
2025年におけるCloudflareチャレンジの回避方法:完全ガイド
Advanced Data Extraction Specialist
Cloudflareは常にセキュリティ対策を進化させており、従来のスクレイピング手法では、cloudflare-challengeやCloudflare Turnstileなどの対策を回避することがますます困難になっています。FlareSolverrなどのオープンソースツールは、Cloudflareのアップデートにより効果がなくなっているため、開発者は新しいソリューションを探しています。
このガイドでは、2025年におけるCloudflareセキュリティ対策の回避方法として、最も効果的な方法を解説します。以下を含みます。
- Scrapeless Scraping Browser – シームレスなスクレイピングのためのヘッドレスブラウザAPI
- Scrapeless Web Unlocker – JSレンダリングと操作のための堅牢なAPI
Web自動化のエキスパートでも初心者でも、このガイドは、障害にぶつかることなくデータ抽出を行うための段階的なソリューションを提供します。
PART1: Cloudflareのチャレンジとセキュリティレイヤーの理解
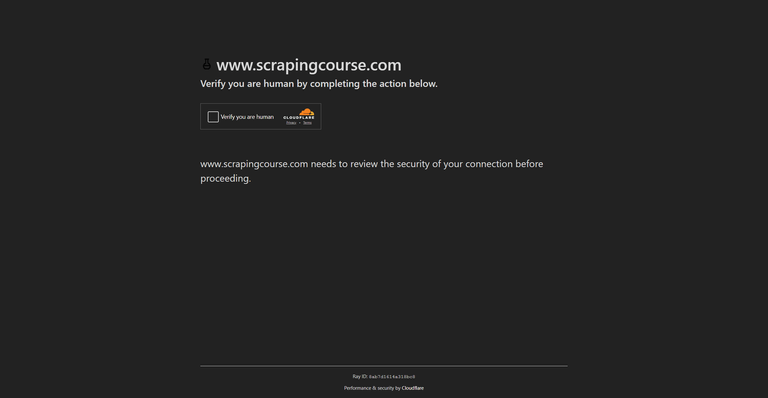
ソリューションに進む前に、自動化されたリクエストをブロックするCloudflareの主要なセキュリティメカニズムを理解することが重要です。
1. Cloudflare JSチャレンジ
Cloudflare JavaScriptチャレンジ(cloudflare-challenge)では、要求されたページにアクセスする前に、ブラウザでスクリプトを実行する必要があります。このスクリプトは、Cookie(cf_clearance)に保存されるクリアランストークンを生成します。JavaScript実行機能のないボットやスクレイパーは、このチャレンジに失敗します。
2. Cloudflare Turnstile
Turnstileは、CloudflareのCAPTCHA代替手段であり、非人間トラフィックを動的に検出します。完了するには、JavaScriptの実行と行動追跡が必要になることが多いです。
3. ブラウザフィンガープリンティング
Cloudflareは、高度なフィンガープリンティングを使用して、非人間的な操作を検出します。これには、以下の分析が含まれます。
- TLSフィンガープリンティング(JA3シグネチャ)
- HTTPヘッダーとその順序
- WebGL、Canvas、およびAudio Fingerprinting
4. レート制限とIPバン
一度チャレンジを回避しても、同じIPからの繰り返しリクエストにより、バンが発生したり、セキュリティレベルが向上したりすることがあります。
PART2: Cloudflare JSチャレンジが他のチャレンジと異なる点
ユーザーの操作が必要なCAPTCHAとは異なり、JSチャレンジはバックグラウンドで自動的に実行されるため、正当なユーザーにとっては邪魔になりにくく、疑わしいトラフィックをブロックできます。しかし、ウェブスクレイパーや自動化ツールにとっては、多くの基本的なHTTPクライアントやヘッドレスブラウザはJavaScriptを正しく実行できないため、JSチャレンジの回避は困難になる可能性があります。
PART3: Scrapeless Scraping Browserを使用したCloudflare JSチャレンジの回避
3.1 Scrapeless Scraping Browserとは
Scrapeless Scraping Browserは、独自のインフラストラクチャを維持することなくJavaScriptチャレンジを回避できるヘッドレスブラウザ環境を提供する高性能ソリューションです。PuppeteerとPlaywrightとシームレスに統合して自動化できます。
Scrapeless Scraping Browserは、最も高度なCloudflareバイパストゥールであり、以下を提供します。
✔️ Cloudflareチャレンジの回避成功率99.9%
✔️ Puppeteer / Playwrightとのシームレスな互換性
✔️ AI駆動型、最新のセキュリティポリシーに自動的に適応
✔️ グローバルプロキシサポート、バンのリスク軽減
3.2 セットアップとAPIキーの設定
Scrapeless Scraping Browserを使用する前に、APIキーを取得します。
- サインアップ Scrapelessダッシュボードで
- 設定タブからAPIキーを取得します
🎁 新規ユーザーには、無料で10,000件のAPIリクエストを提供します!今すぐサインアップ
3.3 Scrapeless Browserを使用したCloudflareバイパスの実装
Scrapeless Browserless WebSocketへの接続
Scrapelessは、Puppeteerがヘッドレスブラウザと直接やり取りし、Cloudflareチャレンジを回避できるWebSocket接続を提供します。
👉 完全なWebSocket接続アドレス:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYコードサンプル:Cloudflareチャレンジの回避
Scrapelessのbrowserlessサービスに接続するには、以下のコードを準備するだけです。
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // ブラウザセッションのライフサイクル(秒単位)
proxy_country: 'GB', // エージェントの国
proxy_session_id: 'test_session_id', // プロキシセッションIDは、プロキシIPを不変に保つために使用されます。セッション時間はデフォルトで3分です(proxy_session_duration設定に基づきます)。
proxy_session_duration: '5' // エージェントセッション時間(分単位)
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')📢 今すぐScrapelessを無料で試して、簡単にCloudflareを回避しましょう! 👉 今すぐサインアップ
Cloudflare保護されたウェブサイトへのアクセスとスクリーンショットによる検証
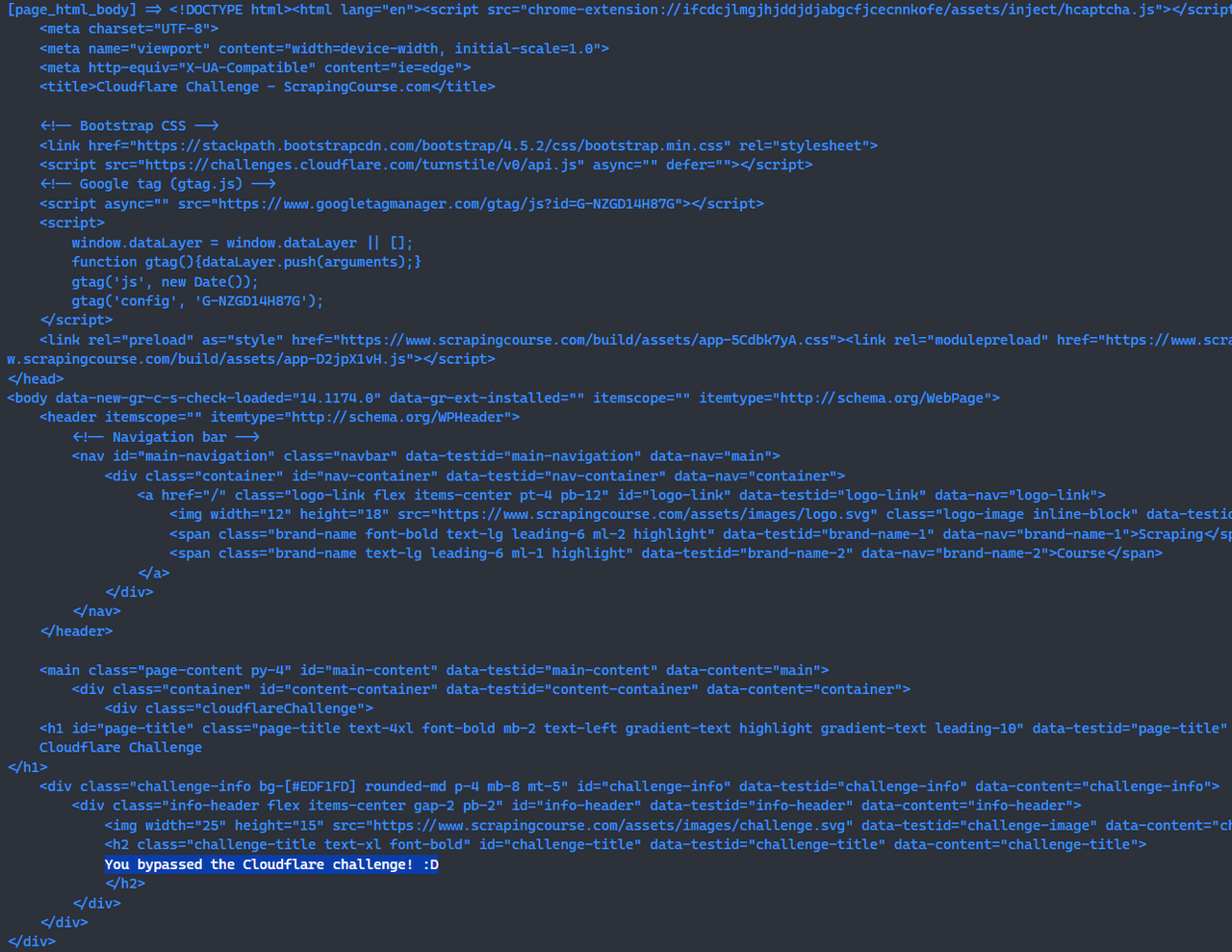
次に、scrapeless browserlessを使用して、cloudflare-challengeテストサイトに直接アクセスし、スクリーンショットを追加します。これにより、効果を非常に直感的に確認できます。スクリーンショットを撮る前に、ページの要素を待つためにwaitForSelectorを使用する必要があることに注意してください。これにより、Cloudflareチャレンジが正常に回避されたことが保証されます。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// サイトページの要素を待つことで、Cloudflareチャレンジが正常に回避されたことを保証します。
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});おめでとうございます!🎉 scrapeless browserlessでCloudflareチャレンジを回避しました。

cf_clearanceCookieとヘッダーの取得
さらに、Cloudflareチャレンジに合格した後、成功ページからリクエストヘッダーとcf_clearance Cookieを取得することもできます。
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueリクエストインターセプトをオンにしてリクエストヘッダーを取得し、Cloudflareチャレンジ後のページリクエストを一致させます。
await page.setRequestInterception(true);
page.on('request', request => {
// Cloudflareチャレンジ後のページリクエストを一致させる
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});PART4: Scrapeless Scraping Browserを使用したCloudflare Turnstileの回避
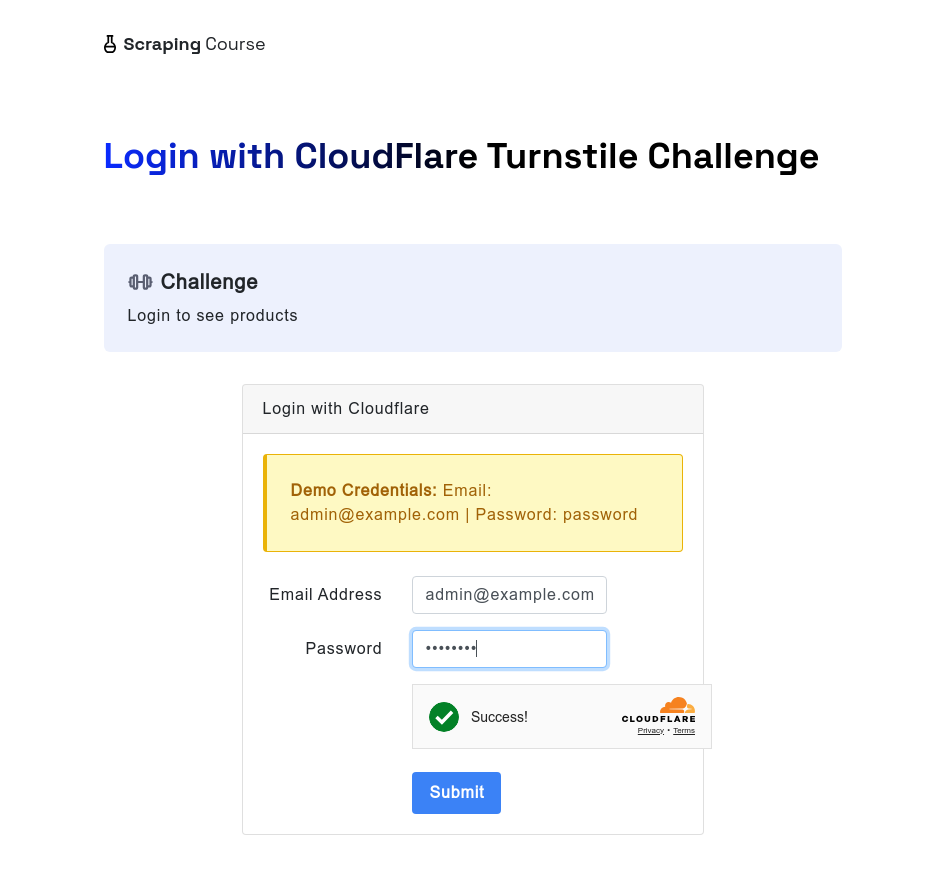
同様に、Cloudflare Turnstileに遭遇した場合でも、scrapelessブラウザは自動的に処理できます。以下の例では、cloudflare-turnstileテストサイトにアクセスします。ユーザー名とパスワードを入力した後、waitForFunctionメソッドを使用してwindow.turnstile.getResponse()からのデータが取得されるまで待機し、チャレンジが正常に回避されたことを確認します。その後、スクリーンショットを撮り、ログインボタンをクリックして次のページに移動します。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Turnstileが正常にロック解除されるまで待機します
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });このスクリプトを実行すると、スクリーンショットを通じてロック解除の効果を確認できます。
PART5: JavaScriptレンダリングのためのScrapeless Web Unlockerの使用
Scrapeless Web Unlockerは、JavaScriptレンダリングと動的な操作を可能にするため、Cloudflareを回避する効果的なツールです。
JavaScriptレンダリング
JavaScriptレンダリングにより、動的に読み込まれたコンテンツとSPA(シングルページアプリケーション)を処理できます。より複雑なページの操作とレンダリング要件をサポートする完全なブラウザ環境を実現します。
js_render=trueを使用すると、ブラウザを使用してリクエストを行います
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}JavaScript命令
ウェブページと動的にやり取りできる広範なJavaScriptディレクティブを提供します。
これらのディレクティブを使用すると、要素をクリックしたり、フォームに入力したり、フォームを送信したり、特定の要素が表示されるまで待機したりできます。「詳細を読む」ボタンをクリックしたり、フォームを送信したりするなど、柔軟なタスクを実行できます。
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"js_instructions": [
{
"wait_for": [
".dynamic-content",
30000
]
// 要素を待機
},
{
"click": [
"#load-more",
1000
]
// 要素をクリック
},
{
"fill": [
"#search-input",
"search term"
]
// フォームに入力
},
{
"keyboard": [
"press",
"Enter"
]
// キー押下をシミュレート
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// カスタムJSを実行
}
]
}
}チャレンジ回避例
次のサンプルコードは、axiosを使用してScrapelessのWeb Unlockerサービスへのリクエストを行います。js_renderを有効にし、js_instructionsパラメータのwait_forディレクティブを使用して、Cloudflareチャレンジが回避された後のページの要素を待機します。
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
js_instructions: [
{
wait_for: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();🎉 上記のスクリプトを実行すると、コンソールでCloudflareチャレンジを正常に回避したページのHTMLが表示されます。
Scrapeless – より強力な動的ウェブサイトアンロックソリューション
動的ウェブサイト、Ajax読み込み、シングルページアプリケーション(SPA)の場合、ScrapelessはWeb Unlockerを提供し、Cloudflareチャレンジを自動的に解決して、ロボットとして検出されるのを回避できます。
✅ AI駆動型の自動回避、Cloudflareの反クロールアップデートへの適応
✅ グローバルプロキシプールサポート、IP制限の安定した回避
✅ Puppeteer / Playwrightとのシームレスな互換性
💡 今すぐScrapeless Web Unlockerを試して、動的ウェブサイトのデータを簡単にクロールしましょう! 👉 今すぐ体験
Cloudflareチャレンジに関するFAQ
Q:Cloudflareチャレンジとは何ですか?
A:Cloudflareチャレンジは、ボット攻撃やDDoS攻撃などの悪意のある活動からウェブサイトを保護するために使用されるセキュリティ対策です。Cloudflareが疑わしい動作を検出すると、訪問者にチャレンジを提示して、正当なユーザーであることを確認します。
Q:Cloudflareで保護されたサイトでチャレンジされるのはなぜですか?
A:IPアドレスに関連付けられた脅威スコアが高い、IPからの疑わしいアクティビティの履歴がある、ボットのような自動化されたトラフィックが検出された、または地域やユーザーエージェントを対象とするウェブサイトの所有者によって設定された特定のルールなど、いくつかの理由でチャレンジされる可能性があります。Cloudflareは、ブラウザが特定の標準を満たしていることも確認します。
Q:Cloudflareチャレンジにはどのような種類がありますか?
A:Cloudflareは、マネージドチャレンジ、JSチャレンジ、インタラクティブチャレンジなど、さまざまな種類のチャレンジを使用しています。マネージドチャレンジは推奨されており、Cloudflareはリクエストの特性に基づいて適切なチャレンジの種類を動的に選択します。JSチャレンジは、ブラウザによるJavaScript処理が必要なページを表示します。インタラクティブチャレンジでは、訪問者はパズルを解くためにページとやり取りする必要があります。
Q:マネージドチャレンジとは何ですか?
A:マネージドチャレンジは、Cloudflareがリクエストの特性に基づいて適切なチャレンジの種類を選択する動的システムです。これには、非インタラクティブなチャレンジページ、カスタムインタラクティブチャレンジ、またはプライベートアクセストークンが含まれる場合があります。目標は、CAPTCHAの使用を最小限に抑え、ユーザーがCAPTCHAを解決するために費やす時間を短縮することです。
今すぐScrapeless Discordコミュニティに参加しましょう!🚀 エキスパートスクレイパーとつながり、Cloudflareチャレンジの回避に関する独占的なヒントを入手し、最新の機能を最新の状態に保ちましょう。クリック ここで今すぐ参加できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


