
Como Fazer Scraping de um Site Protegido por Login com Python (2026)
Expert Network Defense Engineer
Após anos construindo scrapers, as paredes de login continuam sendo um dos desafios mais difíceis. Este guia foca em métodos práticos que funcionam em projetos reais: desde logins simples em formulários até proteção CSRF e sites protegidos por WAFs modernos e sistemas anti-bot. Os exemplos estão em Python onde relevante, e eu termino mostrando como usar um navegador remoto (Scrapeless Browser) para lidar com as proteções mais difíceis.
Este guia é apenas para uso educacional. Respeite os termos de serviço e as regras de privacidade do site (por exemplo, GDPR). Não faça scraping de conteúdo que você não está autorizado a acessar.
O que este guia cobre
- Scraping de sites que requerem um nome de usuário e senha simples.
- Logging em páginas que requerem um token CSRF.
- Acesso ao conteúdo por trás de uma proteção WAF básica.
- Lidando com proteções avançadas anti-bot usando um navegador remoto (Scrapeless Browser) controlado via Puppeteer.
É possível fazer scraping em sites que requerem login?
Sim — tecnicamente você pode obter páginas por trás de um login. Dito isso, limites legais e éticos se aplicam. Plataformas sociais e sites com dados pessoais são especialmente sensíveis. Sempre verifique a política de robôs do site alvo, os termos de serviço e a legislação aplicável.
Tecnicamente, os passos chave são:
- Compreender o fluxo de login.
- Reproduzir as requisições necessárias (e tokens) programaticamente.
- Persistir o estado autenticado (cookies, sessões).
- Lidar com verificações do lado do cliente quando necessário.
1) Logins simples de nome de usuário + senha (Requests + BeautifulSoup)
Conclusão antecipada: Se o login for um formulário HTTP básico, use uma sessão e envie as credenciais via POST.
Instale as bibliotecas:
bash
pip3 install requests beautifulsoup4Exemplo de script:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login"
payload = {
"email": "admin@example.com",
"password": "password",
}
with requests.Session() as session:
r = session.post(login_url, data=payload)
print("Código de status:", r.status_code)
soup = BeautifulSoup(r.text, "html.parser")
print("Título da página:", soup.title.string)Notas:
- Use
Session()para que os cookies (ID da sessão) persistam para requisições subsequentes. - Verifique os códigos de resposta e o corpo para confirmar um login bem-sucedido.
- Se o site usar redirecionamentos,
requestsos segue por padrão; inspecioner.historyse necessário.
2) Logins protegidos por CSRF (obter token, então post)
Conclusão antecipada: Muitos sites requerem um token CSRF. Primeiro faça um GET na página de login, analise o token, depois faça um POST com o token.
Padrão:
- Faça um GET na página de login.
- Analise o token oculto do formulário.
- Envie as credenciais + token usando a mesma sessão.
Exemplo:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login/csrf"
with requests.Session() as session:
r = session.get(login_url)
soup = BeautifulSoup(r.text, "html.parser")
csrf_token = soup.find("input", {"name": "_token"})["value"]
payload = {
"_token": csrf_token,
"email": "admin@example.com",
"password": "password",
}
r2 = session.post(login_url, data=payload)
soup2 = BeautifulSoup(r2.text, "html.parser")
produtos = []
for item in soup2.find_all(class_="product-item"):
produtos.append({
"Nome": item.find(class_="product-name").text.strip(),
"Preço": item.find(class_="product-price").text.strip(),
})
print(produtos)Dicas:
- Alguns frameworks usam nomes de tokens diferentes; inspecione o formulário para encontrar o nome correto do campo de entrada.
- Envie cabeçalhos apropriados (User-Agent, Referer) para parecer um navegador normal.
3) Verificações básicas de WAF / bot — use um navegador sem cabeça quando Requests falhar
Quando cabeçalhos e tokens não são suficientes, simule um navegador real com Selenium ou um navegador sem cabeça.
Selenium + Chrome podem passar muitas proteções básicas porque executam JavaScript e rodam um ambiente completo de navegador. Se você usar Selenium, adicione esperas realistas, ações de mouse/teclado e cabeçalhos normais de navegador.
Entretanto, alguns WAFs detectam automação através de navigator.webdriver ou outras heurísticas. Ferramentas como undetected-chromedriver ajudam, mas não são garantidas contra verificações avançadas. Use-as apenas para uso legítimo e permitido.
4) Proteções avançadas anti-bot — use uma sessão de navegador real remoto (Scrapeless Browser)
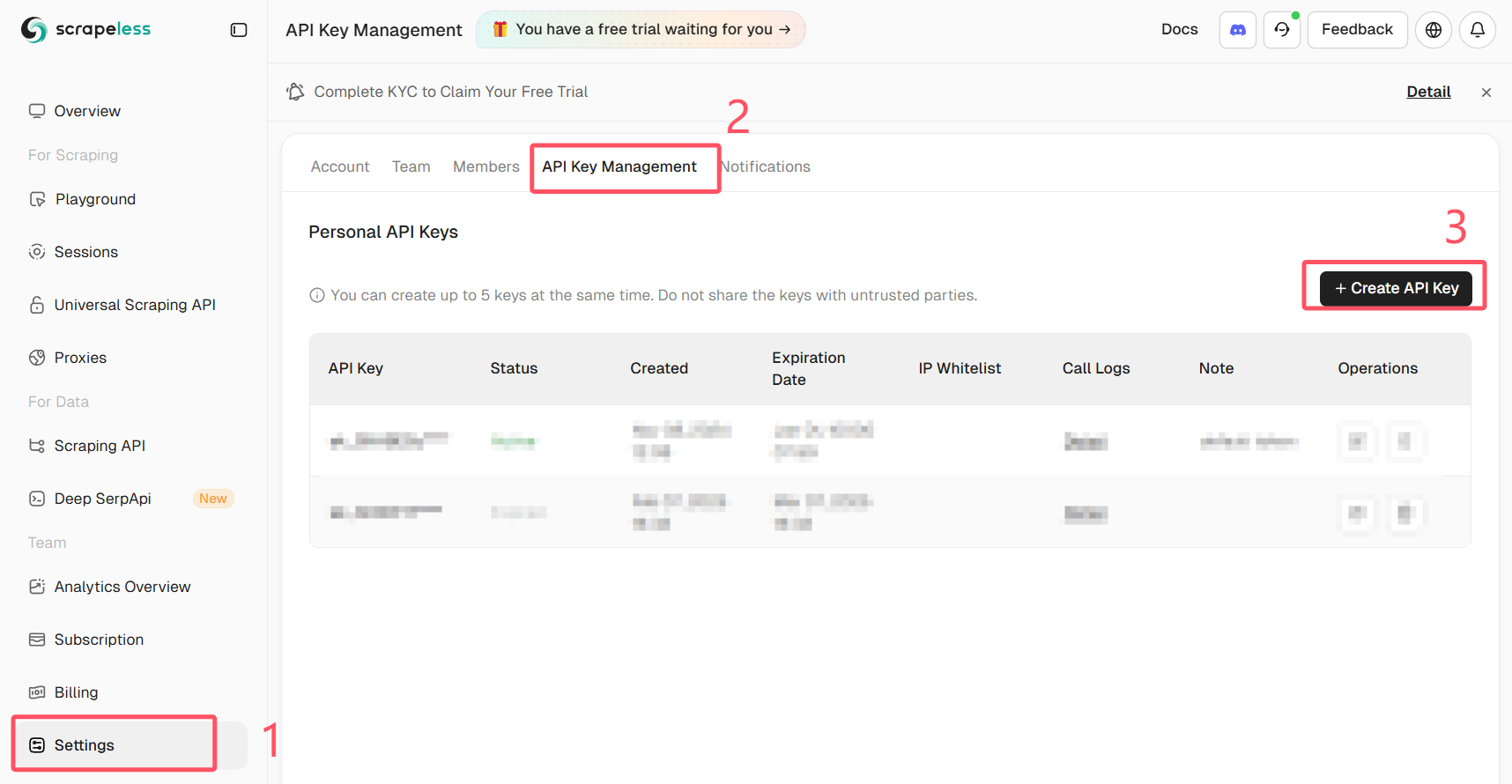
Obtenha sua chave API Scrapeless
Faça login no Scrapeless e obtenha sua chave API.
Para a abordagem mais robusta, execute um navegador real remotamente (não uma instância local sem cabeça) e controle-o via Puppeteer. O Scrapeless Browser fornece um ponto de extremidade de navegador gerenciável que reduz o risco de detecção e descarrega a complexidade de proxy/renderização de JS.
Por que isso ajuda:
- O navegador roda em um ambiente gerenciado que imita sessões reais de usuários.
- O JS é executado exatamente como em um navegador de usuário real, então as verificações do lado do cliente passam.
- Você pode gravar sessões e usar roteamento por proxy conforme necessário.
Abaixo está um exemplo que mostra como conectar o Puppeteer ao Scrapeless Browser e realizar um login automático. O trecho usa puppeteer-core para se conectar a um endpoint WebSocket do Scrapeless. Substitua o token, seu_email@exemplo.com e sua_senha pelos seus próprios valores e nunca compartilhe credenciais publicamente.
Importante: nunca comite credenciais reais ou tokens de API em código público. Armazene segredos de forma segura (variáveis de ambiente ou um gerenciador de segredos).
javascript
import puppeteer from "puppeteer-core"
// 💡Habilitar "Usar Configurações do Playground" sobrescreverá os parâmetros de conexão do seu código de playground.
const query = new URLSearchParams({
token: "sua-chave-api-scrapeless",
proxyCountry: "QUALQUER",
sessionRecording: true,
sessionTTL: 900,
sessionName: "Login Automático",
})
const connectionURL = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://github.com/login")
await page.locator("input[name='login']").fill("seu_email@exemplo.com")
await page.locator("input[name='password']").fill("sua_senha")
await page.keyboard.press("Enter")Notas sobre o exemplo:
- O exemplo usa
puppeteer-corepara se conectar a um navegador remoto. O Scrapeless expõe um endpoint WebSocket (browserWSEndpoint) que o Puppeteer pode usar. - As opções de gravação de sessão e proxy são passadas em parâmetros de consulta. Ajuste de acordo com seu plano e necessidades do Scrapeless.
- A lógica de espera é importante: use
waitUntil: "networkidle"ouwaitForSelectorexplícito para garantir que a página tenha carregado completamente. - Substitua o token de espaço reservado por um segredo seguro do seu ambiente.
Dicas práticas e lista de verificação anti-bloqueio
- Utilize a API do site, se existir. É mais seguro e estável.
- Evite solicitações paralelas rápidas; regule seu scraper.
- Rode IPs e impressões digitais de sessão quando legítimo e necessário. Use provedores de proxy de boa reputação.
- Use cabeçalhos realistas e manipulação de cookies.
- Verifique o robots.txt e os termos do site. Se o site não permitir scraping, considere pedir permissão ou usar feeds de dados oficiais.
- Registre os passos que seu scraper executa para facilitar a depuração (requisições, códigos de resposta, redirecionamentos).
Resumo
Você aprendeu como:
- Fazer login e raspar páginas que aceitam nome de usuário/senha simples com
requests. - Extrair e usar tokens CSRF para autenticação segura.
- Utilizar uma ferramenta de automação de navegador quando um site precisa de renderização completa em JS.
- Usar um navegador gerenciado remoto (Scrapeless Browser) via Puppeteer para contornar proteções avançadas do lado do cliente, mantendo seu próprio ambiente simples.
Quando as proteções são fortes, uma abordagem de navegador gerenciado é frequentemente a rota mais confiável. Use-a de forma responsável e mantenha credenciais e tokens de API seguros.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


