
PythonでGoogleトレンドデータをスクレイピングする方法
Senior Web Scraping Engineer
Google Trendsとは?
Google Trendsは、Googleが提供する無料のオンラインツールで、Google検索エンジンの特定のキーワードや検索用語の人気度を時間とともに分析します。
チャート形式でデータを表示することで、特定のトピックやキーワードの検索人気度を理解し、季節変動、新たなトレンド、関心の低下などのパターンを特定するのに役立ちます。Google Trendsはグローバルデータ分析をサポートするだけでなく、特定の地域に絞り込むこともでき、関連する検索用語やトピックの推奨事項も提供します。
Google Trendsは、市場調査、コンテンツプランニング、SEO最適化、ユーザー行動分析などで広く使用されており、データに基づいたより情報に基づいた意思決定を支援します。
PythonでGoogle Trendsのデータをスクレイピングする方法 - ステップバイステップガイド
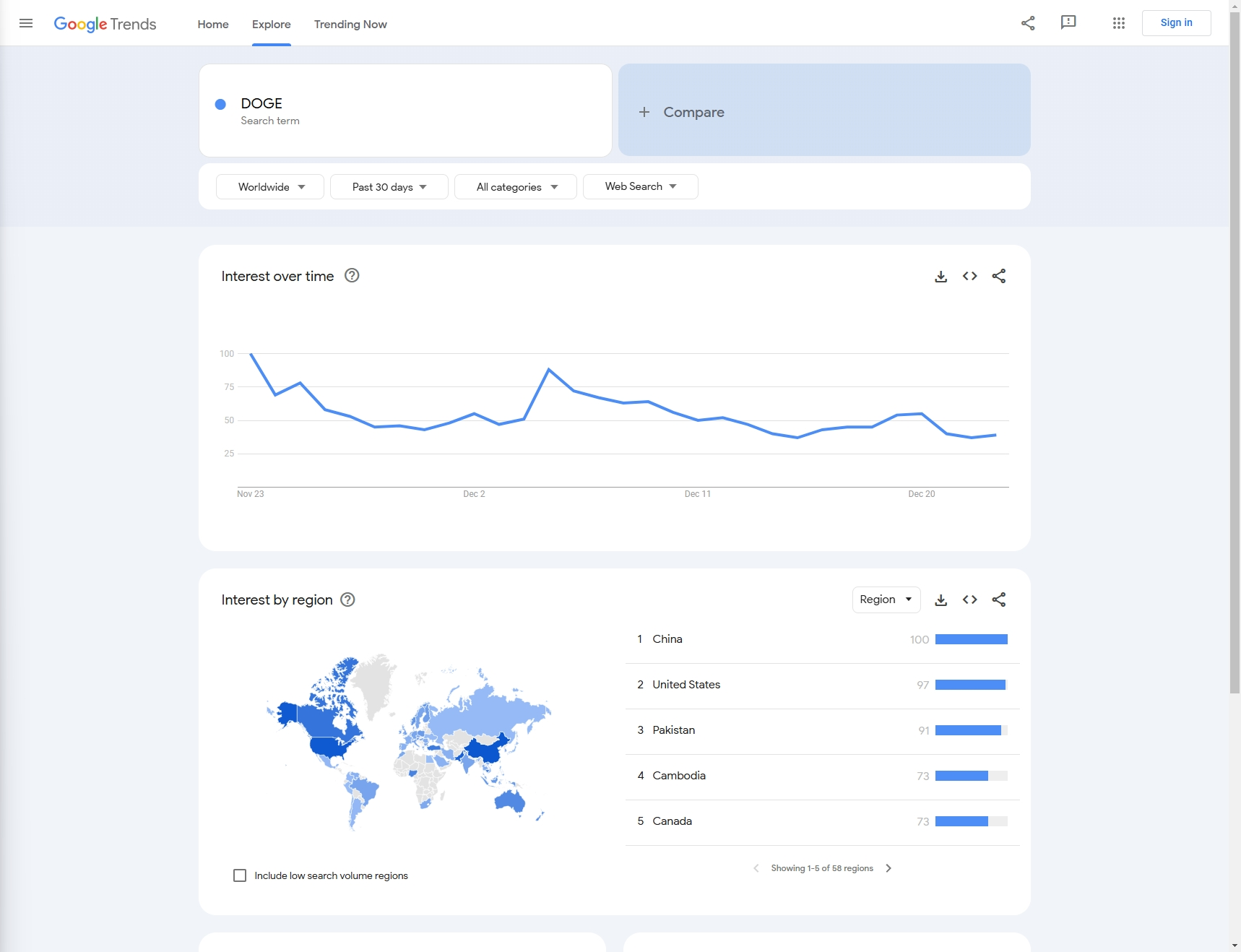
例:この記事では、過去1ヶ月間のDOGEのGoogle検索トレンドをスクレイピングしてみましょう。
ステップ1:前提条件
Pythonのインストール
Windowsの場合
公式Pythonインストーラーを使用する
-
Pythonインストーラーをダウンロードする:
- 公式Pythonウェブサイトにアクセスします。
- ウェブサイトは自動的にWindows向けの最新バージョンを提案します。「Download Python」ボタンをクリックしてインストーラーをダウンロードします。
-
インストーラーを実行する:
- ダウンロードした
.exeファイルを開いてインストールプロセスを開始します。
- ダウンロードした
-
インストールのカスタマイズ(オプション):
- インストールウィンドウの先頭で、「Add Python to PATH」というチェックボックスに必ずチェックを入れてください。これにより、コマンドライン(
cmdまたはPowerShell)からPythonにアクセスできるようになります。 - 「Customize installation」をクリックして、
pip、IDLE、documentationなどの追加機能を選択することもできます。
- インストールウィンドウの先頭で、「Add Python to PATH」というチェックボックスに必ずチェックを入れてください。これにより、コマンドライン(
-
Pythonをインストールする:
- デフォルト設定でPythonをインストールするには、「Install Now」をクリックします。
- インストール後、コマンドプロンプト(
cmd)を開いて次のように入力することで確認できます。bashpython --version
-
pipのインストール(必要な場合):
- Pythonのパッケージマネージャーであるpipは、最新のPythonバージョンではデフォルトでインストールされています。pipがインストールされているかどうかを確認するには、次のように入力します。
bash
pip --version
- Pythonのパッケージマネージャーであるpipは、最新のPythonバージョンではデフォルトでインストールされています。pipがインストールされているかどうかを確認するには、次のように入力します。
Windowsストア(Windows 10/11で使用可能)からもPythonを直接インストールできます。Microsoft Storeアプリで「Python」を検索し、必要なバージョンを選択します。
macOSの場合
方法1. Homebrewを使用する(推奨)
-
Homebrewをインストールする(まだインストールしていない場合):
- ターミナルアプリを開きます。
- Homebrew(macOSのパッケージマネージャー)をインストールするには、次のコマンドを貼り付けます。
bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
-
HomebrewでPythonをインストールする:
- Homebrewがインストールされたら、次のコマンドでPythonをインストールできます。
bash
brew install python
- Homebrewがインストールされたら、次のコマンドでPythonをインストールできます。
-
インストールを確認する:
- インストール後、次のコマンドでPythonとpipのバージョンを確認できます。
bash
python3 --version pip3 --version
- インストール後、次のコマンドでPythonとpipのバージョンを確認できます。
方法2. 公式Pythonインストーラーを使用する
-
macOSインストーラーをダウンロードする:
- Pythonダウンロードページにアクセスします。
- Pythonの最新のmacOSインストーラーをダウンロードします。
-
インストーラーを実行する:
.pkgファイルを開いてインストールプロセスを開始し、指示に従います。
-
インストールを確認する:
- インストール後、ターミナルを開いてPythonのバージョンを確認します。
bash
python3 --version pip3 --version
- インストール後、ターミナルを開いてPythonのバージョンを確認します。
Linuxの場合
Debian/Ubuntuベースのディストリビューションの場合
-
パッケージリストを更新する:
- ターミナルを開き、次のコマンドを実行してパッケージリストを更新します。
bash
sudo apt update
- ターミナルを開き、次のコマンドを実行してパッケージリストを更新します。
-
Pythonをインストールする:
- Python 3(通常はPython 3.xの最新バージョン)をインストールするには、次を実行します。
bash
sudo apt install python3
- Python 3(通常はPython 3.xの最新バージョン)をインストールするには、次を実行します。
-
pipをインストールする(インストールされていない場合):
- pipがまだインストールされていない場合は、次のようにインストールできます。
bash
sudo apt install python3-pip
- pipがまだインストールされていない場合は、次のようにインストールできます。
-
インストールを確認する:
- インストールされたPythonのバージョンを確認するには、次のようにします。
bash
python3 --version pip3 --version
- インストールされたPythonのバージョンを確認するには、次のようにします。
Red Hat/Fedoraベースのディストリビューションの場合
-
Python 3をインストールする:
- ターミナルを開き、次を実行します。
bash
sudo dnf install python3
- ターミナルを開き、次を実行します。
-
pipをインストールする(必要な場合):
pipがデフォルトでインストールされていない場合は、次のようにインストールできます。bashsudo dnf install python3-pip
-
インストールを確認する:
- インストールされたPythonのバージョンを確認するには、次のようにします。
bash
python3 --version pip3 --version
- インストールされたPythonのバージョンを確認するには、次のようにします。
Arch LinuxとArchベースのディストリビューションの場合
-
Python 3をインストールする:
- 次のコマンドを実行します。
bash
sudo pacman -S python
- 次のコマンドを実行します。
-
pipをインストールする:
- pipはPythonと一緒にインストールされるはずですが、そうでない場合は、次のようにインストールできます。
bash
sudo pacman -S python-pip
- pipはPythonと一緒にインストールされるはずですが、そうでない場合は、次のようにインストールできます。
-
インストールを確認する:
- Pythonとpipのバージョンを確認するには、次のようにします。
bash
python --version pip --version
- Pythonとpipのバージョンを確認するには、次のようにします。
Anacondaを使用したPython(クロスプラットフォーム)
Anacondaは、科学計算用の一般的なディストリビューションであり、Python、ライブラリ、condaパッケージマネージャーが付属しています。
-
Anacondaをダウンロードする:
- Anacondaダウンロードページにアクセスし、プラットフォームに適したバージョンをダウンロードします。
-
Anacondaをインストールする:
- オペレーティングシステムに基づいてインストール手順に従います。Anacondaは、WindowsとmacOSの両方でグラフィカルインストーラーを提供しており、すべてのプラットフォームでコマンドラインインストーラーも提供しています。
-
インストールを確認する:
-
インストール後、ターミナル(またはWindowsのAnaconda Prompt)を開き、Pythonが動作しているかどうかを確認します。
bashpython --version -
conda(Anacondaのパッケージマネージャー)も確認できます。bashconda --version
-
Pythonのバージョンの管理(オプション)
同じマシンに複数のPythonバージョンを管理する必要がある場合は、バージョンマネージャーを使用できます。
-
pyenv: LinuxとmacOSで動作する一般的なPythonバージョンマネージャー。
- HomebrewまたはGitHubからインストール(LinuxとmacOSの場合)。
- Windowsでは、pyenv-winを使用できます。
bashpyenv install 3.9.0 pyenv global 3.9.0
Scrapeless APIとGoogleトレンドへのアクセス
サードパーティライブラリはまだ開発していないため、Scrapeless APIサービスを利用するにはrequestsをインストールするだけです。
Shell
pip install requestsステップ2:必要なコードフィールドの設定
次に、設定を通じて必要なデータを取得する方法を知る必要があります。
- キーワード: この例では、キーワードは「DOGE」です(複数のキーワードの比較データの収集もサポートしています)。
- データ設定:
- 国: クエリ対象の国、デフォルトは「Worldwide」
- 期間: 期間
- カテゴリ: タイプ
- プロパティ: ソース
ステップ3:データの抽出
では、Pythonコードを使用してターゲットデータを取得しましょう。
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:あなたのAPIキーを使用してください
headers = {"x-api-token": token}
input_data = {
"q": search_term,
"date": "today 1-m",
"data_type": data_type,
"hl": "en-sg",
"tz": "-480",
"geo": "",
"cat": "",
"property": "",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request(data_type="interest_over_time", search_term="DOGE")- 出力:
JSON
{"interest_over_time":{"averages":[],"timelineData":[{"formattedAxisTime":"24 Nov","formattedTime":"24 Nov 2024","formattedValue":["85"],"hasData":[true],"time":"1732406400","value":[85]},{"formattedAxisTime":"25 Nov","formattedTime":"25 Nov 2024","formattedValue":["89"],"hasData":[true],"time":"1732492800","value":[89]},{"formattedAxisTime":"26 Nov","formattedTime":"26 Nov 2024","formattedValue":["68"],"hasData":[true],"time":"1732579200","value":[68]},{"formattedAxisTime":"27 Nov","formattedTime":"27 Nov 2024","formattedValue":["60"],"hasData":[true],"time":"1732665600","value":[60]},{"formattedAxisTime":"28 Nov","formattedTime":"28 Nov 2024","formattedValue":["49"],"hasData":[true],"time":"1732752000","value":[49]},{"formattedAxisTime":"29 Nov","formattedTime":"29 Nov 2024","formattedValue":["55"],"hasData":[true],"time":"1732838400","value":[55]},{"formattedAxisTime":"30 Nov","formattedTime":"30 Nov 2024","formattedValue":["54"],"hasData":[true],"time":"1732924800","value":[54]},{"formattedAxisTime":"1 Dec","formattedTime":"1 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1733011200","value":[55]},{"formattedAxisTime":"2 Dec","formattedTime":"2 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733097600","value":[64]},{"formattedAxisTime":"3 Dec","formattedTime":"3 Dec 2024","formattedValue":["57"],"hasData":[true],"time":"1733184000","value":[57]},{"formattedAxisTime":"4 Dec","formattedTime":"4 Dec 2024","formattedValue":["61"],"hasData":[true],"time":"1733270400","value":[61]},{"formattedAxisTime":"5 Dec","formattedTime":"5 Dec 2024","formattedValue":["100"],"hasData":[true],"time":"1733356800","value":[100]},{"formattedAxisTime":"6 Dec","formattedTime":"6 Dec 2024","formattedValue":["84"],"hasData":[true],"time":"1733443200","value":[84]},{"formattedAxisTime":"7 Dec","formattedTime":"7 Dec 2024","formattedValue":["79"],"hasData":[true],"time":"1733529600","value":[79]},{"formattedAxisTime":"8 Dec","formattedTime":"8 Dec 2024","formattedValue":["72"],"hasData":[true],"time":"1733616000","value":[72]},{"formattedAxisTime":"9 Dec","formattedTime":"9 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733702400","value":[64]},{"formattedAxisTime":"10 Dec","formattedTime":"10 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733788800","value":[64]},{"formattedAxisTime":"11 Dec","formattedTime":"11 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1733875200","value":[63]},{"formattedAxisTime":"12 Dec","formattedTime":"12 Dec 2024","formattedValue":["59"],"hasData":[true],"time":"1733961600","value":[59]},{"formattedAxisTime":"13 Dec","formattedTime":"13 Dec 2024","formattedValue":["54"],"hasData":[true],"time":"1734048000","value":[54]},{"formattedAxisTime":"14 Dec","formattedTime":"14 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734134400","value":[48]},{"formattedAxisTime":"15 Dec","formattedTime":"15 Dec 2024","formattedValue":["43"],"hasData":[true],"time":"1734220800","value":[43]},{"formattedAxisTime":"16 Dec","formattedTime":"16 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734307200","value":[48]},{"formattedAxisTime":"17 Dec","formattedTime":"17 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1734393600","value":[55]},{"formattedAxisTime":"18 Dec","formattedTime":"18 Dec 2024","formattedValue":["52"],"hasData":[true],"time":"1734480000","value":[52]},{"formattedAxisTime":"19 Dec","formattedTime":"19 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1734566400","value":[63]},{"formattedAxisTime":"20 Dec","formattedTime":"20 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1734652800","value":[64]},{"formattedAxisTime":"21 Dec","formattedTime":"21 Dec 2024","formattedValue":["47"],"hasData":[true],"time":"1734739200","value":[47]},{"formattedAxisTime":"22 Dec","formattedTime":"22 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734825600","value":[44]},{"formattedAxisTime":"23 Dec","formattedTime":"23 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734912000","value":[44]},{"formattedAxisTime":"24 Dec","formattedTime":"24 Dec 2024","formattedValue":["46"],"hasData":[true],"isPartial":true,"time":"1734998400","value":[46]}]}}ステップ4:コードの最適化
- 複数の国を設定する
Python
country_map = {
"Worldwide": "",
"Afghanistan":"AF",
"Åland Islands":"AX",
"Albania":"AL",
#...
}- 複数の期間を設定する
Python
time_map = {
"過去1時間":"now 1-H",
"過去4時間":"now 4-H",
"過去7日間":"now 7-d",
"過去30日間":"today 1-m",
# ...
}- 複数のカテゴリを設定する
Python
category_map = {
"すべてのカテゴリ": "",
"芸術とエンターテイメント": "3",
"自動車と乗り物": "47",
# ...
}- 複数のソースを設定する
Python
property_map = {
"ウェブ検索":"",
"画像検索":"images",
"Googleショッピング":"froogle",
# ...
}- 改良されたコード:
Python
import json
import requests
country_map = {
"Worldwide": "",
"Afghanistan": "AF",
"Åland Islands": "AX",
"Albania": "AL",
# ...
}
time_map = {
"Past hour": "now 1-H",
"Past 4 hours": "now 4-H",
"Past 7 days": "now 7-d",
"Past 30 days": "today 1-m",
# ...
}
category_map = {
"All categories": "",
"Arts & Entertainment": "3",
"Autos & Vehicles": "47",
# ...
}
property_map = {
"Web Search": "",
"Image Search": "images",
"Google Shopping": "froogle",
# ...
}
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term, country, time, category, property):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:あなたのAPIキーを使用してください
headers = {"x-api-token": token}
input_data = {
"q": search_term, # 検索用語
"geo": country,
"date": time,
"cat": category,
"property": property,
"hl": "en-sg",
"tz": "-480",
"data_type": data_type
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload, verify=False)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
# 検索用語1つ
send_request(
data_type="interest_over_time",
search_term="DOGE",
country=country_map["Worldwide"],
time=time_map["Past 30 days"],
category=category_map["Arts & Entertainment"],
property=property_map["Web Search"],
)
# 検索用語2つ
send_request(
data_type="interest_over_time",
search_term="DOGE,python",
country=country_map["Worldwide"],
time=time_map["Past 30 days"],
category=category_map["Arts & Entertainment"],
property=property_map["Web Search"],
)クロールプロセスにおける問題点
- エラーによってシャットダウンを防ぐために、ネットワークエラーに対する判断を行う必要があります。
- 特定のリトライメカニズムを追加することで、クロールプロセスの中断が重複した/無効なデータ取得を引き起こすのを防ぐことができます。
ScrapelessスクレイピングAPIによるテスト - 最高のGoogle Trendsスクレイパー
- ステップ1. Scrapelessにログインします。
- ステップ2. 「Scraping API」をクリックします。
- ステップ3. 「Google Trends」パネルを見つけてアクセスします。
- ステップ4. 左側の操作パネルでデータを設定します。
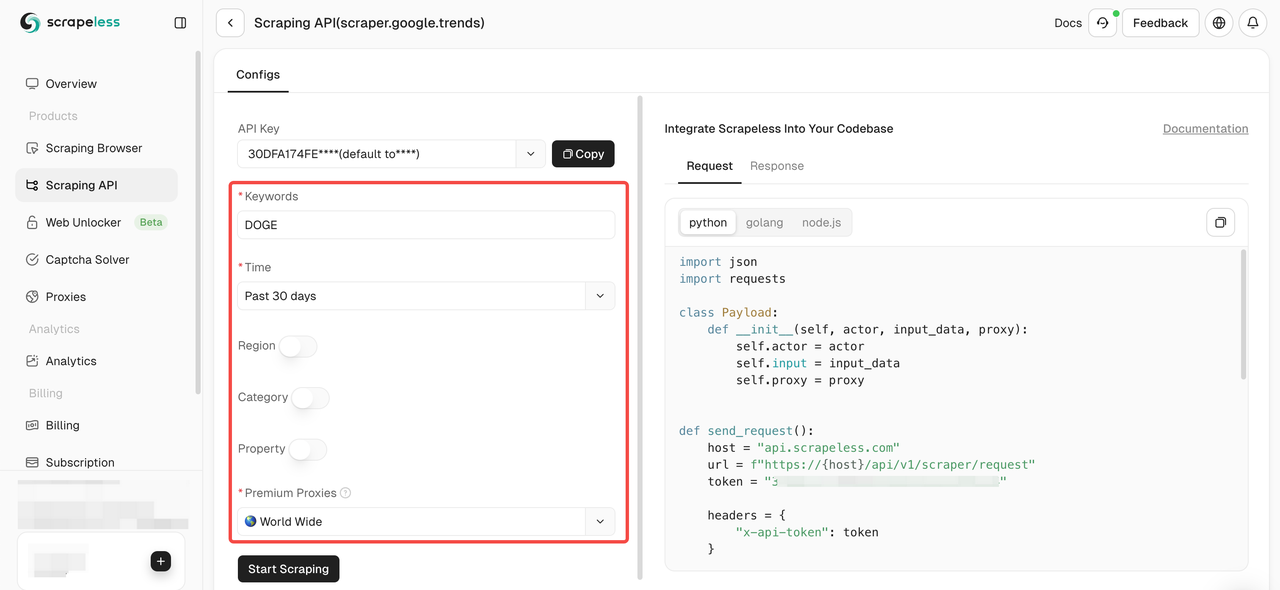
- ステップ5. 「Start Scraping」ボタンをクリックすると、結果を取得できます。
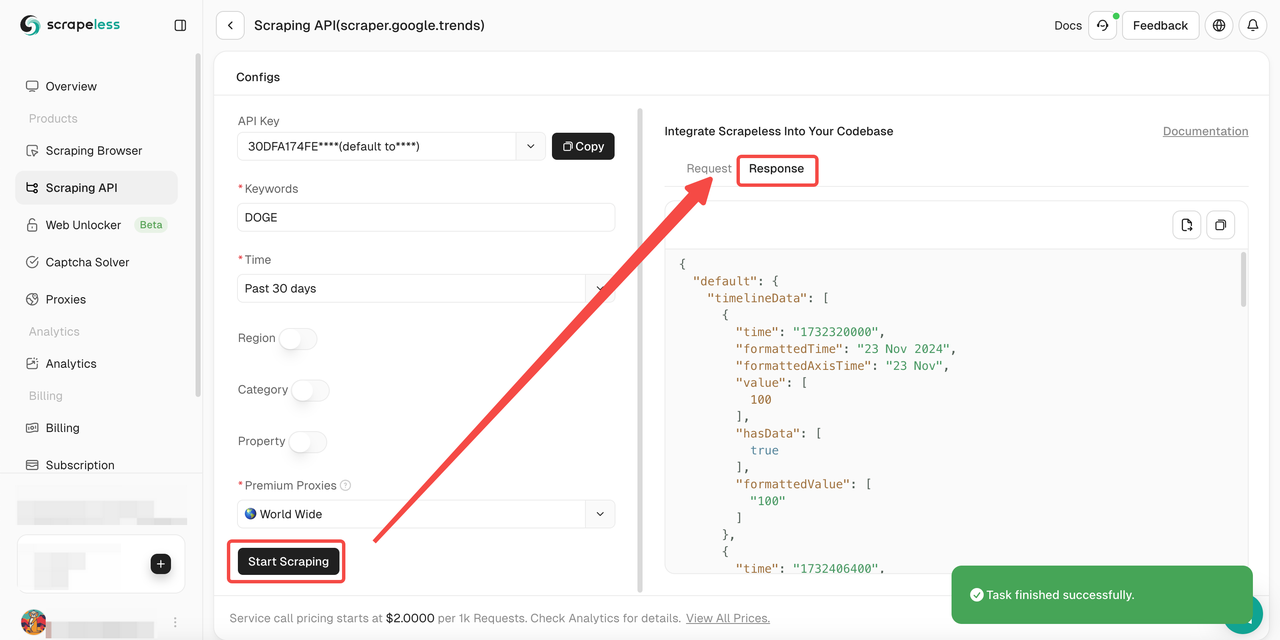
また、サンプルコードも参照できます。
Scrapeless Google Trends API:全体像
Scrapelessは、ウェブサイトからのデータ抽出プロセスを簡素化するために設計された革新的なソリューションです。私たちのAPIは、最も複雑なWeb環境をナビゲートし、動的なコンテンツとJavaScriptレンダリングを効果的に管理するように設計されています。
なぜScrapelessはGoogle Trendsのスクレイピングに適しているのか?
Pythonコーディングのみを使用してGoogle Trendsをクロールしようとすると、reCAPTHCA検証システムに簡単に遭遇します。これは、クロールプロセスに大きな課題をもたらします。
しかし、Scrapeless Google TrendsスクレイピングAPIはCAPTCHAソルバーとインテリジェントなIPローテーションを統合しているため、ウェブサイトによる監視や識別を心配する必要はありません。Scrapelessは99.9%のウェブサイトクロール成功率を保証し、完全に安定した安全なデータクロール環境を提供します。
Scrapelessの4つの典型的な利点
- 競争力のある価格
Scrapelessは強力であるだけでなく、より競争力のある市場価格を保証します。Scrapeless Google TrendsスクレイピングAPIサービスコールの価格は、成功したリクエスト1,000件あたり2ドルから始まります。 - 安定性
豊富な経験と堅牢なシステムにより、高度なCAPTCHA解決機能を備えた信頼性の高い、中断のないスクレイピングが保証されます。 - 速度
大規模なプロキシプールにより、IPブロックや遅延なしで効率的な大規模スクレイピングが保証されます。 - 費用対効果
独自のテクノロジーによりコストを最小限に抑え、品質を犠牲にすることなく競争力のある価格を提供できます。 - SLA保証
サービスレベルアグリーメントにより、エンタープライズニーズに対する一貫したパフォーマンスと信頼性が確保されます。
FAQ
Google Trendsをスクレイピングすることは合法ですか?
はい、グローバルで公開されているGoogle Trendsのデータをスクレイピングすることは完全に合法です。ただし、短時間に多数のリクエストを送信することでサイトに損害を与えないようにしてください。
Google Trendsは誤解を招く可能性がありますか?
Google Trendsは、検索活動の完全な反映ではありません。Google Trendsは、ごく少数の人々によって実行される検索など、特定の種類の検索をフィルターで除外します。Trendsは人気のある用語のデータのみを表示するため、検索ボリュームが少ない用語は「0」と表示されます。
Google TrendsはAPIを提供していますか?
いいえ、Google Trendsはまだ公開APIを提供していません。ただし、Scrapelessなどのサードパーティ開発者ツールのプライベートAPIからGoogle Trendsデータにアクセスできます。
まとめ
Google Trendsは、検索エンジンの検索クエリを分析することで、キーワード分析と人気のある検索トピックを提供する貴重なデータ統合ツールです。この記事では、Pythonを使用してGoogle Trendsをスクレイピングする方法を詳しく説明しました。
しかし、Pythonコーディングを使用してGoogle Trendsをスクレイピングすると、常にCAPTCHAの障害に遭遇します。これにより、データ抽出が特に困難になります。Google Trends APIは利用できませんが、Scrapeless Google Trends APIが理想的なツールになります!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


