
2025年、WebスクレイピングAPIベスト5
Advanced Data Extraction Specialist
ウェブスクレイピングAPIは、インターネット上のウェブサイトからデータを自動的に抽出するように設計された強力なツールです。その主な目的は、企業、研究者、開発者が様々なオンラインソースから貴重な情報を収集し、整理するのを支援することです。これらのAPIは、大量のウェブデータを効率的に処理するために不可欠であり、組織が手動による介入なしに正確で関連性の高いインサイトにアクセスできるようにします。
データ抽出の具体的なユースケースに関係なく、現在利用可能な最高のウェブスクレイピングAPIのリストをまとめました。各APIは、その機能、費用対効果、および全体的なパフォーマンスに基づいて徹底的に評価されています。SEOの強化、データ収集プロセスの合理化、または包括的な調査の実施を検討している場合でも、これらのウェブスクレイピングAPIはニーズに対応できます。
2025年最高のウェブスクレイパー
- Scrapeless – 全体的に最高のウェブクローラー
- Scrapy – 高度なオープンソースクローラー
- DYNO Mapper – SEOに特化したビジュアルクローラー
- Oncrawl – テクニカルSEOウェブクローラー
- Node Crawler – JavaScriptベースのウェブクローラー
では、これらのウェブスクレイピングAPIプロバイダーが際立っている理由、およびウェブスクレイピングのニーズにそれらを検討する必要がある理由について詳しく見ていきましょう。
Scrapeless
ScrapelessのウェブスクレイパーAPIは、ターゲットウェブサイトから関連データを効率的に抽出するように設計されています。必要な正確な情報を収集するために、自動的にウェブを閲覧します。AIエージェントテクノロジーとBrowserless統合を組み合わせることで、Scrapelessは手動コーディングなしで強力なウェブスクレイピングツールを作成します。AIエージェントはスクレイピングタスクを最適化することでスクレイピングプロセスを強化し、Browserlessはヘッドレスブラウザ操作を処理して、動的なウェブサイトからのスムーズなデータ収集を保証します。
Scrapelessのウェブクローラーを使用すると、ユーザーはクロール戦略と範囲を完全に制御できます。クローラーは開始ページからリンクを体系的にたどり、すべてのページがインデックス付けされるまで、サイトのアクセス可能なすべてのページをトラバースします。
利点:
- 高い成功率:最小限のエラーで正確で信頼性の高いデータ抽出を提供します。
- スケーラビリティ:大規模なデータ収集を効率的に処理するため、大規模なウェブサイトに適しています。
- AI搭載機能:人工知能を活用してウェブスクレイピングタスクの効率を向上させます。
- Browserless統合:ヘッドレスブラウジングテクノロジーを使用して、動的でJavaScriptを多用したウェブサイトをシームレスにスクレイピングします。
- 倫理的なデータ収集:倫理的でコンプライアンスに準拠した運用を確保するために、データスクレイピングのベストプラクティスに従います。
欠点:
- 学習曲線:新しいユーザーは、Scrapelessの高度な機能をすべて完全に理解して利用するために時間が必要になる場合があります。
価格:
- 無料トライアル
Scrapelessの無料トライアルを入手する方法?
Scrapelessの無料トライアルを入手するには、Scrapelessダッシュボードにログインするだけです。ログインしたら、ダッシュボードから直接無料トライアルを請求するオプションが表示されます。簡単で直接的なプロセスであり、すぐにツールを使い始めることができます。
ScrapelessのスクレイピングAPIの費用はいくらですか?
ScrapelessのスクレイピングAPIは、1000 URLあたり1ドルから始まります。さらに、Scrapelessは、わずか1〜2秒で処理される検索クエリを提供する、最も手頃で高速なSERP APIの1つを提供しています。これらの検索クエリへの価格は、1000クエリあたり0.30ドルと低く、市場で最も費用対効果の高いソリューションの1つとなっています。
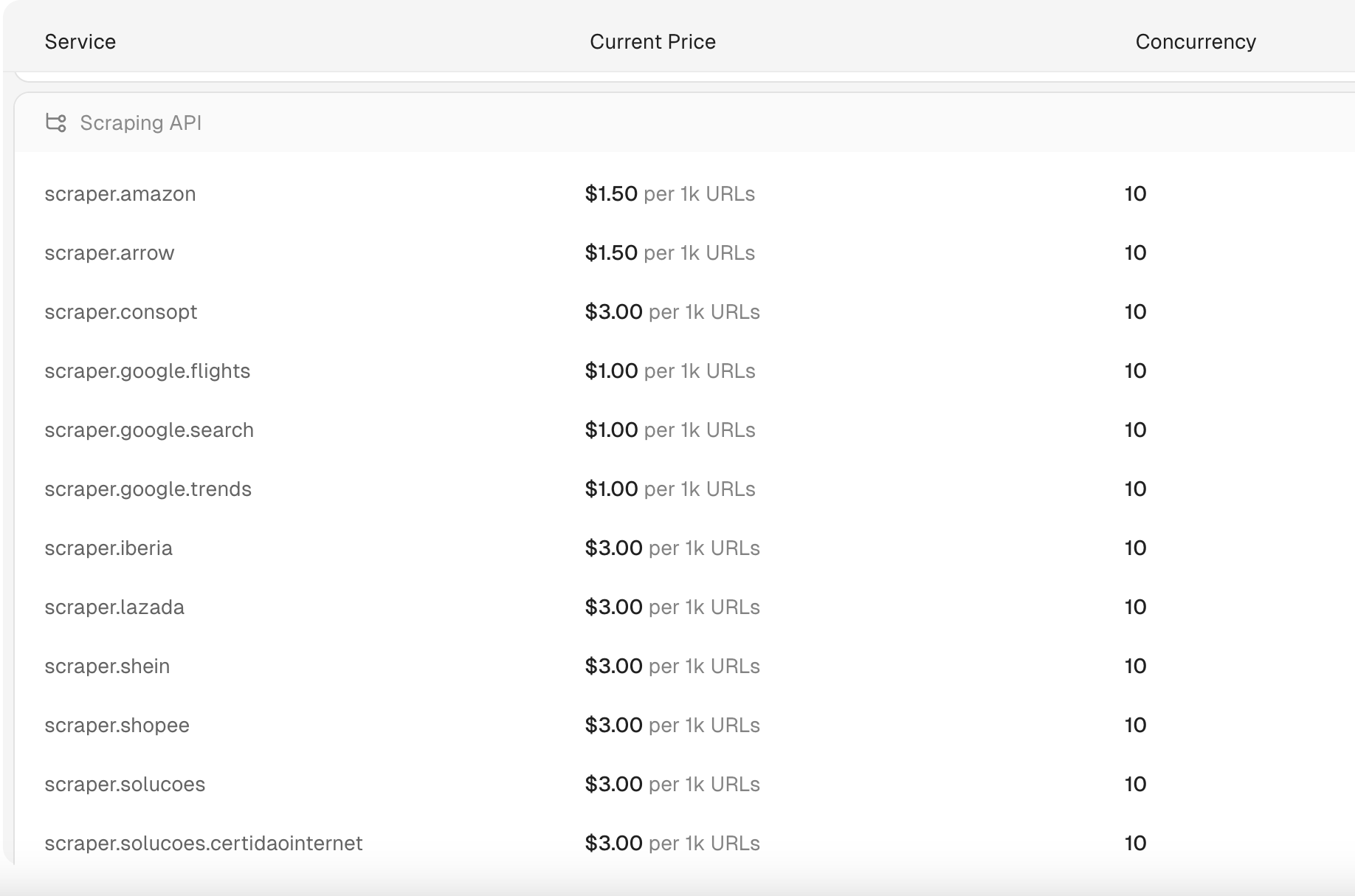
注記:
- 請求はリクエスト単位で適用されます。
- 成功したリクエストのみが請求されます。
ScrapelessのスクレイピングAPIを使用してShopeeデータを取得する方法
ScrapelessのスクレイピングAPIを使用してShopeeデータのスクレイピングを行うには、一般的に次の手順に従う必要があります。ウェブスクレイピングには法的および倫理的な問題が含まれる場合があるため、Shopeeの利用規約を確認し、適用される法律に準拠していることを確認してください。
ステップ1. Scrapeless APIにサインアップする
Scrapelessアカウントにログインしてください。ログイン後、APIキーを取得します。
ステップ2. スクラピングプランを選択する
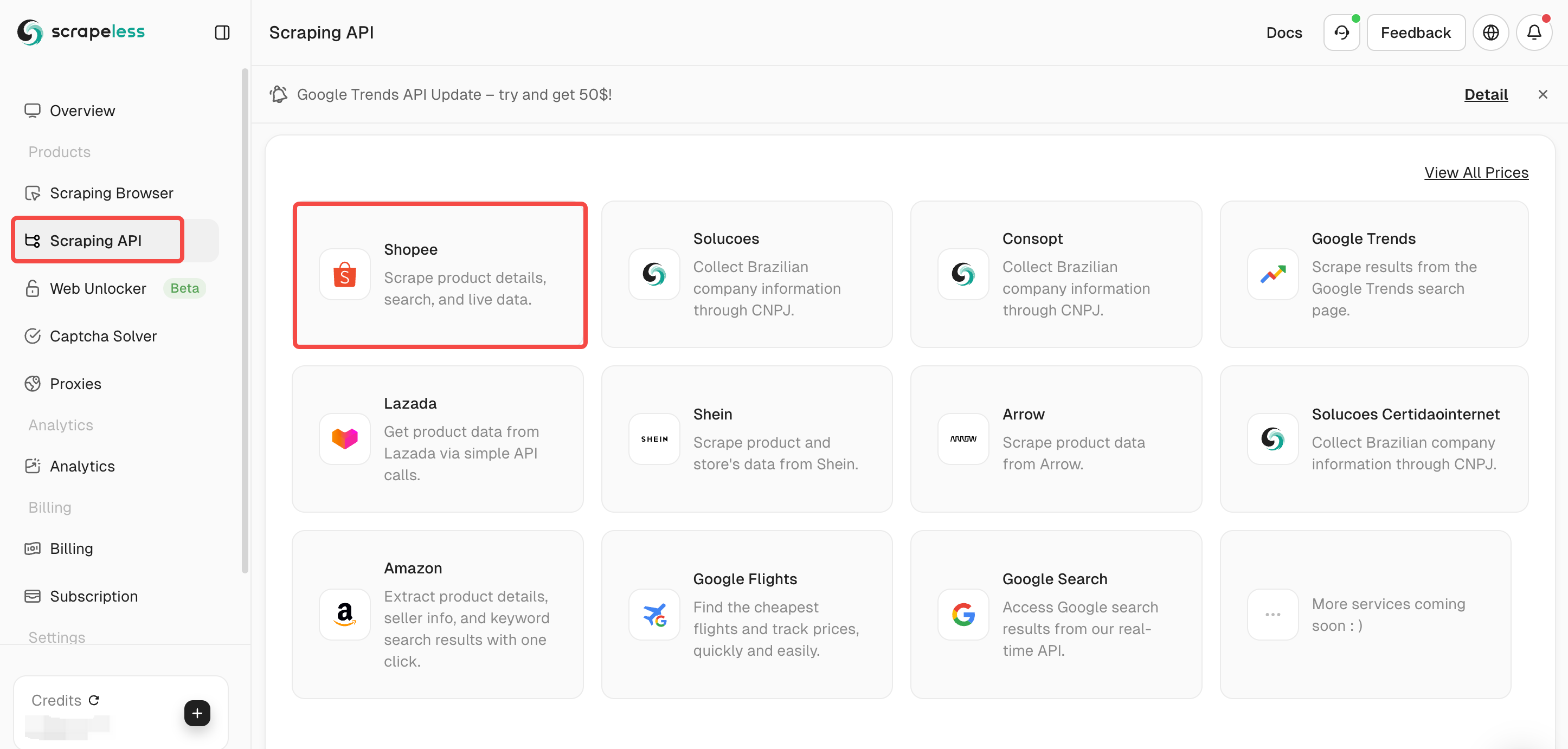
ダッシュボードで「スクレイピングAPI」を選択し、次に「Shopee」を選択します。
Scrapelessは、Lazada /Shein /Google検索/Google Flightsなどの複数のスクレイピングAPIを提供しています。
ステップ3. ShopeeスクレイピングAPIのパラメータを構成します。「スクレイピング開始」をクリックすると、右側のペインに出力結果データが表示されます。
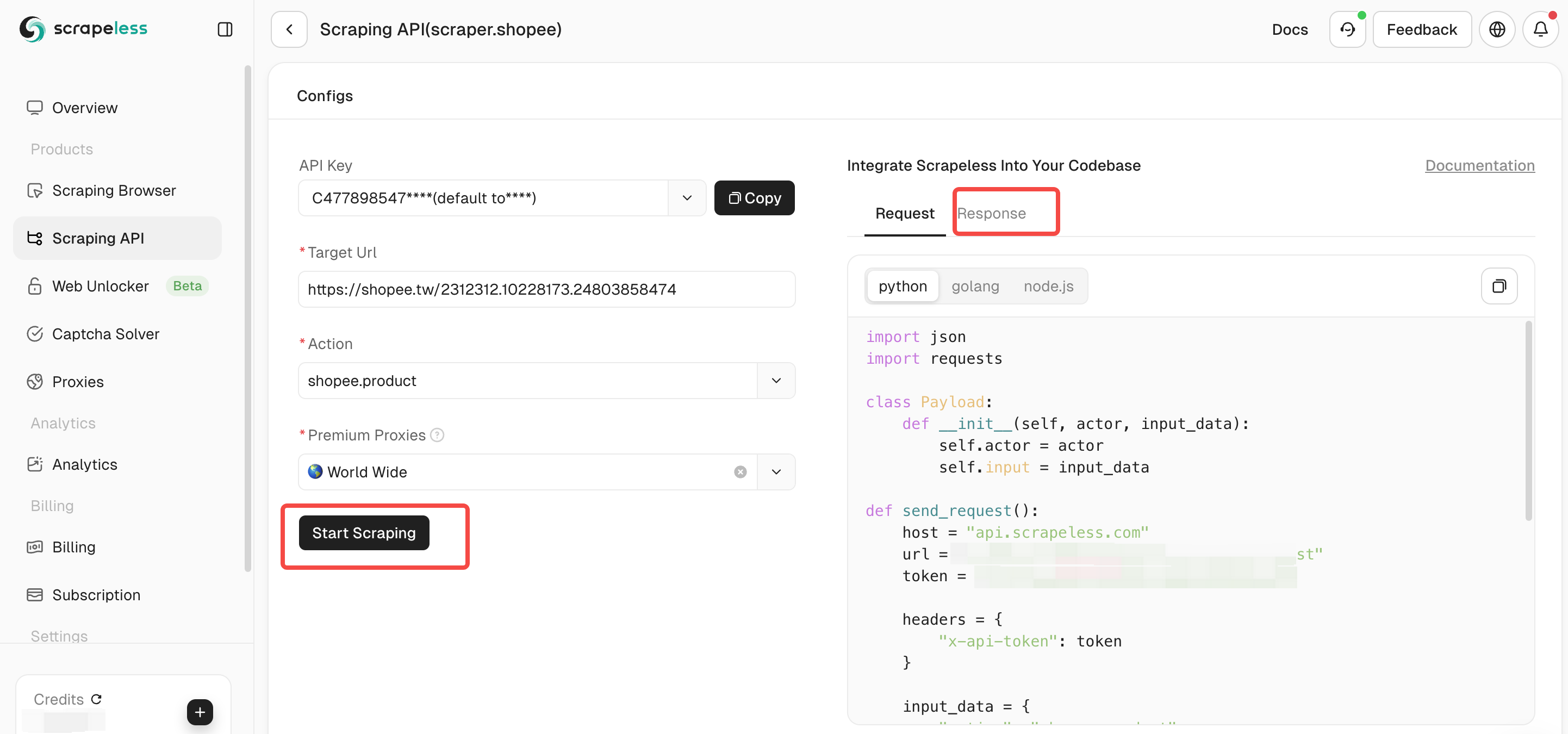
Scrapelessをプロジェクトに統合する方法
Scrapelessをプロジェクトに統合することで、クロール効率を効果的に向上させることができます。Scrapelessは、ウェブスクレイピングとデータ抽出タスクによく使用されます。以下は、Scrapelessをプロジェクトに統合するコード例です。もちろん、Scrapelessの完全なドキュメントも確認できます。
Shopee商品
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee検索
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopeeライブ
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.live",
"url": "https://live.shopee.co.th/api/v1/session/{sessionId}"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Rcmd
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.rcmd",
"url": "https://shopee.co.th/api/v4/shop/rcmd_items?bundle=shop_page_category_tab_main&item_card_use_scene=category_product_list_topsales&limit=30&offset=0&shop_id=1195212398&sort_type=13&upstream="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee評価
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.ratings",
"url": "https://shopee.ph/api/v2/item/get_ratings?exclude_filter=1&filter=0&filter_size=0&flag=1&fold_filter=0&itemid=23760784194&limit=6&offset=0&relevant_reviews=false&request_source=2&shopid=29975023&tag_filter=&type=0&variation_filters="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Scrapy
Scrapyは、Pythonで構築された人気のあるオープンソースのウェブクロールフレームワークであり、ウェブスクレイピングAPIを介してウェブスクレイピングとデータ抽出を容易にするように設計されています。「スパイダー」を中心とした整理されたシステムを活用することで、開発者は堅牢でスケーラブルなクローラーを構築するためのツールを提供します。「スパイダー」とは、データのターゲットを絞るための具体的な指示を含む、自己完結型のクロールユニットです。
「繰り返さない」(DRY)原則に従って、Scrapyはコードの再利用性を促進し、大規模なクロール操作をスケーリングするための効率的な選択肢となります。その汎用性のおかげで、Scrapyは高度なスクレイピングタスクに取り組んでいる開発者やデータサイエンティストに好まれています。
利点:
- オープンソーススクレイピングライブラリ:BSDライセンスの下で無料で利用でき、活気のあるコミュニティからの貢献があります。
- 開発者とデータサイエンティストに最適:強力なカスタマイズオプションとスクレイピングプロセスの完全な制御を提供します。
欠点:
- 初心者には難しい:Pythonとウェブスクレイピングの概念の深い理解が必要であり、この分野の初心者にとっては障壁となる可能性があります。
- リソースを消費する:特に大規模なスクレイピングプロジェクトを扱う場合、かなりのシステムリソースを消費する可能性があります。
- 新参者にはあまりユーザーフレンドリーではない:複雑さとコーディングの専門知識が必要なため、ウェブスクレイピングの初心者を圧倒する可能性があります。
価格:
- 無料
必要になるかもしれません:ウェブスクレイピングの課題を解決する方法-完全ガイド2025
DYNO Mapper
DYNO Mapperは、内部リンクに従ってウェブサイトをクロールし、検索エンジンのボットの動作を模倣する、直感的なビジュアルサイトマップジェネレーターです。クロール後、ウェブサイトの構造を示すビジュアルサイトマップを生成し、ユーザーはサイトのナビゲーションをよりよく理解できます。このツールは、インタラクティブなビジュアルサイトマップ、HTML、CSV、XML、PDF、JSON、Excel(XLSX)など、複数の出力形式をサポートしています。サイトマップ機能に加えて、DYNO Mapperは、コンテンツインベントリと監査機能、およびADAウェブサイト標準への準拠を確保するためのアクセシビリティテストを提供します。また、高度なデータ抽出ニーズのためにウェブスクレイピングAPIとシームレスに統合されるため、コンテンツ管理に最適なウェブクローラーの1つとなっています。
利点:
- 複数の出力形式:複数の形式でデータを提供することで柔軟性を高め、情報の使いやすさを向上させます。
- コンテンツインベントリと監査ツール:パフォーマンス向上のためのウェブサイトコンテンツの整理と最適化を合理化します。
欠点:
- 無料プランの制限:無料プランでは機能が制限されており、すべてのユーザーのニーズを満たせない可能性があります。
- マスターするのが複雑:高度な機能をすべて完全に理解して使用するには、時間と労力が必要です。
価格:
- 無料トライアルあり。最も手頃なプランは月額39ドルから。
Oncrawl
Oncrawlは、SEOとテクニカルなウェブサイト分析のために調整された強力なウェブクロールツールです。詳細なSEO監査、カスタマイズ可能なダッシュボード、大規模なウェブサイトのためのスケーラブルなソリューションを提供するため、デジタルマーケティング戦略の重要なリソースとなります。最高のウェブクローラーの1つとして、Oncrawlは企業がオンラインプレゼンスを効率的に分析および改善することを可能にします。さらに、データ抽出機能を強化するためにウェブスクレイピングAPIと統合されます。
利点:
- 徹底的なSEO監査:ウェブサイトのSEOパフォーマンスに関する包括的な洞察を提供します。
- カスタマイズ可能なダッシュボードとレポート:ユーザーは、特定の要件に合わせてレポートとダッシュボードをパーソナライズできます。
欠点:
- 小規模なウェブサイトのクロール制御が制限されている:小規模なサイトでは、クロール設定の柔軟性が低くなる可能性があります。
- 急な学習曲線:Oncrawlのすべての機能を完全に理解して活用するには時間が必要です。
価格:
- 月額69ドルから
Node Crawler
Node Crawlerは、Node.js用に設計された人気のあるウェブクロールライブラリであり、その柔軟性と使いやすさで広く知られています。Cheerioをデフォルトのパーサーとして使用することで、高速で効率的なHTMLのパースと操作を提供します。このライブラリは、並行処理、レート制限、自動再試行の処理のためのキュー管理など、多数のカスタマイズオプションを提供するため、ウェブスクレイピングプロジェクトに強力なツールとなります。
軽量な性質のおかげで、Node Crawlerはメモリ消費を最小限に抑えるため、大量のリクエストを処理する場合でも、高性能なタスクに最適です。Node.js開発者にとって最高のウェブクローラーの1つとして、JavaScriptベースのワークフローに完全に統合され、ウェブスクレイピングAPIをシームレスに使用できます。
利点:
- Node.js開発者に最適:JavaScript環境に簡単に統合されるため、Node.jsに精通した開発者にとって最適な選択肢となります。
- 効率的で軽量:パフォーマンスを念頭に置いて設計されており、複数のリクエストを処理する場合でも、低メモリ使用率を保証します。
欠点: - ネイティブJavaScriptレンダリングなし:デフォルトではJavaScriptレンダリングをサポートしていないため、動的コンテンツをスクレイピングするには追加のツールや構成が必要になる場合があります。
価格:
- 無料
最高のウェブスクレイピングツールの比較
| プロバイダー | 最高の機能 |
|---|---|
| Scrapeless | スケーラブルで倫理的なウェブスクレイピングとウェブクロールのための高度なプロキシインフラストラクチャと住宅用IP。 |
| Scrapy | カスタムウェブクローラーとスクレイパーを構築するための強力なオープンソースPythonフレームワーク。 |
| DYNO Mapper | ウェブサイトの最適化と構造分析のためのビジュアルサイトマップの作成とSEO監査に重点を置いています。 |
| Oncrawl | ウェブサイトのアーキテクチャ、クロール予算、ログファイルに関する高度な分析を備えた、テクニカルSEOに重点を置いたウェブクローラー。 |
| Node Crawler | 動的コンテンツを持つ最新のウェブサイトに最適な、Node.js上に構築された柔軟なJavaScriptベースのクローラー。 |
ウェブスクレイピングとは?
ウェブスクレイピングは、ウェブサイトからデータを自動的に抽出するために使用される手法です。このプロセスには、いくつかの重要な手順が含まれています。
定義
ウェブスクレイピングは、ウェブハーベスティングまたはウェブデータ抽出とも呼ばれ、ウェブページから情報を取得および収集する自動化された方法を指します。通常、インターネットにアクセスし、ウェブページをダウンロードし、分析またはデータベースへの保存など、さまざまな目的のために特定のデータを抽出できるソフトウェアツールまたはスクリプトを使用することを含みます。
ウェブスクレイピングの仕組み
- リクエスト:このプロセスは、ブラウザにURLを入力するのと同じように、ウェブサイトのサーバーにリクエストを送信することから始まります。
- レスポンス:サーバーは、テキスト、画像、その他の種類のデータを含む可能性のある要求されたウェブページを提供することによって応答します。
- パース:次に、ウェブスクレイピングツールはページのHTMLコンテンツを分析して、製品価格、連絡先情報、その他の関連する詳細など、特定のデータポイントを見つけ出し、抽出します。
- ストレージ:最後に、抽出されたデータは、CSV、Excel、またはデータベースなど、後で使用する構造化された形式で保存されます。
ウェブスクレイピングの用途
ウェブスクレイピングは、さまざまな業界で幅広い用途があります。
- 市場調査:競合他社の価格と製品情報を収集します。
- リードジェネレーション:営業およびマーケティング活動のための連絡先情報を収集します。
- 価格監視:さまざまな小売業者間で製品の価格の変更を追跡します。
- コンテンツ集約:複数のソースからニュース記事や製品レビューをまとめます。
ウェブクロールとの違い
ウェブスクレイピングとウェブクロールは関連する概念ですが、異なる目的を果たします。ウェブクロールは、主にインターネット全体でリンクに従うことによってウェブページを発見し、インデックスを作成することに重点を置いています。一方、ウェブスクレイピングは、アクセスされたページからデータを抽出することを具体的に対象としています。
まとめ
結論として、適切なウェブスクレイピングAPIを選択することは、ウェブから貴重なデータを抽出して活用しようとする企業や開発者にとって非常に重要です。2025年のトップ5のウェブスクレイピングAPIは、スケーラビリティ、使いやすさ、高度なデータ処理機能など、さまざまなニーズに対応する機能を提供します。これらのツールのそれぞれには独自の強みがあり、SEO最適化から市場調査、コンテンツ集約まで、さまざまなアプリケーションに適しています。
FAQ
ウェブスクレイピングAPIの仕組みは?
ウェブスクレイピングAPIは、ユーザーに代わってターゲットウェブサイトにリクエストを送信し、プロキシ処理やアンチボット対策などの複雑さを管理しながらデータを取得することによって機能します。ユーザーは、カスタムスクレイパーを開発する必要なく、構造化されたデータにアクセスできます。
コミットする前にこれらのウェブスクレイピングAPIを試用できますか?
主要なウェブスクレイピングAPIのほとんどは、無料トライアルまたは従量課金制の価格モデルを提供しており、ユーザーは財務上のコミットメントを行う前に、その機能と有効性をテストできます。たとえば、Scrapelessは無料トライアルを提供しています。また、ScrapelessのDiscordで新機能のテストに参加したユーザーには、すべてのScrapeless製品で使用できるクレジットも提供されます!🎉
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


