
2025年五大最佳网页抓取API
Advanced Data Extraction Specialist
网络抓取API是一个强大的工具,旨在自动化从互联网上的网站提取数据。其主要目的是帮助企业、研究人员和开发人员从各种在线资源收集和整理有价值的信息。这些API对于高效处理大量网页数据至关重要,确保组织能够在无需人工干预的情况下访问准确的相关信息。
无论您具体的用例是什么,我们都已整理了一份目前最好的网络抓取API列表。每个API都根据其功能、成本效益和整体性能进行了全面评估。无论您是想增强SEO、简化数据收集流程还是进行全面研究,这些网络抓取API都能满足您的需求。
2025年最佳网页抓取工具
- Scrapeless – 最佳整体网页爬虫
- Scrapy – 高级开源爬虫
- DYNO Mapper – 专注于SEO的可视化爬虫
- Oncrawl – 技术SEO网页爬虫
- Node Crawler – 基于JavaScript的网页爬虫
现在,让我们深入探讨为什么这些网络抓取API提供商如此出色,以及为什么您应该将它们考虑用于您的网络抓取需求。
Scrapeless
Scrapeless的网页抓取API旨在有效地从目标网站提取相关数据。它会自动浏览网络以收集您所需的确切信息。通过结合AI Agent技术和Browserless集成,Scrapeless创建了一个无需手动编码的强大的网络抓取工具。AI Agent通过优化抓取任务来增强抓取过程,而Browserless则处理无头浏览器操作,确保从动态网站顺利收集数据。
使用Scrapeless的网络爬虫,用户可以完全控制其抓取策略和范围。爬虫会从起始页面有条不紊地遵循链接,遍历网站的所有可访问页面,直到所有页面都被索引。
优点:
- 高成功率:以最小的错误提供准确可靠的数据提取。
- 可扩展性:高效地处理大规模数据收集,使其适用于大型网站。
- AI驱动的功能:利用人工智能来提高网络抓取任务的效率。
- 无头浏览器集成:使用无头浏览技术无缝抓取动态和JavaScript密集型网站。
- 合规的数据收集:遵循数据抓取的最佳实践,以确保合规操作。
缺点:
- 学习曲线:新用户可能需要时间才能完全理解和利用Scrapeless的所有高级功能。
价格:
- 免费试用
如何获得Scrapeless的免费试用?
要获得Scrapeless的免费试用,只需登录Scrapeless仪表板。登录后,您会发现可以直接从仪表板申请免费试用的选项。这是一个简单直接的过程,您可以立即开始使用该工具。
Scrapeless的抓取API价格是多少?
Scrapeless的抓取API起价为每1,000个URL 1美元。此外,Scrapeless还提供最经济实惠和最快的SERP API之一,搜索查询只需1-2秒即可处理。这些搜索查询的价格低至每1,000个查询0.30美元,使其成为市场上最经济高效的解决方案之一。
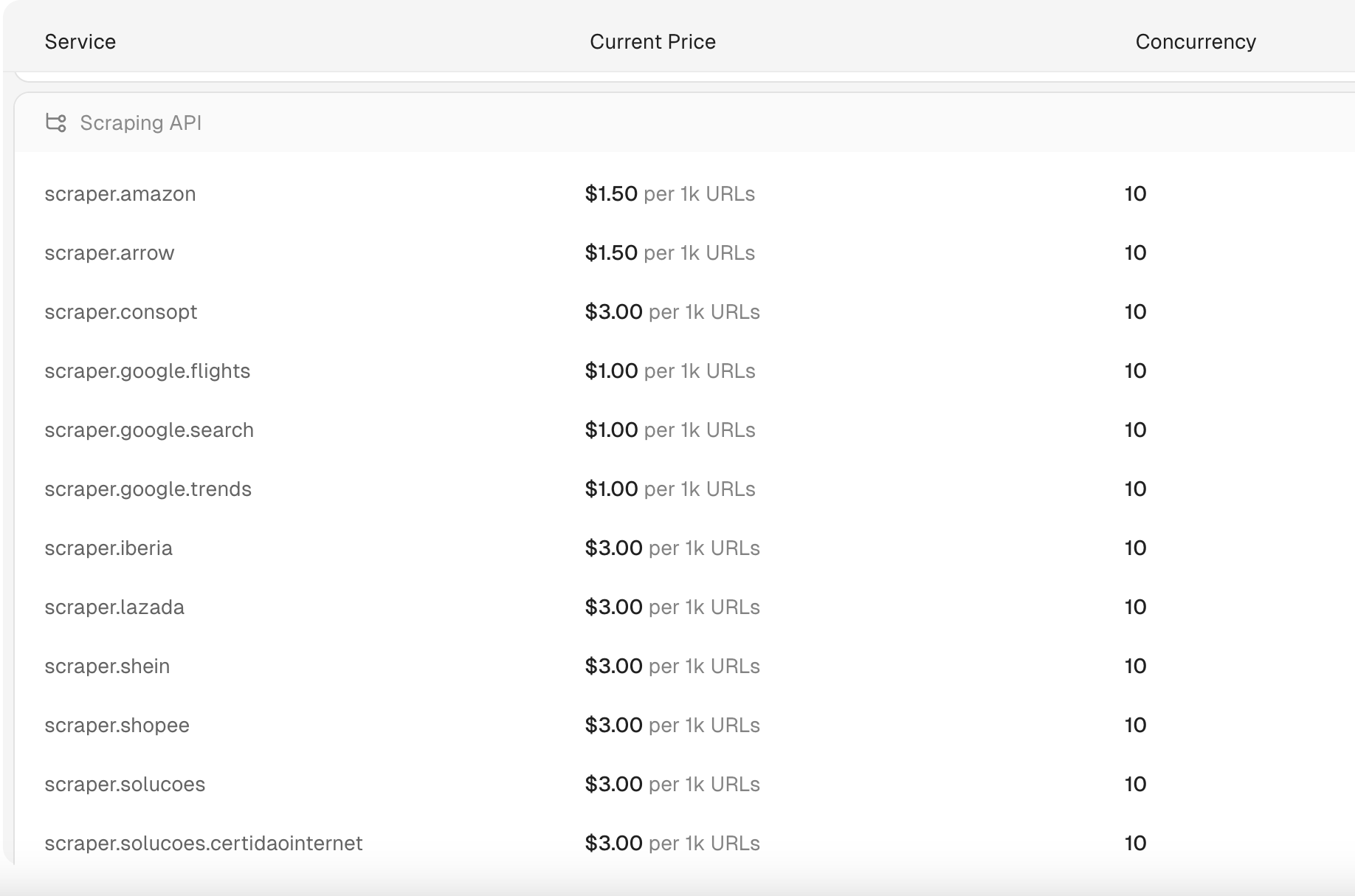
注意:
- 收费按每次请求计算。
- 只有成功的请求才会被计费。
如何使用Scrapeless的抓取API获取Shopee数据?
要使用Scrapeless的抓取API抓取Shopee数据,您通常需要按照以下步骤操作。请记住,网络抓取可能涉及法律和道德问题,因此请务必查看Shopee的服务条款并确保遵守适用的法律。
步骤1. 注册Scrapeless API
请登录您的Scrapeless帐户。登录后,您将获得一个API密钥。
步骤2. 选择您的抓取计划
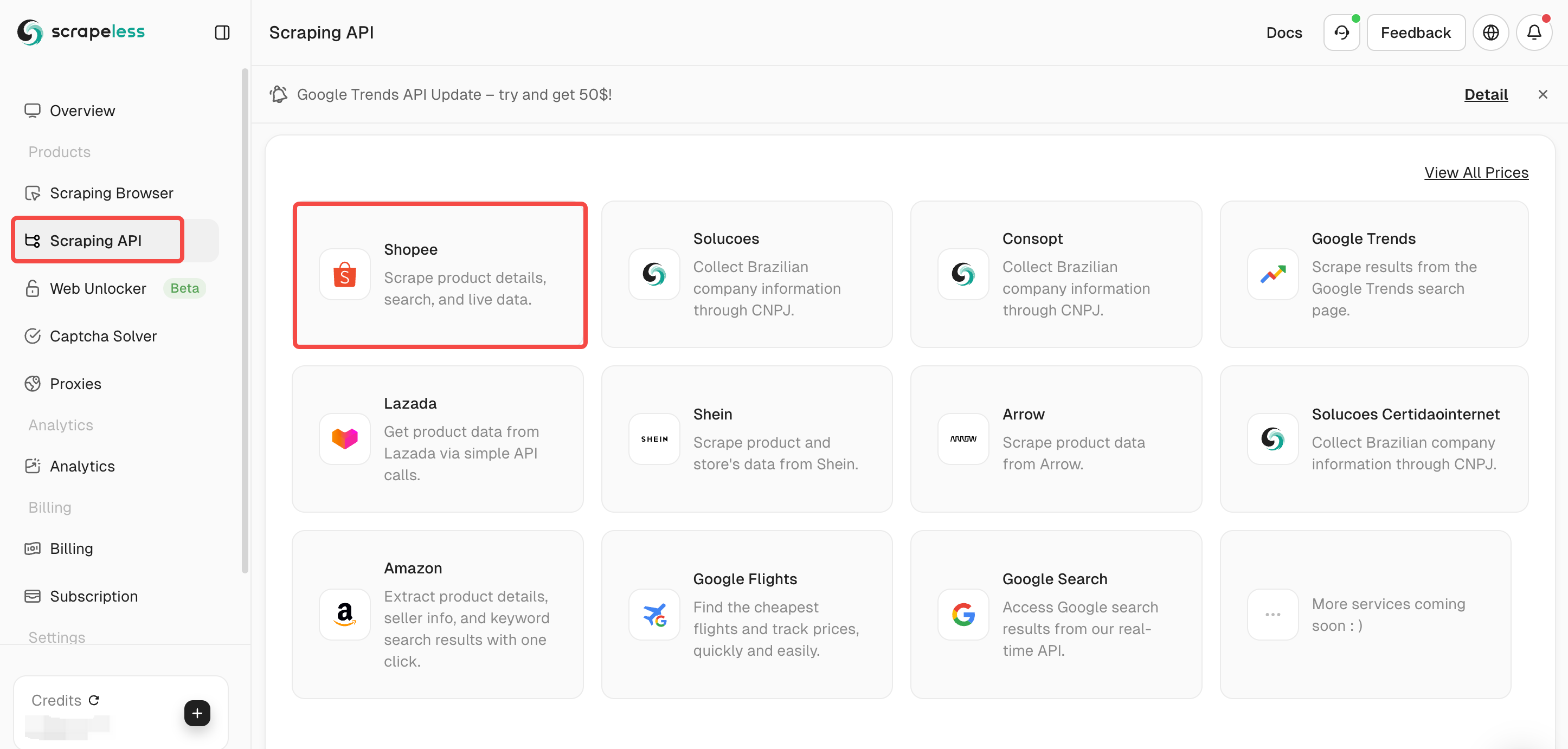
在仪表板上选择抓取API,然后选择Shopee。
Scrapeless提供多种抓取API,例如Lazada /Shein /Google搜索/Google航班。
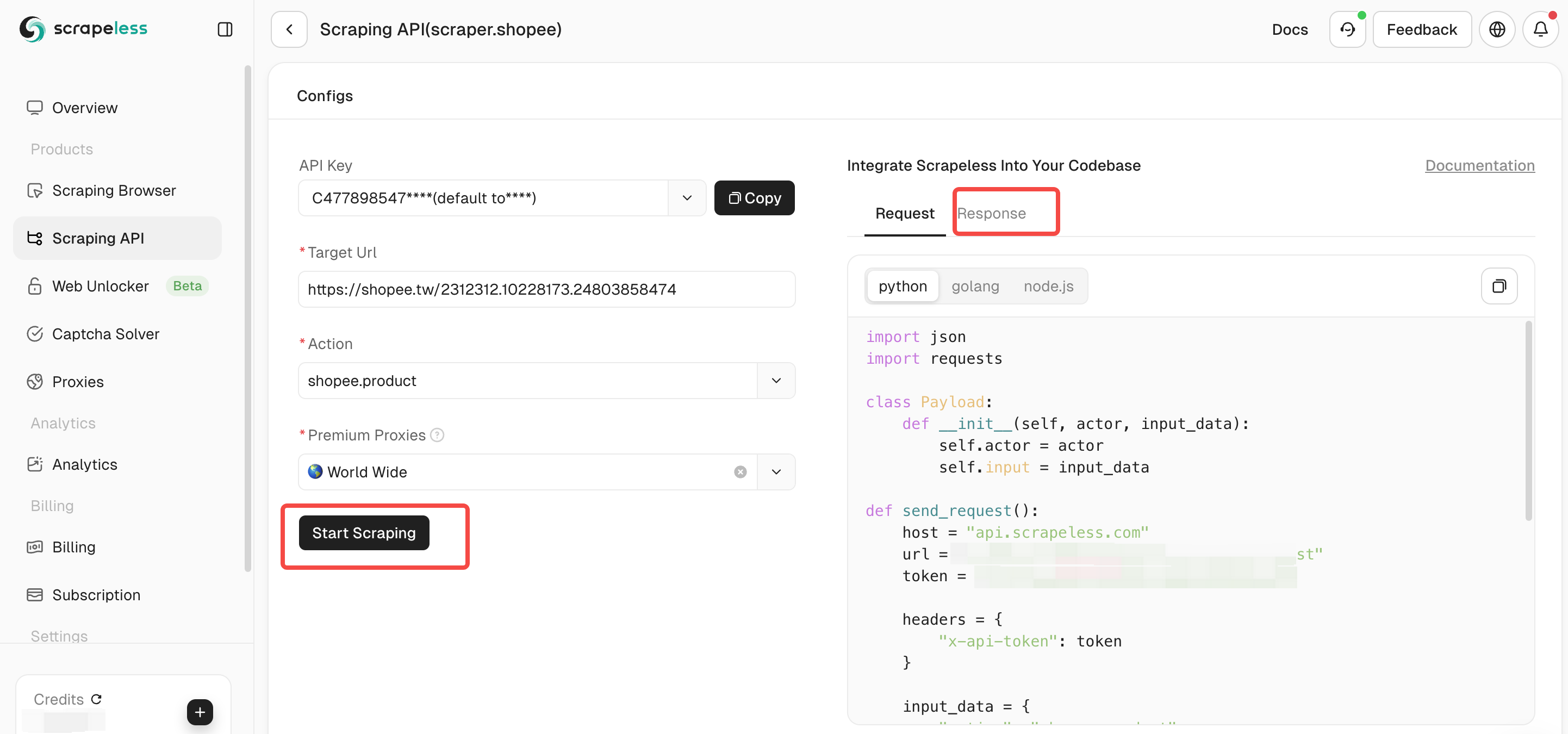
步骤3. 配置Shopee抓取API的参数。然后点击“开始抓取”,您可以在右侧面板中看到输出结果数据。
如何将Scrapeless集成到您的项目中?
通过将Scrapeless集成到您的项目中,您可以有效地提高抓取效率。Scrapeless通常用于网络抓取和数据提取任务。以下是将Scrapeless集成到您的项目中的代码示例。当然,您也可以查看Scrapeless的完整文档:
Shopee产品
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee搜索
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee直播
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.live",
"url": "https://live.shopee.co.th/api/v1/session/{sessionId}"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee推荐
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.rcmd",
"url": "https://shopee.co.th/api/v4/shop/rcmd_items?bundle=shop_page_category_tab_main&item_card_use_scene=category_product_list_topsales&limit=30&offset=0&shop_id=1195212398&sort_type=13&upstream="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee评价
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.ratings",
"url": "https://shopee.ph/api/v2/item/get_ratings?exclude_filter=1&filter=0&filter_size=0&flag=1&fold_filter=0&itemid=23760784194&limit=6&offset=0&relevant_reviews=false&request_source=2&shopid=29975023&tag_filter=&type=0&variation_filters="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Scrapy
Scrapy是一个流行的开源网页爬取框架,使用Python构建,旨在通过网络抓取API促进网络抓取和数据提取。它为开发人员提供了构建强大、可扩展的爬虫的工具,方法是利用一个围绕“蜘蛛”的组织良好的系统——具有针对数据目标的特定指令的自包含抓取单元。
遵循“不要重复自己”(DRY)原则,Scrapy促进了代码的可重用性,使其成为扩展大型抓取操作的有效选择。由于其多功能性,Scrapy受到从事高级抓取任务的开发人员和数据科学家的青睐。
优点:
- 开源抓取库:在BSD许可下免费提供,并得到充满活力的社区的贡献。
- 非常适合开发人员和数据科学家:提供强大的自定义选项和对抓取过程的完全控制。
缺点:
- 对于初学者来说具有挑战性:需要对Python和网络抓取概念有深入的了解,这对于刚接触该领域的人来说可能是一个障碍。
- 资源密集型:尤其是在处理大规模抓取项目时,它会消耗大量的系统资源。
- 对于新手来说不太友好:其复杂性和对编码专业知识的需求可能会让网络抓取新手不知所措。
价格:
- 免费
您可能需要:如何解决网络抓取挑战 - 2025年完整指南
DYNO Mapper
DYNO Mapper是一个直观的可视化站点地图生成器,它通过遵循内部链接来爬取网站,模仿搜索引擎机器人的行为。爬取后,它会生成一个可视化站点地图,展示网站的结构,帮助用户更好地理解网站导航。该工具支持多种输出格式,包括交互式可视化站点地图、HTML、CSV、XML、PDF、JSON和Excel(XLSX)。除了其站点地图功能外,DYNO Mapper还提供内容清单和审计功能,以及辅助功能测试,以确保符合ADA网站标准。它还可以与网络抓取API无缝集成,以满足高级数据提取的需求,使其成为最佳内容管理网络爬虫之一。
优点:
- 多种输出格式:通过多种格式提供数据,增强了信息的可用性。
- 内容清单和审计工具:有助于简化网站内容的组织和优化,以提高性能。
缺点:
- 免费计划的限制:免费计划的功能有限,可能无法满足所有用户的需求。
- 难以掌握:需要时间和精力才能充分理解和使用其所有高级功能。
价格:
- 提供免费试用,最实惠的计划起价为每月39美元。
Oncrawl
Oncrawl是一个功能强大的网页爬虫工具,专为SEO和技术网站分析而设计。它提供详细的SEO审计、可自定义的仪表板和适用于大型网站的可扩展解决方案,使其成为任何数字营销策略的关键资源。作为最好的网络爬虫之一,Oncrawl使企业能够高效地分析和改进其在线形象。此外,它还与网络抓取API集成,以增强数据提取能力。
优点:
- 彻底的SEO审计:提供有关您网站SEO性能的全面见解。
- 可自定义的仪表板和报告:用户可以个性化报告和仪表板以满足其特定要求。
缺点:
- 对于小型网站的抓取控制有限:对于小型网站,在抓取设置方面可能无法提供足够的灵活性。
- 学习曲线陡峭:需要时间才能充分掌握和利用Oncrawl的所有功能。
价格:
- 起价为每月69美元
Node Crawler
Node Crawler是一个流行的网页爬取库,专为Node.js而设计,以其灵活性和易用性而闻名。通过使用Cheerio作为其默认解析器,它提供了快速高效的HTML解析和操作。该库提供了许多自定义选项,例如用于处理并发、速率限制和自动重试的队列管理,使其成为网络抓取项目的强大工具。
由于其轻量级的特性,Node Crawler确保了最小的内存消耗,使其成为高性能任务的理想选择,即使是在处理大量请求时也是如此。作为Node.js开发人员最好的网络爬虫之一,它可以完美地集成到基于JavaScript的工作流程中,并允许无缝使用网络抓取API。
优点:
- 非常适合Node.js开发人员:可以轻松集成到JavaScript环境中,使其成为熟悉Node.js的开发人员的首选。
- 高效且轻量级:注重性能设计,确保在操作期间即使处理多个请求也能保持较低的内存使用率。
缺点: - 没有原生JavaScript渲染:默认情况下它不支持JavaScript渲染,这可能需要其他工具或配置才能抓取动态内容。
价格:
- 免费
最佳网页抓取工具对比
| 提供商 | 最佳功能 |
|---|---|
| Scrapeless | 先进的代理基础设施和住宅IP,用于可扩展和合规的网络抓取和网络爬取。 |
| Scrapy | 一个强大的开源Python框架,用于构建自定义网络爬虫和抓取工具。 |
| DYNO Mapper | 专注于创建可视化站点地图和进行SEO审计,用于网站优化和结构分析。 |
| Oncrawl | 一个专注于技术SEO的网络爬虫,具有高级分析功能,用于网站架构、爬取预算和日志文件。 |
| Node Crawler | 一个灵活的基于JavaScript的爬虫,基于Node.js构建,非常适合具有动态内容的现代网站。 |
什么是网络抓取?
网络抓取是一种用于自动从网站提取数据的技术。此过程涉及几个关键步骤:
定义
网络抓取,也称为网络收集或网络数据提取,是指从网页检索和收集信息的自动化方法。它通常涉及使用可以访问互联网、下载网页并从网页中提取特定数据以用于各种目的(例如分析或存储在数据库中)的软件工具或脚本。
网络抓取的工作原理
- 请求:该过程从向网站服务器发送请求开始,类似于在浏览器中输入URL。
- 响应:服务器通过提供请求的网页来响应,该网页可能包含文本、图像和其他类型的数据。
- 解析:然后,网络抓取工具分析页面的HTML内容以查找和提取特定数据点,例如产品价格、联系信息或其他相关详细信息。
- 存储:最后,提取的数据将以结构化格式(例如CSV、Excel或数据库)保存,以便以后使用。
网络抓取的应用
网络抓取在各个行业的应用范围很广:
- 市场研究:收集竞争性定价和产品信息。
- 潜在客户开发:收集用于销售和营销工作的联系方式。
- 价格监控:跟踪不同零售商产品的价格变化。
- 内容聚合:从多个来源汇编新闻文章或产品评论。
与网络爬取的区别
虽然网络抓取和网络爬取是相关的概念,但它们的目的不同。网络爬取主要专注于通过遵循互联网上的链接来发现和索引网页。相反,网络抓取专门针对在访问这些页面后从中提取数据。
结论
总之,为希望从网络提取和利用有价值数据的企业和开发人员选择合适的网络抓取API至关重要。2025年排名前5的最佳网络抓取API提供了一系列满足不同需求的功能——无论是可扩展性、易用性还是高级数据处理能力。这些工具各有优势,使其适用于各种应用,从SEO优化到市场研究和内容聚合。
常见问题
网络抓取API如何工作?
网络抓取API通过代表用户向目标网站发送请求来工作,在管理代理处理和反机器人措施等复杂问题的同时检索数据。用户可以访问结构化数据,而无需开发自定义抓取工具。
在付费之前,我可以试用这些网络抓取API吗?
大多数领先的网络抓取API都提供免费试用或按次付费定价模式,让用户在做出财务承诺之前测试其功能和有效性。例如,Scrapeless提供免费试用。参与Scrapeless的Discord测试新功能的用户还将获得可在所有Scrapeless产品中使用的积分!🎉
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


