
Scrapeless SDK Lançado Oficialmente: Sua Solução Completa para Web Scraping e Navegador
Expert Network Defense Engineer
Estamos empolgados em anunciar que o SDK oficial Scrapeless já está disponível! 🎉
É a ponte definitiva entre você e a poderosa plataforma Scrapeless — tornando a extração de dados da web e a automação de navegadores mais simples do que nunca.
Com apenas algumas linhas de código, você pode realizar raspagem de dados em larga escala e extração de dados SERP, fornecendo suporte estável para sistemas de IA Agentic.
O SDK Scrapeless oferece aos desenvolvedores um wrapper oficial para todos os serviços principais, incluindo:
- Navegador de Raspagem: Uma camada de automação baseada em Puppeteer e Playwright, suportando cliques reais, preenchimento de formulários e outros recursos avançados.
- API do Navegador: Crie e gerencie sessões de navegador, ideal para necessidades de automação avançadas.
- API de Raspagem: Busque páginas da web e extraia conteúdo em múltiplos formatos.
- API Deep SERP: Raspagem fácil de resultados de mecanismos de busca do Google e mais.
- API de Raspagem Universal: Raspagem da web de propósito geral com renderização JS, captura de tela e extração de metadados.
- API de Proxy: Configure proxies instantaneamente, incluindo endereços IP e geolocalização.
Se você é um engenheiro de dados, desenvolvedor de rastreadores, ou parte de uma startup construindo produtos baseados em dados, o SDK Scrapeless ajuda você a adquirir os dados de que precisa de forma mais rápida e confiável.
Desde a automação do navegador até a análise de resultados de mecanismos de busca, da extração de dados da web à gestão automática de proxies, o SDK Scrapeless simplifica todo o seu fluxo de trabalho de aquisição de dados.
👉 Ver Exemplos de Código Completos
Referência de Uso do SDK Scrapeless
Pré-requisito
Faça login no Painel Scrapeless e obtenha a Chave da API
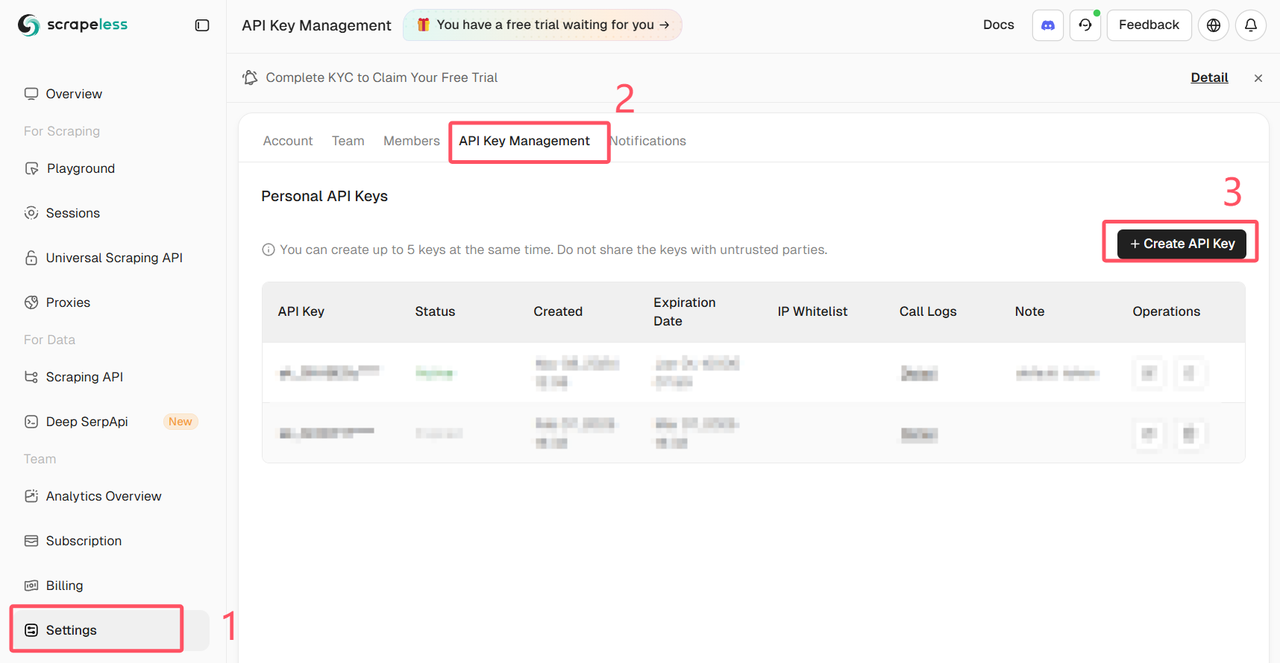
Instalação
- npm:
Bash
npm install @scrapeless-ai/sdk- yarn:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdkConfiguração Básica
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// Inicializar o cliente
const client = new Scrapeless({
apiKey: 'sua-chave-api' // Obtenha sua chave da API em https://scrapeless.com
});Variáveis de Ambiente
Você também pode configurar o SDK usando variáveis de ambiente:
Bash
# Requerido
SCRAPELESS_API_KEY=sua-chave-api
# Opcional - Endpoints de API personalizados
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.comNavegador de Raspagem (Wrapper de Automação de Navegador)
O módulo Navegador de Raspagem fornece uma API unificada de alto nível para automação de navegadores, construída sobre a API do Navegador Scrapeless. Ele suporta tanto Puppeteer quanto Playwright, e estende o objeto de página padrão com métodos avançados, como realClick, realFill e liveURL para uma automação mais semelhante à humana.
Exemplo de Puppeteer:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'minha-sessão',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'meuusuario');
const urlInfo = await page.liveURL();
console.log('URL atual da página:', urlInfo.liveURL);
await browser.close();Exemplo de Playwright:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'minha-sessão',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'meuusuario');
const urlInfo = await page.liveURL();
console.log('URL atual da página:', urlInfo.liveURL);
await browser.close();👉 Visite nossa documentação para mais casos de uso
👉 Integração com um clique via GitHub
Exemplo Prático: Raspagem de Resultados de Busca "Air Max" em Nike.com
Suponha que você está construindo um sistema de backend para uma plataforma de comparação de calçados e precisa buscar resultados de busca para "Air Max" do site oficial da Nike em tempo real. Tradicionalmente, você teria que implantar Puppeteer, lidar com proxies, evitar bloqueios, analisar estruturas de páginas… trabalhoso e propenso a erros.
Agora, com o SDK Scrapeless, todo o processo leva apenas algumas linhas de código:
Passo 1. Instalar o SDK
Use seu gerenciador de pacotes preferido:
Python
npm install @scrapeless-ai/sdkPasso 2. Inicializar o Cliente
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'sua-chave-api' // Obtenha em https://scrapeless.com
});Passo 3. Extração de SERP com Um Clique
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);Você não precisa se preocupar com proxies, mecanismos anti-bot, emulação de navegador ou rotação de IP — Scrapeless cuida de tudo isso nos bastidores.
Exemplo de Saída
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=pt-BR',
source: 'Nike',
source_logo: '',
title: "Tênis Nike Air Max 1 Masculino",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}Agora você pode armazenar esses resultados em seu banco de dados ou usá-los diretamente para exibição e análise de ranking.
Instale o SDK Scrapeless Agora
O SDK Scrapeless para Node.js torna a extração de dados da web e a automação de navegadores mais fáceis do que nunca. Se você está construindo uma ferramenta de monitoramento de preços, um sistema de análise de SERP ou simulando o comportamento real do usuário — uma única linha de código conecta você à poderosa infraestrutura do Scrapeless.
O SDK Scrapeless é de código aberto sob a licença MIT. Desenvolvedores são bem-vindos para contribuir com código, enviar problemas ou se juntar à nossa comunidade no Discord para mais ideias!
✅ Teste Gratuito Disponível
🔗 Leia a Documentação
💬 Tem Dúvidas? Junte-se à Nossa Comunidade no Discord
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


