
Web Crawler em Python: Um Guia Passo a Passo para 2025
Advanced Data Extraction Specialist
Com o aumento dramático na quantidade de dados, a Web Crawling se tornou uma ferramenta em áreas como ciência de dados, pesquisa de mercado e análise da concorrência. Entre as linguagens de programação, Python se tornou a linguagem preferida para o desenvolvimento de web crawlers (web crawlers Python) com sua sintaxe concisa e suporte poderoso de bibliotecas. Seja extraindo dados de uma plataforma de comércio eletrônico ou coletando os artigos mais recentes de um site de notícias, os web crawlers Python podem concluir a tarefa de forma eficiente. Este artigo fornecerá a você uma versão de 2025 de um guia passo a passo para ajudá-lo a dominar como usar Python para construir um web crawler poderoso, desde o conhecimento básico até técnicas avançadas, para melhorar abrangentemente suas capacidades de web crawling.
O que é um Web Crawler em Python e por que é importante para a extração de dados
Um web crawler é um programa automatizado projetado para rastrear informações da Internet de acordo com regras específicas. Ele acessa páginas da web simulando um navegador, extraindo os dados necessários e armazenando-os localmente. Esse processo geralmente inclui a seleção da URL inicial, o download do conteúdo da página da web, a análise de HTML, o acompanhamento de links e a repetição desse processo para obter mais dados. O papel dos web crawlers na extração de dados é crucial porque pode coletar informações eficientemente de um grande número de páginas da web e apoiar a construção de índices de mecanismos de busca e tarefas de análise de dados.
Vantagens do Web Crawler em Python
Existem muitas vantagens em escrever web crawlers em Python, especialmente em termos de flexibilidade e facilidade de uso. Primeiro, a sintaxe do Python é concisa e fácil de aprender, permitindo que os desenvolvedores comecem rapidamente e implementem uma lógica de rastreamento complexa. Segundo, o Python possui uma grande quantidade de bibliotecas e frameworks, como Scrapy e BeautifulSoup, que simplificam muito o processo de análise de páginas da web e extração de dados. Além disso, a natureza multiplataforma do Python permite que os crawlers sejam executados em diferentes sistemas operacionais, aumentando assim a flexibilidade de desenvolvimento e implantação.
💡 Leitura Relacionada: Web Scraping com Python em 2025
Técnicas avançadas para Web Crawling em Python
Quando se trata de desenvolver um web crawler Python, existem várias técnicas avançadas que podem melhorar suas capacidades de web scraping, especialmente quando se trata de conteúdo dinâmico e medidas anti-raspagem. Essas estratégias são cruciais para superar desafios como renderização de JavaScript, resolução de CAPTCHA e bloqueio de IP, que são frequentemente encontrados ao construir um web crawler Python. Aqui estão algumas estratégias importantes:
- Lidando com páginas da web dinâmicas:
- Use Selenium: Essa biblioteca permite que você automatize ações do navegador, permitindo que você aguarde o carregamento do conteúdo JavaScript antes de extrair dados.
- Realize solicitações Ajax: Analise as solicitações de rede nas ferramentas de desenvolvedor do seu navegador para identificar os endpoints da API. Use a biblioteca de solicitações em Python para enviar solicitações diretas a esses endpoints para uma recuperação de dados mais eficiente.
- Contornando medidas anti-raspagem:
- Utilize Proxies: Implemente IPs de proxy rotativos para distribuir solicitações entre vários endereços IP, dificultando para os sites detectarem e bloquear suas atividades de raspagem.
- Falsifique o User-Agent: Modifique a string do User-Agent nos cabeçalhos da sua solicitação para imitar navegadores populares. Isso ajuda a reduzir a probabilidade de ser sinalizado como um bot.
- Melhorando a eficiência:
- Implemente Programação Assíncrona: Use bibliotecas como asyncio e aiohttp para fazer solicitações concorrentes, acelerando significativamente o processo de extração de dados.
- Aproveite XPath ou Seletores CSS: Essas ferramentas permitem a segmentação precisa de elementos HTML, melhorando a precisão e a eficiência da sua extração de dados.
Configurando seu ambiente Python para Web Crawling
Antes de começar a configurar seu ambiente de Web Crawling, você precisa preparar alguns ambientes básicos:
- Python 3+: Baixe o instalador, clique duas vezes nele e siga o assistente de instalação.
- IDE Python: Visual Studio Code ou PyCharm com a extensão Python.
Em seguida, digite o seguinte comando no terminal para inicializar um projeto chamado python-crawler:
mkdir python-crawler
cd python-crawler
python -m venv envAo fazer web crawling, precisamos usar duas bibliotecas para solicitações HTTP e análise HTML. As duas bibliotecas mais populares em Python são:
- requests: Uma poderosa biblioteca de cliente HTTP que pode enviar solicitações HTTP e processar respostas.
- beautifulsoup4: Um analisador HTML e XML completo.
Digite os seguintes comandos no terminal para instalá-los:
pip install beautifulsoup4 requestsNa pasta do projeto, crie crawler.py e importe as dependências do projeto:
import requests
from bs4 import BeautifulSoupO projeto foi construído, vamos começar a rastrear a web.
Como raspar dados da Amazon usando Python
Raspar dados da Amazon pode gerar conteúdo sobre informações do produto, avaliações e tendências. No entanto, as medidas anti-raspagem da Amazon, como CAPTCHA e limitação de taxa de IP, tornam o processo desafiador. Neste guia, mostraremos como raspar dados da Amazon usando Python.
Como construir um Web Crawler simples em Python
Depois de configurar o ambiente de rastreamento do site de acordo com as etapas acima, você precisa seguir as etapas abaixo para criar um Web Crawler Simples em Python.
Etapa 1: Web Crawler básico usando Requests e BeautifulSoup
Exemplo de código
import requests
from bs4 import BeautifulSoup
class SimpleWebCrawler:
def __init__(self, start_url):
self.start_url = start_url
self.visited_urls = set()
self.urls_to_visit = [start_url]
def crawl(self):
while self.urls_to_visit:
current_url = self.urls_to_visit.pop(0)
if current_url in self.visited_urls:
continue
print(f"Crawling: {current_url}")
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
self.visited_urls.add(current_url)
self.extract_links(soup)
def extract_links(self, soup):
for link in soup.find_all('a', href=True):
absolute_link = link['href']
if absolute_link not in self.visited_urls and absolute_link not in self.urls_to_visit:
self.urls_to_visit.append(absolute_link)
if __name__ == "__main__":
crawler = SimpleWebCrawler("https://example.com")
crawler.crawl()Explicação
- Inicialização: A classe SimpleWebCrawler é inicializada com uma URL inicial e conjuntos para rastrear URLs visitadas e URLs a serem visitadas.
- Lógica de rastreamento: O método crawl processa as URLs na lista urls_to_visit, recuperando o conteúdo de cada página.
- Extração de links: O método extract_links encontra todos os hiperlinks na página e os adiciona à lista de URLs a serem visitadas se ainda não foram visitados.
Etapa 2: Usando Scrapy para rastreamento mais complexo
Se o seu projeto exigir recursos mais avançados, como o tratamento de várias solicitações simultaneamente ou a raspagem de sites grandes de forma eficiente, considere usar o Scrapy.
Exemplo básico do Scrapy
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ['https://example.com']
def parse(self, response):
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)Executando Scrapy
Você pode executar sua aranha Scrapy usando a linha de comando:
scrapy crawl my_spiderComo raspar dados da Amazon com Python
Em seguida, esta seção apresentará detalhadamente como usar Python para rastrear dados da Amazon.
Etapa 1. Primeiro, precisamos obter a página do produto e usar o método get para fazer uma solicitação:
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)response.content contém o documento HTML gerado pelo servidor. Isso é alimentado no BeautifulSoup, e a opção html.parser permite que você especifique o analisador que a biblioteca usará:
soup = BeautifulSoup(response.content, "html.parser")Etapa 2. Em seguida, precisamos obter os dados que queremos rastrear. Podemos usar seletores CSS para obter os elementos correspondentes.
BeautifulSoup fornece dois métodos, select e select_one, que ambos suportam estratégias de seletor CSS.
Antes de escrever o código, você pode abrir a ferramenta devtool para visualizar o CSS do elemento.
- Obtenha o título do produto:
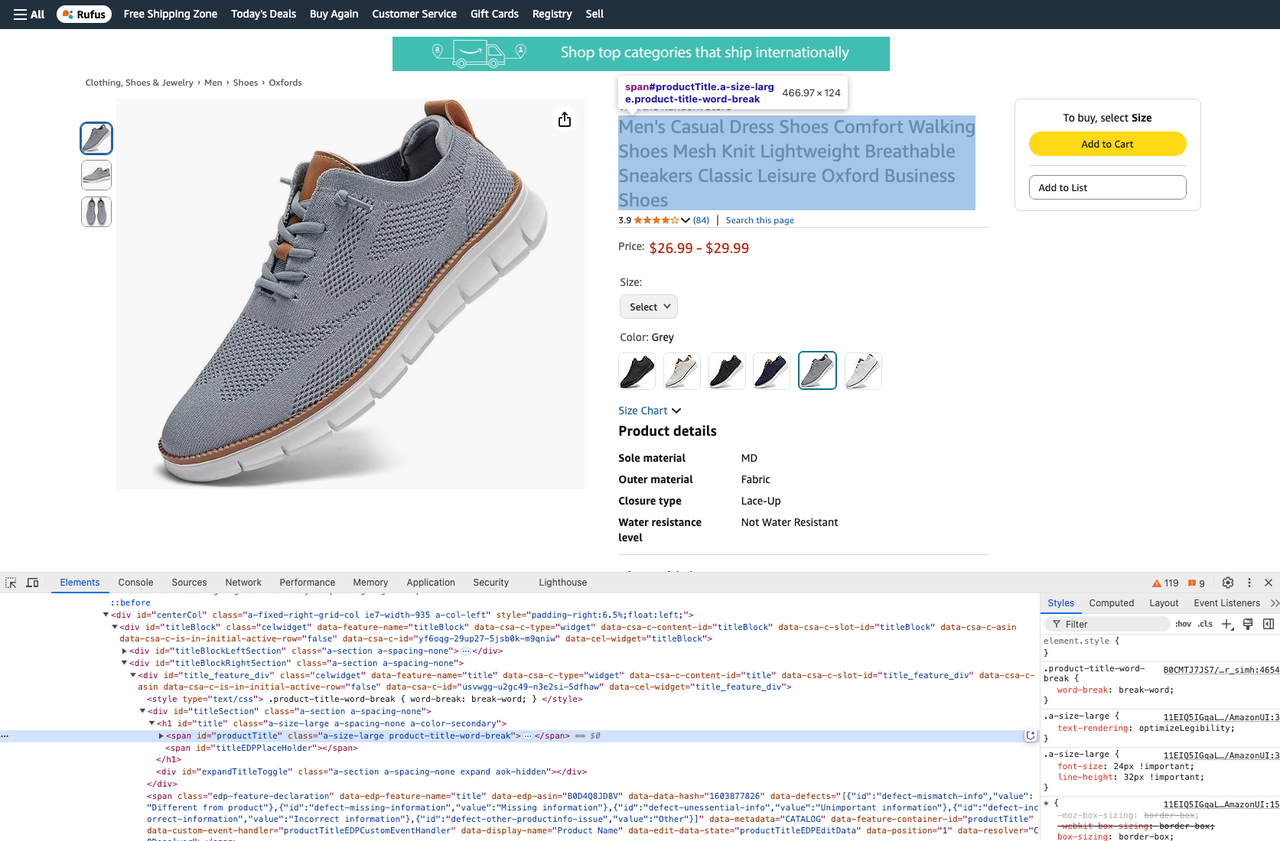
product_title = soup.select_one("#productTitle").text- Obtenha a descrição do produto:
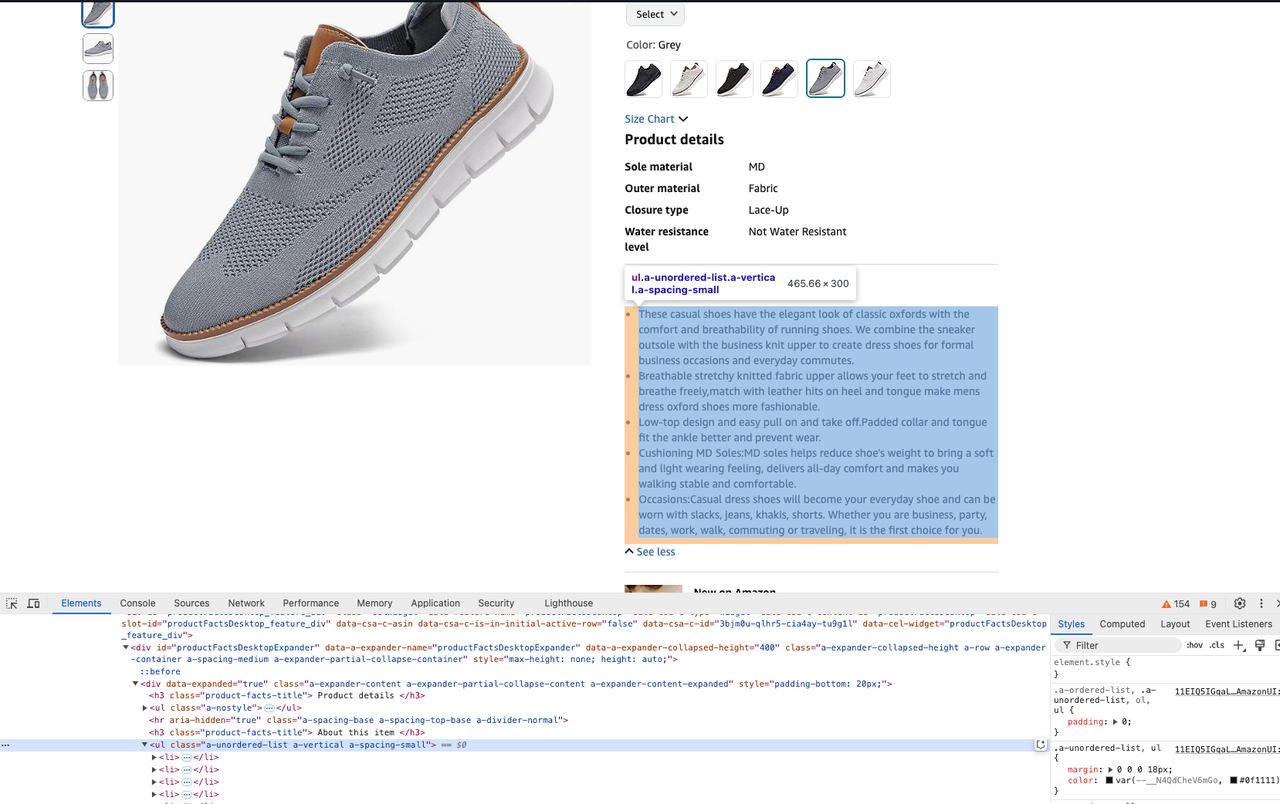
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text- Obtenha o preço de um produto:
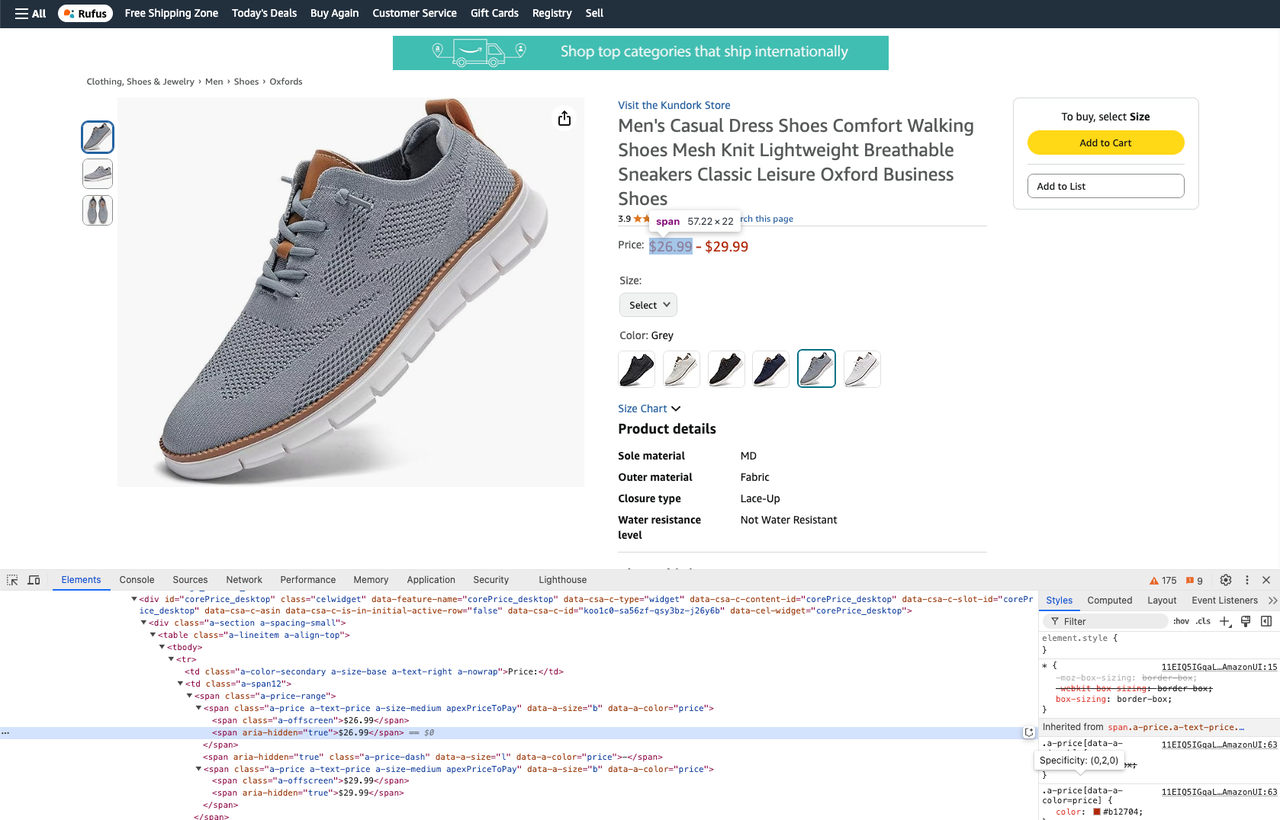
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text- Obtenha avaliações de produtos:
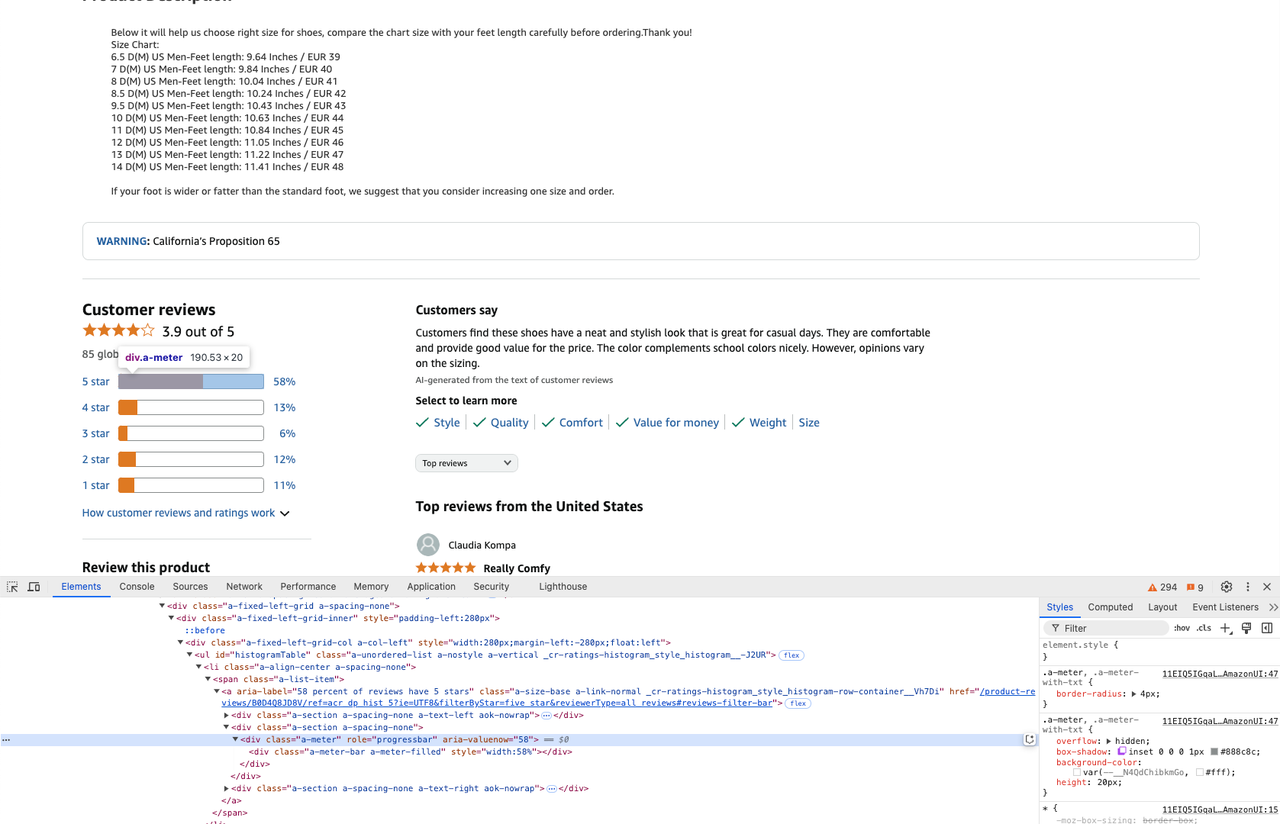
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'Etapa 3. Agora que rastreamos o site e obtivemos os dados que desejamos, podemos extrair as informações rastreadas para um arquivo csv.
Para fazer isso, adicione o seguinte ao topo do arquivo:
import csvEscreva os dados rastreados em um arquivo csv:
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])Execute o seguinte comando no terminal para executar o comando de rastreamento:
python crawler.pyEtapa 4. Após a conclusão da execução, podemos ver que o arquivo product.csv aparece na sua pasta. Abra este arquivo e poderemos ver os resultados de dados que rastreados:

O código completo é o seguinte:
import csv
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
product_title = soup.select_one("#productTitle").text
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])Como a API de Raspagem da Amazon da Scrapeless pode simplificar suas tarefas de Web Crawling
A API de Raspagem da Amazon da Scrapeless foi projetada para automatizar e simplificar o processo de extração de dados da Amazon, tornando-se uma ferramenta valiosa para desenvolvedores e empresas. Ao contrário do uso de uma abordagem de web crawler Python, que geralmente requer extensa codificação manual e tratamento de vários desafios, como rotação de IP ou contorno de CAPTCHA, a API Scrapeless simplifica o processo. Ela oferece uma variedade de recursos que melhoram a eficiência, permitindo que os usuários coletem facilmente dados, como preços de produtos, avaliações e descrições, sem a necessidade de scripts Python complexos.
Além da API de Raspagem da Amazon, a Scrapeless também inclui a API de Raspagem Shopee, API de Raspagem Lazada, API de Raspagem do Google Trends, API de Raspagem do Google Flights, API de Raspagem da Pesquisa Google, API de Raspagem do Airbnb, etc., fornecendo uma solução abrangente para extração de dados da web.
Pronto para começar a raspar sem esforço?
Cadastre-se na Scrapeless hoje mesmo e obtenha sua avaliação gratuita para experimentar o poder de nossas APIs. Libere a extração perfeita de dados de plataformas de comércio eletrônico líderes, como Amazon, Shopee e muito mais. Não perca—comece agora!
Vantagens sobre web crawlers Python manuais
1. Automação e eficiência
A API de Raspagem da Amazon automatiza todo o processo de extração de dados, garantindo que os usuários possam coletar rapidamente e com precisão grandes quantidades de dados. Isso elimina a codificação complexa que normalmente é necessária para web crawlers Python manuais, que geralmente envolvem lidar com vários desafios, como conteúdo dinâmico e medidas anti-raspagem.
2. Infraestrutura integrada
Com a API da Scrapeless, os usuários se beneficiam de uma infraestrutura robusta que gerencia automaticamente proxies, rotação de IP e resolução de CAPTCHA. Em contraste, os web crawlers Python manuais exigem que os desenvolvedores implementem esses recursos sozinhos, o que pode ser demorado e propenso a erros.
3. Interface sem código
A API fornece uma interface sem código que permite aos usuários iniciar tarefas de raspagem com chamadas de API simples. Isso é muito mais fácil do que escrever e depurar código para um web crawler Python, para que usuários de diferentes níveis de habilidade possam usá-lo.
Extraia dados da Amazon de forma eficiente por meio da API
Usando a API de Raspagem da Amazon da Scrapeless, os usuários podem extrair facilmente dados estruturados seguindo estas etapas:
-
Geração da chave da API: Cadastre-se na Scrapeless e gere sua chave de API exclusiva.
-
Clique em API de Raspagem e selecione Amazon.
-
Defina seus requisitos: Especifique o tipo de dados que você deseja raspar (por exemplo, detalhes do produto, avaliações).
-
Clique em Iniciar Raspagem: Solicite dados da Amazon usando chamadas de API simples.
-
Receba dados estruturados: A API Scrapeless fornece os dados coletados em vários formatos (por exemplo, JSON) para análise ou integração em seu sistema.
Ao aproveitar a API de Raspagem da Amazon da Scrapeless, os usuários podem simplificar muito suas tarefas de raspagem da web, permitindo que se concentrem em analisar insights em vez de gerenciar a complexidade da raspagem da web. Essa ferramenta poderosa não apenas melhora a produtividade, mas também garante a conformidade com os regulamentos de proteção de dados, tornando-a ideal para empresas que buscam obter uma vantagem competitiva em seus esforços de pesquisa de mercado.
Se você precisar integrar a Scrapeless ao seu próprio projeto, poderá consultar nosso código de exemplo. Você também pode clicar aqui para ver a documentação completa.
Exemplos de solicitação - Produto
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Exemplos de solicitação - Vendedor
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Exemplos de solicitação - palavras-chave
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Junte-se à comunidade Scrapeless Discord hoje!
Mantenha-se atualizado com notícias semanais, atualizações exclusivas e participe de eventos emocionantes para ter a chance de ganhar créditos. Não perca a diversão—faça parte da ação agora!
FAQ sobre web crawler python
FAQ #1: Qual a diferença entre web crawlers e web scrapers em Python?
Web crawlers e web scrapers têm usos diferentes no campo da extração de dados. Um web crawler é focado principalmente na descoberta; ele navega em sites para encontrar e indexar URLs, essencialmente criando um mapa da internet ou de um site específico. A saída de um web crawler geralmente é uma lista de URLs. Em contraste, um web scraper extrai dados específicos dessas URLs, como detalhes do produto ou informações de preços. Embora ambos os processos envolvam o download de conteúdo HTML, o objetivo de um crawler é coletar links, enquanto o objetivo de um scraper é filtrar e extrair pontos de dados relevantes dessas páginas.
FAQ #2: Como lidar com CAPTCHA ao construir um web crawler com Python?
Lidar com CAPTCHA é um dos aspectos mais desafiadores da construção de um web crawler com Python, pois é projetado especificamente para evitar acesso automatizado. Aqui estão algumas estratégias eficazes para lidar com CAPTCHA:
- Use navegadores sem cabeça: Navegadores sem cabeça combinados com ferramentas como Puppeteer ou Playwright podem ajudar a contornar CAPTCHAs imitando o comportamento de um navegador real.
- Evite acionar CAPTCHAs:
2.1 Use um serviço de proxy para rotar endereços IP para evitar a detecção.
2.2 Randomize os cabeçalhos de solicitação (por exemplo, agente do usuário) e introduza atrasos entre as solicitações para imitar a atividade humana.
Embora esses métodos possam ajudar a contornar CAPTCHAs, certifique-se sempre de que suas ações estejam de acordo com os termos de serviço e os requisitos legais do site.
FAQ #3: É legal raspar dados de sites como a Amazon usando Python?
A legalidade da raspagem da web depende de uma variedade de fatores, especialmente quando se destina a plataformas de comércio eletrônico como a Amazon. Aqui estão algumas considerações importantes:
- Conformidade com robots.txt: Os sites geralmente incluem um arquivo que descreve quais partes do site podem ser raspadas. Embora ignorá-lo não seja ilegal em si, pode ser considerado antiético ou contrário às melhores práticas.
- Uso justo e dados públicos: Se os dados forem publicamente acessíveis e usados para fins não comerciais (como pesquisa acadêmica), eles podem se enquadrar no "uso justo" em algumas jurisdições. No entanto, isso não é garantido.
Para evitar problemas legais:
- Antes de raspar dados, sempre verifique os termos de serviço do site.
- Se possível, peça permissão.
- Use uma API de raspagem de site legal, como a Scrapeless.
Conclusão
Neste artigo, exploramos a importância do Web Crawler em Python, especialmente sua ampla aplicação na raspagem de dados de comércio eletrônico. Como uma linguagem de programação flexível e poderosa, o Python fornece uma riqueza de bibliotecas e ferramentas que podem ajudar os desenvolvedores a rastrear dados eficientemente de plataformas de comércio eletrônico e obter dados importantes, como informações do produto, preços e comentários. No entanto, escrever e manter manualmente o Web Crawler geralmente requer muito tempo e esforço, especialmente quando confrontado com mecanismos complexos anti-crawler.
Neste contexto, a API de Raspagem da Amazon da Scrapeless fornece uma alternativa eficiente. Para usuários que precisam rastrear dados de comércio eletrônico em larga escala, a API Scrapeless não apenas simplifica o processo de rastreamento, mas também lida automaticamente com vários problemas complexos, ajudando os usuários a economizar tempo e esforço e obter facilmente os dados da Amazon necessários. Seja uma pequena empresa ou uma demanda de dados em larga escala, a Scrapeless é uma escolha ideal.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


