
アンチボット検出を回避する方法は?
Senior Web Scraping Engineer
自動化とセキュリティの戦いにおいて、アンチボットメカニズムはウェブの門番となり、不要なボットをブロックしながら、しばしば正当なデータ収集の妨げになっています。
ログインページからeコマースサイトまで、これらの防御策—特にCAPTCHA—は、ウェブスクレイパーや自動化ツールにとってイライラさせる障害物となることがあります。これらを回避する方法はあるのでしょうか?
この記事では、アンチボットシステムの世界を探求し、自動化をどのように検出するかを探り、法的または道徳的な境界を越えずに制限を回避するための倫理的な戦略を明らかにします。
さあ、読み始めましょう!
なぜアンチボット検出が必要なのか?
まずは旅行を楽しんでみましょう。顧客が自由に閲覧できるお店を運営していると想像してみてください。しかし数分おきに、マスクをかぶった人物が駆け込んできて、あなたのすべての商品を掴んで消えてしまいます。あなたはどう感じますか?
これがウェブサイトがボットに対して感じていることです!アンチボット検出は、本物のユーザーと自動化されたスクリプトを区別し、認証情報の詰め込み、コンテンツの盗用、攻撃的なウェブスクレイピングから保護するために存在します。
CAPTCHAからブラウザフィンガープリンティングまで、これらのデジタルバウンサーは、悪意のあるボットを排除するために絶え間なく働いていますが、時にはデータを取得しようとしている善意の開発者にとってもつまずくことがあります。
それでは、ルールを破らずに彼らを出し抜く方法はあるのでしょうか?もっと探求できますね。
一般的なアンチボットメカニズム
- ヘッダー検証: ヘッダー検証は、受信したHTTPヘッダーを分析し、それらをブロックするかどうかを確認します。
- IPブロッキング: IPアドレスに基づいてアクセスを制限します。
- レートリミティング: 単一のIPからのリクエストを制限します。
- ブラウザフィンガープリンティング: ブラウザの属性や挙動を分析します。
- TLSフィンガープリンティング: TLSフィンガープリンティングは、ハンドシェイクパラメータを分析し、予期しない値を持つリクエストをブロックしてボットを検出します。
- ハニーポット: ボットを誘引するための見えない罠。
- CAPTCHAチャレンジ: 人間には簡単ですが、ボットには難しい課題を提供します。
CAPTCHA: 重要なアンチボットメカニズム
CAPTCHAとは?
CAPTCHA(「Completely Automated Public Turing test to tell Computers and Humans Apart」の略)は、実際のユーザーを自動化されたボットから区別するために設計されたセキュリティメカニズムです。人間には簡単ですが機械には難しい課題を提示することで、スパム、認証情報の詰め込み、自動化されたウェブスクレイピングなどの悪意のある行為を防ぐ助けとなります。
CAPTCHAの種類:
- テキストベースのCAPTCHA: ユーザーは歪められたまたは隠されたテキストを認識して入力しなければならず、ボットにとって解釈が難しいです。
- 画像ベースのCAPTCHA: ユーザーは、交通信号や店舗のような画像中の物体を特定します。このタスクは、ほとんどのボットが持たない視覚認識能力を必要とします。
- reCAPTCHA: Googleの高度なCAPTCHAシステムで、単純なチェックボックスの確認(「私はロボットではありません」)、画像選択の課題、明示的な操作なしにユーザーの行動を分析する見えないCAPTCHAなど、複数の形式があります。
- hCAPTCHA: データトラッキングを最小限に抑えながら、依然として効果的なボット保護を提供することを目的とした、プライバシー重視のreCAPTCHAの代替品です。
CAPTCHAの仕組み:
CAPTCHAは、チャレンジ・レスポンスメカニズムに基づいています。ユーザーは自分が人間であることを証明するタスクを完了しなければなりません。システムは、マウスの動き、打鍵速度、またはインタラクションパターンなどの応答と行動を評価し、信頼性を判断します。
現代のCAPTCHAシステムは、進化するボットの能力に基づいて難易度を調整するために機械学習を活用しています。行動データを分析し、リスクベースの評価を行い、さらにはバイオメトリックキューを統合して、精度とセキュリティを高め、ボットがこれらの防御をバイパスすることをますます難しくしています。
アンチボットを回避するためのベストプラクティス
Scrapelessを選ぶ理由は?
Scrapelessは、CAPTCHAで保護されたウェブサイトをシームレスにナビゲートし、途切れのないデータ抽出を保証する強力なCAPTCHAソルバーを提供します。
- 手頃な価格: Scrapelessは、効率を損なうことなく費用対効果の高いCAPTCHA解決策を提供します。
- 安定性と信頼性: 実績のあるトラックレコードを持つScrapelessは、高負荷の下でもCAPTCHAを一貫して解決し、スムーズな自動化を保証します。
- 高い成功率: もはやCAPTCHAの障害物に悩まされることはありません—ScrapelessはCAPTCHAチャレンジを99.99%の成功率で回避します。
- スケーラビリティ: Scrapelessの堅牢なインフラに支えられ、数千のCAPTCHA保護リクエストを簡単に処理できます。
Scrapelessは高価ですか?
Scrapelessは、競争力のある価格で信頼性が高くスケーラブルなウェブスクレイピングプラットフォームを提供しており、ユーザーに優れた価値を提供します:
- Captchaソルバー: 1,000 URLsあたり$0.8から
- スクレイピングブラウザ: 1時間あたり$0.09から
- スクレイピングAPI: 1,000 URLsあたり$0.8から
- Webアンロッカー: 1,000 URLsあたり$0.2
- プロキシ: 1GBあたり$2.8
無料トライアルとさらに割引を受けるためにコミュニティに参加しよう!
ボット検出を回避する:Scrapeless CAPTCHA Solverガイド
- ステップ1. Scrapelessにサインイン。
- ステップ2. "CAPTCHA Solver"インターフェースに入る。reCAPTCHAの解除サービスをクリックし、適応する必要があるreCAPTCHAのタイプを選択します:通常またはエンタープライズ。
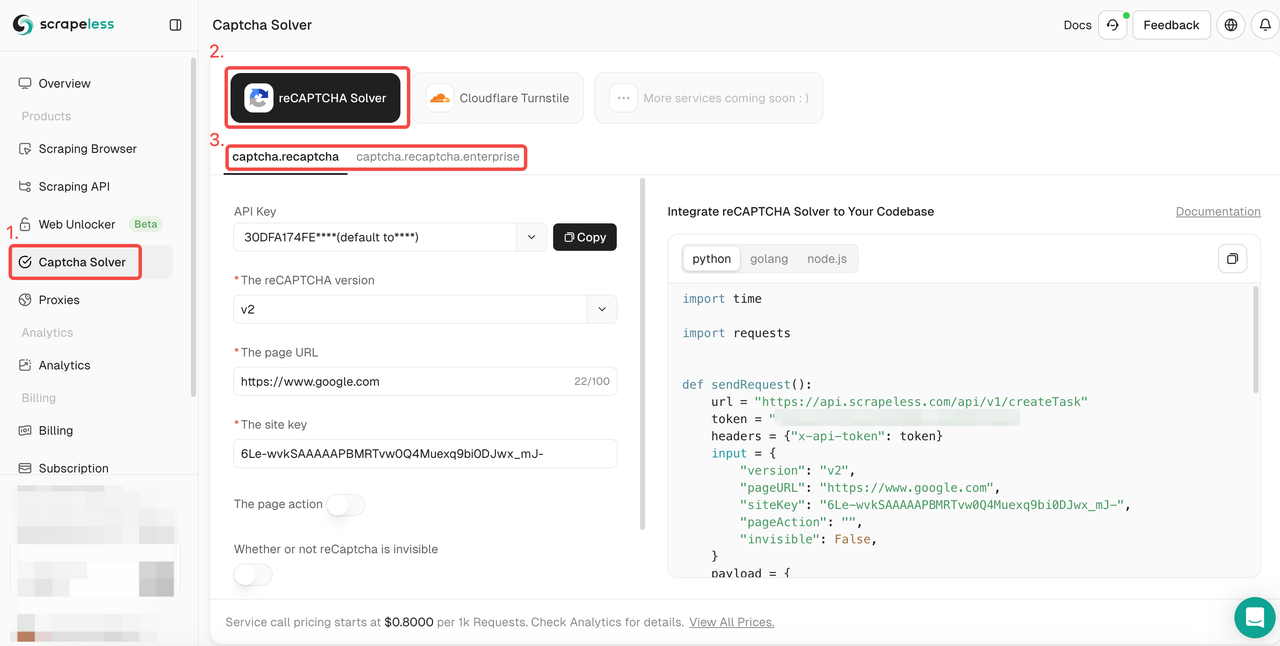
- ステップ3.左側の操作ボックスに必要な関連情報を設定します:reCAPTCHAバージョン、ページURL、サイトキー、アクション、プロキシなど。
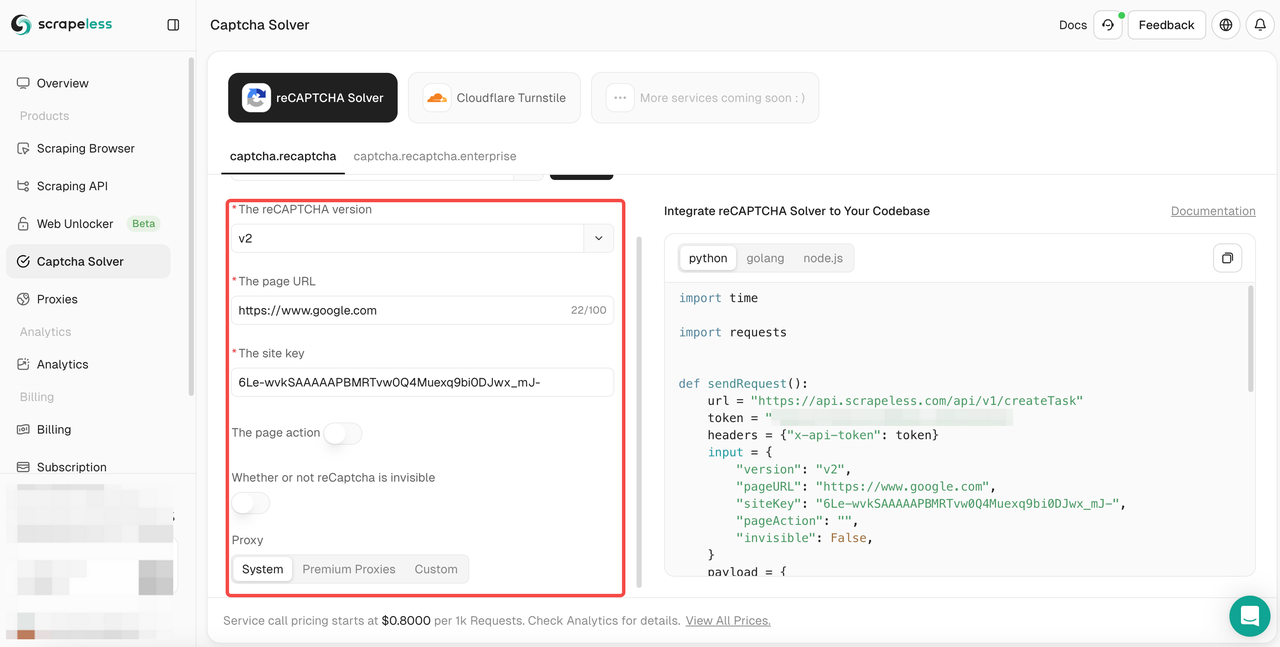
- ステップ4. 設定が完了したら、右側のコードボックスで関連するコードフィードバックを取得できます。それをコピーして、あなたのプログラムに統合するだけです。ここでは、scrapeless.comのスクレイピングを例に取ります。v2のreCAPTCHAを解除し、プレミアムプロキシを使用し、"シンガポール"に設定し、ページアクションを"スクレイピング"に設定します。以下は私が得たコードフィードバックです:
Python
import time
import requests
def sendRequest():
url = "https://api.scrapeless.com/api/v1/createTask"
token = "xxx"
headers = {"x-api-token": token}
input = {
"version": "v2",
"pageURL": "https://www.scrapeless.com/en",
"siteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-",
"pageAction": "scraping",
"invisible": False,
}
payload = {
"actor": "captcha.recaptcha",
"input": input
}
# タスクを作成
result = requests.post(url, json=payload, headers=headers).json()
taskId = result.get("taskId")
if not taskId:
print("タスクの作成に失敗しました:", result)
return
print(f"タスクを作成しました: {taskId}")
# 結果をポーリング
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + taskId
resp = requests.get(url, headers=headers)
result = resp.json()
if resp.status_code != 200:
print("タスクが失敗しました:", resp.text)
return
if result.get("success"):
return result["solution"]["token"]
data = sendRequest()
print(data)actor: 現在のタスクのアクターstate: 現在のタスクの状態success: タスクが成功したかどうかtaskId: タスクが成功裏に作成されると、taskIdが取得できます。その後、このtaskIdを使用して結果を照会する必要がありますsolution: タスクが成功した場合、解決策が受け取られますmessage: タスクが失敗した場合、このエラーメッセージを確認してください
詳細については、ドキュメントチュートリアルをご覧ください。
CAPTCHAソルバーを利用したアンチボット回避のための高度な戦略
CAPTCHAのようなアンチボット対策を回避するには、尊重あるスクレイピングと高度な技術の組み合わせが必要です。スクレイピング操作を効率的かつ倫理的に保つ方法を紹介します。
尊重あるスクレイピングの実践
- robots.txtを遵守する: いつもウェブサイトの
robots.txtファイルを確認して、何をスクレイピングすることができるかのガイドラインに従ってください。 - リクエストレートを制限する: リクエスト間にランダムな遅延を導入して、人間のブラウジング行動を模倣し、ブロックを引き起こす迅速な連続リクエストを避けます。
- ユーザーエージェントを回転させる: 現実的なユーザーエージェントのプールを使用して、異なるブラウザやデバイスをシミュレートし、静的なユーザーエージェント文字列からの検出を防ぎます。
進化的な技術
- レジデンシャルプロキシ: 複数のIPアドレスにリクエストを分散させるためにレジデンシャルプロキシを使用し、ウェブサイトがあなたをブロックするのを難しくします。
- ヘッドレスブラウザ: PuppeteerやSeleniumのようなツールは、実際のユーザーのインタラクションをシミュレートし、アンチボットシステムがあなたのスクレイピング活動を検出するのを困難にします。
- 検出回避のための機械学習: ブラウジングパターンを分析して、ボットが人間の行動をより正確に再現するように学習させ、ボットとしてフラグが立つ確率を減らします。
まとめ
おめでとうございます!あなたはアンチボット検出について多くを学びました。基礎から高度なアンチ検出の達人になるまで成長しました!
今あなたは以下を知っています:
- アンチボットが何であるか。
- アンチボット技術を回避するためのいくつかのベストプラクティス。
- アンチボットが依存する最も一般的なメカニズムのいくつか。
- それらすべてを回避する方法。
さらに詳しいアンチスクレイピング技術を発見できますが、どんなに高度なスクレイパーでも、一部の技術はまだそれを阻止できるでしょう。
これらのすべての問題は、先進的なプロキシ、内蔵IP回転、ヘッドレスブラウザ機能、高度なアンチボット回避機能を持つウェブスクレイピングAPIであるScrapelessを使用することで回避できます。ウェブをスクレイピングするためのシンプルな方法です。
今すぐ無料トライアルを開始しましょう!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


