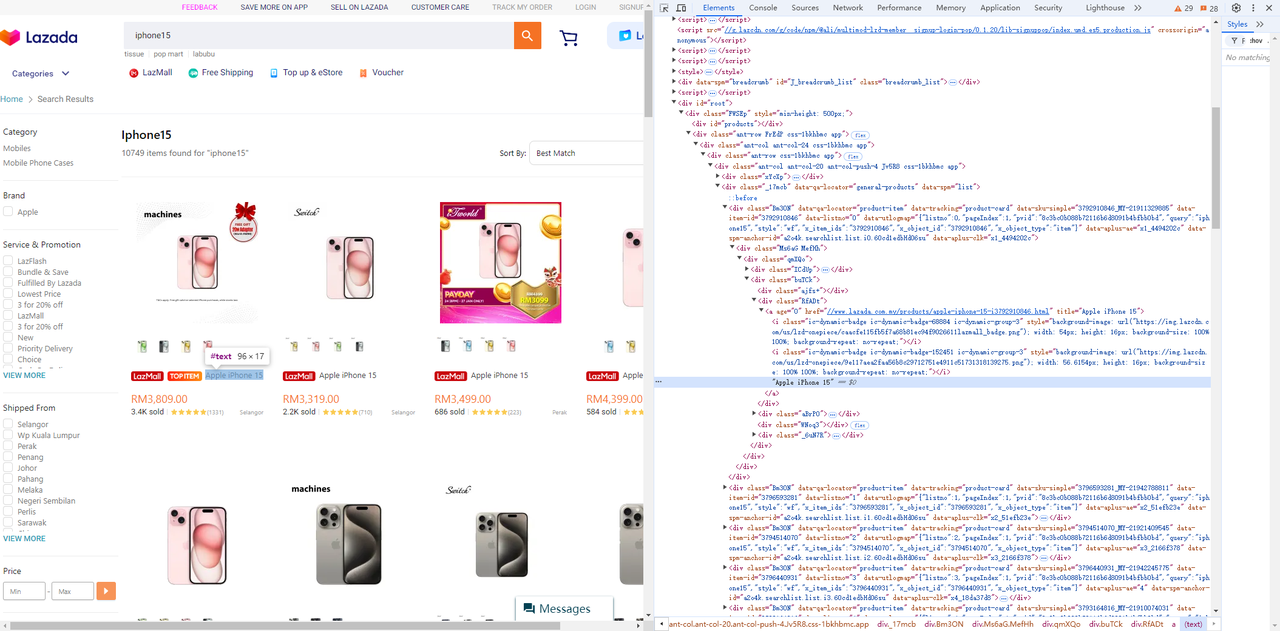
-
価格要素
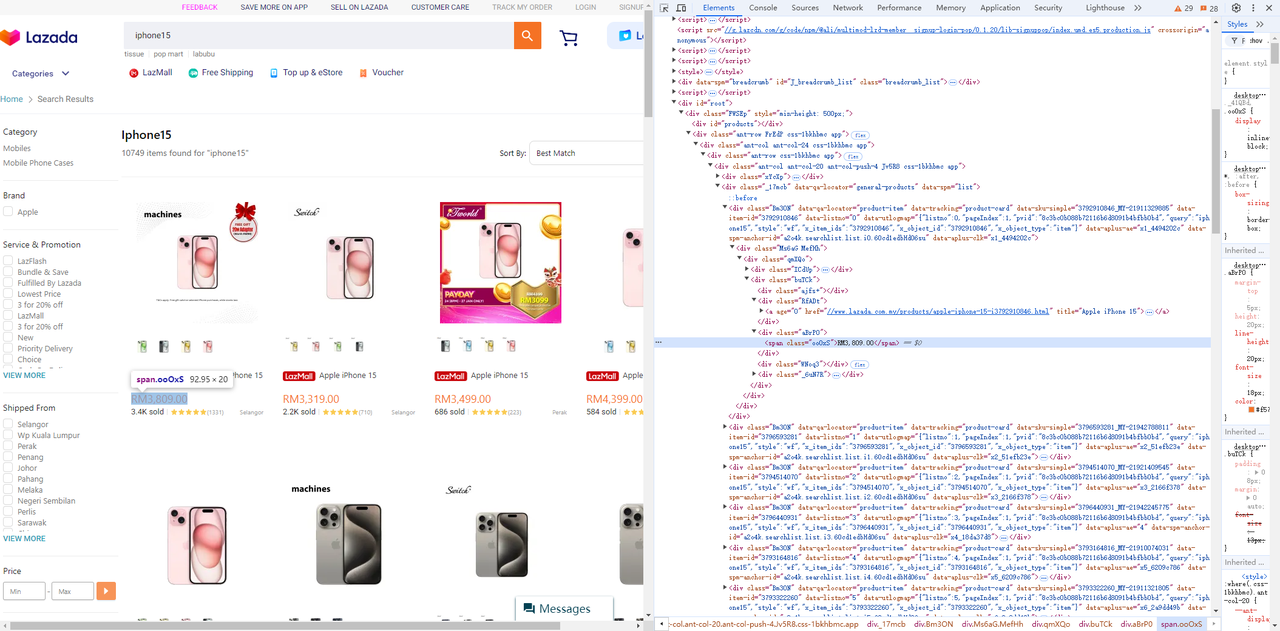
Go
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // すべてのページ要素がレンダリングされるように下にスクロールする。
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // すべての画像がロードされるように繰り返しスクロールする。
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
return product, nil
}Chrome環境の設定
デバッグを容易にするために、PowerShellでChromeブラウザを起動し、リモートデバッグポートを指定できます。
PowerShell
chrome.exe --remote-debugging-port=9223http://localhost:9223/json/list にアクセスして、ブラウザの公開されたリモートデバッグアドレスである webSocketDebuggerUrl を取得できます。
PowerShell
[
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080",
"id": "85CE4D807D11D30D5F22C1AA52461080",
"title": "localhost:9223/json/list",
"type": "page",
"url": "http://localhost:9223/json/list",
"webSocketDebuggerUrl": "ws://localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080"
}
]コードの実行
完全なコードは次のとおりです。
Go
package main
import (
"context"
"encoding/json"
"flag"
"log"
"time"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
type Product struct {
ID string `json:"id"`
Img string `json:"img"`
Price string `json:"price"`
Title string `json:"title"`
}
func main() {
product := flag.String("product", "iphone15", "あなたの商品キーワード")
url := flag.String("webSocketDebuggerUrl", "", "あなたのwebsocket URL")
flag.Parse()
var baseCxt context.Context
if *url != "" {
baseCxt, _ = chromedp.NewRemoteAllocator(context.Background(), *url)
} else {
baseCxt = context.Background()
}
ctx, cancel := chromedp.NewContext(
baseCxt,
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate(`https://www.lazada.com.my/`),
searchProduct(*product),
getNodes(&nodes),
)
products := make([]*Product, 0, len(nodes))
for _, v := range nodes {
product, err := getProductData(ctx, v)
if err != nil {
log.Println("ノードタスクの実行エラー: ", err)
continue
}
products = append(products, product)
}
if err != nil {
log.Fatal(err)
}
jsonData, _ := json.Marshal(products)
log.Println(string(jsonData))
}
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// 入力要素が表示されるのを待つ
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// 検索する商品を入力する。
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// 検索をクリックする
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // すべてのページ要素がレンダリングされるように下にスクロールする。
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // すべての画像がロードされるように繰り返しスクロールする。
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
product.ID = node.AttributeValue("data-item-id")
return product, nil
}次のコマンドを実行すると、スクレイピングされたデータの結果を取得できます。
PowerShell
go run .\crawl.go -product="YOUR KEYWORD" -webSocketDebuggerUrl="YOUR WEBSOCKETDEBUGGERURL"
JSON
[
{
"id": "3792910846",
"img": "https://img.lazcdn.com/g/p/a79df6b286a0887038c16b7600e38f4f.png_200x200q75.png_.webp",
"price": "RM3,809.00",
"title": "Apple iPhone 15"
},
{
"id": "3796593281",
"img": "https://img.lazcdn.com/g/p/627828b5fa28d708c5b093028cd06069.png_200x200q75.png_.webp",
"price": "RM3,319.00",
"title": "Apple iPhone 15"
},
{
"id": "3794514070",
"img": "https: //img.lazcdn.com/g/p/6f4ddc2693974398666ec731a713bcfd.jpg_200x200q75.jpg_.webp",
"price": "RM3,499.00",
"title": "Apple iPhone 15"
},
{
"id": "3796440931",
"img": "https://img.lazcdn.com/g/p/8df101af902d426f3e3a9748bafa7513.jpg_200x200q75.jpg_.webp",
"price": "RM4,399.00",
"title": "Apple iPhone 15"
},
......
{
"id": "3793164816",
"img": "https://img.lazcdn.com/g/p/b6c3498f75f1215f24712a25799b0d19.png_200x200q75.png_.webp",
"price": "RM3,799.00",
"title": "Apple iPhone 15"
},
{
"id": "3793322260",
"img": "https: //img.lazcdn.com/g/p/67199db1bd904c3b9b7ea0ce32bc6ace.png_200x200q75.png_.webp",
"price": "RM5,644.00",
"title": "[Ready Stock] Apple iPhone 15 Pro"
},
{
"id": "3796624559",
"img": "https://img.lazcdn.com/g/p/81a814a9c829afa200fbc691c9a0c30c.png_200x200q75.png_.webp",
"price": "RM6,679.00",
"title": "Apple iPhone 15 Pro (1TB)"
}
]スケーラブルなウェブクローラーのための高度なテクニック
ウェブクローラーを改善する必要があります!ブロックされたり、オーバーロードされたりすることなく効果的にデータを収集するには、速度、信頼性、リソースの最適化のバランスをとるテクニックを実装する必要があります。
大量のワークロード下でもクローラーが優れていることを確認するための高度な戦略を探求しましょう。
リクエストとセッションの維持
ウェブクロールでは、短時間にサーバーに多くのリクエストを集中することは、検出され、禁止される確実な方法です。ウェブサイトは、同じクライアントからのリクエストの頻度を監視することが多く、突然の急増はアンチボットメカニズムをトリガーする可能性があります。
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// 再利用可能なHTTPクライアントを作成する
client := &http.Client{}
// クロールするURL
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
}
// リクエスト間の間隔(例:2秒)
requestInterval := 2 * time.Second
for _, url := range urls {
// 新しいHTTPリクエストを作成する
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (compatible; WebCrawler/1.0)")
// リクエストを送信する
resp, err := client.Do(req)
if err != nil {
fmt.Println("エラー:", err)
continue
}
// レスポンスを読み取り、出力する
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("レスポンス from %s:\n%s\n", url, body)
resp.Body.Close()
// 次のリクエストを送信する前に待つ
time.Sleep(requestInterval)
}
}重複リンクの回避
同じURLを2回クロールしてリソースを無駄にすることほど悪いことはありません。すでにアクセスしたページを追跡するためにURLセット(例:ハッシュマップまたはRedisデータベース)を維持することにより、堅牢な重複排除システムを実装します。これは帯域幅を節約するだけでなく、クローラーが効率的に動作し、新しいページを見逃さないようにします。
IPブロックを回避するためのプロキシ管理
大規模なスクレイピングは、多くの場合、アンチボット対策をトリガーし、IPブロックにつながります。これを回避するために、プロキシローテーションをクローラーに統合します。
- プロキシプールを使用して、複数のIPにリクエストを分散します。
- リクエストが異なるユーザーや場所から発信されたように見えるように、プロキシを動的にローテーションする。
特定のページの優先順位付け
特定のページを優先順位付けすると、クロールプロセスを合理化し、使用可能なリンクのクロールに集中できます。現在のクローラーでは、CSSセレクターを使用してページネーションリンクのみをターゲットにし、貴重な商品情報を抽出します。
ただし、ページ上のすべてのリンクに関心があり、ページネーションを優先したい場合は、別のキューを維持し、最初にページネーションリンクを処理できます。
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
// ...
// ページネーションリンクとその他のリンクを分離するための変数を定義する
var paginationURLs = []string{}
var otherURLs = []string{}
func main() {
// ...
}
func crawl (currenturl string, maxdepth int) {
// ...
// ----- 全てのリンクを見つけ、アクセスする ---- //
// 全てのアンカータグのhref属性を選択する
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// 絶対URLを取得する
link := e.Request.AbsoluteURL(e.Attr("href"))
// 現在のURLが既にアクセス済みかどうかを確認する
if link != "" && !visitedurls[link] {
// 現在のURLをvisitedURLsに追加する
visitedurls[link] = true
if e.Attr("class") == "page-numbers" {
paginationURLs = append(paginationURLs, link)
} else {
otherURLs = append(otherURLs, link)
}
}
})
// ...
// まずページネーションリンクを処理する
for len(paginationURLs) > 0 {
nextURL := paginationURLs[0]
paginationURLs = paginationURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("ページへのアクセスエラー:", err)
}
}
// その他のリンクを処理する
for len(otherURLs) > 0 {
nextURL := otherURLs[0]
otherURLs = otherURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("ページへのアクセスエラー:", err)
}
}
}ScrapelessスクレイピングAPI:効果的なクロールツール
なぜScrapelessスクレイピングAPIがより理想的なのでしょうか?
ScrapelessスクレイピングAPIは、ウェブサイトからデータを抽出するプロセスを簡素化するために設計されており、最も複雑なウェブ環境をナビゲーションし、動的コンテンツとJavaScriptレンダリングを効果的に管理できます。
さらに、ScrapelessスクレイピングAPIは、7,000万を超える住宅用IPへのアクセスをサポートする195カ国にまたがるグローバルネットワークを活用しています。99.9%のアップタイムと卓越した成功率により、ScrapelessはIPブロックやCAPTCHAなどの課題を容易に克服し、複雑なウェブ自動化とAI駆動のデータ収集のための堅牢なソリューションとなっています。
高度なスクレイピングAPIを使用すると、複雑なスクレイピングスクリプトを作成または維持することなく、必要なデータにアクセスできます!
スクリプトAPIの利点
Scrapelessは高性能なJavaScriptレンダリングをサポートしているため、動的コンテンツ(AJAXやJavaScriptを介してロードされたデータなど)を処理し、コンテンツ配信にJSを依存する最新のウェブサイトをスクレイピングできます。
- 手頃な価格: Scrapelessは、優れた価値を提供するように設計されています。
- 安定性と信頼性: 実績のあるScrapelessは、大量のワークロード下でも安定したAPI応答を提供します。
- 高い成功率: 失敗した抽出に別れを告げ、ScrapelessはGoogle SERPデータへの99.99%の成功率の高いアクセスを約束します。
- スケーラビリティ: Scrapelessを支える堅牢なインフラストラクチャのおかげで、数千のクエリを簡単に処理できます。
今すぐ安価で強力なScrapelessスクレイピングAPIを入手しましょう!
Scrapelessは、競争力のある価格で信頼性が高くスケーラブルなウェブスクレイピングプラットフォームを提供し、ユーザーに優れた価値を提供します。
- スクレイピングブラウザ: 時間あたり0.09ドルから
- スクレイピングAPI: URL 1,000件あたり1.00ドルから
- ウェブアンロッカー: URL 1,000件あたり0.20ドル
- CAPTCHAソルバー: URL 1,000件あたり0.80ドルから
- プロキシ: GBあたり2.80ドル
登録すると、各サービスで最大20%の割引を受けることができます。具体的な要件がありますか?お問い合わせください。お客様のニーズに合わせてさらに大きな割引を提供いたします!
ScrapelessスクレイピングAPIの使用方法?
ScrapelessスクレイピングAPIを使用してLazadaデータをクロールするのは非常に簡単です。必要なデータすべてを取得するには、1つの簡単なリクエストだけで済みます。Scrapeless APIをすばやく呼び出す方法は?次の手順に従ってください。
- ステップ1. Scrapelessにログインします。
- ステップ2. 「スクレイピングAPI」をクリックします。
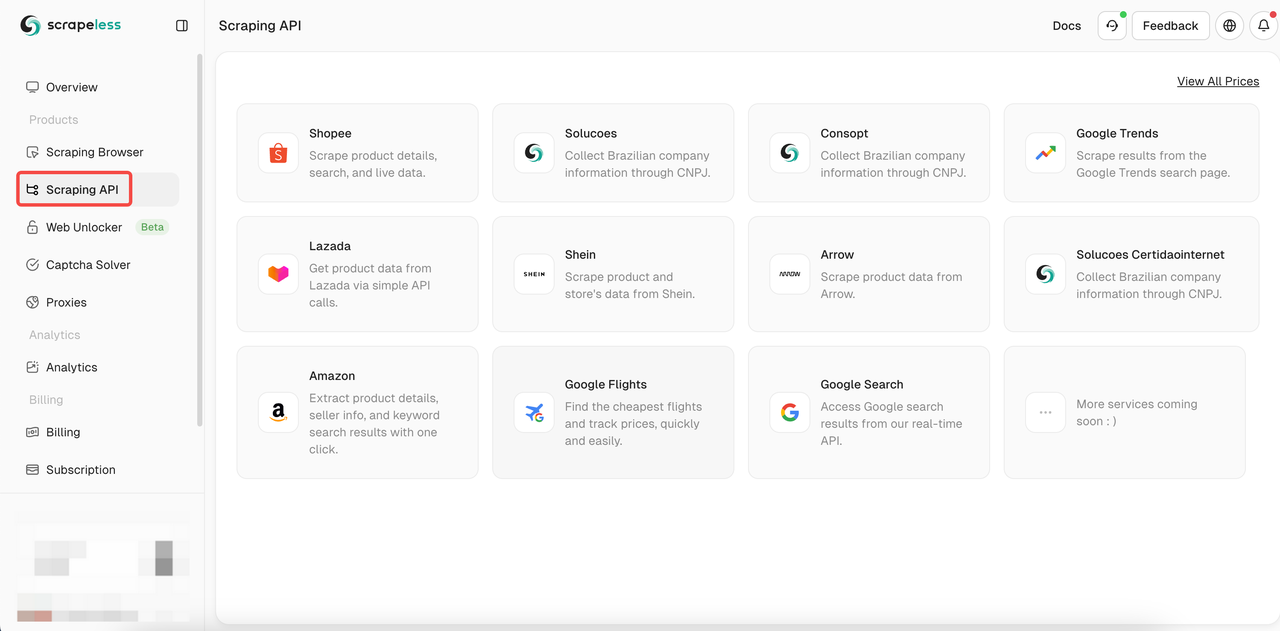
- ステップ3. 私たちの「Lazada」APIを見つけ、入力します。
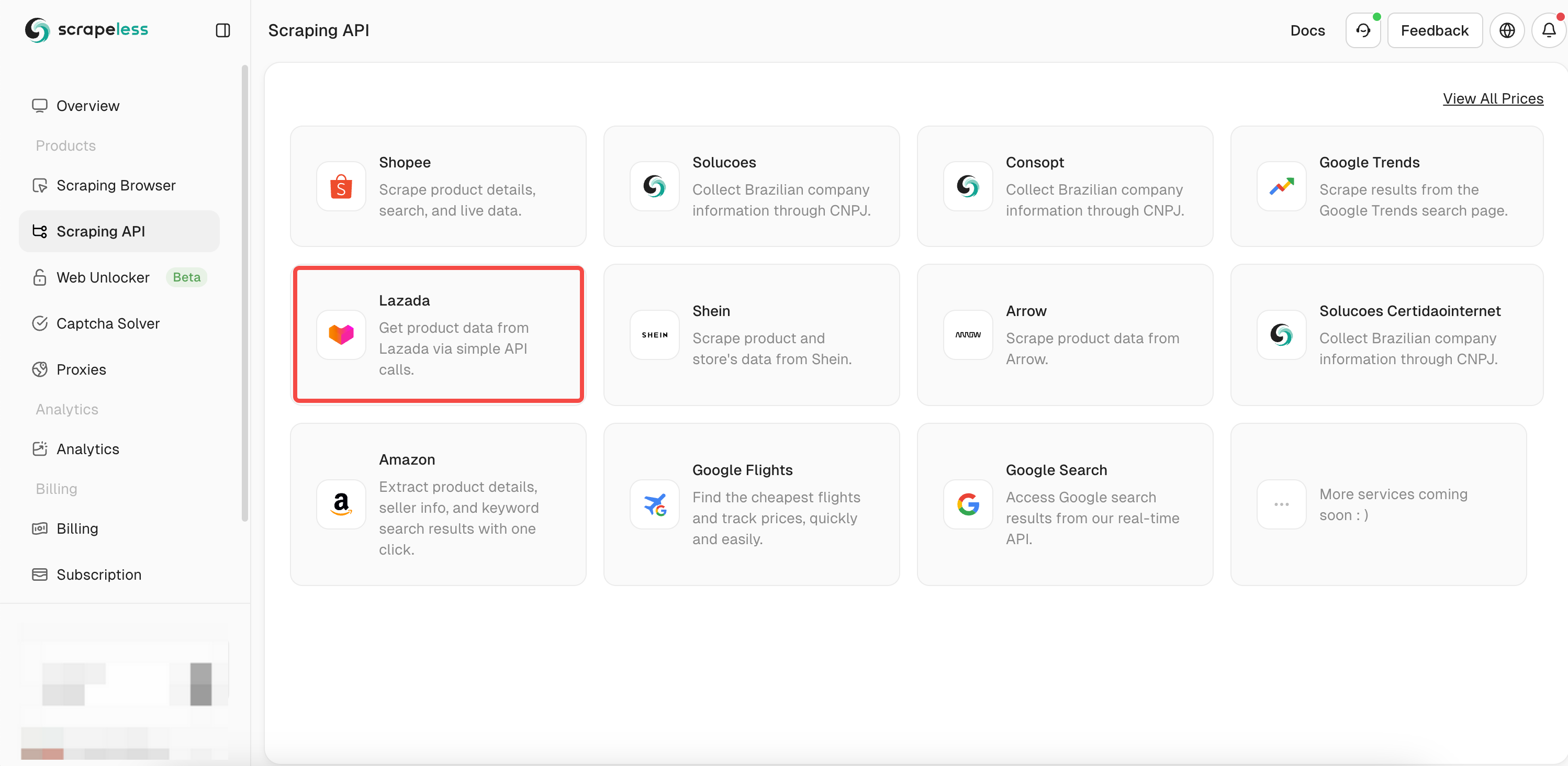
- ステップ4. 左側の操作ボックスにクロールしたい商品の完全な情報を入力します。
chromedpを使用してデータをクロールする場合、すでにクロールされた商品のIDを取得しています。これで、itemIdパラメーターにIDを追加するだけで、商品に関するより詳細なデータを取得できます。次に、使用する式言語を選択します。
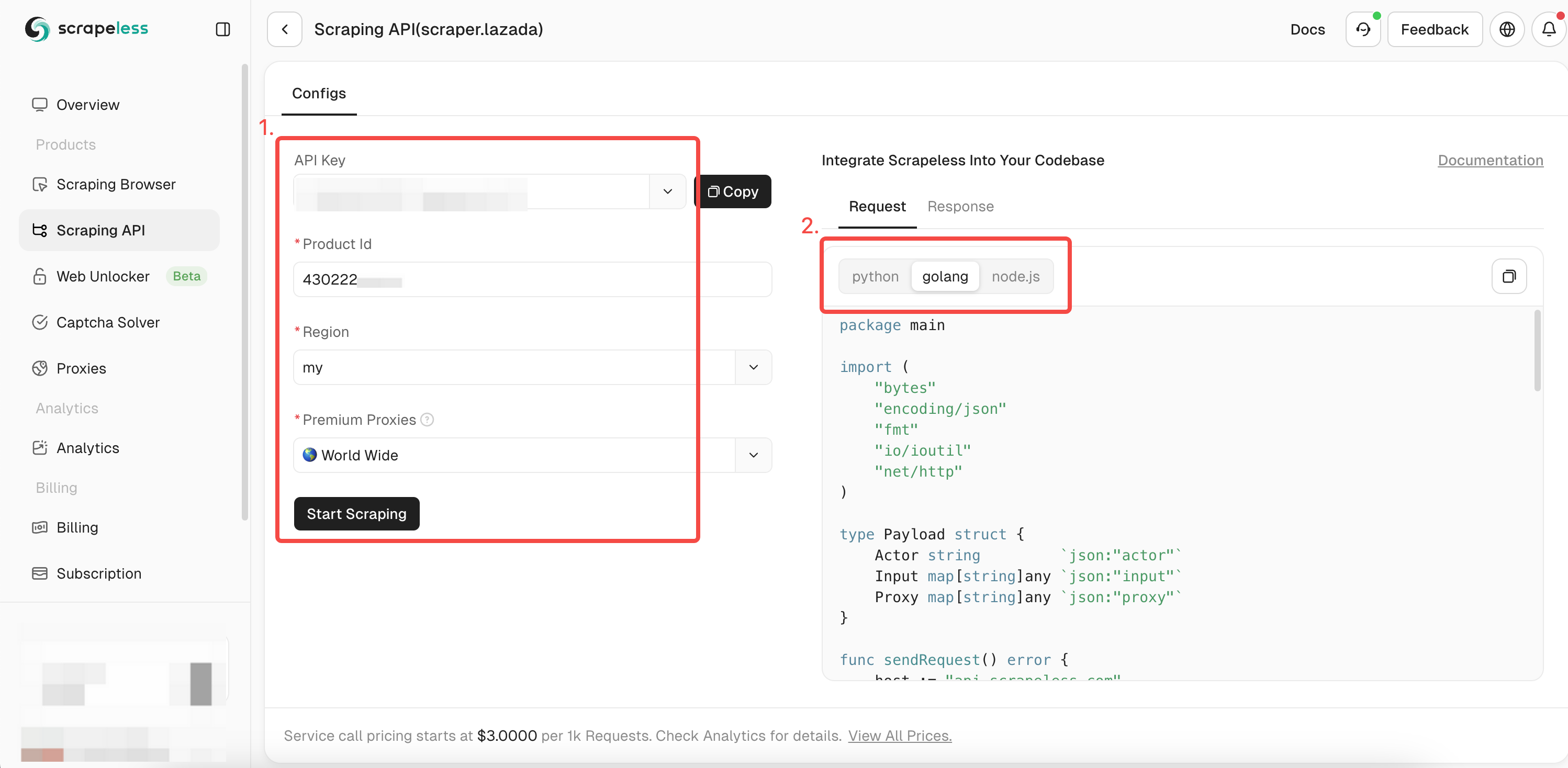
- ステップ5. 「スクレイピングを開始」をクリックすると、右側のプレビューボックスに商品のクロール結果が表示されます。
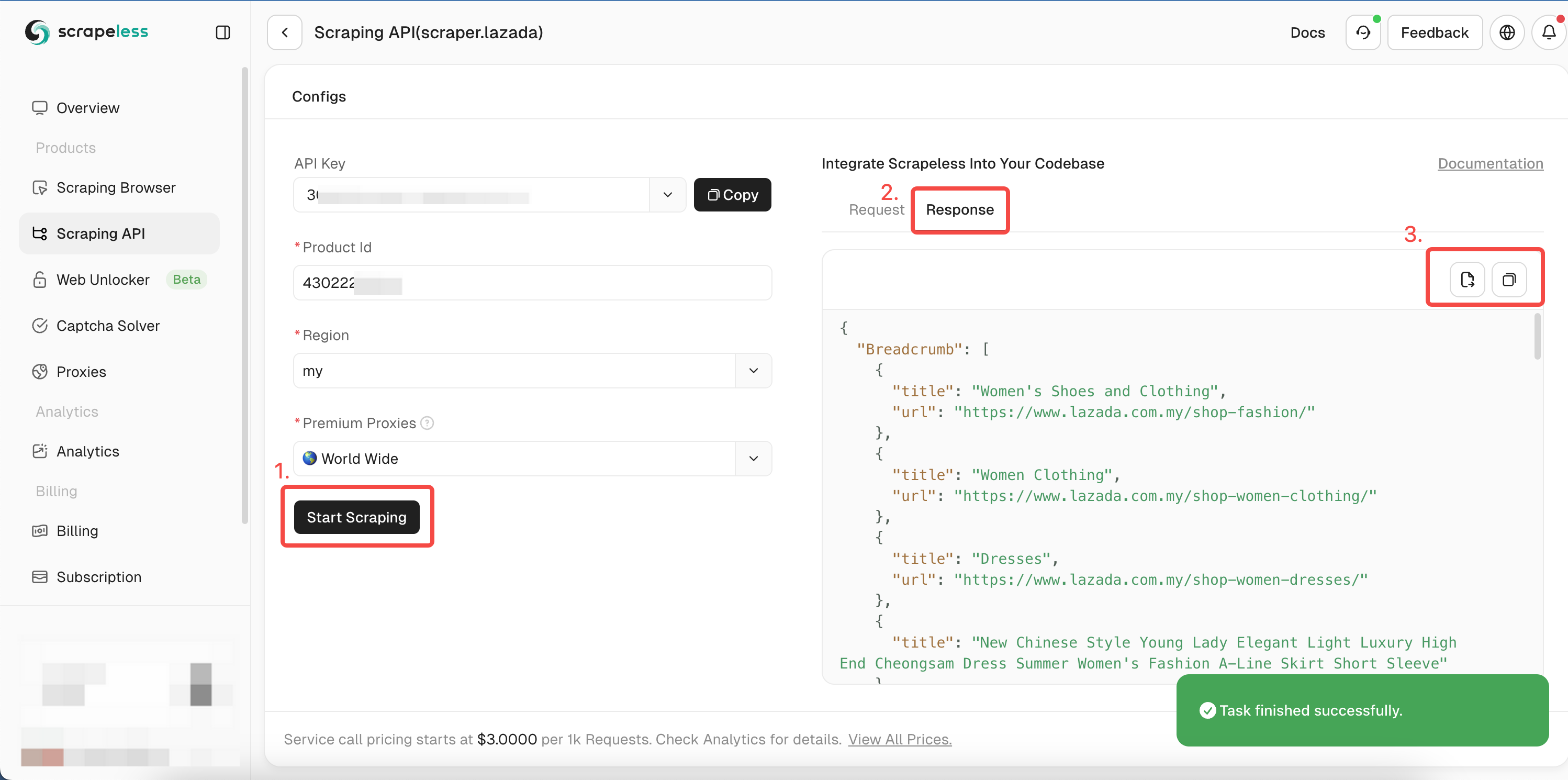
Golangのサンプルコードを参照するか、APIドキュメントで他の言語を確認してください。
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := "YOUR_TOKEN"
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": "3792910846", // 取得したいitemIdに置き換えます。
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("エラー:", err)
return
}
}実行後、リンク、画像、SKU、レビュー、同じ販売者など、次の詳細データを取得します。
スペースの制約により、ここではクロール結果の一部のみを表示しています。ダッシュボードにアクセスして無料トライアルを取得し、すぐにクロールして完全な結果を取得できます!
JSON
{
"Breadcrumb": [
{
"title": "モバイルとタブレット",
"url": "https://www.lazada.com.my/shop-mobiles-tablets/"
},
{
"title": "スマートフォン",
"url": "https://www.lazada.com.my/shop-mobiles/"
},
{
"title": "Apple iPhone 15"
}
],
"deliveryOptions": {
"21911329880": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "ローカルアイテムの場合、2〜4営業日以内にアイテムを受け取ることができます。<br/>送料は、販売者から購入した商品の総サイズ/重量に基づいて決定されます。<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">詳細はこちら</a>",
"duringTime": "1月24日から27日まで保証",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "標準配送",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "代金引換は利用できません",
"type": "noCOD"
}
],
"21911329881": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "ローカルアイテムの場合、2〜4営業日以内にアイテムを受け取ることができます。<br/>送料は、販売者から購入した商品の総サイズ/重量に基づいて決定されます。<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">詳細はこちら</a>",
"duringTime": "1月24日から27日まで保証",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "標準配送",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "代金引換は利用できません",
"type": "noCOD"
}
],
...さらに読む
- Shopee商品詳細をスクレイピングする完全な手順
- Google Trendsデータを迅速かつ簡単にスクレイピングする方法?
- Google Flights APIを使用して格安航空券を追跡するための手順を取得する!
Golangクロールベストプラクティスと考慮事項
並列クロールと並行処理
複数のページを同期的にスクレイピングすると、一度に1つのゴルーチンしかアクティブにタスクを処理できないため、非効率になる可能性があります。ウェブクローラーは、レスポンスを待機し、データ処理を行うのに多くの時間を費やし、次のタスクに進む前に時間を取られます。
ただし、Goの並行処理機能を活用して並行クロールを試みると、全体的なクロール時間を大幅に短縮できます!
ただし、ターゲットサーバーを圧倒したり、アンチボット制限をトリガーしたりしないように、並行処理を適切に管理する必要があります。
GoでのJavaScriptレンダリングページのクロール
Collyは多くの組み込み機能を備えた優れたウェブクローラーツールですが、JavaScriptレンダリングされたページ(動的コンテンツ)をクロールすることはできません。静的HTMLのみを取得して解析でき、動的コンテンツはウェブサイトの静的HTMLには存在しません。
ただし、動的コンテンツをクロールするために、ヘッドレスブラウザまたはJavaScriptエンジンと統合できます。
結論
高度なプログラミングを使用してGolangウェブクローラーを構築する方法を学習しました。ウェブを閲覧するためのウェブスクレイパーの構築は良い出発点ですが、最新のウェブサイトにアクセスするにはアンチボット対策を克服する必要があることを忘れないでください。
失敗しやすい手動構成に苦労するのではなく、あらゆるアンチボットシステムを回避するための最も信頼性の高いソリューションであるScrapelessスクレイピングAPIを検討してください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


