
Como raspar páginas da web usando o navegador de raspagem do Scrapeless
Advanced Data Extraction Specialist
Por que escolher o navegador de scraping da Scrapeless para web scraping?
O web scraping tornou-se uma ferramenta vital para empresas coletarem dados em tempo real, desde preços de concorrentes até tendências de mercado. Uma pesquisa recente da Statista descobriu que mais de 70% das empresas dependem do web scraping para extrair dados valiosos, tornando-o uma parte crucial da tomada de decisões baseada em dados.
À medida que o mercado de web scraping cresce, com projeções para atingir US$ 5,4 bilhões até 2025 (MarketsandMarkets), as empresas estão adotando cada vez mais ferramentas de scraping por sua eficiência e escalabilidade. No entanto, desafios como bloqueio de IP, CAPTCHAs e conteúdo dinâmico podem interromper o processo de scraping.
A Scrapeless resolve esses problemas com suas soluções baseadas em IA, garantindo a extração perfeita de dados mesmo diante de barreiras comuns contra scraping.
Comece a raspar de forma mais inteligente hoje com o Scraping Browser da Scrapeless! Extraia dados de páginas da web sem esforço com nossa ferramenta amigável, projetada para lidar até mesmo com os sites mais complexos. Experimente agora e experimente a extração perfeita de dados como nunca antes!
A Scrapeless oferece uma solução avançada de web scraping baseada em IA, projetada para ajudar as empresas a superar esses obstáculos comuns. O kit de ferramentas Scrapeless é feito sob medida para aqueles que buscam extração de dados da web de alta qualidade, confiável e rápida. Se você deseja raspar sites de comércio eletrônico, plataformas de mídia social ou agregadores de notícias, a Scrapeless oferece as ferramentas certas para fazer o trabalho.
Benefícios principais da Scrapeless incluem:
- Gerenciamento de proxy perfeito: Proteja suas sessões de scraping com rotação de IP e cobertura global.
- Solução CAPTCHA baseada em IA: Resolva automaticamente os desafios de CAPTCHA para garantir que sua coleta de dados não seja interrompida.
- Tecnologia de navegador avançada: Navegue por páginas da web complexas e dinâmicas sem erros.
- Solução escalonável: De pequenas tarefas de extração de dados a operações de scraping em larga escala, a Scrapeless pode ser dimensionada para atender às suas necessidades.
A Scrapeless é mais do que apenas outra ferramenta de scraping. É uma plataforma abrangente que resolve os desafios principais associados ao web scraping, garantindo que sua coleta de dados permaneça rápida, eficiente e confiável. Se você é uma startup ou uma grande empresa, a flexibilidade da Scrapeless permite que você personalize suas tarefas de scraping de acordo com suas necessidades específicas. Do gerenciamento de proxy ao tratamento de sites complexos com conteúdo dinâmico, a Scrapeless fornece todas as ferramentas necessárias para simplificar suas operações de web scraping e economizar tempo valioso.
Navegador de Scraping Scrapeless:
No coração da solução de web scraping da Scrapeless está o Scraping Browser. O Scraping Browser da Scrapeless é otimizado para lidar com os cenários de scraping mais desafiadores e integra-se perfeitamente ao kit de ferramentas Scrapeless para proporcionar uma experiência de scraping excepcional.
Recursos principais do Scraping Browser Scrapeless:
- 🌐 Tratamento de conteúdo dinâmico: Raspe facilmente sites com muito JavaScript e conteúdo dinâmico com os quais outras ferramentas costumam ter dificuldades.
- 🖥️ Modo sem cabeça: Execute tarefas de scraping sem iniciar uma janela de navegador completa, melhorando o desempenho e reduzindo o uso de recursos.
- 🛡️ Tecnologia antidetecção: Evite a detecção com técnicas avançadas como impressões digitais do navegador e modo furtivo.
- ⚡ Eficiência superior: 10 vezes mais rápido que o modo de navegador tradicional, rodando no lado do servidor para tempos de resposta mais rápidos e suportando acesso concorrente em larga escala.
- ⏱️ 99,99% de tempo de atividade: Disponibilidade confiável 24 horas por dia, 7 dias por semana, garante que suas tarefas de scraping sejam sempre executadas no cronograma.
Com o Scraping Browser da Scrapeless, seu processo de extração de dados fica mais rápido, confiável e fácil, garantindo que você possa se concentrar em extrair insights valiosos em vez de lidar com os desafios técnicos do scraping.
Começando com o Navegador de Scraping da Scrapeless
A Chave da API (Application Programming Interface Key) é uma ferramenta usada para verificar a identidade e autorizar o acesso a uma API. Normalmente é uma sequência única de letras, números e símbolos. A Chave da API funciona como uma "senha" de autenticação ao acessar a API, garantindo que a solicitação seja feita por um usuário ou aplicativo legítimo.
✅ Você pode obter a CHAVE DA API seguindo as etapas abaixo:
- Depois de clicar para entrar na Scrapeless, você pode obter automaticamente a CHAVE DA API correspondente.
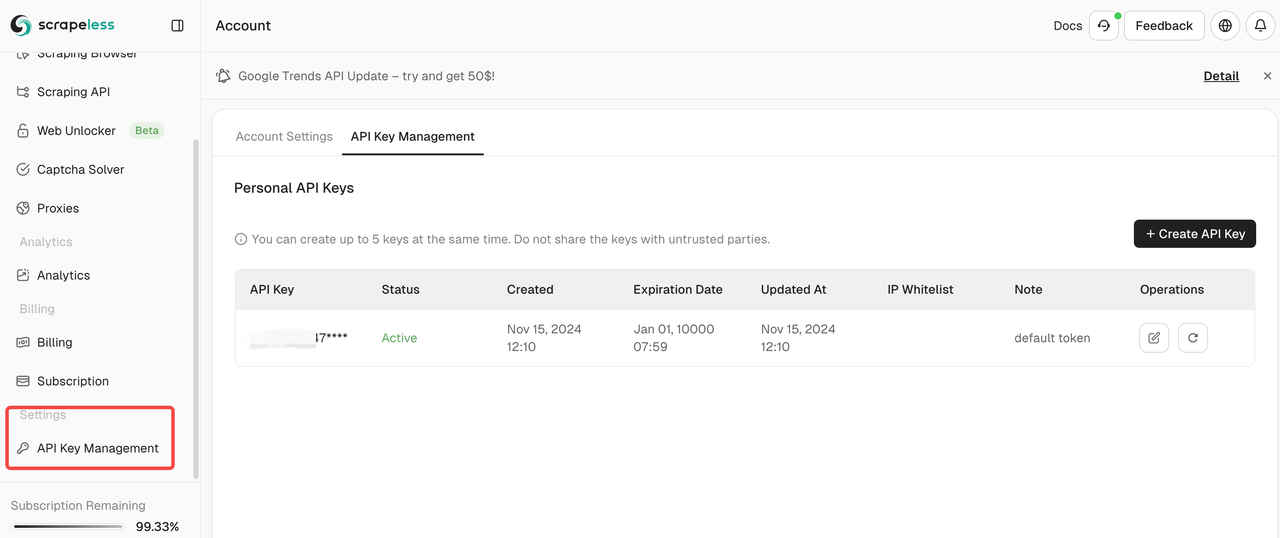
- Você pode ver sua Chave da API no Gerenciamento da Chave da API:
Guia passo a passo para raspar páginas da web com Scrapeless
Nesta seção, usaremos scrapeless + puppeteer para demonstrar como rastrear o conteúdo do produto na Amazon.
O Puppeteer é uma biblioteca Node.js desenvolvida pelo Google que fornece uma API de alto nível para executar operações automatizadas por meio de navegadores Chromium ou Chrome. Ele pode ser usado para operar o navegador, clicar, inserir, navegar, etc., como um usuário humano, e também pode rastrear o conteúdo da página, gerar capturas de tela e PDFs, testar páginas da web, etc.
Primeiro, precisamos obter a Chave da API scrapeless. Você pode consultar a seção anterior para aprender como obter e visualizar sua Chave da API.
Guia passo a passo para raspar páginas da web com Scrapeless:
- Instale o puppeteer por meio do comando npm
npm i puppeteer-core- Prepare os parâmetros de conexão para scrapeless. Você pode definir a configuração do tempo da sessão e do país do proxy.
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- Comece a se preparar para rastrear dados de produtos na Amazon、
- Use as ferramentas de desenvolvedor do navegador (F12) para obter a caixa de entrada e os elementos de pesquisa, e obtenha o seletor do elemento.
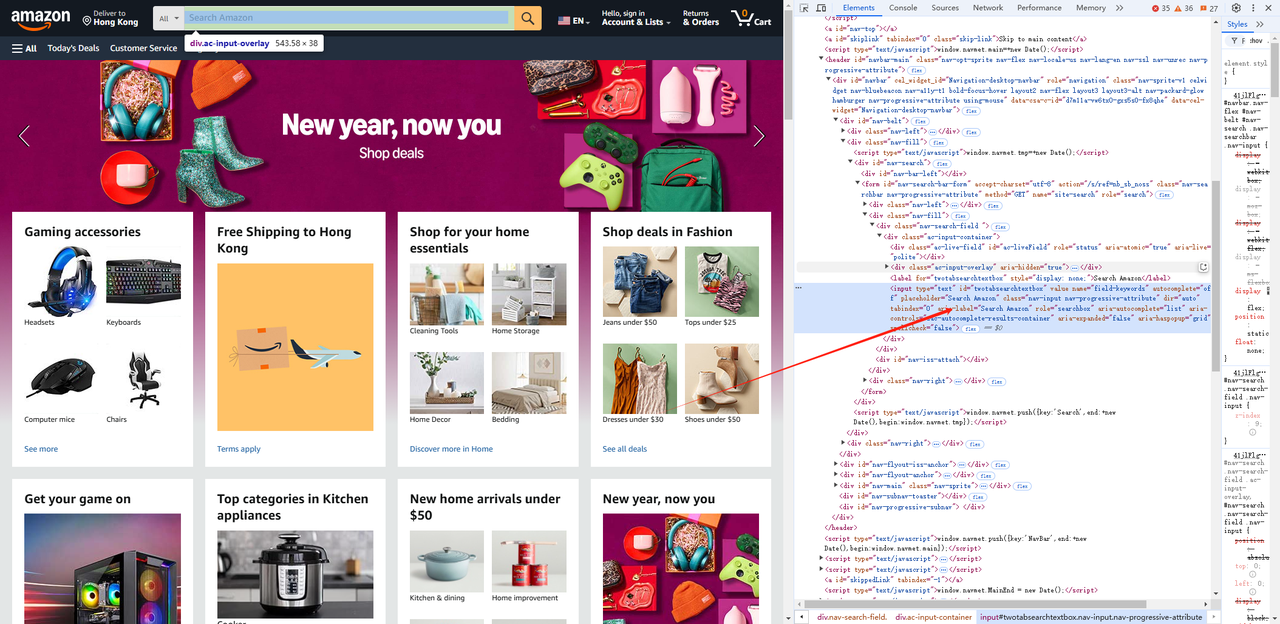
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')Você pode substituir iphone 15 pelo conteúdo que deseja rastrear.
- Então chegamos à página da lista de produtos e obtemos todos os elementos div cujo atributo de função é listitem.
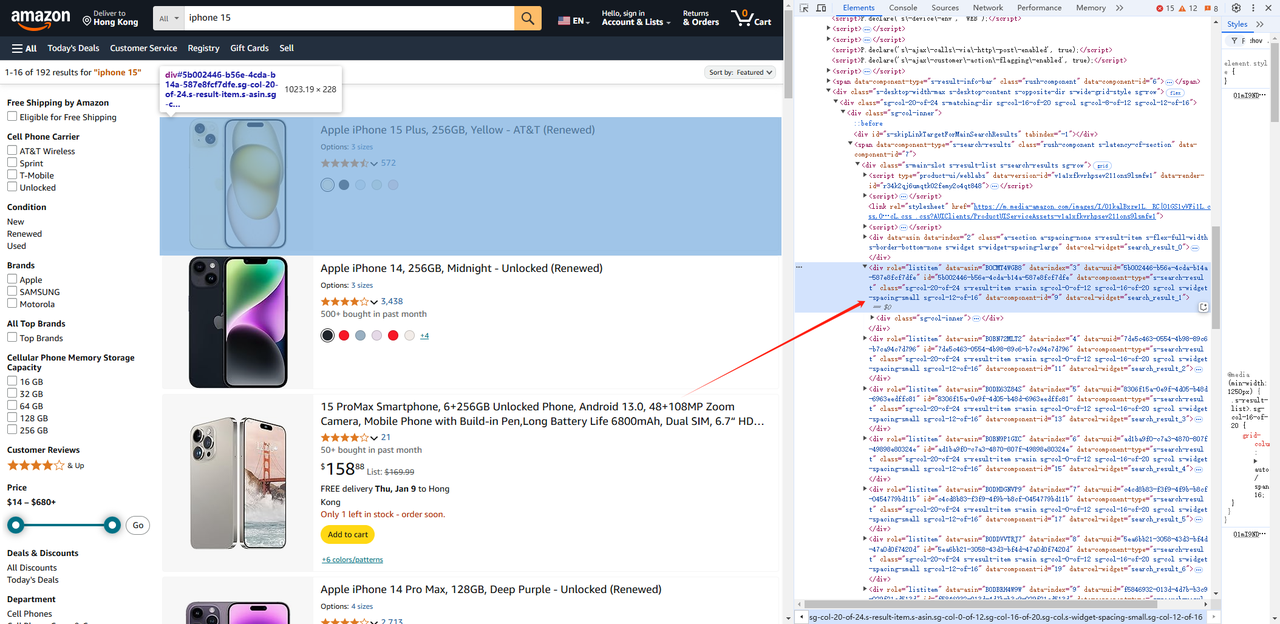
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // Você precisa esperar que o elemento seja renderizado antes de buscá-lo
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- Da mesma forma, podemos obter informações do produto, como imagens, títulos, links, etc., para cada elemento.
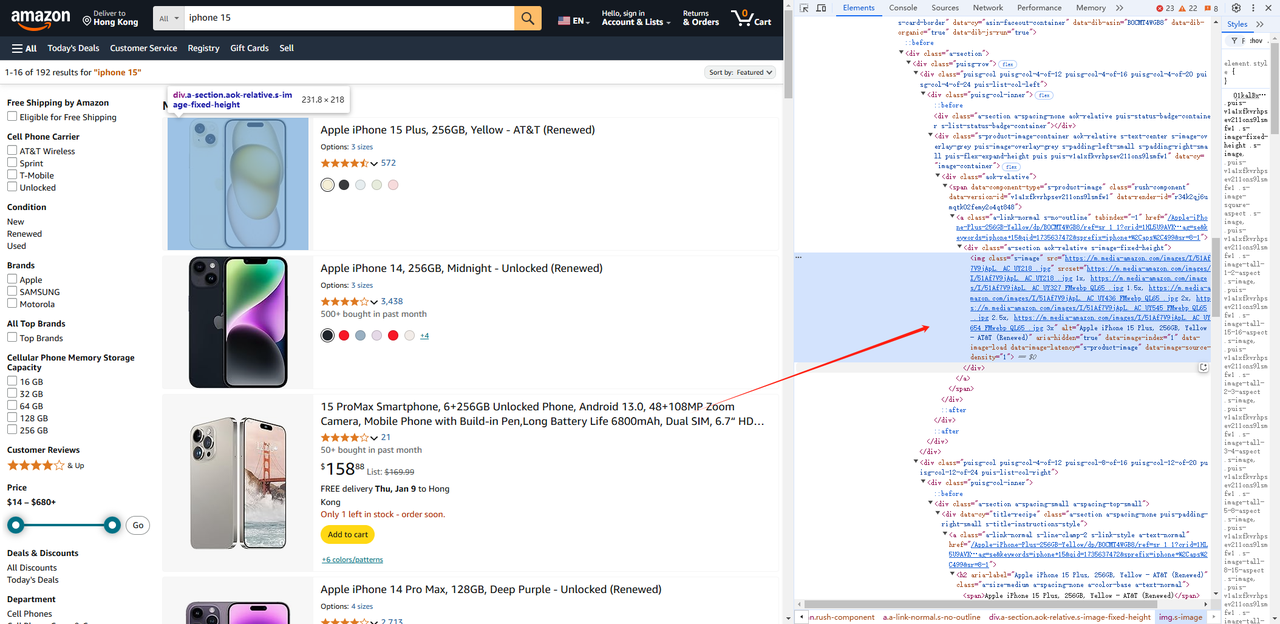
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
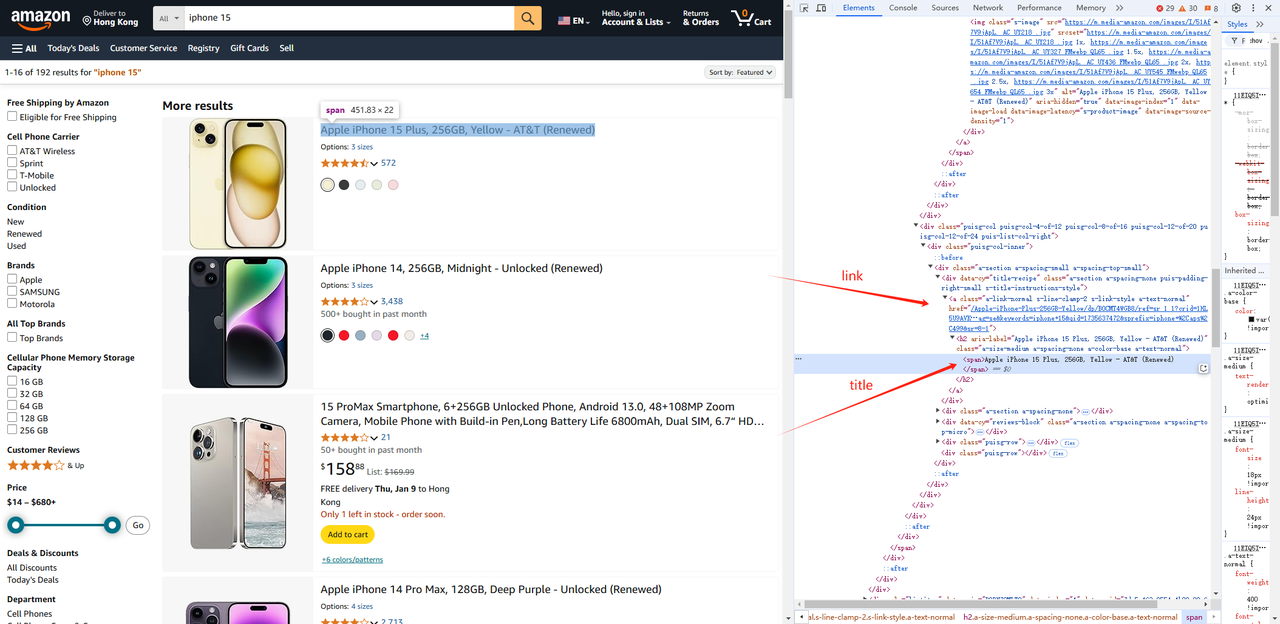
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}Execute o seguinte código completo para obter o conteúdo rastreado:
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]Recursos avançados para usuários avançados
Ao realizar operações de web scraping em larga escala ou complexas, recursos avançados são essenciais para manter a eficiência, superar obstáculos e escalonar suas tarefas de scraping. O Scraping Browser Scrapeless oferece uma variedade de recursos poderosos para atender às necessidades de usuários profissionais que precisam de mais do que apenas recursos básicos de scraping, e também fornece alguns recursos avançados:
- Personalize os parâmetros de scraping para casos de uso específicos
Um dos principais desafios do web scraping é adaptar suas ferramentas para extrair exatamente o que você precisa sem gerar dados redundantes ou perder oportunidades. A Scrapeless oferece opções de personalização avançadas que permitem aos usuários definir parâmetros de scraping específicos para se adequar ao seu caso de uso exato.
- Lidar com CAPTCHA e proteções anti-scraping
Os sites costumam implantar desafios CAPTCHA e mecanismos anti-scraping complexos para bloquear robôs automatizados. O Scraping Browser Scrapeless é um navegador de impressão digital baseado em nuvem com recursos de desbloqueio de CAPTCHA. Essas soluções avançadas não apenas aumentam a velocidade da coleta de dados, mas também reduzem a probabilidade de serem detectadas ou bloqueadas por sites com medidas anti-bot robustas.
- Use proxies e rotações para escalabilidade e evite proibições de IP
Aumentar as operações de scraping muitas vezes leva os sites a banir IPs e limitar as taxas, o que interrompe a coleta de dados. Para aliviar esse problema, a Scrapeless fornece uma rede de proxy poderosa que inclui rotação de IP e pools de proxy para ajudá-lo a manter o rastreamento contínuo em larga escala sem interrupções. A Scrapeless fornece acesso a uma vasta rede proxy de mais de 80 milhões de IPs de mais de 200 países, garantindo que os usuários possam distribuir solicitações e evitar proibições de IP.
Melhores práticas para web scraping eficaz
O web scraping é uma ferramenta poderosa para empresas que buscam coletar dados valiosos da web. No entanto, para extrair dados de forma eficiente e evitar armadilhas comuns, é importante seguir as melhores práticas. Ao utilizar soluções baseadas em IA como a Scrapeless, as empresas podem aprimorar suas estratégias de scraping para garantir precisão, conformidade e escalabilidade. Aqui está uma análise das melhores práticas de web scraping, incluindo como a Scrapeless pode otimizar esses processos para você.
Garantir a precisão e a completude dos dados
Um dos principais desafios do web scraping é garantir que os dados coletados sejam precisos. Ao extrair grandes conjuntos de dados de uma variedade de fontes, é fácil encontrar problemas como dados ausentes ou inconsistências. Para combater isso, os algoritmos de IA na Scrapeless podem analisar automaticamente a estrutura da página da web e ajustar a abordagem de scraping para se adequar ao conteúdo.
Cumprir os padrões legais e éticos
Com o aumento do escrutínio sobre o web scraping, é fundamental operar dentro dos limites legais e éticos. Os scrapers devem estar cientes das leis de privacidade, dos termos de serviço do site e de regulamentos como o GDPR. A Scrapeless ajuda a manter a conformidade integrando a detecção inteligente de robots.txt para garantir que o scraping esteja de acordo com as regras definidas pelos proprietários do site.
Além disso, a IA pode ser usada para analisar o conteúdo da página da web e filtrar dados confidenciais ou protegidos, garantindo que as empresas evitem práticas antiéticas. Os algoritmos de IA da Scrapeless são projetados para ajudar os usuários a cumprir os requisitos legais, ajudando-os a evitar riscos como violação de propriedade intelectual ou violações de privacidade.
Evitar ser bloqueado por sites
Os sites costumam implantar medidas anti-scraping para detectar e bloquear scrapers automatizados. A tecnologia de IA da Scrapeless ajuda a evitar a detecção simulando o comportamento de navegação humana, fazendo com que as solicitações de scraping pareçam mais naturais. O algoritmo de IA ajusta a frequência das solicitações, o tempo e os cabeçalhos para imitar a atividade do usuário real, reduzindo muito a probabilidade de ser bloqueado.
Além disso, a Scrapeless usa rotação de proxy, um sistema baseado em IA que alterna automaticamente entre vários endereços IP para distribuir solicitações. Isso ajuda a contornar os limites de taxa e impede que os sites bloqueiem um único endereço IP por enviar muitas solicitações. Ao usar inteligentemente a rotação de proxy baseada em IA, a Scrapeless garante a extração ininterrupta de dados.
Otimizando a tecnologia Scrapeless para coleta de dados em larga escala
Para empresas envolvidas na coleta de dados em larga escala, a eficiência e a escalabilidade do scraping são críticas. Os recursos de IA da Scrapeless ajustam automaticamente as estratégias de scraping para garantir o desempenho ideal, mesmo ao extrair dados de sites complexos ou grandes. Por exemplo, o rastreador baseado em IA da Scrapeless pode lidar com conteúdo dinâmico, como sites com uso intensivo de JavaScript, permitindo que as empresas rastreiem uma gama maior de conteúdo que as ferramentas tradicionais podem ter dificuldade em lidar.
Além disso, os algoritmos de IA ajudam a priorizar os dados mais importantes, garantindo uma alocação eficiente de recursos ao processar grandes quantidades de informações. Isso permite um rastreamento em alto volume perfeito que atende às necessidades do negócio, mantendo a velocidade e o desempenho.
Seguir as melhores práticas de web scraping é fundamental para maximizar o valor dos dados coletados. Ao utilizar a tecnologia de rastreamento baseada em IA da Scrapeless, as empresas podem melhorar a precisão dos dados, garantir a conformidade legal, evitar ser bloqueadas por sites e otimizar as operações de rastreamento para coleta de dados em larga escala. Com a Scrapeless, as empresas podem acessar rapidamente, eficientemente e eticamente os dados de que precisam, ajudando-as a se manterem à frente em um espaço competitivo e baseado em dados.
Solução de problemas comuns de web scraping
- Alterações na estrutura do site
- Problema: Os sites atualizam frequentemente seu layout ou estrutura HTML, fazendo com que os scrapers que dependem de tags específicas parem de funcionar.
- Solução: Crie scrapers flexíveis usando técnicas dinâmicas ou implemente o tratamento de erros que possa se adaptar a pequenas mudanças. A Scrapeless oferece um scraper inteligente e baseado em IA que detecta alterações e se ajusta de acordo.
- Bloqueio de IP
- Problema: Os sites limitam o número de solicitações de um único endereço IP, bloqueando scrapers após muitas tentativas.
- Solução: Use Proxies Scrapeless com rotação de IP para distribuir solicitações entre vários IPs, tornando mais difícil para os sites detectarem padrões de scraping e bloquear o acesso.
- CAPTCHAs e mecanismos anti-scraping
- Problema: CAPTCHAs e outras medidas anti-bot (como desafios JavaScript) podem interromper seu scraper.
- Solução: Utilize o Scrapeless Captcha Solver para automatizar a resolução de CAPTCHA. Para páginas com uso intensivo de JavaScript, use o Scraping Browser Scrapeless, que lida eficientemente com conteúdo dinâmico.
- Limitação de taxa
- Problema: Os sites limitam o número de solicitações em um período de tempo específico para evitar sobrecarga do servidor, fazendo com que os scrapers falhem.
- Solução: Configure seu scraper com proxies e rotação e controles de limitação de taxa para imitar o comportamento humano e evitar atingir os limites de taxa.
- Imprecisão de dados ou informações ausentes
- Problema: O scraping resulta em dados incompletos ou imprecisos devido a erros na lógica de scraping ou análise de dados deficiente.
- Solução: Implemente verificações para validar os dados coletados e garantir que o scraper esteja configurado corretamente. A Scrapeless usa algoritmos baseados em IA para garantir a integridade e a consistência dos dados.
- Questões legais e éticas
- Problema: Raspar certos sites pode violar os termos de serviço ou leis locais, levando a consequências legais.
- Solução: Sempre garanta que você esteja em conformidade com os padrões legais e éticos. A Scrapeless fornece uma estrutura integrada para ajudar a garantir que suas atividades de scraping permaneçam dentro dos limites legais.
Para mais desafios comuns no web scraping e como resolvê-los, leia: Como resolver desafios de web scraping - Guia completo 2025
Perguntas frequentes sobre raspar páginas da web
1. Como raspo uma página da web?
O método mais simples é copiar manualmente os dados necessários diretamente da página da web e colá-los no documento.
Você também pode usar as ferramentas de desenvolvedor do navegador (como a função "Inspecionar" do Chrome) para visualizar a estrutura HTML da página da web e extrair dados dela. O mais simples é usar ferramentas sem código, como a Scrapeless, que permitem que os usuários configurem facilmente tarefas de scraping por meio de uma interface gráfica sem escrever código.
Com esses métodos, você pode raspar efetivamente a página da web e extrair os dados necessários.
2. É aceitável raspar dados de sites?
O web scraping é legal desde que você siga os termos de serviço do site, a política de uso de dados e as leis locais. Sempre verifique o arquivo robots.txt e os termos de serviço do site antes de raspar. É melhor seguir os limites de taxa e evitar raspar dados pessoais ou protegidos por direitos autorais.
3. Como extraio todas as páginas de um site?
Você pode usar um rastreador da web para raspar todas as páginas de um site. Isso envolve visitar recursivamente todos os links da página inicial ou outras páginas principais. Ferramentas como o Scraping Browser Scrapeless ou a API Scrapeless podem automatizar esse processo, extraindo dados de cada página com base na estrutura do site.
4. Que ferramenta é usada para web scraping?
Ferramentas comuns de web scraping incluem Scrapeless, BeautifulSoup, Selenium, Octoparse e Scrapy. Essas ferramentas permitem que os usuários automatizem o processo de extração de dados de sites enviando solicitações, analisando conteúdo HTML e fornecendo os dados em formatos estruturados como CSV, JSON ou Excel.
5. Você pode ganhar dinheiro com web scraping?
Sim, você pode ganhar dinheiro com web scraping fornecendo serviços de extração de dados para empresas, conduzindo pesquisas de mercado ou raspando dados publicamente disponíveis para clientes. O web scraping também pode ser usado para coletar dados para análise competitiva, geração de leads ou construção de bancos de dados especializados que são valiosos para setores como comércio eletrônico, imóveis e finanças.
Conclusão: Por que a Scrapeless é o futuro do web scraping
A Scrapeless fornece uma solução poderosa e baseada em IA para simplificar as tarefas de web scraping, trazendo enormes benefícios para desenvolvedores e empresas. Com seus recursos de ponta, a Scrapeless garante que sua coleta de dados seja eficiente, precisa e escalonável:
- Scraping com IA: Utiliza IA para melhorar a eficiência do scraping e lidar com conteúdo dinâmico e complexo.
- 10 vezes mais rápido: A operação otimizada do navegador o torna 10 vezes mais rápido que os métodos tradicionais de scraping.
- Contornar CAPTCHA e anti-scraping: Contorna automaticamente CAPTCHA e outras proteções anti-bot.
- Scraping personalizável: Personalize os parâmetros de scraping para atender às necessidades e casos de uso específicos.
- Fluxos de trabalho automatizados: A automação baseada em IA reduz a intervenção manual e simplifica a coleta de dados.
Se você é um desenvolvedor que busca melhorar a eficiência do scraping ou uma empresa que busca coletar dados estruturados em escala, a Scrapeless oferece uma solução abrangente para atender às suas necessidades. Não deixe a complexidade do web scraping atrasá-lo - comece a usar a Scrapeless hoje e desbloqueie o potencial da extração de dados da web perfeita e baseada em IA.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


