
Quais são as melhores práticas para web scraping?
Senior Web Scraping Engineer
Introdução: Um Novo Paradigma de Automação de Navegadores e Coleta de Dados na Era da IA
Com a rápida ascensão da IA generativa, agentes de IA e aplicações intensivas em dados, os navegadores estão evoluindo de "ferramentas de interação com o usuário" tradicionais para "motores de execução de dados" para sistemas inteligentes. Neste novo paradigma, muitas tarefas não dependem mais de únicos endpoints de API, mas aproveitam o controle automatizado do navegador para lidar com interações complexas em páginas, raspagem de conteúdo, orquestração de tarefas e recuperação de contexto.
De comparações de preços em sites de e-commerce e capturas de tela de mapas à análise de resultados de motores de busca e extração de conteúdo de redes sociais, o navegador está se tornando uma interface crucial para a IA acessar dados do mundo real. No entanto, a complexidade das estruturas modernas da web, robustas medidas anti-bot e altas demandas de concorrência representam desafios técnicos e operacionais significativos para soluções tradicionais, como instâncias locais do Puppeteer/Playwright ou estratégias de rotação de proxies.
Apresentamos o Scrapeless Scraping Browser—uma plataforma avançada de navegador baseada em nuvem, projetada especificamente para automação em larga escala. Ele supera barreiras técnicas fundamentais, como mecanismos anti-raspagem, detecção de impressões digitais e manutenção de proxies. Além disso, oferece agendamento de concorrência nativo em nuvem, simulação de comportamento humano e extração de dados estruturados, posicionando-se como um componente de infraestrutura vital na próxima geração de sistemas de automação e pipelines de dados.
Este artigo explora as capacidades centrais do Scrapeless e suas aplicações práticas na automação de navegadores e raspagem da web. Ao analisar as tendências atuais da indústria e direções futuras, temos como objetivo fornecer aos desenvolvedores, construtores de produtos e equipes de dados um guia abrangente e sistemático.
I. Contexto: Por Que Precisamos do Scrapeless Scraping Browser?
1.1 A Evolução da Automação de Navegadores
Na era da automação movida por IA, os navegadores não são mais apenas ferramentas para interação humana—eles se tornaram pontos de execução essenciais para a aquisição de dados estruturados e não estruturados. Em muitos cenários do mundo real, APIs estão indisponíveis ou limitadas, tornando necessário simular o comportamento humano por meio de navegadores para coleta de dados, execução de tarefas e extração de informações.
Casos de uso comuns incluem:
- Comparação de preços em sites de e-commerce: Dados de preços e estoque são frequentemente carregados de forma assíncrona no navegador.
- Análise de páginas de resultados de motores de busca: O conteúdo deve ser totalmente carregado ao rolar e clicar em elementos da página.
- Sites multilíngues, sistemas legados e plataformas de intranet: O acesso a dados é impossível via API.
Soluções tradicionais de raspagem (por exemplo, Puppeteer/Playwright rodando localmente ou configurações de rotação de proxies) frequentemente sofrem com baixa estabilidade em alta concorrência, bloqueios frequentes de anti-bot e altos custos de manutenção. O Scrapeless Scraping Browser, com seu deployment nativo em nuvem e simulação de comportamento de navegador real, fornece aos desenvolvedores uma plataforma de automação de navegador de alta disponibilidade e confiável—servindo como infraestrutura crítica para sistemas de automação de IA e fluxos de trabalho de dados.
1.2 O Desafio dos Mecanismos Anti-Bot
Ao mesmo tempo, à medida que as tecnologias anti-bot evoluem, ferramentas de rastreamento tradicionais são cada vez mais sinalizadas como tráfego de bots por sites-alvo, resultando em bloqueios de IP e restrições de acesso. Mecanismos comuns de anti-raspagem incluem:
- Impressão digital do navegador: Detecta padrões de acesso anômalos via User-Agent, renderização de canvas, handshake TLS e mais.
- Verificação CAPTCHA: Exige que os usuários provem que são humanos.
- Lista negra de IPs: Bloqueia IPs que acessam com muita frequência.
- Algoritmos de análise comportamental: Detectam movimentos de mouse incomuns, velocidades de rolagem e lógica de interação.
O Scrapeless Scraping Browser supera efetivamente esses desafios por meio da personalização precisa de impressões digitais de navegadores, resolução integrada de CAPTCHA e suporte flexível a proxies—tornando-se infraestrutura central para a próxima geração de ferramentas de automação.
II. Capacidades Centrais do Scrapeless
O Scrapeless Scraping Browser oferece poderosas capacidades centrais, oferecendo aos usuários recursos de interação de dados estáveis, eficientes e escaláveis. Abaixo estão seus principais módulos funcionais e detalhes técnicos:
2.1 Ambiente Real de Navegador
O Scrapeless é construído sobre o motor Chromium, proporcionando um ambiente de navegador completo capaz de simular o comportamento real do usuário. As principais características incluem:
- Falsificação de impressão digital TLS: Finge parâmetros de handshake TLS para contornar mecanismos tradicionais de anti-bot.
- Ofuscação dinâmica de impressões digitais: Ajusta User-Agent, resolução de tela, fuso horário, etc., para fazer com que cada sessão pareça altamente humana.
- Suporte à localização: Personaliza configurações de idioma, região e fuso horário para tornar as interações com sites-alvo mais naturais.
Personalização Profunda de Impressões Digitais de Navegadores
O Scrapeless oferece uma personalização abrangente de impressões digitais de navegadores, permitindo que os usuários criem ambientes de navegação mais "autênticos":
- Controle de User-Agent: Defina a string User-Agent em solicitações HTTP do navegador, incluindo o motor do navegador, versão e sistema operacional.
- Mapeamento de resolução de tela: Defina os valores de retorno de
screen.widthescreen.heightpara simular tamanhos de exibição comuns. - Bloqueio de propriedade de plataforma: Especifique o valor de retorno de
navigator.platformem JavaScript para simular o tipo de sistema operacional. - Emulação de ambiente localizado: Suporta totalmente configurações de localização personalizadas, afetando a renderização de conteúdo, formato de hora e detecção de preferência de idioma em sites.
2.2 Implantação baseada em nuvem e escalabilidade
Scrapeless está totalmente implantado na nuvem e oferece as seguintes vantagens:
- Sem recursos locais necessários: Reduz os custos de hardware e melhora a flexibilidade de implantação.
- Nós distribuídos globalmente: Suporta tarefas concorrentes em larga escala e supera restrições geográficas.
- Suporte a alta concorrência: De 50 a sessões concorrentes ilimitadas — ideal para tudo, desde pequenas tarefas até complexos fluxos de trabalho de automação.
Comparação de Desempenho
Comparado a ferramentas tradicionais como Selenium e Playwright, Scrapeless se destaca em cenários de alta concorrência. Abaixo está uma tabela de comparação simples:
| Recurso | Scrapeless | Selenium | Playwright |
|---|---|---|---|
| Suporte à Concorrência | Ilimitado (personalização de nível empresarial) | Limitado | Moderado |
| Personalização de Impressão Digital | Avançada | Básica | Moderada |
| Resolução de CAPTCHA | Integrado (taxa de sucesso de 98%) Suporta reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, etc. |
Dependência externa | Dependência externa |
Ao mesmo tempo, o Scrapeless tem um desempenho melhor do que outros produtos concorrentes em cenários de alta concorrência. A seguir está um resumo de suas capacidades sob diferentes dimensões:
| Recurso / Plataforma | Scrapeless | Browserless | Browserbase | HyperBrowser | Bright Data | ZenRows | Steel.dev |
|---|---|---|---|---|---|---|---|
| Método de Implantação | Baseado em nuvem | Contêineres Puppeteer baseados na nuvem | Cluster de nuvem multi-navegador | Plataforma de navegador sem cabeça baseada na nuvem | Implantação em nuvem | Interface de API do navegador | Cluster de navegador + API do navegador |
| Suporte à Concorrência | 50 a Ilimitado | 3–50 | 3–50 | 1–250 | Até ilimitado (dependendo do plano) | Até 100 (plano empresarial) | Sem dados oficiais |
| Capacidade de Anti-Detecção | Reconhecimento e bypass de CAPTCHA gratuito, suporta reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, etc. | Bypass de CAPTCHA | Bypass de CAPTCHA + Modo Incongnito | Bypass de CAPTCHA + Incongnito + Gestão de Sessões | Bypass de CAPTCHA + Falsificação de Impressão Digital + Proxy | Impressões digitais personalizadas | Proxy + Reconhecimento de Impressão Digital |
| Custo de Tempo de Execução do Navegador | $0.063 – $0.090/hora (inclui bypass de CAPTCHA gratuito) | $0.084 – $0.15/hora (baseado em unidade) | $0.10 – $0.198/hora (inclui 2–5GB de proxy gratuito) | $30–$100/mês | ~$0.10/hora | ~$0.09/hora | $0.05 – $0.08/hora |
| Custo de Proxy | $1.26 – $1.80/GB | $4.3/GB | $10/GB (além da cota gratuita) | Sem dados oficiais | $9.5/GB (padrão); $12.5/GB (domínios premium) | $2.8 – $5.42/GB | $3 – $8.25/GB |
2.3 Solução automática de CAPTCHA e mecanismo de monitoramento de eventos
Scrapeless fornece soluções avançadas de CAPTCHA e estende uma série de funções personalizadas por meio do Protocolo DevTools do Chrome (CDP) para melhorar a confiabilidade da automação do navegador.
Capacidade de resolução de CAPTCHA
Scrapeless pode lidar automaticamente com tipos de CAPTCHA mainstream, incluindo: reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome, etc.
Mecanismo de monitoramento de eventos
Scrapeless fornece três eventos principais para monitorar o processo de resolução de CAPTCHA:
| Nome do Evento | Descrição |
|---|---|
| Captcha.detected | CAPTCHA detectado |
| Captcha.solveFinished | CAPTCHA resolvido |
| Captcha.solveFailed | Falha na resolução do CAPTCHA |
Estrutura de Dados de Resposta do Evento
| Campo | Tipo | Descrição |
|---|---|---|
| type | string | Tipo de CAPTCHA (ex.: recaptcha, turnstile) |
| success | boolean | Resultado da resolução |
| message | string | Mensagem de status (ex.: "NÃO_DETECTADO", "RESOLUÇÃO_FINALIZADA") |
| token? | string | Token retornado em caso de sucesso (opcional) |
2.4 Suporte a proxies poderoso
Scrapeless fornece um sistema de integração de proxy flexível e controlável que suporta múltiplos modos de proxy:
- Proxy residencial incorporado: suporta proxy geográfico em 195 países/regiões ao redor do mundo, pronto para uso.
- Proxy personalizado (assinatura premium): permite que os usuários se conectem ao seu próprio serviço de proxy, que não está incluído na cobrança de proxy do Scrapeless.
2.5 Repetição de sessão
A repetição de sessão é um dos recursos mais poderosos do Scrapeless Scraping Browser. Ele permite que você reproduza a sessão página por página para verificar as operações e solicitações de rede executadas.
3. Exemplo de código: Integração e uso do Scrapeless
3.1 Uso do Scrapeless Scraping Browser
Exemplo com Puppeteer
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=seu-token-api-scrapeless&session_ttl=180&proxy_country=QUALQUER';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Exemplo com Playwright
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=seu-token-api-scrapeless&session_ttl=180&proxy_country=QUALQUER';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();3.2 Exemplo de Código de Parâmetros de Impressão Digital do Scrapeless Scraping Browser
A seguir está um exemplo simples de código mostrando como integrar a função de personalização da impressão digital do navegador do Scrapeless através do Puppeteer e Playwright:
Exemplo com Puppeteer
const puppeteer = require('puppeteer-core');
// impressão digital personalizada do navegador
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // necessário
session_ttl: 180,
proxy_country: 'QUALQUER',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();
Exemplo com Playwright
const { chromium } = require('playwright-core');
// impressão digital personalizada do navegador
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // necessário
session_ttl: 180,
proxy_country: 'QUALQUER',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();
### 3.3 Exemplo de monitoramento de eventos CAPTCHA
O seguinte é um exemplo completo de código que usa o Scrapeless para monitorar eventos CAPTCHA, mostrando como monitorar o status da solução de CAPTCHA em tempo real:// Listen for CAPTCHA solving events
const client = await page.createCDPSession();
client.on('Captcha.detected', (result) => {
console.log('Captcha detectado:', result);
});
await new Promise((resolve, reject) => {
client.on('Captcha.solveFinished', (result) => {
if (result.success) resolve();
});
client.on('Captcha.solveFailed', () =>
reject(new Error('Falha na solução do CAPTCHA'))
);
setTimeout(() =>
reject(new Error('Tempo esgotado para solução do CAPTCHA')),
5 * 60 * 1000
);
});
Depois de dominar os recursos principais e as vantagens do Scrapeless Scraping Browser, podemos não apenas entender melhor seu valor na extração moderna da web, mas também aproveitar suas vantagens de desempenho de forma mais eficaz. Para ajudar os desenvolvedores a automatizar e extrair dados de sites de maneira mais eficiente e segura, agora exploraremos como aplicar o Scrapeless Scraping Browser em casos de uso específicos, com base em cenários comuns.
4. Melhores Práticas para Automação e Web Scraping Usando Scrapeless Scraping Browser
Aviso Legal e Precauções
Este tutorial cobre técnicas populares de web scraping para fins educacionais. A interação com servidores públicos requer diligência e respeito e aqui está um bom resumo do que não fazer:
- Não extraia dados a taxas que possam prejudicar o site.
- Não extraia dados que não estão disponíveis publicamente.
- Não armazene informações pessoais de cidadãos da UE que são protegidos pelo GDPR.
- Não reutilize conjuntos de dados públicos inteiros, o que pode ser ilegal em alguns países.
Entendendo a Proteção do Cloudflare
- O que é Cloudflare?
Cloudflare é uma plataforma de nuvem que integra rede de distribuição de conteúdo (CDN), aceleração de DNS e proteção de segurança. Os sites usam Cloudflare para mitigar ataques de Negação de Serviço Distribuída (DDoS) (ou seja, sites ficando offline devido a múltiplos pedidos de acesso) e garantir que os sites que o utilizam estejam sempre operacionais.
Aqui está um exemplo simples para entender como o Cloudflare funciona:
Quando você visita um site que tem o Cloudflare habilitado (como example.com), seu pedido primeiro chega ao servidor de borda do Cloudflare, não ao servidor de origem. O Cloudflare então determinará se permitirá que seu pedido continue com base em várias regras, como:
- Se a página em cache pode ser retornada diretamente;
- Se você precisa passar por um teste de CAPTCHA;
- Se seu pedido será bloqueado;
- Se o pedido será encaminhado para o servidor real do site (origem).
Se você for identificado como um usuário legítimo, o Cloudflare encaminhará o pedido para o servidor de origem e retornará o conteúdo para você. Este mecanismo melhora muito a segurança do site, mas também apresenta desafios significativos para o acesso automatizado.
Contornar o Cloudflare é um dos maiores desafios técnicos em muitas tarefas de coleta de dados. Abaixo, vamos nos aprofundar mais sobre por que contornar o Cloudflare é difícil.
- Desafios em Contornar a Proteção do Cloudflare
Contornar o Cloudflare não é fácil, especialmente quando recursos avançados contra bots (como Gerenciamento de Bots, Desafio Gerenciado, Verificação Turnstile, desafios JS, etc.) estão habilitados. Muitas ferramentas tradicionais de scraping (como Selenium e Puppeteer) são frequentemente detectadas e bloqueadas antes mesmo que os pedidos sejam feitos devido a características de impressão digital óbvias ou simulações de comportamento não naturais.
Embora existam algumas ferramentas de código aberto especificamente projetadas para contornar o Cloudflare (como FlareSolverr, undetected-chromedriver), essas ferramentas geralmente têm uma vida útil curta. Uma vez que são amplamente utilizadas, o Cloudflare rapidamente atualiza suas regras de detecção para bloqueá-las. Isso significa que, para contornar os mecanismos de proteção do Cloudflare de maneira sustentada e estável, as equipes frequentemente precisam de capacidades de desenvolvimento interno e investimento contínuo em recursos para manutenção e atualizações.
Aqui estão os principais desafios para contornar a proteção do Cloudflare:
- Reconhecimento Estrito de Impressão Digital do Navegador: O Cloudflare detecta características de impressão digital em pedidos, como User-Agent, configurações de idioma, resolução de tela, fuso horário e renderização Canvas/WebGL. Se detectar navegadores anormais ou comportamentos de automação, bloqueia o pedido.
- Mecanismos Complexos de Desafio em JS: A Cloudflare gera dinamicamente desafios em JavaScript (como CAPTCHA, redirecionamentos atrasados, cálculos lógicos, etc.), e scripts automatizados frequentemente têm dificuldades para analisar ou executar corretamente essas lógicas complexas.
- Sistemas de Análise Comportamental: Além de impressões digitais estáticas, a Cloudflare também analisa trajetórias de comportamento do usuário, como movimentos do mouse, tempo gasto em uma página, ações de rolagem, etc. Isso requer alta precisão na simulação do comportamento humano.
- Controle de Taxa e Concorrência: O acesso em alta frequência pode facilmente acionar as estratégias de limitação de taxa e bloqueio de IP da Cloudflare. Os pools de proxies e o agendamento distribuído devem ser altamente otimizados.
- Validação Invisível do Lado do Servidor: Como a Cloudflare é um interceptador de borda, muitos pedidos reais são bloqueados antes de chegar ao servidor de origem, tornando os métodos tradicionais de captura de pacotes ineficazes.
Portanto, contornar a Cloudflare com sucesso requer simular o comportamento real do navegador, executar JavaScript dinamicamente, configurar impressões digitais de forma flexível e usar proxies de alta qualidade e mecanismos de agendamento dinâmico.
Contornando a Cloudflare do Idealista com o Scrapeless Scraping Browser para Coletar Dados Imobiliários
Neste capítulo, demonstraremos como usar o Scrapeless Scraping Browser para construir um sistema de automação eficiente, estável e anti-anti-scraping para coletar dados imobiliários do Idealista, uma plataforma imobiliária europeia líder. O Idealista emprega múltiplos mecanismos de proteção, incluindo Cloudflare, carregamento dinâmico, limitação de taxa de IP e reconhecimento de comportamento do usuário, tornando-o uma plataforma de alvo altamente desafiadora.
Focaremos nos seguintes aspectos técnicos:
- Contornando páginas de verificação da Cloudflare
- Impressão digital personalizada e simulação do comportamento real do usuário
- Usando Repetição de Sessão
- Scraping de alta concorrência com múltiplos pools de proxies
- Otimização de custos
Compreendendo o Desafio: A Proteção da Cloudflare do Idealista
O Idealista é uma plataforma de imóveis online líder no Sul da Europa, oferecendo milhões de anúncios para vários tipos de propriedades, incluindo casas residenciais, apartamentos e quartos compartilhados. Dado o alto valor comercial de seus dados imobiliários, a plataforma implementou medidas rigorosas anti-scraping.
Para combater o scraping automatizado, o Idealista implantou a Cloudflare — um sistema amplamente utilizado de proteção contra bots e segurança projetado para defender contra bots maliciosos, ataques DDoS e abuso de dados. Os mecanismos anti-scraping da Cloudflare consistem principalmente nos seguintes elementos:
- Mecanismos de Verificação de Acesso: Incluindo Desafio em JS, verificações de integridade do navegador e verificação CAPTCHA, para determinar se o visitante é um usuário real.
- Análise Comportamental: Detectando usuários reais por meio de ações como movimentos do mouse, padrões de cliques e velocidades de rolagem.
- Análise de Cabeçalhos HTTP: Inspecionando tipos de navegador, configurações de idioma e dados de referência para verificar discrepâncias. Cabeçalhos suspeitos podem expor tentativas de disfarçar bots automatizados.
- Detecção e Bloqueio de Impressões Digitais: Identificando tráfego gerado por ferramentas de automação (como Selenium e Puppeteer) por meio de impressões digitais de navegadores, impressões digitais de TLS e informações de cabeçalho.
- Filtragem de Nó de Borda: Os pedidos entram primeiro na rede global de borda da Cloudflare, que avalia seu risco. Apenas pedidos considerados de baixo risco são encaminhados aos servidores de origem do Idealista.
Em seguida, explicaremos em detalhes como usar o Scrapeless Scraping Browser para contornar a proteção da Cloudflare do Idealista e coletar com sucesso dados imobiliários.
Contornando a Cloudflare do Idealista com o Scrapeless Scraping Browser
Pré-requisitos
Antes de começarmos, vamos garantir que temos as ferramentas necessárias:
-
Python: Se você ainda não instalou o Python, faça o download da versão mais recente e instale-a em seu sistema.
-
Bibliotecas Requeridas: Você precisará instalar várias bibliotecas Python. Abra um terminal ou prompt de comando e execute o seguinte comando:
pip install requests beautifulsoup4 lxml selenium selenium-wire undetected-chromedriver -
ChromeDriver: Baixe o ChromeDriver. Certifique-se de escolher a versão que corresponde à sua versão instalada do Chrome.
-
Conta Scrapeless: Para contornar a proteção de bot do Idealista, você precisará de uma conta no Scrapeless Scraping Browser. Você pode se inscrever aqui e receber um teste gratuito de $2.
Localizando os Dados
Nosso objetivo é extrair informações detalhadas sobre cada anúncio de propriedade no Idealista. Podemos usar as ferramentas de desenvolvedor do navegador para entender a estrutura do site e identificar os elementos HTML que precisamos direcionar.
Clique com o botão direito em qualquer lugar da página e selecione Inspecionar para visualizar o código-fonte da página.
Neste artigo, vamos nos concentrar em extrair listagens de propriedades de Alcala de Henares, Madrid, usando a seguinte URL:
https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/
Queremos extrair os seguintes pontos de dados de cada listagem:
- Título
- Preço
- Informações sobre a área
- Descrição da propriedade
- URLs das imagens
Abaixo, você pode ver a página de listagem de propriedades anotada, mostrando onde todas as informações de cada propriedade estão localizadas.
Ao inspecionar o código-fonte HTML, podemos identificar o seletor CSS para cada ponto de dado. Os seletores CSS são padrões usados para selecionar elementos em um documento HTML.
Ao inspecionar o código-fonte HTML, descobrimos que cada listagem de propriedade está contida dentro de uma tag <article> com a classe item. Dentro de cada item:
- O título está localizado em uma tag
<a>com a classeitem-link. - O preço é encontrado em uma tag
<span>com a classeitem-price. - E assim por diante para outros pontos de dados.
Etapa 1: Configurar o Selenium com o ChromeDriver
Primeiro, precisamos configurar o Selenium para usar o ChromeDriver. Comece configurando chrome_options e inicializando o ChromeDriver.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("Substitua pelo seu caminho para o ChromeDriver")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)Este código importa os módulos necessários, incluindo seleniumwire para interações avançadas com o navegador e BeautifulSoup para análise de HTML.
Definimos uma função listings(url) e configuramos o Chrome para rodar em modo headless, adicionando o argumento --headless a chrome_options. Em seguida, inicializamos o ChromeDriver usando o caminho de serviço especificado.
Etapa 2: Carregar a URL Alvo
Em seguida, carregamos a URL alvo e aguardamos a página carregar completamente.
driver.get(url)
time.sleep(8) # Ajuste com base no tempo de carregamento do siteAqui, o comando driver.get(url) instrui o navegador a navegar para a URL especificada.
Usamos time.sleep(8) para pausar o script por 8 segundos, permitindo tempo suficiente para a página da web carregar completamente. Esse tempo de espera pode ser ajustado dependendo da velocidade de carregamento do site.
Etapa 3: Analisar o Conteúdo da Página
Uma vez que a página está carregada, usamos o BeautifulSoup para analisar seu conteúdo:
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()Aqui, usamos driver.page_source para recuperar o conteúdo HTML da página carregada e analisá-lo usando BeautifulSoup com o analisador lxml. Finalmente, chamamos driver.quit() para fechar a instância do navegador e liberar recursos.
Etapa 4: Extrair Dados do HTML Analisado
Em seguida, extraímos os dados relevantes do HTML analisado.
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"Título": listing.find("a", class_="item-link").get("title", "nil"),
"Preço": listing.find("span", class_="item-price").get_text(strip=True),
"Quartos": bedrooms,
"Área": area,
"Descrição": description_text,
"URL da Imagem": first_image_url,
}
extracted_data.append(listing_info)Aqui, procuramos todos os elementos que correspondem à tag article com o nome da classe item, que representam listagens individuais de propriedades. Para cada listagem, extraímos seu título, detalhes (como o número de quartos e área) e a URL da imagem. Armazenamos esses detalhes em um dicionário e adicionamos cada dicionário a uma lista chamada extracted_data.
Etapa 5: Salvar os Dados Extraídos
Finalmente, salvamos os dados extraídos em um arquivo JSON.
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
```python
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Dados extraídos salvos em {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)Aqui está o código completo:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("Substitua pelo seu caminho para o ChromeDriver")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)
driver.get(url)
time.sleep(8) # Ajuste com base no tempo de carregamento do site
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"Título": listing.find("a", class_="item-link").get("title", "nil"),
"Preço": listing.find("span", class_="item-price").get_text(strip=True),
"Quartos": bedrooms,
"Área": area,
"Descrição": description_text,
"URL da Imagem": first_image_url,
}
extracted_data.append(listing_info)
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"novo_dados_revisados_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Dados extraídos salvos em {json_filename}")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)Contornando a Detecção de Bots
Se você executou o script pelo menos duas vezes durante este tutorial, pode ter notado que uma página de CAPTCHA aparece.
A página de Desafio do Cloudflare carrega inicialmente o script cf-chl-bypass e realiza cálculos em JavaScript, o que geralmente leva cerca de 5 segundos.
Scrapeless oferece uma maneira simples e confiável de acessar dados de sites como Idealista sem ter que construir e manter sua própria infraestrutura de scraping. O Scrapeless Scraping Browser é uma solução de automação de alta concorrência construída para IA. É uma plataforma de navegador de alto desempenho, custo-efetivo e anti-bloqueio, projetada para scraping de dados em grande escala e simula um comportamento altamente humano. Ele pode lidar com reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, DataDome e mais em tempo real, tornando-o uma solução eficiente para web scraping.
Abaixo estão os passos para contornar a proteção do Cloudflare usando Scrapeless:
Passo 1: Preparação
1.1 Criar uma Pasta de Projeto
- Crie uma nova pasta para seu projeto, por exemplo,
scrapeless-bypass. - Navegue até a pasta no seu terminal:
cd caminho/para/scrapeless-bypass1.2 Inicializar o projeto Node.js
Execute o seguinte comando para criar o arquivo package.json:
npm init -y1.3 Instalar dependências necessárias
Instale o Puppeteer-core, que permite conexões remotas com a instância do navegador:
npm install puppeteer-coreSe o Puppeteer não estiver instalado no seu sistema, instale a versão completa:
npm install puppeteer puppeteer-corePasso 2: Obter Sua Chave de API do Scrapeless
2.1 Inscrever-se no Scrapeless
- Vá para Scrapeless e crie uma conta.
- Navegue até a seção Gerenciamento de Chaves de API.
- Gere uma nova chave de API e copie-a.
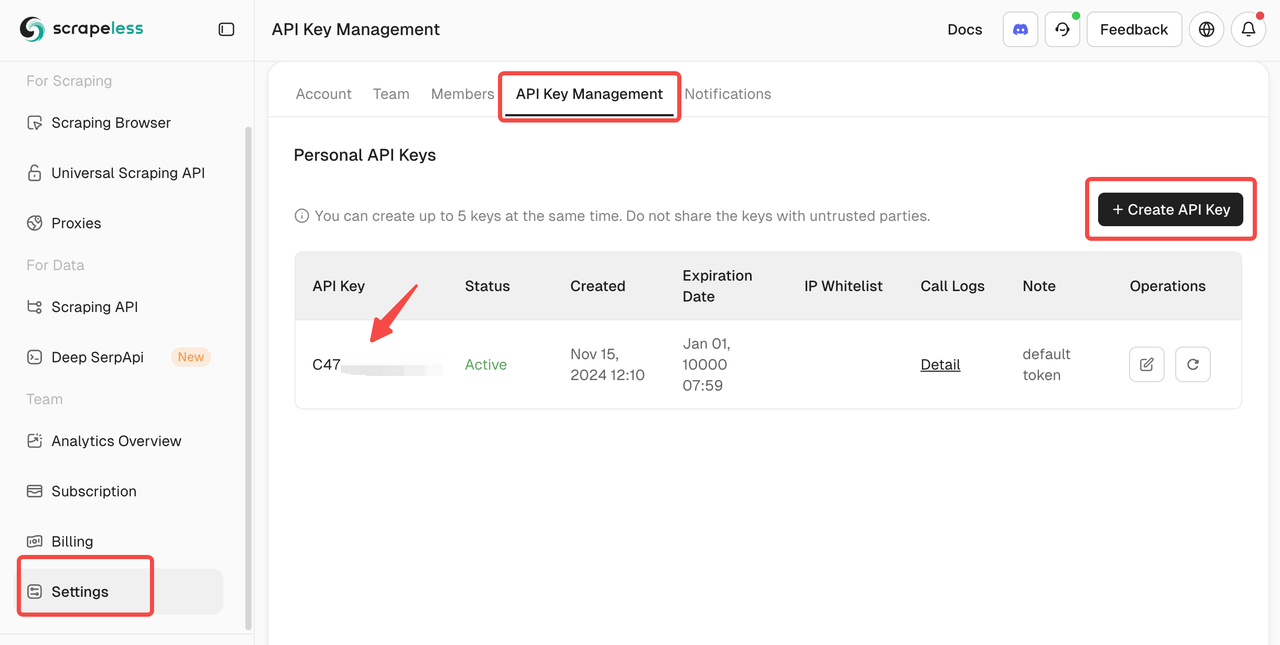
Passo 3: Conectar-se ao Scrapeless Browserless
3.1 Obter a URL de conexão WebSocket
Scrapeless fornece ao Puppeteer uma URL de conexão WebSocket para interagir com o navegador baseado em nuvem.
O formato é:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYSubstitua APIKey pela sua chave de API Scrapeless real.
3.2 Configurar Parâmetros de Conexão
token: Sua chave de API Scrapelesssession_ttl: Duração da sessão do navegador (em segundos), por exemplo,180proxy_country: Código do país do servidor proxy (por exemplo,GBpara o Reino Unido,USpara os Estados Unidos)
Passo 4: Escreva o Script do Puppeteer
4.1 Crie o Arquivo de Script
Dentro da pasta do seu projeto, crie um novo arquivo JavaScript chamado bypass-cloudflare.js.
4.2 Conecte-se ao Scrapeless e Inicie o Puppeteer
Adicione o seguinte código a bypass-cloudflare.js:
import puppeteer from 'puppeteer-core';
const API_KEY = 'sua_chave_api'; // Substitua pela sua chave API real
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({token: API_KEY, session_ttl: '180', // Duração da sessão do navegador em segundos proxy_country: 'GB', // Código do país do proxy proxy_session_id: 'test_session', // ID da sessão do proxy (mantém o mesmo IP) proxy_session_duration: '5' // Duração da sessão do proxy em minutos
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL, defaultViewport: null,
});
console.log('Conectado ao Scrapeless');4.3 Abra uma webpage e contorne o Cloudflare
Amplie o script para abrir uma nova página e navegar para um site protegido pelo Cloudflare:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 Aguardando os elementos da página carregarem
Certifique-se de que a proteção do Cloudflare foi contornada antes de prosseguir:
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // Ajuste o seletor conforme necessário4.5 Faça uma captura de tela
Para verificar se a proteção do Cloudflare foi contornada com sucesso, faça uma captura de tela da página:
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Captura de tela salva como challenge-bypass.png');4.6 Script completo
O seguinte é o script completo:
import puppeteer from 'puppeteer-core';
const API_KEY = 'sua_chave_api'; // Substitua pela sua chave API real
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// Conectar-se ao Scrapeless
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Conectado ao Scrapeless');
// Abra uma nova página e navegue até o site alvo
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// Aguarde a página carregar completamente
await page.waitForTimeout(5000); // Ajuste o atraso se necessário
await page.waitForSelector('main.page-content', { timeout: 30000 });
// Capture uma captura de tela
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Captura de tela salva como challenge-bypass.png');
// Feche o navegador
await browser.close();
console.log('Navegador fechado');
} catch (error) {
console.error('Erro:', error);
}
})();Passo 5: Execute o script
5.1 Salve o script
Certifique-se de que o script esteja salvo como bypass-cloudflare.js.
5.2 Execute o script
Execute o script usando Node.js:
node bypass-cloudflare.js5.3 Saída Esperada
Se tudo estiver configurado corretamente, o terminal exibirá:
Conectado ao Scrapeless
Captura de tela salva como challenge-bypass.png
Navegador fechadoO arquivo challenge-bypass.png aparecerá na pasta do seu projeto, confirmando que a proteção do Cloudflare foi contornada com sucesso.
Você também pode integrar o Navegador de Scraping Scrapeless diretamente no seu código de scraping:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=C4778985476352D77C08ECB031AF0857&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Personalização da Impressão Digital
Ao coletar dados de websites—especialmente grandes plataformas imobiliárias como Idealista—mesmo que você consiga contornar os desafios do Cloudflare utilizando o Scrapeless, ainda pode ser sinalizado como um bot devido ao acesso repetitivo ou em alta volume.
Os sites frequentemente usam impressão digital do navegador para detectar comportamentos automatizados e restringir o acesso.
⚠️ Problemas Comuns Que Você Pode Encontrar
-
Tempos de resposta lentos após múltiplas raspagens
O site pode limitar solicitações com base no IP ou padrões de comportamento. -
Falha na renderização do layout da página
Conteúdo dinâmico pode depender de ambientes de navegador reais, causando dados ausentes ou quebrados durante a raspagem. -
Listagens ausentes em certas regiões
Websites podem bloquear ou ocultar conteúdo com base em padrões de tráfego suspeitos.
Esses problemas são geralmente causados por configurações de navegador idênticas para cada solicitação. Se sua impressão digital do navegador permanecer inalterada, é fácil para sistemas anti-bot detectar automatização.
Solução: Impressão Digital Personalizada com Scrapeless
Scrapeless Scraping Browser oferece suporte embutido para personalização de impressões digitais para imitar o comportamento real do usuário e evitar detecção.
Você pode randomizar ou personalizar os seguintes elementos de impressão digital:
| Elemento de Impressão Digital | Descrição |
|---|---|
| User-Agent | Imitar várias combinações de SO/navegadores (por exemplo, Chrome no Windows/Mac). |
| Plataforma | Simular diferentes sistemas operacionais (Windows, macOS, etc.). |
| Tamanho da Tela | Emular várias resoluções de dispositivos para evitar incompatibilidades móvel/desktop. |
| Localização | Alinhar idioma e fuso horário com geolocalização para consistência. |
Ao girar ou personalizar esses valores, cada solicitação parece mais natural—reduzindo o risco de detecção e melhorando a confiabilidade da extração de dados.
Exemplo de código:
const puppeteer = require('puppeteer-core');
const query = new URLSearchParams({
token: 'sua-chave-api-scrapeless', // necessário
session_ttl: 180,
proxy_country: 'QUALQUER',
// Definir parâmetros de impressão digital
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.6998.45 Safari/537.36',
platform: 'Windows',
screen: JSON.stringify({ width: 1280, height: 1024 }),
localization: JSON.stringify({
locale: 'zh-HK',
languages: ['zh-HK', 'en-US', 'en'],
timezone: 'Asia/Hong_Kong',
})
});
const connectionURL = `wss://browser.Scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.Scrapeless.com');
console.log(await page.title());
await browser.close();
})();
Repetição de Sessão
Após personalizar as impressões digitais do navegador, a estabilidade da página melhora significativamente, e a extração de conteúdo se torna mais confiável.
No entanto, durante operações de raspagem em grande escala, problemas inesperados ainda podem causar falhas na extração. Para resolver isso, Scrapeless oferece um poderoso recurso de Repetição de Sessão.
O que é Repetição de Sessão?
A Repetição de Sessão grava toda a sessão do navegador em detalhes, capturando todas as interações, como:
- Processo de carregamento da página
- Dados de solicitação e resposta da rede
- Comportamento de execução do JavaScript
- Conteúdo carregado dinamicamente, mas não analisado
Por que usar Repetição de Sessão?
Ao raspar sites complexos como Idealista, a Repetição de Sessão pode melhorar bastante a eficiência de depuração.
| Benefício | Descrição |
|---|---|
| Rastreamento Preciso de Problemas | Identificar rapidamente solicitações falhadas sem suposições |
| Sem Necessidade de Re-executar Código | Analisar problemas diretamente da repetição em vez de reexecutar o scraper |
| Colaboração Melhorada | Compartilhar registros de repetição com membros da equipe para facilitar a solução de problemas |
| Análise de Conteúdo Dinâmico | Entender como os dados carregados dinamicamente se comportam durante a raspagem |
Dica de Uso
Uma vez habilitada a Repetição de Sessão, verifique os registros de repetição primeiro sempre que uma raspagem falhar ou os dados parecerem incompletos. Isso ajuda a diagnosticar o problema mais rápido e reduzir o tempo de depuração.
Configuração de Proxy
Ao raspar Idealista, é importante notar que a plataforma é altamente sensível a endereços IP não locais—especialmente ao acessar listagens de cidades específicas. Se seu IP se originar de fora do país, o Idealista pode:
- Bloquear a solicitação completamente
- Retornar uma versão simplificada ou reduzida da página
- Servir dados vazios ou incompletos, mesmo sem acionar um CAPTCHA
Suporte Embutido de Proxy do Scrapeless
Scrapeless oferece configuração de proxy embutida, permitindo que você especifique sua origem geográfica diretamente.
Você pode configurar isso usando:
proxy_country: Um código de país de duas letras (por exemplo,'ES'para Espanha)proxy_url: A URL do seu próprio servidor proxy
Exemplo de uso:
proxy_country: 'ES',Alta Concorrência
A página que acabamos de raspar do Idealista—Listagens de Imóveis de Alcalá de Henares—tem até 6 páginas de listagens.
Quando você está pesquisando tendências do setor ou reunindo estratégias de marketing concorrencial, pode precisar raspar dados de imóveis de 20+ cidades diariamente, cobrindo milhares de páginas. Em alguns casos, você pode até precisar atualizar esses dados a cada hora.
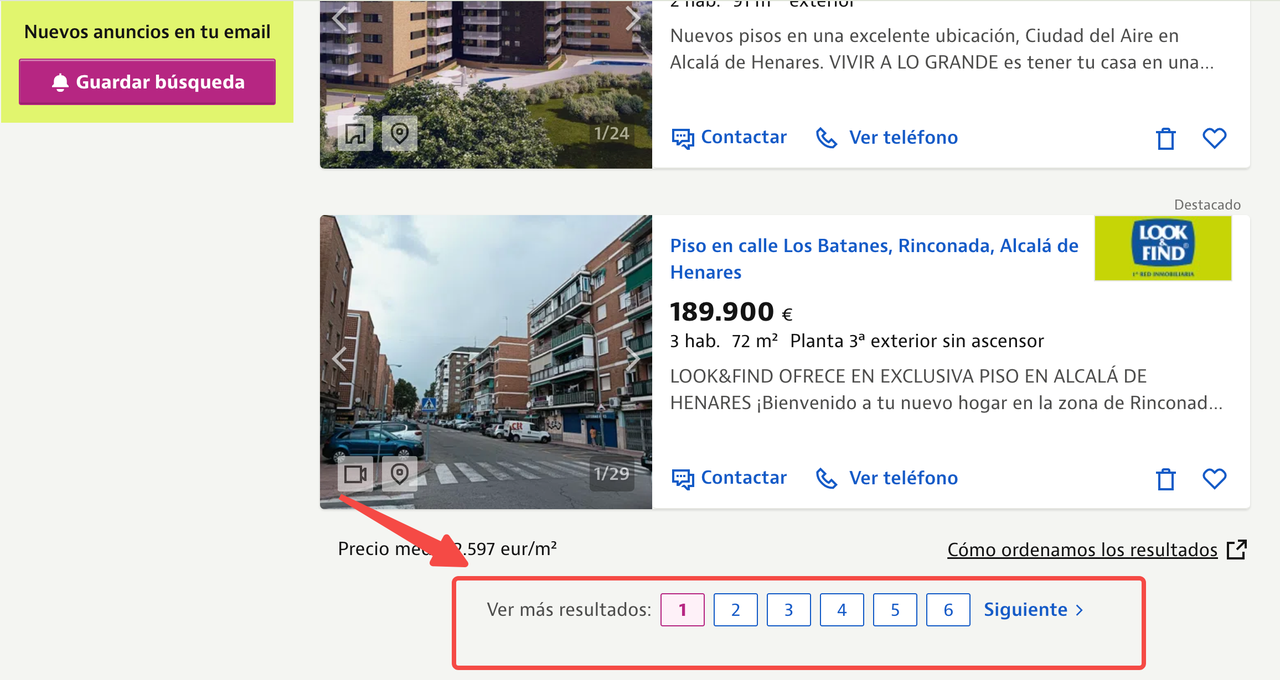
Requisitos de Alta Concorrência
Para lidar com esse volume de forma eficiente, considere os seguintes requisitos:
- Múltiplas conexões simultâneas: Para raspar dados de centenas de páginas sem longos tempos de espera.
- Ferramentas de automação: Use o Scrapeless Scraping Browser ou ferramentas semelhantes que possam lidar com solicitações simultâneas em grande escala.
- Gerenciamento de sessão: Manter sessões persistentes para evitar CAPTCHAs ou bloqueios de IP excessivos.
Escalabilidade Sem Esforço
O Scrapeless é projetado especificamente para raspagem de alta concorrência. Ele oferece:
- Sessões de navegador paralelas: Lidar com múltiplas solicitações simultaneamente, permitindo que você raspe grandes quantidades de dados em várias cidades.
- Raspagem de baixo custo e alta eficiência: Raspagem em paralelo reduz o custo por página raspada enquanto otimiza a taxa de transferência.
- Ultrapassar defesas anti-bot de alto volume: Lida automaticamente com CAPTCHA e outros sistemas de verificação, mesmo durante a raspagem de alta carga.
Dica: Certifique-se de que suas solicitações estejam espaçadas o suficiente para mimetizar o comportamento de navegação humano e prevenir limitação de taxa ou banimentos do Idealista.
Escalabilidade e Eficiência de Custos
O Puppeteer regular tem dificuldades para escalar sessões de forma eficiente e integrar-se com sistemas de enfileiramento. No entanto, o Scrapeless Scraping Browser suporta a escalabilidade sem costura de dezenas de sessões simultâneas a ilimitadas sessões simultâneas, garantindo zero tempo de espera e zero timeouts mesmo durante picos de carga de tarefas.
Aqui está uma comparação de várias ferramentas para raspagem de alta concorrência. Mesmo com o navegador de alta concorrência do Scrapeless, você não precisa se preocupar com custos—na verdade, ele pode ajudá-lo a economizar quase 50% em taxas.
Comparação de Ferramentas
| Nome da Ferramenta | Taxa Horária (USD/hora) | Taxas de Proxy (USD/GB) | Suporte Simultâneo |
|---|---|---|---|
| Scrapeless | $0.063 – $0.090/hora (depende da concorrência e uso) | $1.26 – $1.80/GB | 50 / 100 / 200 / 400 / 600 / 1000 / Ilimitado |
| Browserbase | $0.10 – $0.198/hora (inclui 2-5GB de proxies gratuitos) | $10/GB (após a alocação gratuita) | 3 (Básico) / 50 (Avançado) |
| Brightdata | $0.10/hora | $9.5/GB (Padrão); $12.5/GB (Domínios Avançados) | Ilimitado |
| Zenrows | $0.09/hora | $2.8 – $5.42/GB | Até 100 |
| Browserless | $0.084 – $0.15/hora (cobrança por unidade) | $4.3/GB | 3 / 10 / 50 |
Dica: Se você precisar de raspagem em grande escala e suporte de alta concorrência, Scrapeless oferece a melhor relação custo-benefício.
Estratégias de Controle de Custos para Raspagem da Web
Usuários cuidadosos podem ter notado que as páginas do Idealista que raspamos frequentemente contêm grandes quantidades de imagens de propriedades em alta definição, mapas interativos, apresentações em vídeo e scripts de anúncios. Embora esses elementos sejam amigáveis para os usuários finais, são desnecessários para a extração de dados e aumentam significativamente o consumo de largura de banda e os custos.
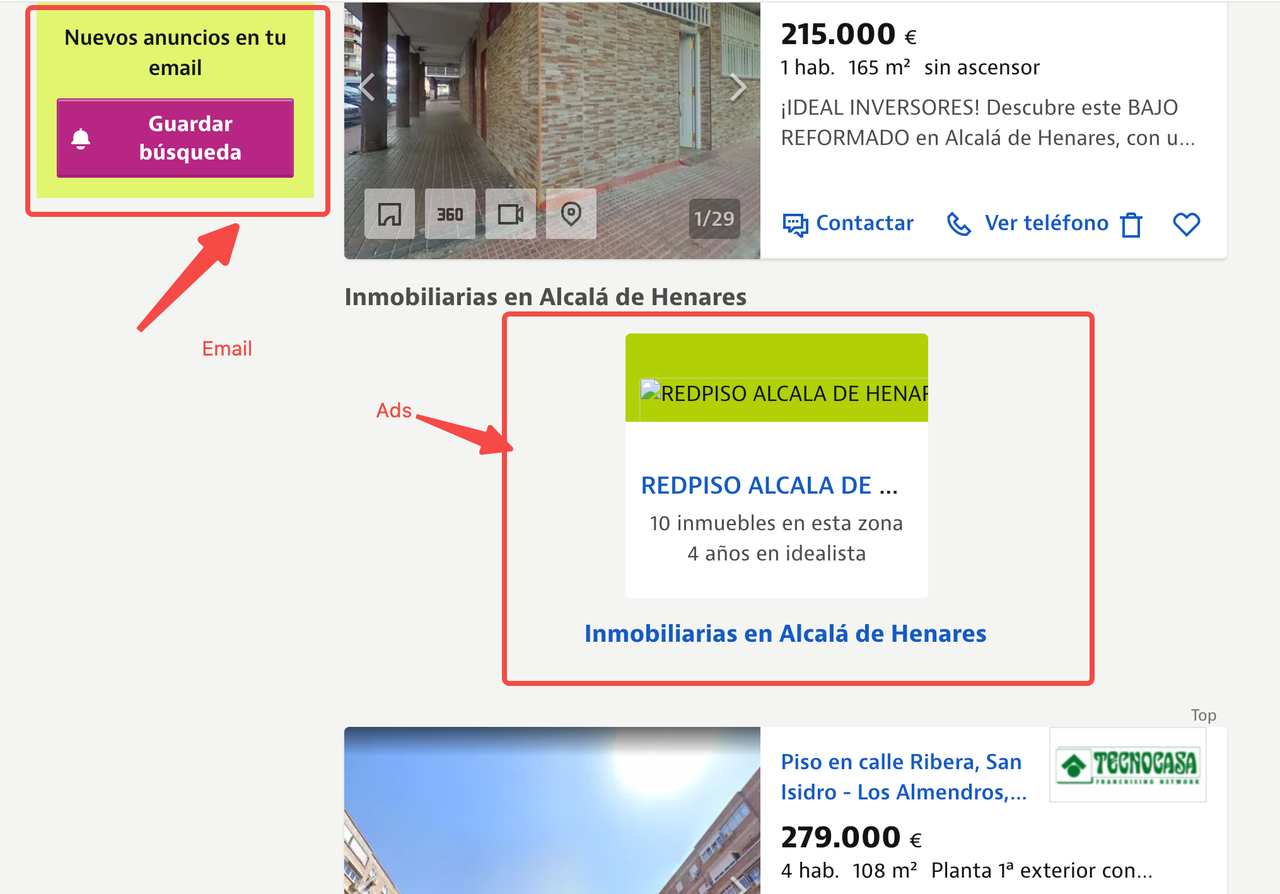
Para otimizar o uso de tráfego, recomendamos que os usuários empreguem as seguintes estratégias:
- Intercepção de Recursos: Interceptar solicitações de recursos desnecessários para reduzir o consumo de tráfego.
- Intercepção de URL de Solicitação: Interceptar solicitações específicas com base nas características da URL para minimizar ainda mais o tráfego.
- Simular Dispositivos Móveis: Usar configurações de dispositivos móveis para buscar versões mais leves das páginas.
Estratégias Detalhadas
1. Intercepção de Recursos
Ativar a intercepção de recursos pode melhorar significativamente a eficiência da raspagem. Ao configurar a função setRequestInterception do Puppeteer, podemos bloquear recursos como imagens, mídias, fontes e folhas de estilo, evitando downloads de conteúdo grande.
2. Filtragem de URL de Solicitação
Ao examinar URLs de solicitação, podemos filtrar solicitações irrelevantes, como serviços de publicidade e scripts de análise de terceiros que não estão relacionados à extração de dados. Isso reduz o tráfego de rede desnecessário.
3. Simulando Dispositivos Móveis
Simular um dispositivo móvel (por exemplo, definindo o agente do usuário como um iPhone) permite que você busque uma versão mais leve e otimizada para dispositivos móveis da página. Isso resulta em menos recursos sendo carregados e acelera o processo de raspagem.
Para mais informações, consulte a documentação oficial do Scrapeless
Exemplo de Código
Aqui está um exemplo de combinação dessas três estratégias usando Scrapeless Cloud Browser + Puppeteer para raspagem otimizada de recursos:
import puppeteer from 'puppeteer-core';
const scrapelessUrl = 'wss://browser.scrapeless.com/browser?token=your_api_key&session_ttl=180&proxy_country=ANY';
async function scrapeWithResourceBlocking(url) {
const browser = await puppeteer.connect({
browserWSEndpoint: scrapelessUrl,
defaultViewport: null
});
const page = await browser.newPage();
// Ativar intercepção de solicitação
pt
await page.setRequestInterception(true);
// Defina os tipos de recursos a serem bloqueados
const BLOCKED_TYPES = new Set([
'imagem',
'fonte',
'mídia',
'folha de estilo',
]);
// Intercepta solicitações
page.on('request', (request) => {
if (BLOCKED_TYPES.has(request.resourceType())) {
request.abort();
console.log(`Bloqueado: ${request.resourceType()} - ${request.url().substring(0, 50)}...`);
} else {
request.continue();
}
});
await page.goto(url, {waitUntil: 'domcontentloaded'});
// Extrair dados
const data = await page.evaluate(() => {
return {
title: document.title,
content: document.body.innerText.substring(0, 1000)
};
});
await browser.close();
return data;
}
// Uso
scrapeWithResourceBlocking('https://www.scrapeless.com')
.then(data => console.log('Resultado da raspagem:', data))
.catch(error => console.error('Raspagem falhou:', error));Dessa forma, você não apenas pode economizar altos custos de tráfego, mas também acelerar a velocidade de rastreamento, garantindo a qualidade dos dados, melhorando assim a estabilidade e a eficiência geral do sistema.
5. Recomendações de Segurança e Conformidade
Ao usar o Scrapeless para raspagem de dados, os desenvolvedores devem prestar atenção ao seguinte:
- Cumprir com o arquivo
robots.txtdo site de destino e com as leis e regulamentos relevantes: Certifique-se de que suas atividades de raspagem sejam legais e respeitem as diretrizes do site. - Evitar solicitações excessivas que possam levar a inatividade do site: Esteja atento à frequência de raspagem para evitar sobrecarga do servidor.
- Não raspar informações sensíveis: Não colete dados de privacidade do usuário, informações de pagamento ou qualquer outro conteúdo sensível.
6. Conclusão
Na era do big data, a coleta de dados se tornou uma base crucial para a transformação digital em diversas indústrias. Especialmente em campos como inteligência de mercado, comparação de preços em e-commerce, análise competitiva, gestão de risco financeiro e análise imobiliária, a demanda por tomada de decisões orientadas a dados se tornou cada vez mais urgente. No entanto, com a contínua evolução das tecnologias da web, especialmente o uso generalizado de conteúdo carregado dinamicamente, os raspadores web tradicionais estão gradualmente revelando suas limitações. Essas limitações não apenas dificultam a raspagem, mas também levam à escalada de mecanismos anti-raspagem, aumentando a barreira para a raspagem na web.
Com o avanço das tecnologias web, os raspadores tradicionais já não conseguem atender às complexas necessidades de raspagem. Abaixo estão alguns dos principais desafios e soluções correspondentes:
- Carregamento Dinâmico de Conteúdo: Raspadores baseados em navegadores, ao simular a renderização real do navegador de conteúdo JavaScript, garantem que possam raspar dados da web carregados dinamicamente.
- Mecanismos Anti-Raspagem: Usando piscinas de proxy, reconhecimento de impressão digital, simulação de comportamento e outras técnicas, podemos contornar os mecanismos anti-raspagem comumente acionados por raspadores tradicionais.
- Raspagem de Alta Concorrência: Navegadores sem cabeça suportam implantação de tarefas de alta concorrência, combinados com agendamento de proxies, para atender às necessidades de raspagem de dados em larga escala.
- Questões de Conformidade: Ao usar APIs legais e serviços de proxy, as atividades de raspagem podem ser asseguradas para estar em conformidade com os termos dos sites de destino.
Como resultado, os raspadores baseados em navegadores se tornaram a nova tendência da indústria. Essa tecnologia não apenas simula o comportamento do usuário através de navegadores reais, mas também lida de forma flexível com as estruturas complexas e mecanismos anti-raspagem de sites modernos, oferecendo aos desenvolvedores soluções de raspagem mais estáveis e eficientes.
O Scrapeless Scraping Browser abraça essa tendência tecnológica, combinando renderização de navegador, gerenciamento de proxy, tecnologias de anti-detecção e agendamento de tarefas de alta concorrência, ajudando os desenvolvedores a concluir tarefas de raspagem de dados de forma eficiente e estável em ambientes online complexos. Melhora a eficiência e estabilidade da raspagem através de várias vantagens principais:
- Soluções de Navegador de Alta Concorrência: O Scrapeless suporta tarefas em larga escala e de alta concorrência, possibilitando a implantação rápida de milhares de tarefas de raspagem para atender à demanda de raspagem a longo prazo.
- Anti-Distensão como Serviço: Solucionadores de CAPTCHA integrados e impressões digitais personalizáveis ajudam os desenvolvedores a contornar mecanismos de reconhecimento de impressão digital e comportamento, reduzindo significativamente o risco de serem bloqueados.
- Ferramenta de Depuração Visual - Repetição de Sessão: Reproduzindo cada interação do navegador durante o processo de raspagem, os desenvolvedores podem facilmente depurar e diagnosticar problemas no processo de raspagem, especialmente para lidar com páginas complexas e conteúdo dinamicamente carregado.
- Garantia de Conformidade e Transparência: O Scrapeless enfatiza a raspagem de dados em conformidade, apoiando a adesão às regras do arquivo
robots.txtdo site e proporcionando registros de raspagem detalhados para garantir que as atividades de raspagem de dados dos usuários estejam em conformidade com as políticas dos sites de destino. - Escalabilidade Flexível: Scrapeless se integra perfeitamente ao Puppeteer, permitindo que os usuários personalizem suas estratégias de coleta de dados e se conectem a outras ferramentas ou plataformas para um fluxo de trabalho unificado de coleta e análise de dados.
Seja coletando dados de plataformas de e-commerce para comparações de preços, extraindo dados de sites imobiliários ou aplicando-os em monitoramento de risco financeiro e análise de inteligência de mercado, o Scrapeless oferece soluções de alta eficiência, inteligentes e confiáveis para diversas indústrias.
Com os detalhes técnicos e melhores práticas abordados neste artigo, você agora entende como aproveitar o Scrapeless para coleta de dados em larga escala. Seja lidando com páginas dinâmicas, extraindo dados interativos complexos, otimizando o uso de tráfego ou superando mecanismos de anti-coleta, o Scrapeless ajuda você a atingir seus objetivos de coleta de dados de forma rápida e eficiente.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


