
Como extrair dados da Amazon via Scrapeless?
Advanced Data Extraction Specialist
Quer ganhar uma vantagem competitiva na Amazon? Seja rastreando preços, analisando tendências de produtos ou conduzindo pesquisas de mercado, a chave para se manter à frente é raspar dados da Amazon de forma eficaz. Mas extrair informações úteis da Amazon pode ser complicado—especialmente com as mudanças frequentes na estrutura do site, medidas anti-bot e bloqueio de IP. É aí que entra a Amazon Scraping API. Neste guia, vamos mostrar como raspar dados de produtos da Amazon usando Python, tornando mais fácil do que nunca coletar dados e informações valiosas da maior plataforma de e-commerce do mundo.
O que é uma Amazon Scraping API?
A Amazon Web Scraping API é como um servidor remoto que ajuda você a coletar dados da Amazon. A operação é simples - você envia um pedido para o endpoint da API contendo a URL alvo e outros parâmetros como geolocalização. A API então visita o site por você.
A Amazon suporta a coleta dos seguintes tipos de dados:
1. Produto:
-
Informações sobre o produto: O conteúdo que pode ser coletado inclui informações básicas como nome do produto, descrição, preço, URL da imagem, ASIN (Número de Identificação Padrão da Amazon), marca, etc.
-
Dados de vendas: Como classificação do produto, volume de vendas e comentários, etc.
2. Vendedor:
- Informações do vendedor: Você pode obter o nome do vendedor, ID do comerciante e informações relacionadas aos produtos que ele vende.
- Classificação do vendedor: Ao rastrear produtos de diferentes vendedores, você pode analisar o desempenho de mercado de cada vendedor e sua competitividade em uma categoria específica.
3. Palavras-chave:
- Resultados de busca por palavras-chave: Você pode raspar listas de produtos relacionados e suas informações detalhadas com base em palavras-chave específicas (como "notebook" ou "figura de anime").
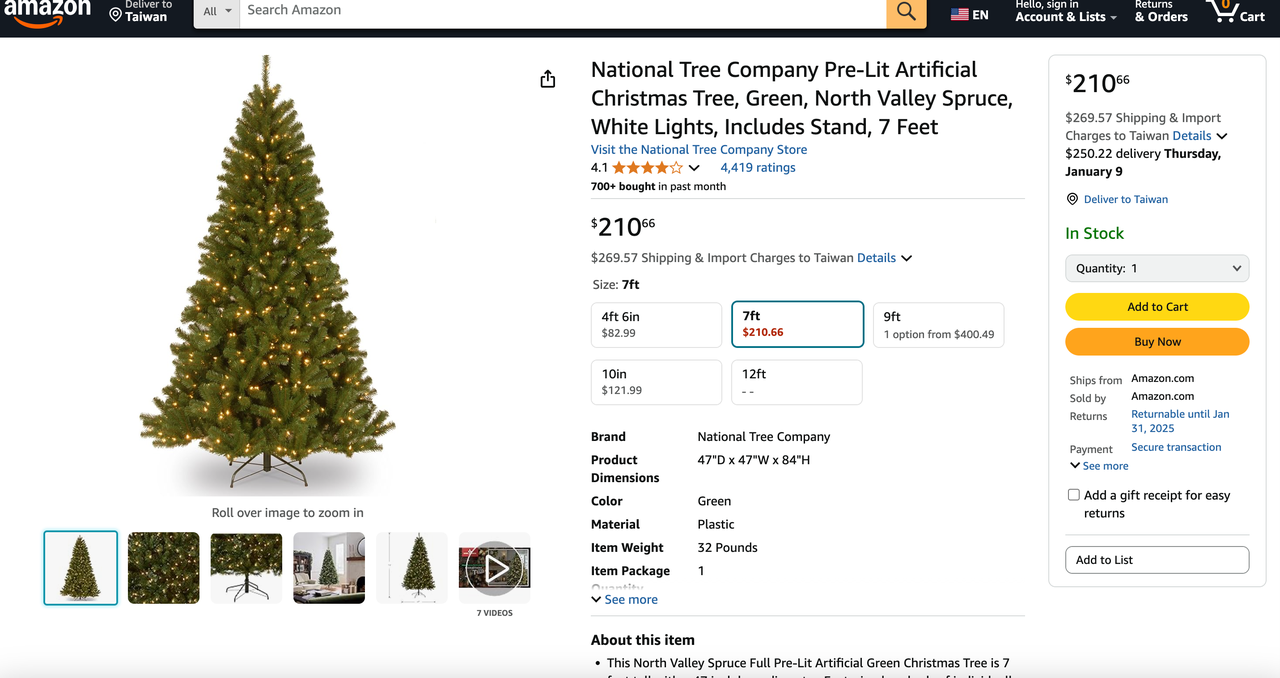
Casos de uso comuns para raspagem da Amazon
A raspagem da Amazon serve a diversos propósitos para empresas e marketeiros:
1. Monitoramento de Preços: Ao raspar preços de produtos, as empresas podem rastrear os preços dos concorrentes e ajustar suas próprias estratégias de acordo.
2. Pesquisa de Produtos: Raspar avaliações, classificações e detalhes de produtos ajuda a identificar itens em tendência e entender as preferências dos consumidores.
3. Otimização de Vendas: Marketers raspam descrições de produtos e promoções para melhorar o conteúdo e criar campanhas eficazes.
4. Monitoramento de Níveis de Estoque: Raspagem de dados de disponibilidade de produtos em tempo real ajuda as empresas a monitorar níveis de inventário e demanda.
5. Análise de Sentimento do Consumidor: Avaliações raspadas da Amazon oferecem insights sobre a satisfação do cliente e áreas para melhoria.
Em essência, a raspagem da Amazon simplifica a análise competitiva, pesquisa de produtos e estratégias de marketing.
Desafios principais na raspagem da Amazon (ex: CAPTCHA, limites de taxa)
- Desafios CAPTCHA
A Amazon usa verificação CAPTCHA para impedir a raspagem automática, especialmente quando um grande número de pedidos rápidos é detectado. Essa verificação exige que os usuários confirmem que são humanos, o que impede que ferramentas automatizadas obtenham dados com sucesso.
A Amazon tem um limite de frequência de pedidos. Se você acessar seu site com muita frequência, o sistema atrasará automaticamente a resposta ou bloqueará temporariamente novos pedidos. Isso torna o processo de raspagem lento e instável.
DICAS: Para a maioria dos usuários comuns, a Amazon geralmente permite entre dezenas e centenas de pedidos por minuto. Exceder essa frequência pode resultar em atrasos ou bloqueios temporários. A Amazon pode definir limites mais rígidos para pedidos de raspagem frequentes.
- Bloqueio de IP
Raspagens altamente frequentes podem fazer com que a Amazon bloqueie temporariamente endereços IP. Se o endereço IP for marcado como uma fonte anormal, a operação de raspagem será completamente bloqueada, e você precisará mudar o IP ou usar uma pool de proxies para contornar esse limite. De modo geral, 5-10 pedidos por segundo podem causar riscos.
- Carregamento Dinâmico de Conteúdo
O conteúdo da página da Amazon geralmente é carregado dinamicamente através de JavaScript, o que significa que um processamento adicional do processo de renderização da página é necessário ao raspar. Métodos tradicionais de raspagem de HTML muitas vezes não conseguem obter diretamente dados carregados dinamicamente.
- Mudanças Frequentes no Layout
O layout da página do site da Amazon muda frequentemente, o que traz desafios para o script de raspagem. A ferramenta de raspagem precisa ser constantemente atualizada para se adaptar às atualizações e mudanças da página, a fim de garantir a precisão e a estabilidade da extração de dados.
Configurando Seu Ambiente Python
Antes de começar a escrever código em Python, você deve primeiro configurar seu ambiente de desenvolvimento. Esta etapa garante que você tenha todas as ferramentas e bibliotecas necessárias para escrever e executar código Python. Nesta seção, vamos guiá-lo pelo processo de instalação do Python, configuração de um ambiente virtual e configuração de um ambiente de desenvolvimento integrado (IDE) para otimizar seu fluxo de trabalho.
Para usar Python, você precisa baixar as seguintes configurações
1. Python: https://www.python.org/downloads/ Este é o software principal para executar Python. Você pode baixar a versão que precisamos no site oficial conforme mostrado abaixo, mas é recomendável não baixar a versão mais recente. Você pode baixar as 1-2 primeiras versões da versão mais recente.
2. Python IDE: Qualquer IDE que suporte Python serve, mas recomendamos usar o PyCharm, que é um software de ferramenta de desenvolvimento IDE projetado especificamente para Python. Para a versão do PyCharm, recomendamos usar a versão gratuita PyCharm Community Edition.
3. pip: Você pode usar o Python Package Index (PyPi) para instalar bibliotecas com um único comando.
Nota: Se você é um usuário do Windows, não se esqueça de marcar a opção Adicionar python.exe ao PATH no assistente de instalação. Assim, o Windows poderá usar python e comandos no terminal. Para sua informação: Como o Python 3.4 ou posterior já inclui isso por padrão, você não precisa instalá-lo manualmente.
Inicializar um projeto Python
Inicie o PyCharm e selecione a opção Arquivo > Novo Projeto... na barra de menu.

Em seguida, ele abrirá uma janela popup. Selecione Python Puro no menu à esquerda e configure seu projeto da seguinte forma:
Nota: Na caixa vermelha abaixo, selecione o caminho de instalação do Python que baixamos na primeira etapa de configuração do ambiente.
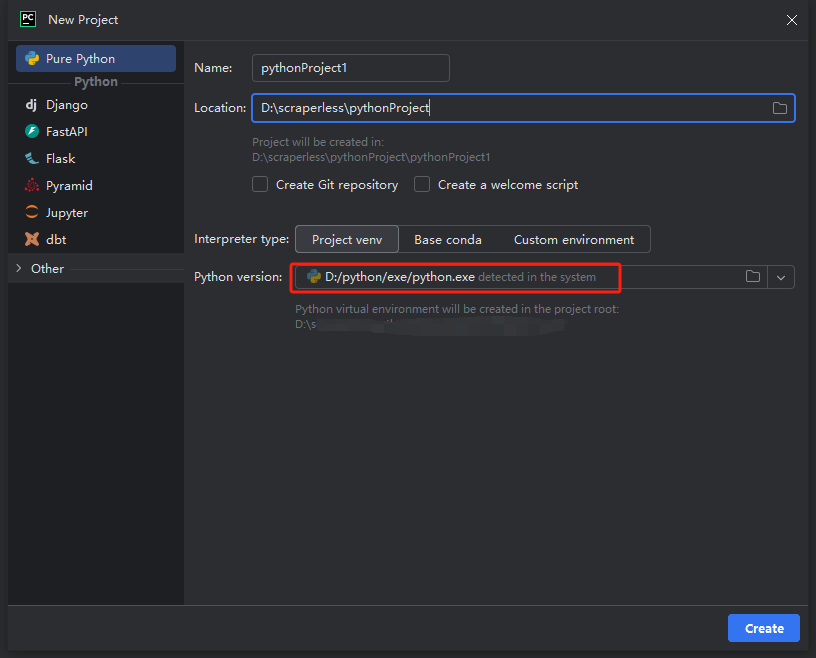
Você pode criar um projeto chamado python-scraper, marcar a opção "Criar um script de boas-vindas main.py" na pasta e clicar no botão Criar.
Após aguardar um momento enquanto o PyCharm configura seu projeto, você deverá ver o seguinte:
Em seguida, clique com o botão direito para criar um novo arquivo Python.
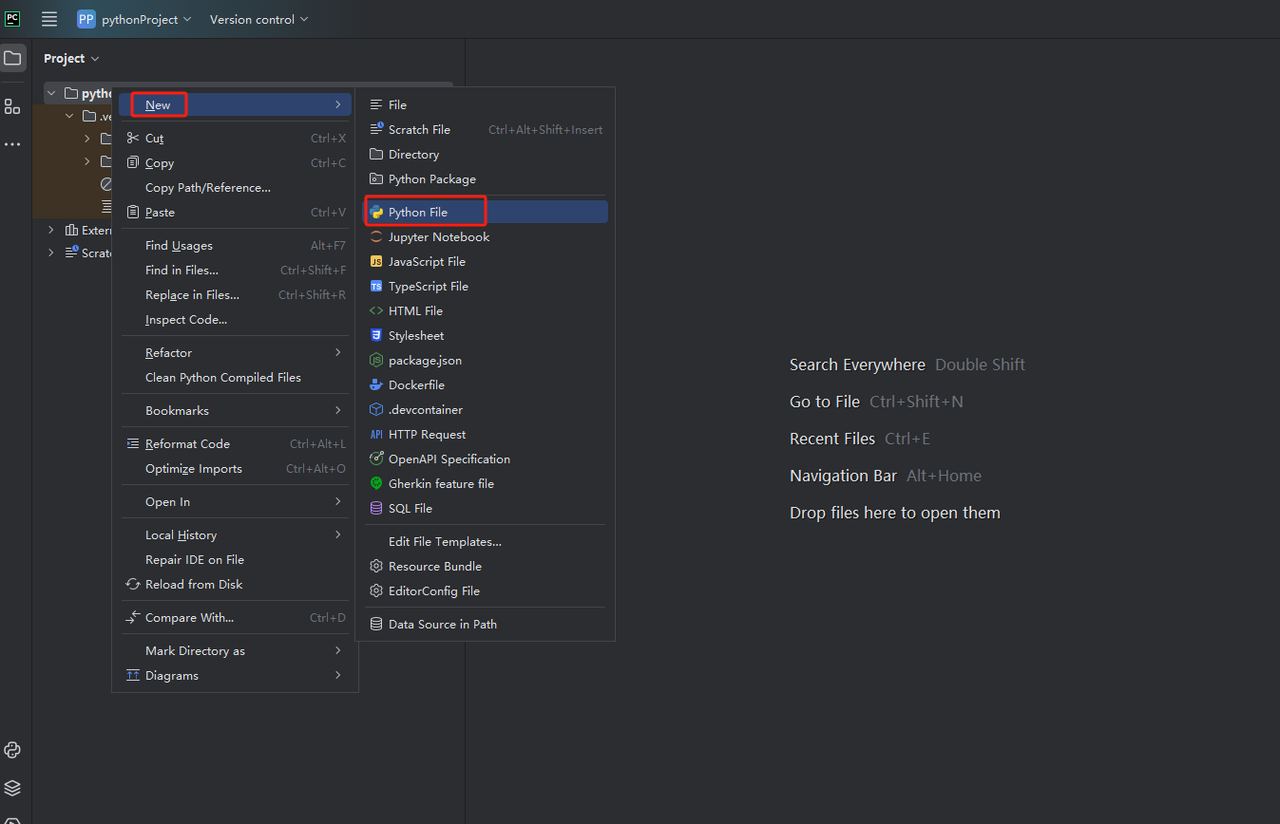
Para verificar se tudo está funcionando corretamente, abra a aba Terminal na parte inferior da tela e digite: python main.py. Após executar este comando, você deverá obter: Oi, PyCharm.
Você pode copiar diretamente o código em scraperless para o pycharm e executá-lo, para que possamos obter os dados em formato json dos produtos da Amazon.
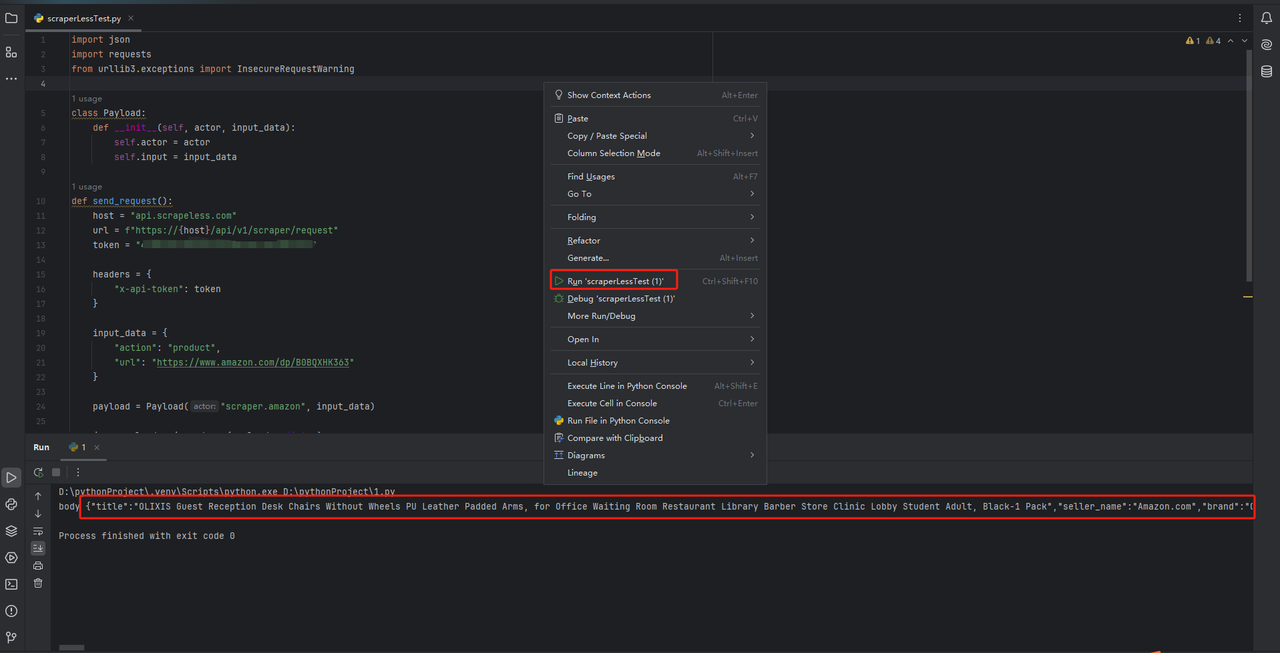
Guia Passo a Passo: Raspagem de Dados de Produtos da Amazon
Como mencionamos acima, após configurar o ambiente necessário para a raspagem da amazon, você pode integrar o código python do Scrapeless.
Como Raspagem de Dados de Produtos da Amazon
Você pode visitar diretamente a documentação da API Scrapeless para obter informações mais completas sobre o código da API e, em seguida, integrar o código Python do Scrapeless ao seu projeto.
Amostras de solicitações - Produto
python
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Como Raspagem de Informações do Vendedor da Amazon
Da mesma forma, apenas integrando o código da API Scrapeless em sua configuração de raspagem, você pode contornar as barreiras de raspagem da Amazon e raspar informações do vendedor da Amazon.
Amostras de solicitações - Vendedor
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
pt
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Como Extrair Resultados de Pesquisa de Palavras-Chave da Amazon
Siga os passos acima para integrar amostras de solicitação - Palavras-Chave em seu projeto para obter Resultados de Pesquisa de Palavras-Chave da Amazon.
Amostras de solicitação - Palavras-Chave
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Através de uma integração e configuração simples, Scrapeless ajuda você a obter dados da Amazon de forma mais eficiente. Você pode facilmente extrair dados-chave na plataforma Amazon, incluindo informações sobre produtos, vendedores e palavras-chave, melhorando assim a precisão e a atualidade da análise de dados.
Perguntas Frequentes Sobre a Extração de Dados da Amazon
1. É legal extrair dados da Amazon?
Extrair informações públicas de produtos (como títulos, descrições, preços e avaliações) é legal, enquanto a extração de dados de contas privadas pode levantar questões de privacidade. Além disso, o uso de dados extraídos para pesquisa de mercado ou análise competitiva é geralmente considerado "uso justo".
2. Quais dados podem ser extraídos da Amazon?
Usando a API de extração da Amazon, você pode extrair dados relacionados a produtos, vendedores, avaliações, etc. Isso inclui nome do produto, preço, ASIN (Número de Identificação Padrão da Amazon), marca, descrição, especificações, categoria, avaliações de usuários e suas classificações.
3. Como extrair dados da Amazon de forma eficaz?
As maneiras eficazes de extrair dados da Amazon incluem o uso de scripts automatizados ou APIs e o cumprimento dos termos de serviço da Amazon. Para evitar ser bloqueado, recomenda-se reduzir a frequência das solicitações e controlar a carga de maneira razoável. Além disso, usar uma solução de captcha pode aumentar a taxa de sucesso da extração.
Conclusão: Melhor Provedor da API de Extração da Amazon
Com a introdução deste artigo, você aprendeu como usar Python para extrair dados de produtos na Amazon de forma eficiente. Seja para obter detalhes do produto, informações de preço ou dados de avaliações, o poder e a flexibilidade do Python tornam a extração automatizada mais fácil e eficiente. No entanto, ao extrair dados em larga escala, você pode enfrentar desafios com mecanismos anti-rastreamento. Nesse momento, o Scrapeless, como uma solução inteligente de rastreamento na web, pode ajudá-lo a contornar esses obstáculos e garantir um processo de rastreamento mais suave e eficiente. Se você deseja melhorar a velocidade e a estabilidade da extração de dados, pode tentar usar o Scrapeless para otimizar ainda mais seu fluxo de trabalho de extração.
Junte-se à Comunidade Discord do Scrapeless! 🚀 Conecte-se com outros entusiastas de dados, obtenha dicas exclusivas sobre como extrair mais rapidamente e de forma mais inteligente, e fique por dentro de nossos últimos recursos. Se você é um iniciante ou um profissional, há um lugar para você aqui. Clique no link e comece a se envolver hoje! 👾 Junte-se Agora
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


