Como usar Playwright para contornar o CAPTCHA
Advanced Bot Mitigation Engineer
Alguma CAPTCHA já impediu você de raspar a web? Essas dificuldades podem causar dores de cabeça ao automatizar a coleta de dados. Felizmente, existem 2 maneiras de contornar o CAPTCHA usando o Playwright, que abordaremos neste post.
O Playwright consegue resolver o CAPTCHA?
O CAPTCHAs são projetados para serem difíceis para bots, mas simples para pessoas, mas também veremos como você pode usar o Playwright em conjunto com outras ferramentas úteis para eliminá-los.
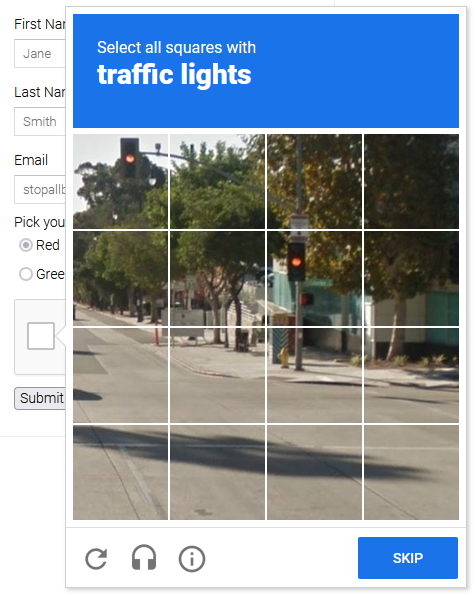
Uma lição crucial é que você pode: A) concluir o exame assim que ele acontecer; ou B) evitá-lo completamente e tentar novamente se ele aparecer.
No primeiro cenário, será necessário usar um resolvedor de CAPTCHA do Playwright, e isso pode ficar caro em grandes quantidades. Para evitar a detecção no segundo caso, seu raspador precisa imitar melhor o comportamento humano. Ambas as estratégias serão mostradas, mas como ponto de partida, a segunda é a melhor.
Vamos agora examinar como você pode colocar isso em prática!
Método 1: Use o Playwright base e o resolvedor de CAPTCHA para contornar o CAPTCHA.
O primeiro método que discutiremos é o uso do Playwright com o Scrapeless, um serviço que resolve CAPTCHAs empregando humanos em seu nome.
Você está cansado de CAPTCHAs e blocos contínuos de raspadores da Web?
Scrapeless: a melhor solução de raspagem online tudo em um disponível!
Utilize nosso formidável conjunto de ferramentas para liberar todo o potencial de sua extração de dados:
Melhor resolvedor de CAPTCHA
Resolução automatizada de CAPTCHAs complexos para garantir raspagem contínua e suave.
Experimente gratuitamente!
Método 2: Empregue o plugin Stealth no Playwright
Se você precisar coletar dados de um site que usa obstáculos CAPTCHA mais difíceis, a configuração anterior do Playwright não funcionará, mas o plugin Stealth é uma solução alternativa útil. Este projeto de código aberto adiciona elementos ao Playwright para torná-lo mais parecido com o tráfego web real:
- Seu User-Agent é ocultado.
- Para evitar a identificação do endereço IP, o WebRTC é desabilitado. Ele preserva a privacidade ocultando o histórico de navegação, mesmo que não proíba especificamente scripts de rastreamento.
- Para tornar suas solicitações mais naturais, ele aprimora seu navegador sem cabeça com componentes adicionais.
- Para adicionar mais vigor ao nosso exemplo, vamos tentar o Astra, um site que possui segurança Cloudflare mínima.
Instale as dependências necessárias antes de começar executando o seguinte comando dentro da pasta do seu projeto:
language
npm install playwright playwright-extraVale ressaltar que a estrutura playwright-extra possui o plugin Stealth.
Para aprimorar o Playwright, use playwright-extra para iniciar um navegador Chrome sem cabeça e chromium.use(pluginStealth) para habilitar puppeteer-extra-plugin-stealth. Este conjunto de tecnologias oferece mais proteções para dificultar a identificação do seu web scraper pelos sites.
language
const { chromium } = require('playwright-extra')
// Carrega o plugin stealth e usa os padrões (todos os truques para esconder o uso do playwright)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
// Use stealth
chromium.use(pluginStealth)
// Isso é tudo, o resto é o uso do playwright como normal 😊
chromium.launch({ headless: true }).then(async browser => {
// Crie uma nova página
const page = await browser.newPage()
// Vá para o site
await page.goto('https://www.scrapeless.com/')
// Aguarda o download da página
await page.waitForTimeout(1000);
// Tire uma captura de tela
await page.screenshot({ path: 'screen.png'})
// Feche o navegador
console.log('Tudo pronto, verifique a captura de tela. ✨')
await browser.close()
})Nosso site está preparado para scraping quando uma nova página é carregada usando browser.newPage() e um método page.goto() foi chamado.
Conclusão
Pode ser difícil contornar o CAPTCHA usando Playwright porque esse obstáculo conhecido tem o objetivo de impedir o acesso automático a sites. No entanto, você poderá raspar os dados desejados se tiver as ferramentas e bibliotecas adequadas.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


