
Como Usar o Playwright para Contornar o Cloudflare em 2024
Advanced Data Extraction Specialist
Quando utiliza um navegador sem cabeça, o seu web scraper ainda está a ser bloqueado? Neste guia, irá descobrir como contornar o Cloudflare melhorando a máscara do Playwright.
Cloudflare: O que é?
O Bot Management, um serviço fornecido pelo provedor de segurança e otimização de desempenho Cloudflare, é um pesadelo para muitos scrapers. Cerca de um quinto dos websites utilizam firewalls de aplicação web (WAFs), que identificam e bloqueiam rotineiramente scrapers. Navegadores sem cabeça, como o Playwright e o Selenium, estão incluídos nesta categoria.
Como funciona o Cloudflare
O Cloudflare compara e separa o tráfego que foi gerado por bots e por utilizadores reais usando uma série de técnicas, tais como:
Análise de comportamento: Monitoriza vários aspetos das interações do utilizador com o website, incluindo cliques, movimentos do rato e tempos de carregamento da página.
Análise de reputação de IP: O endereço IP de cada pedido é comparado com uma base de dados para determinar se foi utilizado para scraping.
Análise de User-Agent: A string serve como um meio de identificação do browser ou dispositivo que efetua o pedido ao website. O Cloudflare consegue identificar strings de User-Agent genéricas ou imediatamente identificáveis usadas por scrapers.
Testes de CAPTCHA: O sistema pode optar por determinar se um utilizador que envia um pedido a um website é um robô ou um humano. O pedido será aprovado se o utilizador passar. Caso contrário, será banido.
Análise de taxa de pedidos: Usando esta técnica, é possível rastrear o volume de pedidos enviados para um website e identificar tendências que são características de bots automatizados. Os bots, por exemplo, frequentemente enviam um grande número de pedidos num curto espaço de tempo.
Porquê usar o Playwright Base não é suficiente para contornar o Cloudflare
O Playwright Base pode não conseguir contornar as defesas anti-bot do Cloudflare. A causa? Embora algumas das dificuldades possam ser ultrapassadas simulando um comportamento de navegação semelhante ao humano usando esta ou outras ferramentas de automatização de navegadores, métodos mais sofisticados, tais como a utilização de proxies e de user agents personalizados, podem exigir esforços adicionais para serem ultrapassados.
Para demonstrar isso, vamos iniciar um projeto NodeJS Playwright e ver como ele falha ao funcionar através do Cloudflare.
Passo 1: Verifique se o npm e o Node.js estão instalados no seu computador.
Passo 2: Utilize este comando para lançar um novo projeto depois de navegar para o diretório desejado:
language
npm initPasso 3: Agora utilize o seguinte comando para instalar o Playwright como uma dependência.
language
npm install playwrightPasso 4: Trabalho Fantástico! Já pode começar a utilizar o Playwright. Crie um novo ficheiro com uma extensão .js, como scraper.js, no diretório do seu projeto. Nele, construa um script para visitar https://crozdesk.com e obter uma captura de ecrã.
language
const playwright = require("playwright");
async function scraper() {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://crozdesk.com");
await page.waitForTimeout(1000);
await page.screenshot({ path: "screenshot.png", fullPage: true });
await browser.close();
}
scraper();O nosso scraper utiliza o Chromium como browser, como pode ver na linha quatro, mas é livre de utilizar outro.
Passo 5: Utilize este comando para executar todo o código:
language
node scraper.jsEste é o resultado:
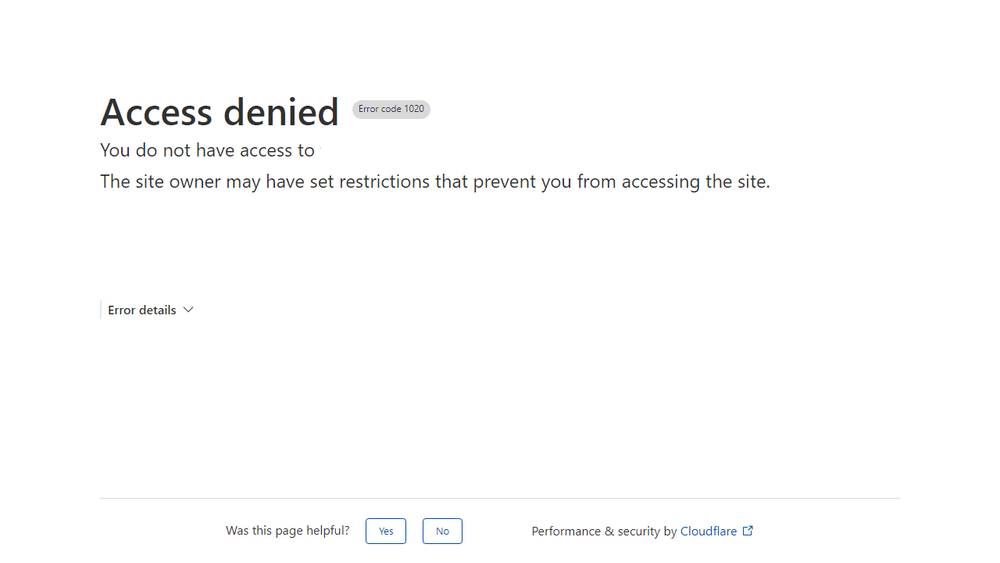
Infelizmente, a versão simples do Playwright é sinalizada como um bot e é então bloqueada de aceder ao website.
Na próxima parte, iremos abordar algumas estratégias que o ajudarão a contornar o Cloudflare. Continue a ler!
Como contornar o Cloudflare mascarando o Playwright
Vamos ver algumas estratégias para lidar com as técnicas de deteção do Cloudflare. Normalmente, para que o seu script funcione, será necessária uma combinação destes.
Método 1: Replicar a conduta humana
Para tornar o navegador automatizado mais humano, pode adicionar pausas aleatórias, deslocamentos e outras interações com o website ao nosso código de scraper Playwright anterior.
Método 2: Empregar proxies
É fácil ser banido do scraping de websites se enviar demasiados pedidos num curto espaço de tempo. Ao utilizar proxies rotativos para se fazer passar por vários utilizadores, pode evitar isso.
Método 3: Escolher um User-Agent único
Os User-Agents contêm factos sobre o cliente que efetua os pedidos, incluindo o sistema operativo e o browser. É preferível utilizar um User-Agent personalizado que imite um browser online popular, em vez do User-Agent predefinido do Playwright, para evitar ser detetado.
Método 4: Usar um Solver de CAPTCHA
Com o Playwright, pode utilizar uma variedade de ferramentas, como o Scrapeless, para resolver CAPTCHAs.
Está farto de bloqueios constantes de scraping web e de CAPTCHAs?
Apresentamos o Scrapeless - a solução de scraping web definitiva tudo-em-um!
Libere o potencial total da sua extração de dados com nosso poderoso conjunto de ferramentas:
Melhor Desbloqueador Web
Resolva automaticamente CAPTCHAs avançados, mantendo sua raspagem perfeita e ininterrupta.
Experimente a diferença - experimente gratuitamente!
Método 5: Adicionar Playwright-extra
Playwright-extra é uma estrutura para plugins Playwright que é leve e permite add-ons adicionais úteis. O que usaremos para contornar o Cloudflare é chamado Puppeteer-extra-plugin-stealth, e ele emprega uma série de estratégias, incluindo geração de eventos de mouse e modificação do User-Agent, para ocultar o uso de um navegador sem cabeça.
Em conclusão
Como você pode ver, você pode usar o Playwright para contornar o Cloudflare, mas pode ser necessário usar alguns truques sofisticados que podem não funcionar o tempo todo. Enquanto isso, o Scrapeless ajudará você a ter sucesso imediatamente e fornecerá uma chave API gratuita agora.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


