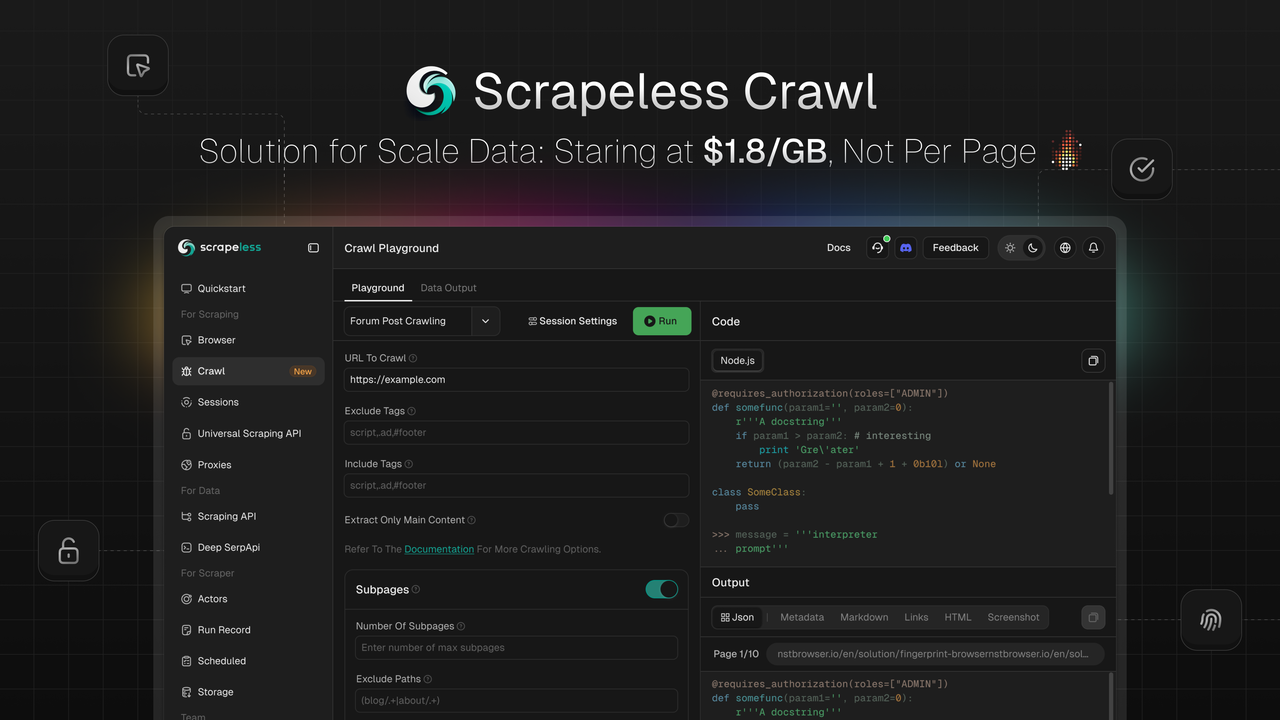
O que é Crawl Sem Desperdício e como funciona?
Senior Web Scraping Engineer
Scrapeless está empolgado em lançar Crawl, uma funcionalidade projetada para raspagem e processamento de dados em larga escala. Crawl se destaca com suas vantagens principais de raspagem recursiva inteligente, capacidades de processamento de dados em massa e saída flexível em múltiplos formatos, capacitando empresas e desenvolvedores a adquirir e processar rapidamente grandes volumes de dados da web — alimentando aplicações em treinamento de IA, análise de mercado, tomada de decisões empresariais e muito mais.
💡Em Breve: Extração e sumarização de dados via AI LLM Gateway, com integração perfeita para estruturas de código aberto e integrações de fluxo de trabalho visual — resolvendo desafios de conteúdo da web para desenvolvedores de IA.
O que é Crawl
Crawl não é apenas uma ferramenta simples de raspagem de dados, mas uma plataforma abrangente que integra funcionalidades de raspagem e navegação.
-
Raspagem em Massa: Suporta raspagem de página única em larga escala e raspagem recursiva.
-
Entrega em Múltiplos Formatos: Compatível com formatos JSON, Markdown, Metadados, HTML, Links e Captura de Tela.
-
Raspagem Anti-Detecção: Nosso núcleo Chromium desenvolvido independentemente permite alta personalização, gerenciamento de sessões e capacidades anti-detecção, como configuração de impressão digital, resolução de CAPTCHA, modo furtivo e rotatividade de proxy para contornar bloqueios de sites.
-
Movido por Chromium Desenvolvido Internamente: Impulsionado pelo nosso núcleo Chromium, permite alta personalização, gerenciamento de sessões e resolução automática de CAPTCHA.
1. Resolvedor Automático de CAPTCHA: Lida automaticamente com tipos comuns de CAPTCHA, incluindo reCAPTCHA v2 e Cloudflare Turnstile/Challenge.
2. Gravação e Reproduzido de Sessões: A reprodução de sessões ajuda você a verificar facilmente ações e solicitações através da reprodução gravada, revisando-as passo a passo para entender rapidamente operações para resolução de problemas e melhoria de processos.
3. Vantagem de Concorrência: Ao contrário de outros rastreadores com limites de concorrência rígidos, o plano básico do Crawl suporta 50 concorrências, com concorrência ilimitada no plano premium.
4. Economia de Custos: Superando concorrentes em sites com medidas anti-raspagem, oferece vantagens significativas na resolução gratuita de captcha — expectativa de economia de 70% nos custos.
Aproveitando capacidades avançadas de raspagem e processamento de dados, o Crawl garante a entrega de dados de busca estruturados em tempo real. Isso capacita empresas e desenvolvedores a sempre ficarem à frente das tendências de mercado, otimizar fluxos de trabalho automatizados baseados em dados e ajustar rapidamente estratégias de mercado.
Resolva Desafios de Dados Complexos com o Crawl: Mais Rápido, Mais Inteligente e Mais Eficiente
Para desenvolvedores e empresas que precisam de dados da web confiáveis em larga escala, o Crawl também oferece:
✔ Raspagem de Dados em Alta Velocidade – Recupere dados de várias páginas da web em questão de segundos
✔ Integração Sem Costura– Em breve integrará com estruturas de código aberto e integrações de fluxo de trabalho visual, como Langchain, N8n, Clay, Pipedream, Make, etc.
✔ Proxies de Geo-alvo – Suporte de Proxies embutido em 195 países
✔ Gerenciamento de Sessão – Gerencie sessões de forma inteligente e visualize sessões LiveURL em tempo real
Como Usar o Crawl
A API Crawl simplifica a raspagem de dados, seja buscando conteúdos específicos de páginas da web em uma única chamada ou rastreando recursivamente todo um site e seus links para coletar todos os dados disponíveis, suportados em múltiplos formatos.
O Scrapeless fornece endpoints para iniciar solicitações de raspagem e verificar seu status/resultados. Por padrão, a raspagem é assíncrona: inicie um trabalho primeiro, depois monitore seu status até a conclusão. No entanto, nossos SDKs incluem uma função simples que gerencia todo o processo e retorna os dados assim que o trabalho termina.
Instalação
Instale o SDK do Scrapeless usando NPM:
Bash
npm install @scrapeless-ai/sdkInstale o SDK do Scrapeless usando PNPM:
Bash
pnpm add @scrapeless-ai/sdkRaspagem de Página Única
Raspe dados específicos (por exemplo, detalhes de produtos, avaliações) de páginas da web em uma chamada.
Uso
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Inicialize o cliente
const client = new Scrapeless({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();Configurações do Navegador
Você pode personalizar as configurações de sessão para raspagem, como o uso de proxies, assim como criar uma nova sessão de navegador.
Scrapeless lida automaticamente com CAPTCHAs comuns, incluindo reCAPTCHA v2 e Cloudflare Turnstile/Challenge—sem necessidade de configuração extra, para mais detalhes, veja solução de CAPTCHAs.
Para explorar todos os parâmetros do navegador, consulte a Referência da API ou Parâmetros do Navegador.
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new Scrapeless({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "QUALQUER",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Configurações de Rastreamento
Os parâmetros opcionais para o trabalho de rastreamento incluem formatos de saída, filtragem para retornar apenas o conteúdo da página principal e definição de um tempo máximo de espera para navegação da página.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new ScrapingCrawl({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();Para uma referência completa sobre o endpoint de rastreamento, consulte a Referência da API.
Rastreamento em Lote
O Rastreamento em Lote funciona da mesma forma que o rastreamento regular, exceto que, em vez de uma única URL, você pode fornecer uma lista de URLs para rastrear de uma vez.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new ScrapingCrawl({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "QUALQUER",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Rastreamento de Subpáginas
A API de Rastreamento suporta o rastreamento recursivo de um site e seus links para extrair todos os dados disponíveis.
Para um uso detalhado, consulte a Referência da API.
Uso
Use o rastreamento recursivo para explorar um domínio inteiro e seus links, extraindo cada pedaço de dado acessível.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new ScrapingCrawl({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "QUALQUER",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Resposta
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "Página Exemplo",
"description": "Uma página web de amostra"
},
"markdown": "# Página Exemplo\nEste é o conteúdo...",
...
},
...
]
}Cada página rastreada tem seu próprio status de completed ou failed e pode ter seu próprio campo de erro, então fique atento a isso.
Para ver o esquema completo, consulte a Referência da API.
Configurações do Navegador
Personalizar as configurações da sessão para trabalhos de rastreamento segue o mesmo processo que a criação de uma nova sessão de navegador. As opções disponíveis incluem configuração de proxy. Para ver todos os parâmetros de sessão suportados, consulte a Referência da API ou Parâmetros do Navegador.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new ScrapingCrawl({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "QUALQUER",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();Configurações de Scraping
Os parâmetros podem incluir formatos de saída, filtros para retornar apenas o conteúdo da página principal e configurações máximas de timeout para navegação na página.
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// Inicializa o cliente
const client = new ScrapingCrawl({
apiKey: "sua-chave-api", // Obtenha sua chave API em https://scrapeless.com
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();Para uma referência completa sobre o endpoint de crawling, confira a Referência da API.
Explorando os Diversos Casos de Uso do Crawling
Um playground integrado está disponível para desenvolvedores testarem e depurarem seu código, e você pode utilizar o Crawl para quaisquer necessidades de scraping, por exemplo:
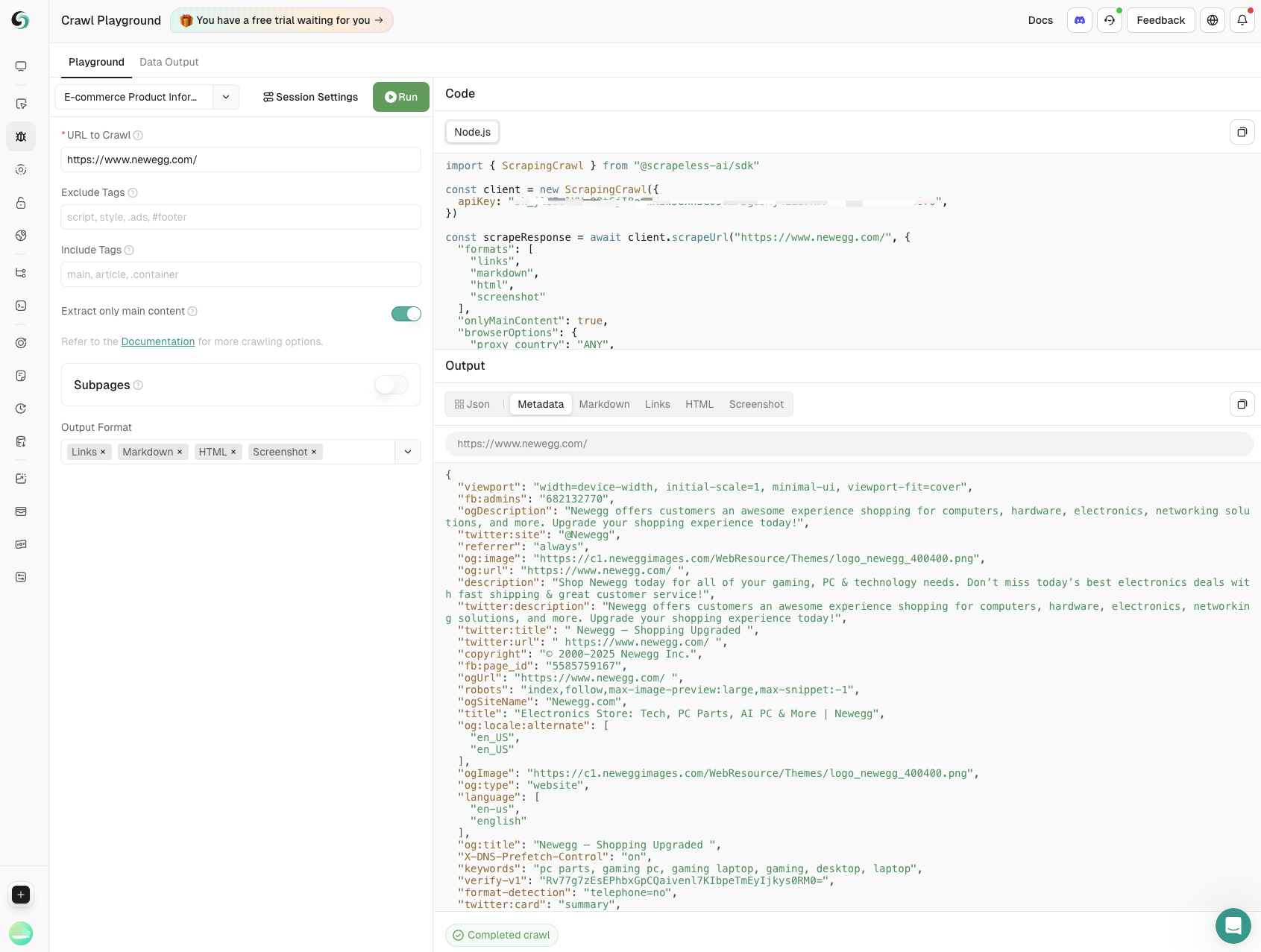
- Scraping de Informações de Produtos
Dados-chave, incluindo nomes de produtos, preços, classificações de usuários e contagens de avaliações, são extraídos por meio de scraping em websites de E-commerce. Suporta totalmente o monitoramento de produtos e auxilia empresas a tomar decisões informadas.
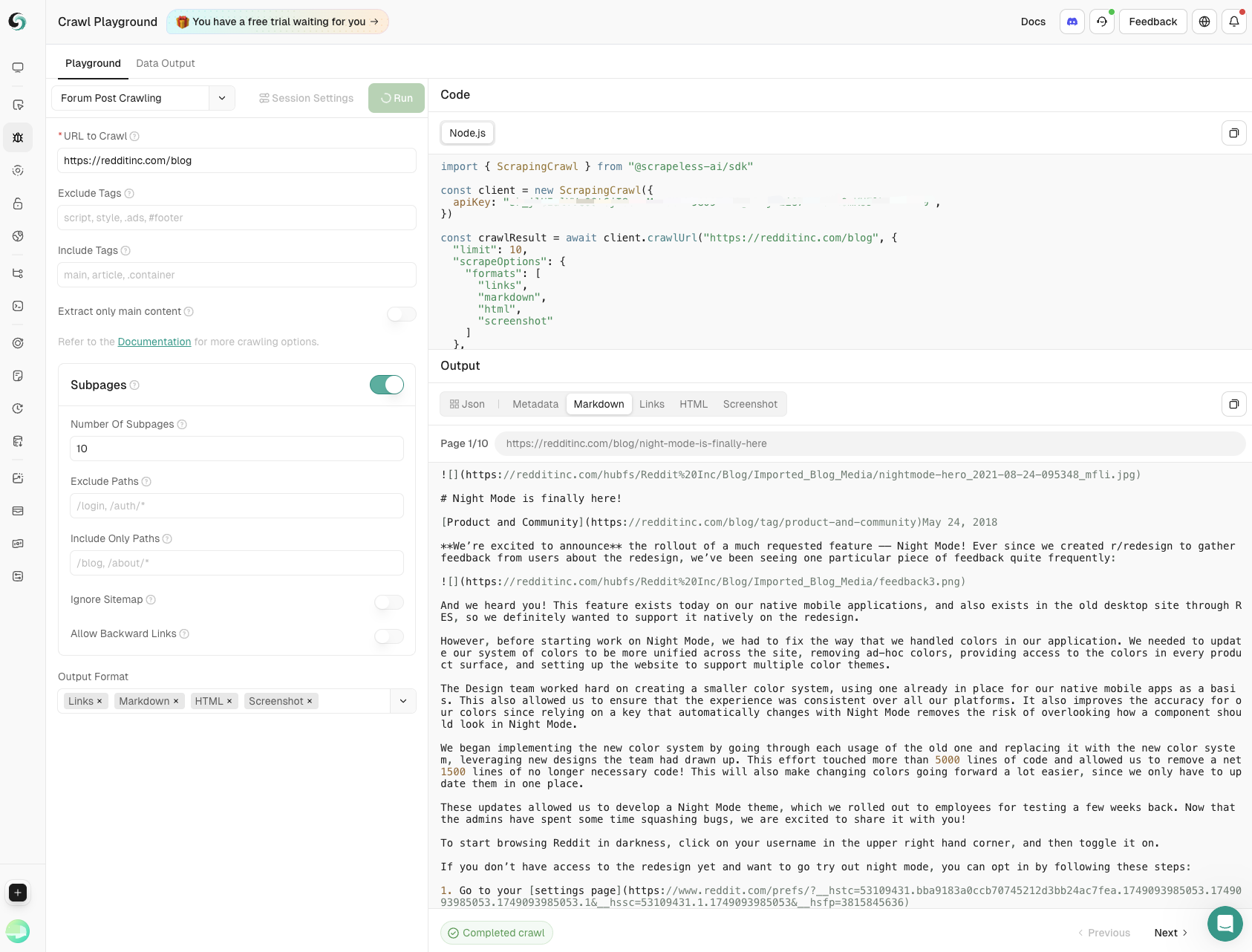
- Crawling de Postagens em Fóruns
Capture o conteúdo principal das postagens e comentários de subpáginas com controle preciso sobre a profundidade e a amplitude, garantindo insights abrangentes das discussões da comunidade.
Aproveite o Crawl e Scrape Agora!
Custo-Eficiente e Acessível para qualquer necessidade: Começa em $1,8/GB, Não por Página
Supere os concorrentes com nosso scraper baseado em Chromium, apresentando um modelo de preços que combina volume de proxies e taxa horária, oferecendo até 70% de economia em projetos de dados em larga escala em comparação com modelos de contagem de páginas.
Registre-se para um Teste Agora e obtenha o Robust Web Toolkit.
💡Para usuários de alto volume, entre em contato conosco para preços personalizados – taxas competitivas ajustadas às suas necessidades.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


