
Como Desbloquear Sites ao Fazer Scraping com o Scrapeless Web Unlocker?
Senior Web Scraping Engineer
A raspagem web é amplamente usada para análise de dados e pesquisa de mercado, e, claro, análise da concorrência. No entanto, inevitavelmente encontraremos alguns obstáculos de rastreio, como bloqueio de IP, renderização complexa de JavaScript e verificação CAPTCHA. Uma preocupação fundamental que os usuários frequentemente levantam é: a raspagem de sites é legal?
Como evitar ser detectado e bloqueado ao executar trabalhos automatizados?
Este artigo mostrará os métodos mais eficazes e que economizam tempo.
Comece a ler agora!
Por que continuo sendo bloqueado ao raspar sites?
Antes de entrarmos nas dicas de raspagem web, primeiro, você precisa conhecer as medidas anti-bot comuns que pode encontrar ao raspar dados da web.
Se você sempre encontra bloqueios de rede, verifique os seguintes 8 aspectos:
1️⃣ Pedidos Excessivos do Mesmo IP
Os sites monitoram os padrões de tráfego e podem bloquear endereços IP que fazem muitas solicitações em um curto período. Isso geralmente é feito para evitar raspagem e abuso.
2️⃣ Lista Negra de IP
Se sua atividade de raspagem for sinalizada como suspeita, o site poderá incluir seu IP na lista negra. Isso pode acontecer se você acessar o site repetidamente do mesmo endereço IP ou usar padrões de comportamento identificáveis que se assemelham a um bot.
3️⃣ Uso de Captcha
Muitos sites usam desafios CAPTCHA para distinguir entre usuários humanos e bots. Se seu rastreador acionar um desafio CAPTCHA, ele poderá ser bloqueado até que o CAPTCHA seja resolvido.
4️⃣ Renderização JavaScript
Sites com JavaScript complexo podem ocultar ou gerar conteúdo dinamicamente. Os métodos de raspagem tradicionais têm dificuldades com isso, resultando em raspagens incompletas ou com falhas.
Esta é a razão mais básica pela qual os sites bloqueiam seu rastreador. Como superar o desafio de renderização JS? Não se preocupe. Podemos resolver isso mais tarde.
5️⃣ Detecção do User-Agent
Os sites geralmente verificam a string "User-Agent" para ver se a solicitação vem de um navegador real ou de um bot. Ferramentas de raspagem que não imitam adequadamente um navegador real podem ser detectadas e bloqueadas.
6️⃣ Limitação de Taxa e Expiração da Sessão
Os sites podem limitar o número de solicitações que você pode fazer dentro de um determinado período de tempo, e sua sessão pode expirar após um determinado número de ações. Acessar o site repetidamente pode levar a bloqueios temporários ou permanentes.
7️⃣ Impressão Digital
Os sites modernos usam técnicas de impressão digital do navegador para detectar raspagem automatizada. Este método acompanha padrões exclusivos, como resolução de tela, fuso horário e outras características do navegador, tornando mais fácil para os sites identificar e bloquear ferramentas de raspagem.
8️⃣ Bloqueio Geográfico
Alguns sites restringem o acesso com base na localização geográfica do endereço IP. Se você estiver raspando de uma região que não tem permissão de acesso, poderá encontrar bloqueios.
Scrapeless Web Unlocker - A Melhor Solução para Raspagem de Sites
Scrapeless não é apenas um desbloqueador de sites líder, mas também uma solução abrangente de raspagem web.
Como um poderoso desbloqueador web, o Scrapeless fornece aos usuários serviços de extração de HTML simplificados e eficientes. Com sua tecnologia avançada de seleção de proxy e mecanismo de desbloqueio automático, o Scrapeless pode facilmente contornar a proteção anti-crawler complexa e ajudar os usuários a obter rapidamente os dados necessários.
Por que devemos escolher o Scrapeless Web Unlocker?
⚙️ Renderização JavaScript eficiente (JSRender)
A tecnologia JSRender do Scrapeless usa um mecanismo de renderização de simulação de navegador avançado que pode lidar com o carregamento de conteúdo dinâmico em páginas da web em tempo real. É particularmente adequado para sites modernos que exigem JavaScript para gerar conteúdo, como páginas dinâmicas, aplicativos de página única (SPAs), etc.
Em comparação com as ferramentas de crawler tradicionais, o JSRender do Scrapeless pode renderizar dados complexos gerados por JavaScript em pouco tempo, o que é muito importante para rastrear conteúdo que requer interação ou atualizações dinâmicas (como páginas de detalhes de produtos em sites de comércio eletrônico). Por exemplo, ao raspar páginas de produtos da Shopee, Amazon e Lazada, o Scrapeless pode carregar e extrair todos os dados dinâmicos (como preço, estoque, avaliações, etc.) sem perder nenhuma informação importante.
- Como raspar dados de produtos da Amazon, informações do vendedor e dados de pesquisa?
- Raspe dados de produtos da Shopee facilmente
- Guia completo para raspar detalhes de produtos da Lazada 2025
🧩 Contornando o bloqueio de IP
O Scrapeless fornece um pool de proxy inteligente integrado que pode alternar automaticamente os IPs para garantir uma experiência de acesso estável. O pool de proxy seleciona inteligentemente recursos de IP de alta qualidade, de modo que, mesmo em rastreio em larga escala, ele ainda pode contornar efetivamente o bloqueio e as restrições de IP do site, garantindo que a tarefa de rastreio prossiga sem problemas.
Os usuários não precisam fazer nenhuma configuração adicional. Garantimos o maior grau de automação, economizando muito tempo e esforço de desenvolvimento. Os usuários podem se concentrar na lógica de negócios sem se preocupar com o bloqueio de IP.
⚔️ Solucionador de CAPTCHA automático
O Scrapeless possui um solucionador de CAPTCHA integrado capaz de lidar com CAPTCHAs de imagem, CAPTCHAs de texto e desafios do Google reCAPTCHA. Isso garante sessões de raspagem ininterruptas sem intervenção manual.
Para aqueles que se perguntam, raspar sites é legal? — a resposta depende dos termos de serviço do site e da natureza da coleta de dados. Embora informações publicamente disponíveis sejam frequentemente consideradas justas, considerações éticas e legais devem sempre ser levadas em consideração ao realizar raspagem na web.
O Scrapeless simplifica o processo automatizando os mecanismos de desvio, permitindo que empresas e desenvolvedores se concentrem na extração de insights valiosos de forma eficiente.
Como usar o Scrapeless Web Unlocker?
- Etapa 1. Faça login em Scrapeless.
- Etapa 2. Digite o "Web Unlocker".
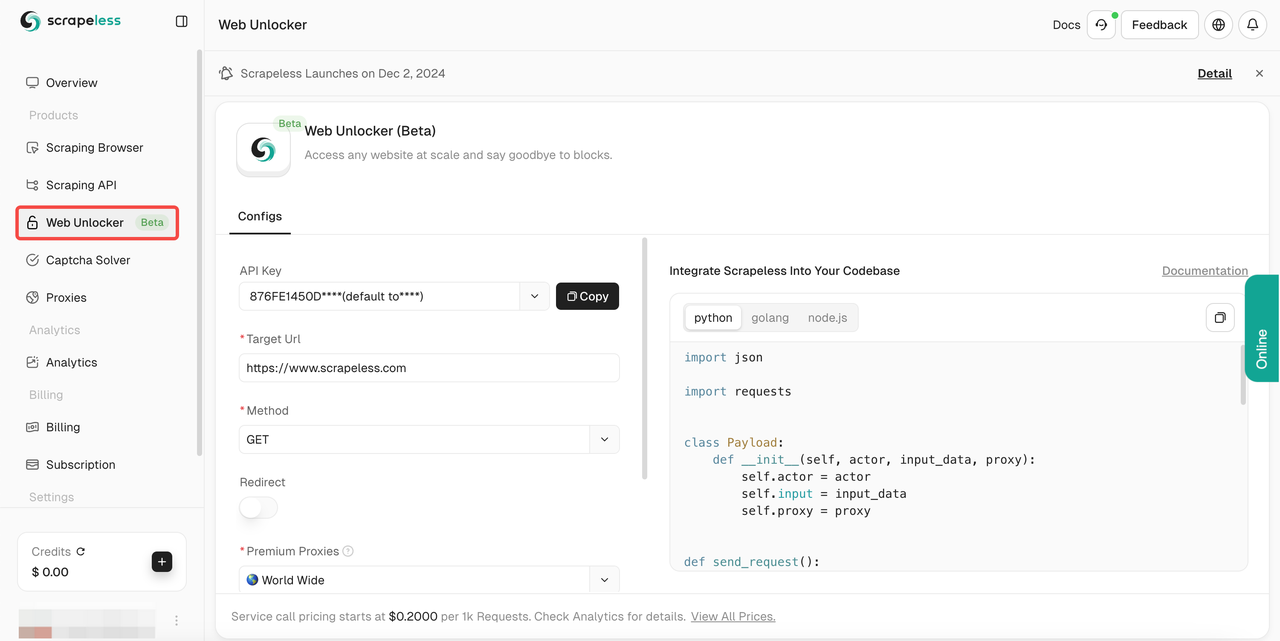
- Etapa 3. Configure o painel de operação à esquerda de acordo com suas necessidades:
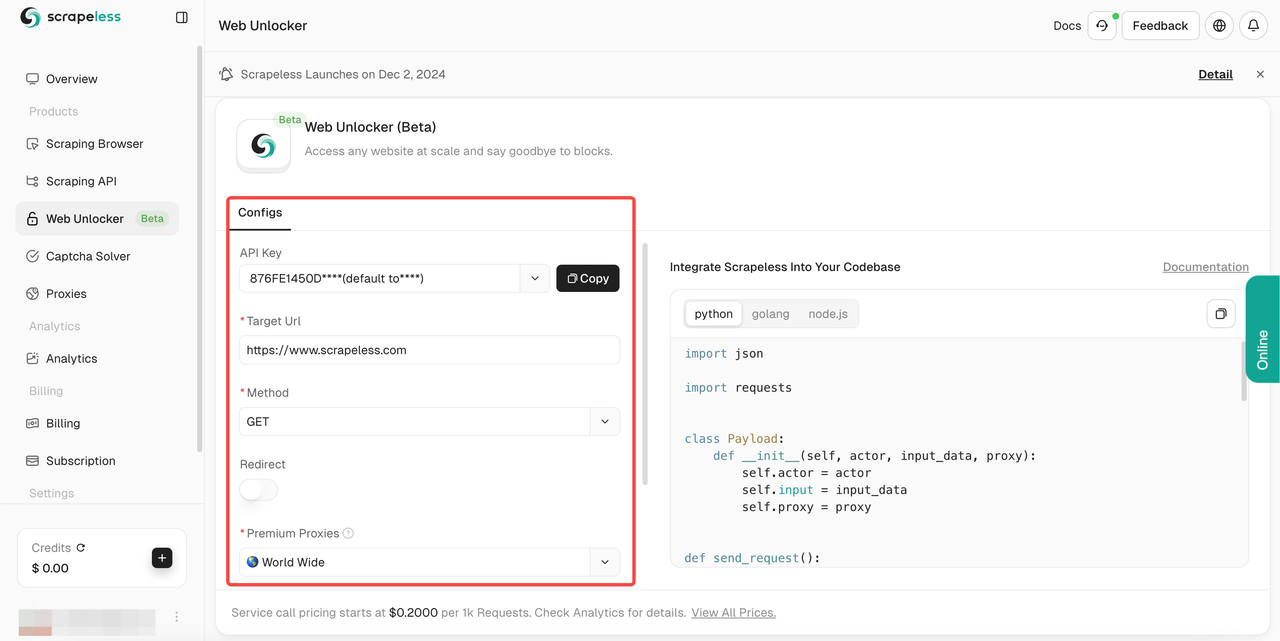
- Etapa 4. Após preencher sua
url de destino, o Scrapeless rastreará automaticamente o conteúdo para você. Você pode ver os resultados de rastreamento na caixa de exibição de resultados à direita. Selecione a linguagem que você precisa:Python,Golangounode.jse, finalmente, clique no logotipo no canto superior direito para copiar o resultado.
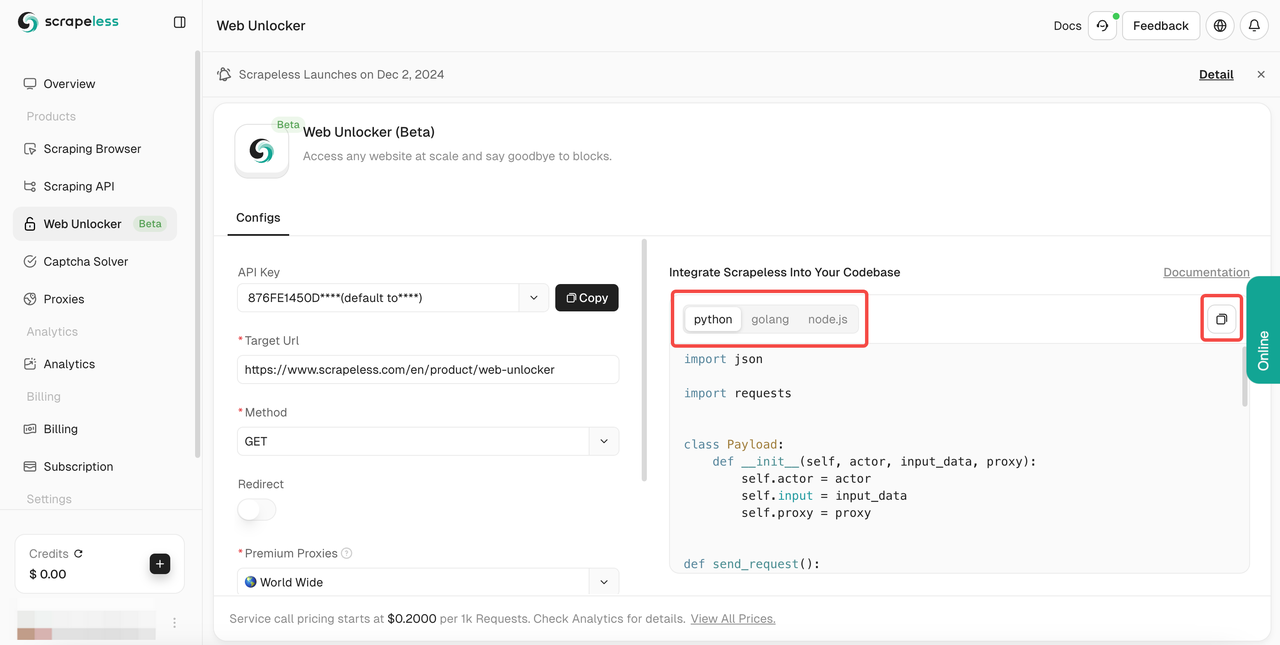
Isso garante que você possa acessar qualquer site público sem interrupções. Ele suporta vários métodos de rastreamento, se destaca na renderização de JavaScript e implementa tecnologia anti-rastreamento para fornecer as ferramentas para navegar na web de forma eficaz.
Ou você pode usar nosso código de amostra abaixo para integrar ao seu próprio projeto de forma eficaz:
- Url: Site de destino
- Método: Método de solicitação
- Redirecionar: Se permite redirecionamento
- Headers: Campos de cabeçalho de solicitação personalizados
Python:
Python
import requests
import json
url = "https://api.scrapeless.com/api/v1/unlocker/request"
payload = json.dumps({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": False,
"method": "GET",
"request_id": "",
"extractor": ""
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)JavaScript:
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/unlocker/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));Go
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/unlocker/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Soluções alternativas sem ser bloqueado
1. Rotação de IP
A primeira maneira de um site de raspagem detectar um rastreador web é verificando seu endereço IP e rastreando suas interações com o site. Se o servidor vir um padrão de comportamento estranho de "aquele usuário" ou uma frequência de solicitação impossível, o servidor pode bloquear esse endereço IP de acessar o site novamente.
Para evitar enviar todas as solicitações por meio do mesmo endereço IP, você pode usar um serviço de rotação de IP (como os proxies residenciais rotativos do Scrapeless) para direcionar suas solicitações por meio de um pool de proxies, ocultando seu endereço IP real enquanto rastreia o site. Isso permitirá que você rastreie a maioria dos sites sem ser bloqueado.
Por que usar proxies residenciais? Porque em alguns sites com requisitos de bloqueio mais rígidos, eles serão mais rigorosos em relação à detecção de seu proxy. Escolher um proxy residencial tornará a identidade do seu rastreador mais real, tornando seus esforços de raspagem de sites mais estáveis.
Por fim, usando a rotação de IP, seu rastreador pode fazer com que as solicitações pareçam vir de usuários diferentes e imitar o comportamento normal do tráfego online.
Ao usar os proxies Scrapeless, nosso sistema inteligente de rotação de IP utilizará anos de análise estatística e aprendizado de máquina para girar seus proxies conforme necessário de pools de proxy de data center, residenciais e móveis para garantir uma taxa de sucesso de 99,99%.
Obtenha seus proxies rotativos especiais gratuitamente agora!
2. Use um navegador sem cabeça
Os sites de raspagem mais difíceis podem detectar sinais sutis, como fontes da web, extensões, cookies do navegador e execução de JavaScript, para determinar se a solicitação vem de um usuário real.
Para raspar esses sites, você pode precisar implantar seu próprio navegador sem cabeça (ou deixar o Scrapeless Scraping Browser fazer isso por você!).
Os navegadores sem cabeça permitem que você escreva um programa para controlar um navegador da web real que é idêntico ao usado por um usuário real para evitar completamente a detecção.
3. Provedor de solucionador de CAPTCHA
Os solucionadores de CAPTCHA são serviços de terceiros que costumamos usar. Eles funcionam usando tecnologias como Reconhecimento Ótico de Caracteres (OCR), aprendizado de máquina ou solucionadores humanos de terceiros para resolver automaticamente os desafios CAPTCHA gratuitamente, permitindo que os bots de raspagem contornem os bloqueios da web.
Essas ferramentas permitem atividades contínuas e automatizadas de raspagem de sites, evitando interrupções causadas pela verificação CAPTCHA. Imitando o comportamento semelhante ao humano ou resolvendo CAPTCHAs em tempo real, eles ajudam a evitar a detecção como bots e mantêm um processo de raspagem suave.
No entanto, é importante considerar as implicações éticas e legais do uso de tais ferramentas, pois elas podem violar os termos de serviço e as políticas de privacidade do site. Raspar sites é legal? Depende da jurisdição e dos termos do site. Sempre garanta a conformidade com as leis e regulamentos locais. Além disso, essas ferramentas geralmente também têm preços mais altos.
4. Defina o agente de usuário real
Definir um User-Agent real é um método comum para evitar a detecção durante as atividades de raspagem de sites. Os sites costumam usar o cabeçalho User-Agent nas solicitações para identificar se eles vêm de um navegador de usuário real ou de um bot automatizado. Ao falsificar ou randomizar o User-Agent, os scripts de raspagem podem parecer como se estivessem vindo de um usuário regular, reduzindo as chances de serem detectados.
Como implementá-lo:
- Falsifique o User-Agent de um navegador real
Use strings User-Agent de navegadores comuns (como Chrome, Firefox, Safari, etc.) para imitar o comportamento de usuários reais. Por exemplo, em Python, você pode definir um cabeçalho User-Agent de navegador típico usando a biblioteca requests:
Python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)- Gire o User-Agent dinamicamente
Gire diferentes strings User-Agent para evitar a detecção usando um pool de proxy ou uma API (como random-user-agent). Isso torna mais difícil para os sites reconhecerem padrões de raspagem com base em um único User-Agent.
5. Combine outros cabeçalhos
Além do User-Agent, você também pode falsificar outros cabeçalhos (como Referer, Accept-Language, etc.) para imitar ainda mais a solicitação de um navegador real.
Geralmente, é melhor fazer parecer que está sendo acessado do Google.
Você pode fazer isso com um cabeçalho: "Referer": "https://www.google.com/"
Isso pode tornar ainda mais desafiador para os sites distinguirem entre solicitações automatizadas e interações genuínas do usuário.
6. Defina um intervalo aleatório entre as solicitações de rastreamento
Os sites costumam detectar atividades de raspagem com base na frequência e regularidade das solicitações. Se as solicitações chegarem muito rápido ou em um padrão previsível, é mais fácil para os sites identificar e bloquear o rastreador. Ao introduzir atrasos aleatórios entre as solicitações, você pode tornar seu comportamento de raspagem mais natural.
Você pode usar a função time.sleep() em Python para introduzir atrasos entre as solicitações. Ao definir um intervalo aleatório, você pode variar o tempo entre cada solicitação para tornar o comportamento menos previsível.
Python
import time
import random
import requests
# Envie uma solicitação com um atraso aleatório entre 1 e 3 segundos
headers = {'User-Agent': 'Mozilla/5.0'}
url = 'https://example.com'
for i in range(10):
response = requests.get(url, headers=headers)
print(f"Request {i+1} Status: {response.status_code}")
time.sleep(random.uniform(1, 3)) # Atraso aleatório entre 1 e 3 segundos7. Evite armadilhas Honeypot
Muitos sites usam links invisíveis para detectar rastreadores da web, pois apenas os bots os seguirão.
Para evitar a detecção, você deve verificar se um link possui as propriedades CSS "display: none" ou "visibility: hidden." Se alguma delas estiver definida, não visite o link! Deixar de fazer isso pode expor seu rastreador à detecção, permitindo que o servidor identifique os atributos de sua solicitação e o bloqueie.
Honeypots são um método comum usado por sites para detectar rastreadores, portanto, certifique-se de executar esta verificação em cada página que você raspar.
Além disso, alguns webmasters avançados também podem definir a cor do link como branca (ou combinar com a cor de fundo), portanto, vale a pena verificar as propriedades como "color: #fff;" ou "color: #ffffff" para garantir que o link permaneça invisível.
8. Exclua o cache do Google
Para evitar ser bloqueado ao raspar, é importante limpar ou contornar o cache do Google, pois ele pode armazenar suas interações anteriores e ajudar os sites a detectar atividades suspeitas de raspagem. Aqui estão algumas estratégias para lidar com o cache do Google:
Puppeteer: Use as funções clearBrowserCookies() e clearBrowserCache() no Puppeteer para limpar:
JavaScript
cookies e cache entre as sessões de raspagem.
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Limpe o cache e os cookies
await page.clearBrowserCache();
await page.clearBrowserCookies();Hora de tornar o rastreamento simples e eficiente!
O Scrapeless Web Unlocker é uma ferramenta poderosa que integra um pool de proxy inteligente, renderização JavaScript eficiente (JSRender) e processamento automático de CAPTCHA, projetado para resolver problemas comuns na raspagem de sites. O Scrapeless torna as tarefas complexas de raspagem simples, eficientes e confiáveis.
Se você deseja quebrar as limitações da raspagem e melhorar a eficiência, seja lidando com páginas dinâmicas complexas ou tarefas de raspagem em larga escala, o Scrapeless Web Unlocker é sua solução confiável.
Comece a usar o Scrapeless gratuitamente agora para experimentar um desempenho de raspagem incomparável e facilitar sua coleta de dados!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


