
Scrapeless agora está disponível no Pipedream!
Senior Web Scraping Engineer
Estamos empolgados em anunciar que Scrapeless agora está oficialmente ativo no Pipedream! 🎉
Isso significa que você pode agora aproveitar de forma integrada as poderosas capacidades de scraping do Scrapeless dentro desta robusta plataforma de integração sem servidor para construir fluxos de trabalho automatizados de extração de dados — sem mais configurações de scrapers bagunçadas ou dores de cabeça com anti-bots.
Por que escolher o Pipedream?
Pipedream é uma plataforma de automação altamente flexível e eficiente que suporta arquitetura orientada a eventos e permite integrar centenas de serviços como Slack, Notion, GitHub, Google Sheets e mais. Você pode escrever lógica personalizada em JavaScript, Python e outras linguagens — sem nunca ter que gerenciar servidores ou infraestrutura.
É o ambiente perfeito para construir webhooks, sincronizar dados, criar notificações em tempo real e automatizar tudo o que você precisar — agilizando o desenvolvimento e economizando tempo.
Construa seu primeiro fluxo de trabalho Scrapeless no Pipedream!
Pré-requisitos
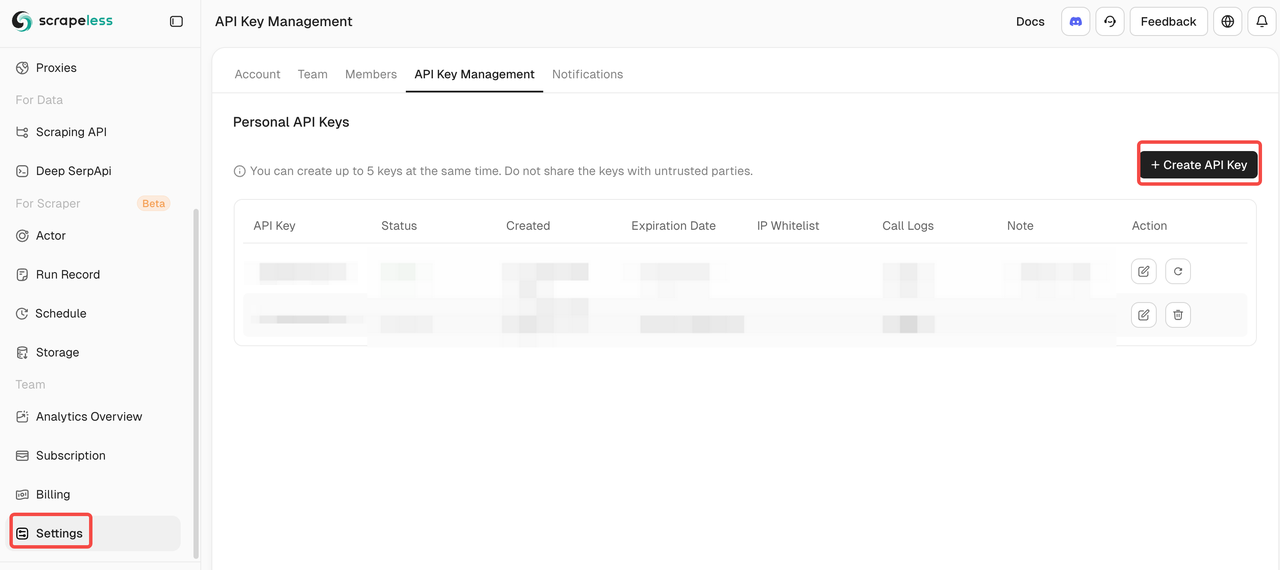
Passo 1. Obtenha sua chave de API do Scrapeless. Antes de usar o Scrapeless no Pipedream, certifique-se de que já tem sua chave de API:
- Faça login em Scrapeless
- Vá para Gerenciamento de API e gere sua chave
Passo 2. Crie uma conta no Pipedream. Cadastre-se em Pipedream se ainda não tiver uma conta.
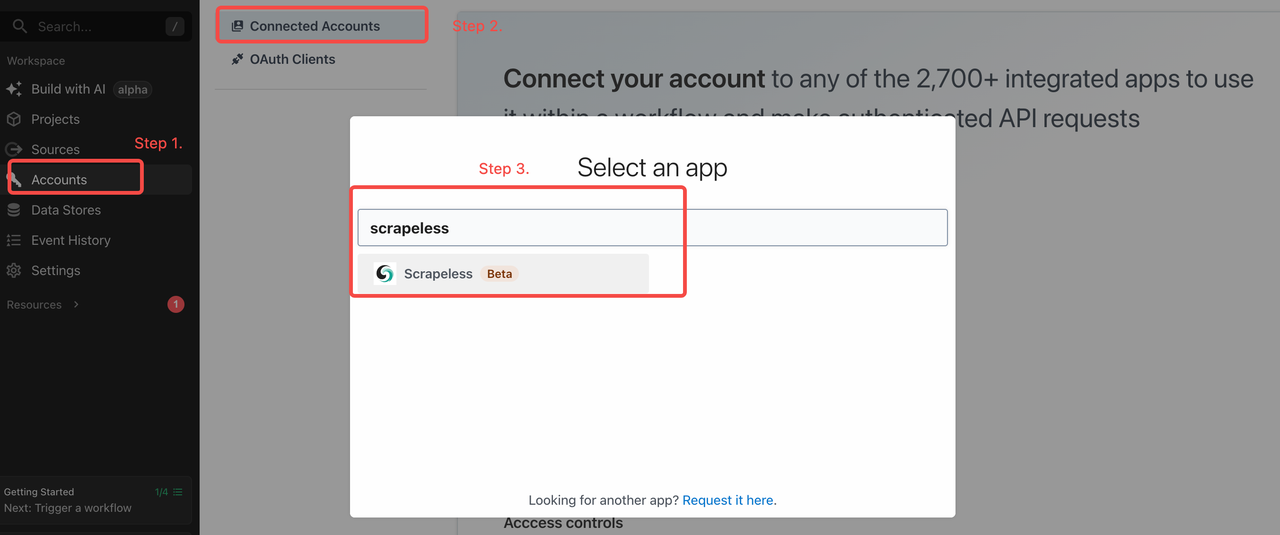
Configure sua chave de API do Scrapeless no Pipedream
Quando você estiver pronto, vá para a aba “Contas” no Pipedream e adicione sua chave de API do Scrapeless:
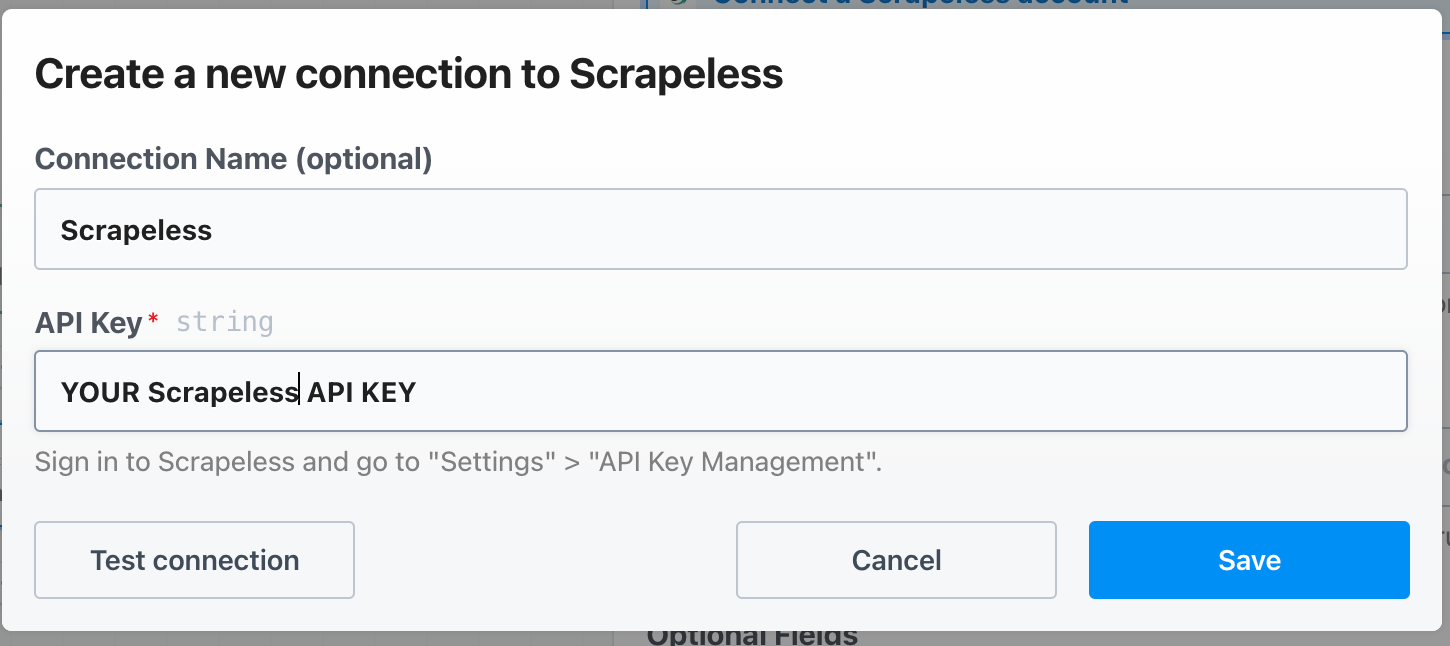
Configure a chave de API do Scrapeless no Pipedream assim:
Scrapeless oferece três módulos poderosos para ajudar você a construir seus fluxos de trabalho de extração de dados em minutos:
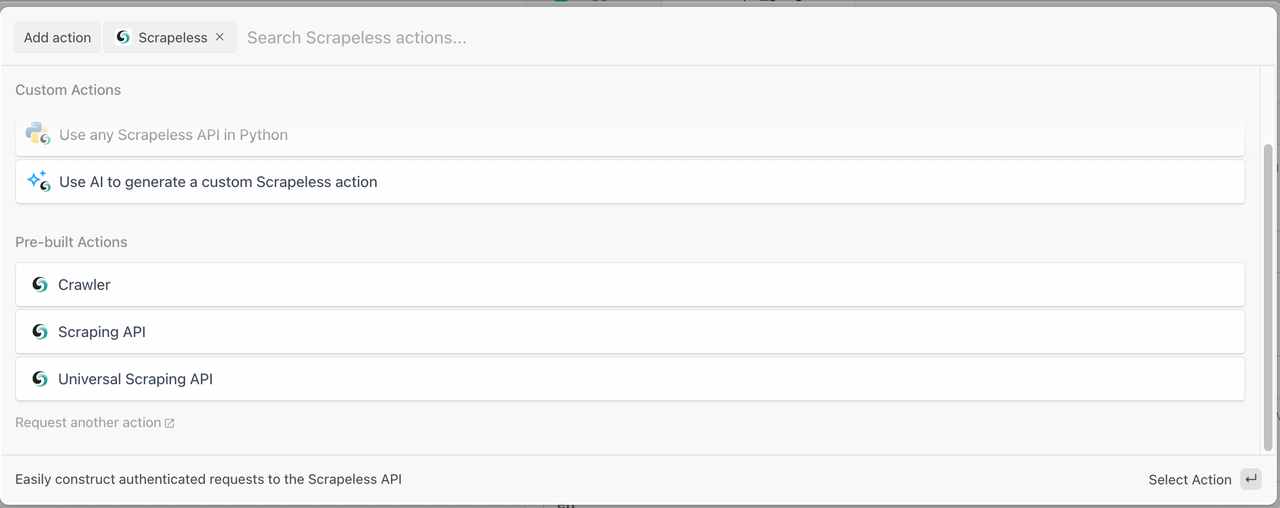
1. Módulo Crawler
- Crawler Crawl: Rasteie todo o site, acesse links dentro da página de forma recursiva e obtenha o conjunto completo de dados.
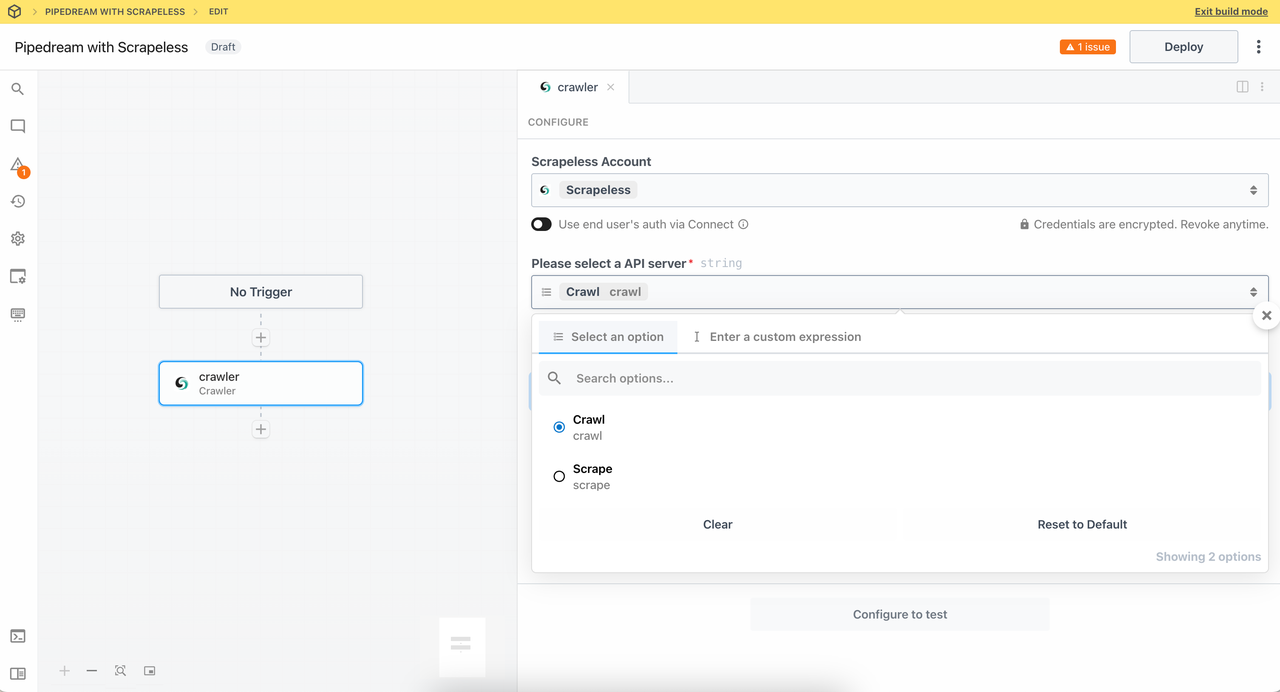
Este nó usa a função Crawler do Crawl. O Scrapeless fornece rastreamento recursivo inteligente para capturar totalmente todas as páginas vinculadas.
Defina a contagem de subpáginas para coletar a quantidade de dados de página que você precisa. Agora, vamos tentar rastrear https://www.scrapeless.com/en:
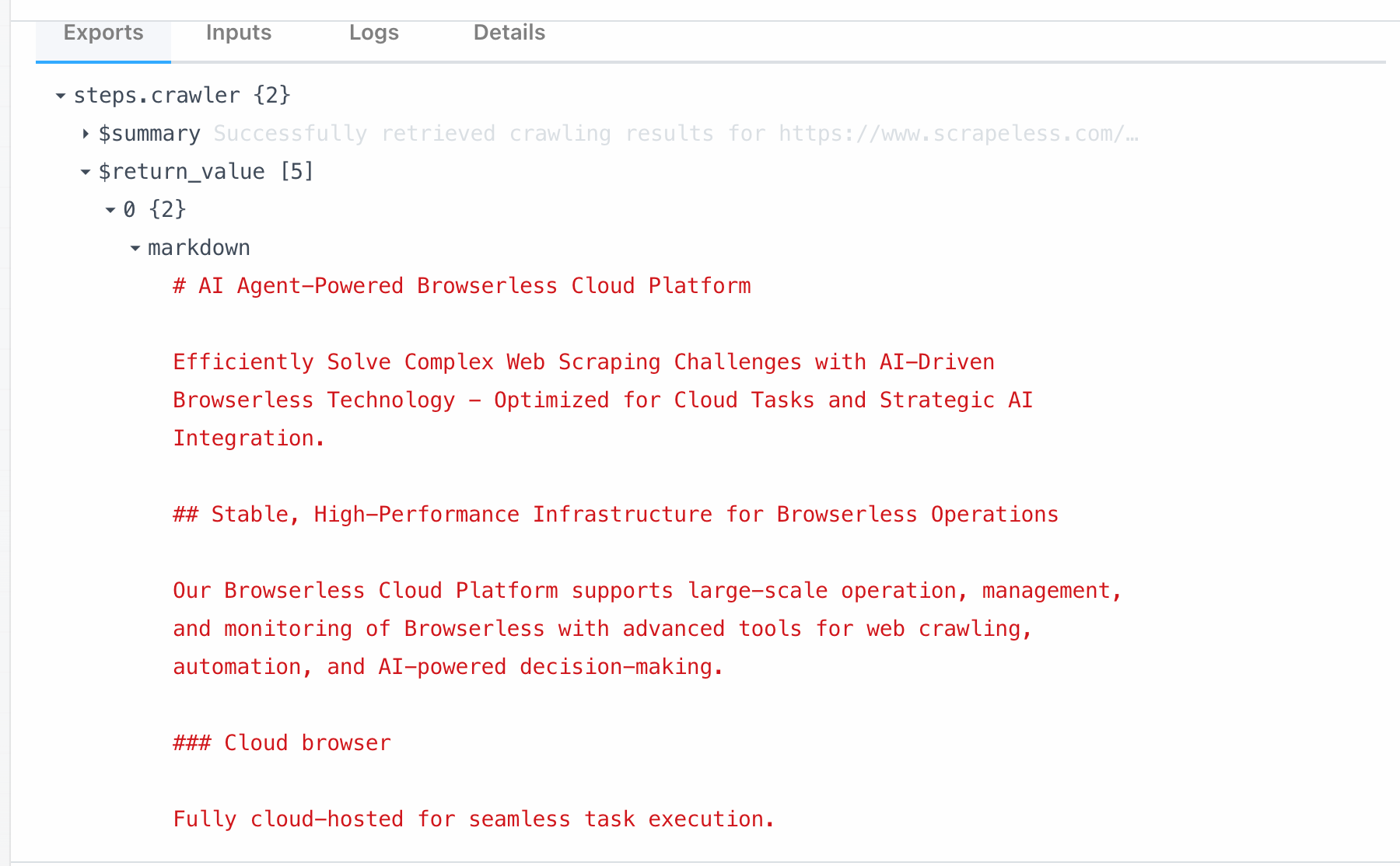
- Crawler Scrape: Usado para rastrear o conteúdo de uma única página da web e extrair dados estruturados.
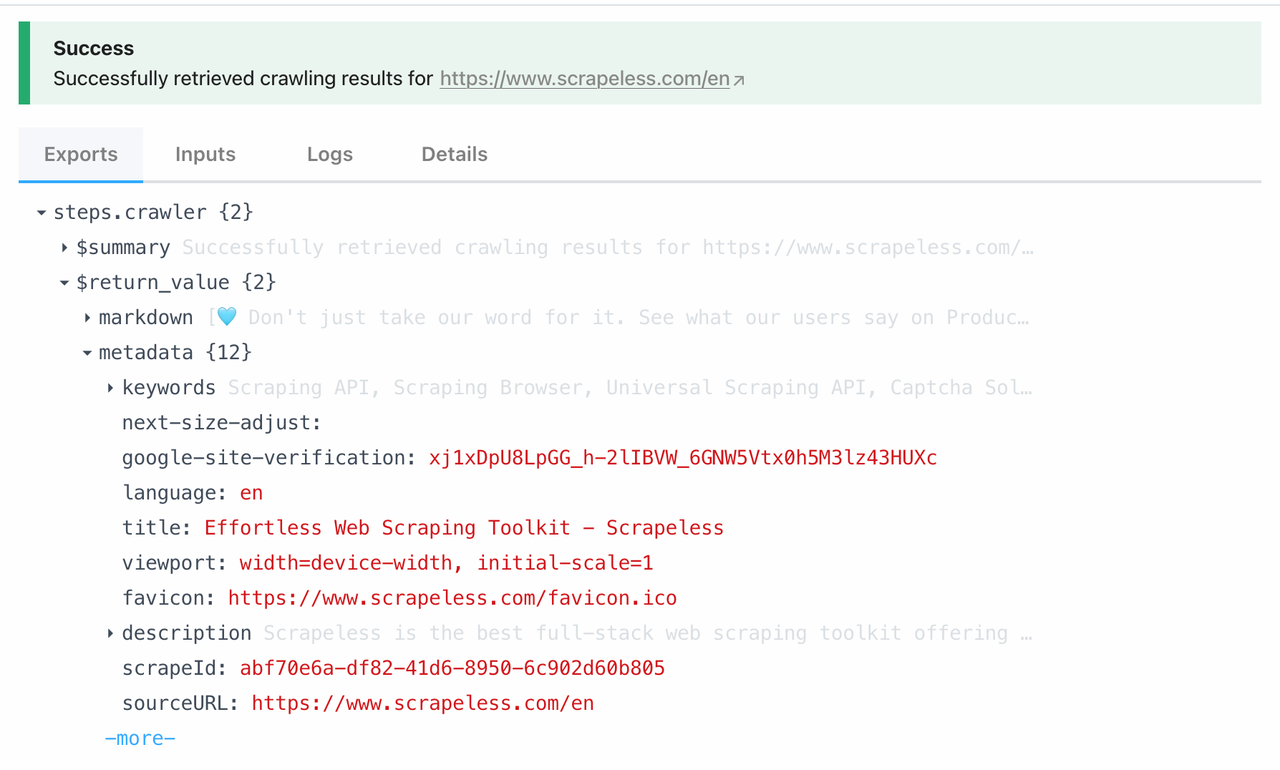
O nó Scrape está diretamente vinculado à função Scrape sob o Crawl do Scrapeless. Ao chamar este módulo, você pode raspar todos os dados de uma única página em um clique. Aqui está o que podemos obter raspando de https://www.scrapeless.com/en:
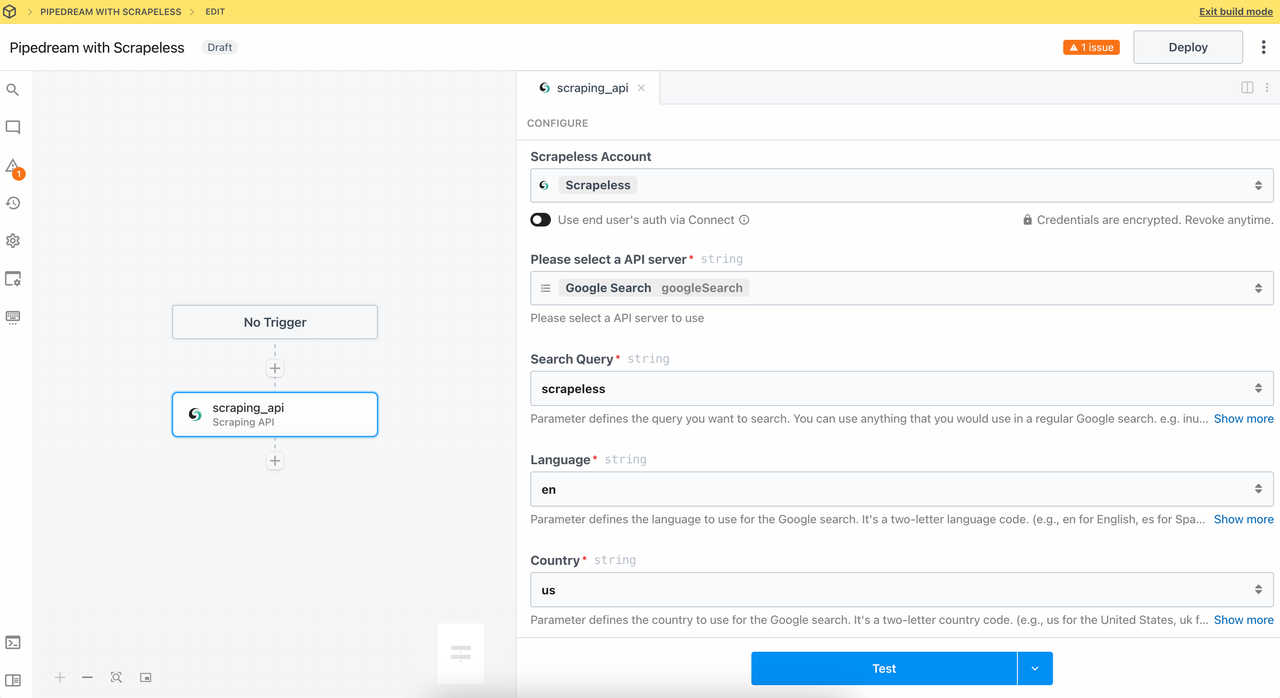
2. Módulo de API de Scraping
Chamar o módulo de API de Scraping pode acessar fontes de dados como Google Search e Google Trends com um clique e obter facilmente resultados de busca e dados de tendências sem precisar escrever solicitações complexas ou processar respostas você mesmo.
Vamos configurar:
- Consulta:
Scrapeless - Língua:
en - País:
us
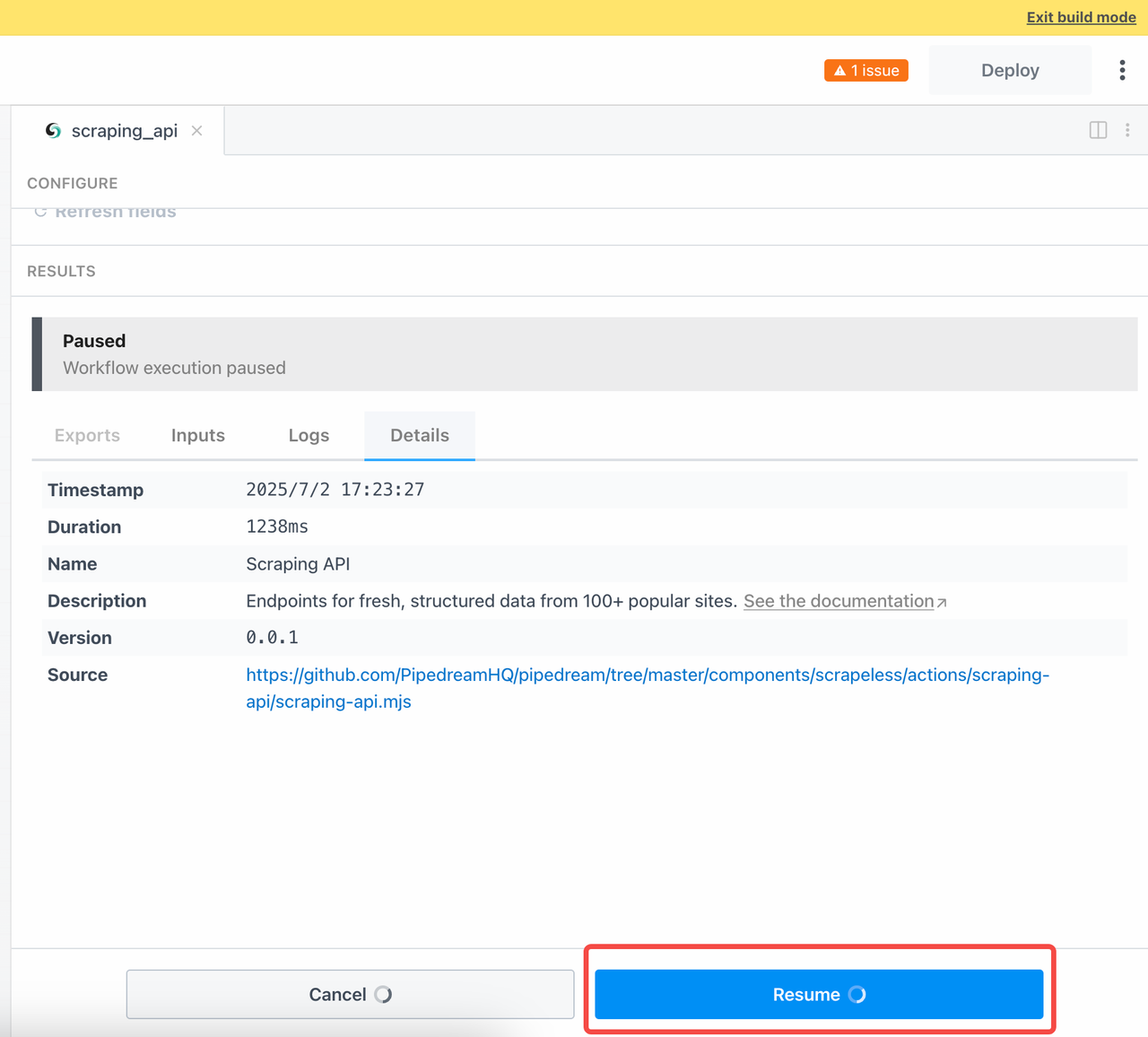
Para aguardar os resultados da tarefa assíncrona, precisamos clicar manualmente em Retomar após enviar a consulta:
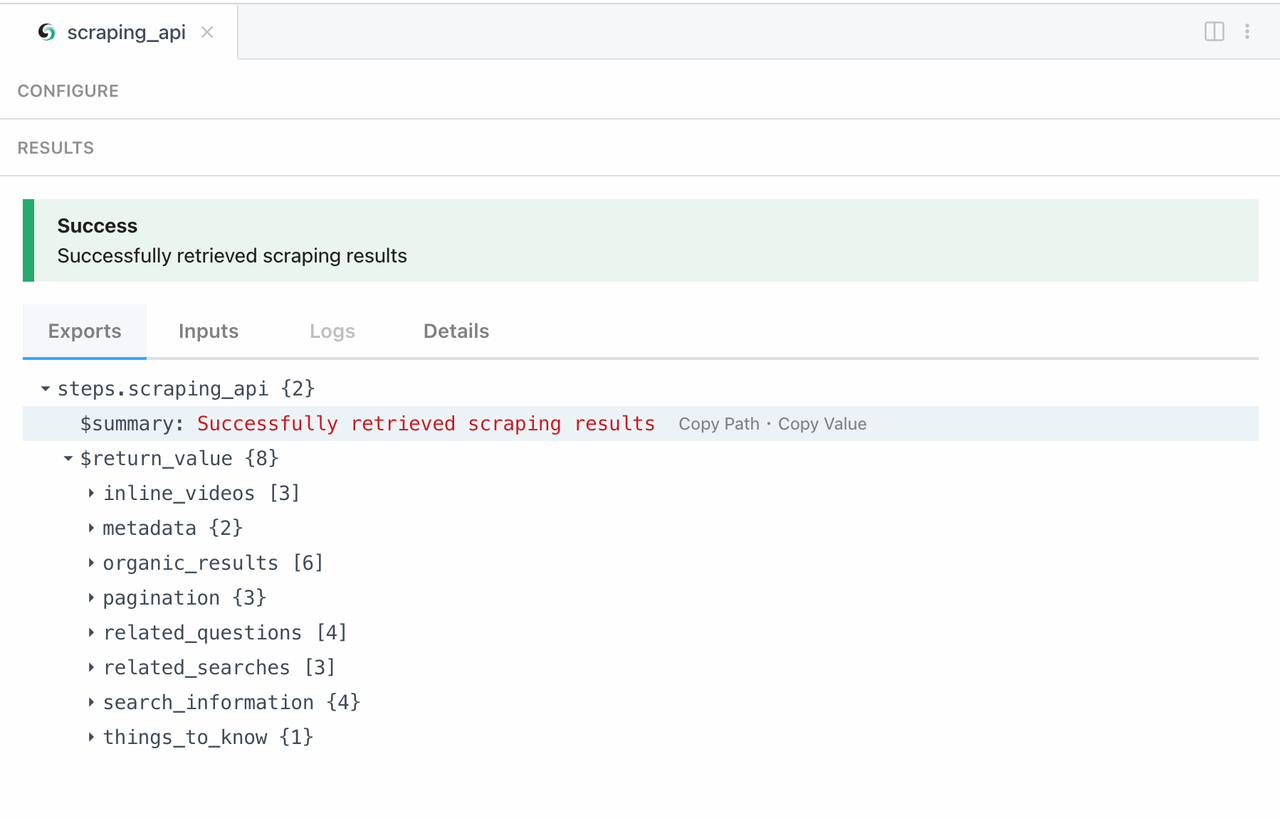
Agora, vamos verificar nossos resultados de scraping:
3. Módulo de API de Scraping Universal
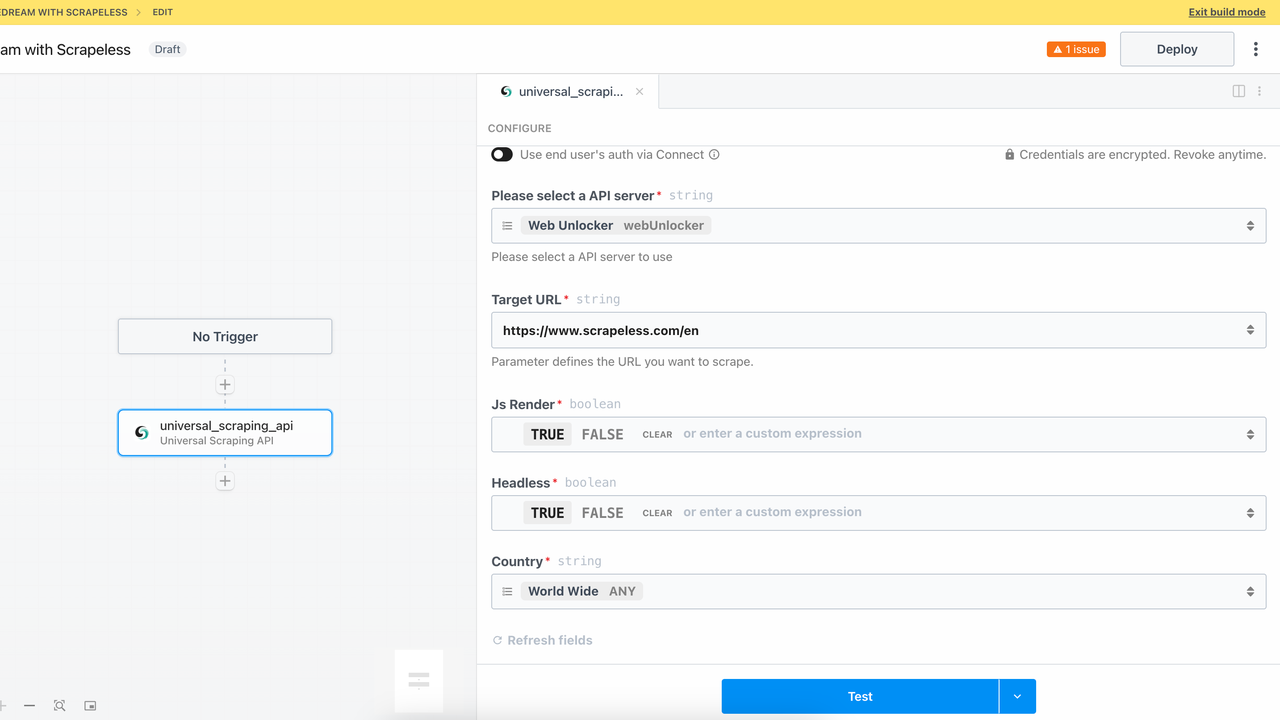
Ao adicionar o módulo Desbloquear um site, você pode chamar com sucesso o serviço de API de Scraping Universal do Scrapeless. Enfrentando páginas complexas, como páginas de renderização JavaScript, verificação de login, mecanismos anti-rastreio, etc., este módulo pode lidar automaticamente com vários obstáculos e acessar páginas, extraindo dados como um navegador.
O seguinte é o resultado HTML retornado:
Começando!
Se você quer fazer scraping de páginas web públicas, extrair tendências de busca ou acessar páginas dinâmicas altamente protegidas, Scrapeless + Pipedream permite que você complete as tarefas de automação de dados mais complexas com um código mínimo.
🔗 Experimente agora -> Scrapeless no Pipedream
Leitura Adicional
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


