Navegador em Nuvem Sem Raspagem em Ação: Adaptando o Puppeteer para Automação, Tratamento de Impressões Digitais e CAPTCHA
Expert Network Defense Engineer
Na automação da web e em cenários de raspagem de dados, os desenvolvedores frequentemente enfrentam três desafios técnicos principais:
- Isolamento de Ambiente:
Ao executar dezenas ou até centenas de sessões de navegador independentes simultaneamente, soluções tradicionais de implantação local sofrem com alto consumo de recursos, gestão complexa e configuração complicada.
- Riscos de Detecção de Impressão Digital:
Visitas repetidas usando a mesma impressão digital do navegador podem facilmente ativar mecanismos de detecção de anti-bot e impressão digital em sites-alvo.
- Interrupções de CAPTCHA:
Uma vez ativadas, verificações como reCAPTCHA ou Cloudflare Turnstile interrompem scripts de automação. Integrar serviços de resolução de CAPTCHA de terceiros não apenas aumenta o custo e a complexidade do desenvolvimento, mas também reduz a eficiência de execução.
Esses problemas frequentemente requerem que os desenvolvedores gastem tempo significativo configurando ambientes locais ou integrando serviços externos, aumentando tanto o tempo quanto os custos operacionais.
Essencialmente, o que é necessário é uma ferramenta capaz de:
- Ambientes Massivamente Isolados:
Gerar perfis de navegador independentes via API, com cada perfil representando uma instância de navegador totalmente isolada.
- Randomização Automática de Impressão Digital:
Randomizar parâmetros chave como User-Agent, fuso horário, idioma e resolução de tela—tudo isso mantendo total consistência com ambientes de navegador reais.
- Manuseio Integrado de CAPTCHA:
Reconhecer e resolver automaticamente desafios comuns de CAPTCHA sem intervenção humana ou integrações de terceiros.
E quanto aos navegadores com impressão digital?
Na automação de empresas domésticas, navegadores com impressão digital implantados localmente são amplamente utilizados. No entanto, frequentemente consomem grandes quantidades de recursos do sistema, são difíceis de manter de maneira consistente entre instâncias e ainda requerem serviços de CAPTCHA de terceiros para o tratamento de verificações.
Em contraste, navegadores headless baseados em nuvem modernos, como Scrapeless.com, oferecem uma alternativa mais escalável e eficiente. Eles permitem que os desenvolvedores:
- Criem perfis de navegador isolados via API,
- Randomizem impressões digitais nativamente, e
- Manipulem automaticamente desafios de CAPTCHA,
tudo na nuvem—reduzindo significativamente os custos de desenvolvimento e manutenção, enquanto suportam cargas de trabalho de alta concorrência.
Nas seções seguintes, exploraremos vários cenários de benchmark para avaliar como os navegadores headless baseados em nuvem se comportam em termos de isolamento de impressão digital, concorrência, e manuseio de CAPTCHA.
⚠️ Aviso:
Ao usar qualquer solução de automação de navegador, sempre cumpra os Termos de Serviço do site-alvo, as regras do robots.txt, e as leis e regulamentos relevantes.
A raspagem de dados para fins não autorizados ou ilegais, ou infringindo os direitos de terceiros, é estritamente proibida.
Não assumimos responsabilidade por quaisquer consequências legais ou perdas resultantes do uso indevido.
Configuração do Ambiente
Primeiro, instale o SDK Node do Scrapeless. Se você não tiver o Node instalado, por favor instale o Node anteriormente.
bash
npm install @scrapeless-ai/sdk puppeteer-coreTeste básico de conexão
js
// defina sua chave de API
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();Se o título da página for impresso, o ambiente está configurado com sucesso.
Pronto para potencializar sua automação da web? Experimente o Scrapeless Cloud Browser hoje e experimente gerenciamento de perfil sem costura, impressões digitais independentes e manuseio automatizado de CAPTCHA—tudo na nuvem!
Caso 1: Verificação de Impressão Digital Aleatória do Navegador
Objetivo: Verificar se a impressão digital do navegador gerada por cada perfil é realmente independente.
Este exemplo:
- Cria múltiplos perfis independentes
- Visita o site de teste de impressão digital: https://xfreetool.com/zh/fingerprint-checker
- Extrai e compara o ID da impressão digital do navegador de cada perfil
- Valida a independência e aleatoriedade da impressão digital
O site https://xfreetool.com/zh/fingerprint-checker é um site que verifica impressões digitais de navegadores e captura automaticamente informações de impressão digital do navegador visitante.
Código de Exemplo:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from "@scrapeless-ai/sdk";
// Constantes de configuração
const MAX_PROFILES = 3; // Número máximo de perfis necessários
// Inicializar cliente
const client = new ScrapelessClient();- Obtenha o ID da impressão digital do navegador a partir da página do CreepJS
- @param {Object} page - Objeto de página do Puppeteer
- @returns {Promise<string>} ID da impressão digital do navegador
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
-
Executar uma tarefa única
-
@param {string} profileId - ID do perfil
-
@param {number} taskId - ID da tarefa
-
@returns {Promise<string>} ID da impressão digital do navegador
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'Meu Navegador',
sessionTTL: 45000,
profileId: profileId,
});const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);await page.goto('https://xfreetool.com/zh/fingerprint-checker', { waitUntil: 'networkidle0' }); // Recuperar e imprimir informações sobre cookies const cookies = await page.cookies(); console.log(`[${taskId}] Cookies:`); cookies.forEach(cookie => { // console.log(` Nome: ${cookie.name}, Valor: ${cookie.value}, Domínio: ${cookie.domain}`); }); const fpId = await getFPId(page); console.log(`[${taskId}] ✓ ID da impressão digital do navegador = ${fpId}`); return fpId;} finally {
await browser.close();
}
};
/**
- Criar um novo perfil
- @returns {Promise<string>} ID do perfil recém-criado
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('Meu Perfil' + randomString());
console.log('Perfil criado:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Falha ao criar perfil:', error);
throw error;
}
};
/**
-
Obter ou criar a lista necessária de perfis
-
@param {number} count - Número de perfis necessários
-
@returns {Promise<string[]>} Lista de IDs de Perfis
*/
const getProfiles = async (count) => {
try {
// Obter perfis existentes
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];// Criar novos perfis se os existentes forem insuficientes if (profiles.length < count) { const profilesToCreate = count - profiles.length; const creationPromises = Array(profilesToCreate) .fill(0) .map(() => createProfile()); const newProfiles = await Promise.all(creationPromises); return [ ...profiles.map(p => p.profileId), ...newProfiles ]; } // Retornar os primeiros `count` perfis se houver suficientes return profiles.slice(0, count).map(p => p.profileId);} catch (error) {
console.error('Falha ao obter perfis:', error);
throw error;
}
};
/**
-
Executar tarefas em paralelo
*/
const runTasks = async () => {
try {
// Obter ou criar os perfis necessários
const profileIds = await getProfiles(MAX_PROFILES);// Criar tarefas para cada perfil const tasks = profileIds.map((profileId, index) => { const taskId = index + 1; return runTask(profileId, taskId); }); await Promise.all(tasks); console.log('Todas as tarefas concluídas com sucesso');} catch (error) {
console.error('Erro ao executar tarefas:', error);
}
};
// Executar tarefas
await runTasks();
**Resultados do Teste:**
1. 3 perfis são executados em paralelo, cada ambiente é completamente independente.
2. O ID da impressão digital do navegador para cada perfil é completamente diferente.
**Explicação dos Resultados:**
1. **Unicidade da Impressão Digital**
3 perfis retornam IDs de impressões digitais diferentes. Cada vez que um perfil é criado, a impressão digital do navegador é gerada aleatoriamente, evitando a detecção devido a impressões digitais duplicadas.
2. **Verificação da Isolamento do Ambiente**
Os cookies de cada perfil são completamente independentes:
* Cookies do Perfil 1 não aparecem nos Perfis 2 ou 3
* Vários perfis podem fazer login em diferentes contas simultaneamente sem afetar um ao outro
---
### Caso 2: Teste de Alta Concurrência e Isolamento do Ambiente
**Objetivo:** Verificar o isolamento do ambiente dos perfis em cenários de alta concorrência e testar a capacidade de criar e gerenciar perfis em lote.
Em muitos casos, para acelerar a extração de dados ou fazer login em várias contas, as ferramentas precisam suportar alta concorrência e isolamento de ambiente - o que equivale a ter dezenas ou centenas de instâncias independentes de navegador simultaneamente. Scrapeless suporta a adição de perfis manualmente ou a operação de perfis via API.
Este exemplo:
* Cria 10 perfis independentes via API
* Cada perfil visita primeiro [https://abrahamjuliot.github.io/creepjs/](https://abrahamjuliot.github.io/creepjs/) para obter o ID da impressão digital do navegador
* Depois visita [https://minecraftpocket-servers.com/login/](https://minecraftpocket-servers.com/login/) e tira uma captura de tela
* Verifica a independência da impressão digital e o isolamento do ambiente
**Código de Exemplo:**process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
// Constantes de configuração
const MAX_PROFILES = 5; // Número máximo de perfis necessários
// Inicializar cliente
const client = new ScrapelessClient({});
/**
- Obter o ID da impressão digital do navegador a partir da página CreepJS
- @param {Object} page - Objeto da página Puppeteer
- @returns {Promise<string>} ID da impressão digital do navegador
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
-
Executar uma única tarefa
-
@param {string} profileId - ID do perfil
-
@param {number} taskId - ID da tarefa
-
@returns {Promise<string>} ID da impressão digital do navegador
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'Meu Navegador',
sessionTTL: 30000,
profileId: profileId,
});const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});try {
// Etapa 1: Obter impressão digital do navegador
let page = await browser.newPage();
page.setDefaultTimeout(30000);await page.goto('https://abrahamjuliot.github.io/creepjs/', { waitUntil: 'networkidle0' }); const fpId = await getFPId(page); await page.close(); // Fechar a primeira página // Etapa 2: Usar uma nova página para captura de tela page = await browser.newPage(); const screenshotPath = `fp_${taskId}_${fpId}.png`; await page.goto('https://minecraftpocket-servers.com/login/', { waitUntil: 'networkidle0' }); await page.screenshot({ fullPage: true, path: screenshotPath }); console.log(`[${taskId}] ✓ ID da Impressão Digital: ${fpId}, Captura de tela salva em: ${screenshotPath}`); return fpId;} finally {
await browser.close();
}
};
/**
- Criar um novo perfil
- @returns {Promise<string>} ID do perfil recém-criado
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('Meu Perfil' + randomString());
console.log('Perfil criado:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Falha ao criar perfil:', error);
throw error;
}
};
/**
-
Obter ou criar a lista necessária de perfis
-
@param {number} count - Número de perfis necessários
-
@returns {Promise<string[]>} Lista de IDs de Perfis
*/
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({
page: 1,
pageSize: count
});const profiles = response?.docs || []; if (profiles.length < count) { const profilesToCreate = count - profiles.length; const creationPromises = Array(profilesToCreate) .fill(0) .map(() => createProfile()); const newProfiles = await Promise.all(creationPromises); return [ ...profiles.map(p => p.profileId), ...newProfiles ]; } return profiles.slice(0, count).map(p => p.profileId);} catch (error) {
console.error('Falha ao obter perfis:', error);
throw error;
}
};
/**
-
Executar tarefas concorrentemente
*/
const runTasks = async () => {
try {
console.log(Iniciando tarefas, preciso de ${MAX_PROFILES} perfis);
const profileIds = await getProfiles(MAX_PROFILES);
console.log(Recuperados ${profileIds.length} perfis);const tasks = profileIds.map((profileId, index) => { const taskId = index + 1; return runTask(profileId, taskId); }); const results = await Promise.all(tasks); console.log('Todas as tarefas concluídas com sucesso!'); console.log('Lista de IDs de Impressão Digital:', results);} catch (error) {
javascript
console.error('Erro ao executar tarefas:', error);
}
};
// Executar tarefas
await runTasks();Resultados do Teste:
- Independência de Impressão Digital: Impressões digitais e parâmetros do ambiente são gerados aleatoriamente e mutuamente distintos.
- Isolamento do Ambiente: Cada tarefa é executada em um perfil independente; os dados do navegador (Cookie, LocalStorage, Session, etc.) não são compartilhados.
- Estabilidade de Concurrency: 10 perfis criados e executados com sucesso de forma concorrente.
Explicação do Resultado do Exemplo:
- Processo de Criação e Conexão do Perfil
A saída mostra o processo completo de criação de perfil e conexão do navegador:
Perfil criado: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
Perfil criado: d92b0cb1-5608-4753-92b0-b7125fb18775
...
info Puppeteer: Conectado com sucesso ao navegador Scrapeless {}
...
Todas as tarefas concluídas com sucessoTodos os 10 perfis são criados e conectados ao Scrapeless Cloud Browser quase simultaneamente, demonstrando estabilidade sob alta concorrência.
- Verificação da Independência de Impressões Digitais
Cada perfil retorna um ID de impressão digital completamente diferente.
As 10 impressões digitais únicas provam que a impressão digital do navegador de cada perfil é gerada de forma independente e aleatória, sem duplicatas.
-
Estabilidade de Execução em Alta Concurrency
Todas as 10 tarefas são executadas simultaneamente, sendo concluídas com sucesso sem erros ou conflitos. -
Várias Maneiras de Criar Perfis
Scrapeless oferece várias maneiras de criar e gerenciar perfis:
- Criação Manual pelo Painel: Crie perfis diretamente do Painel para um início rápido e operações individuais.
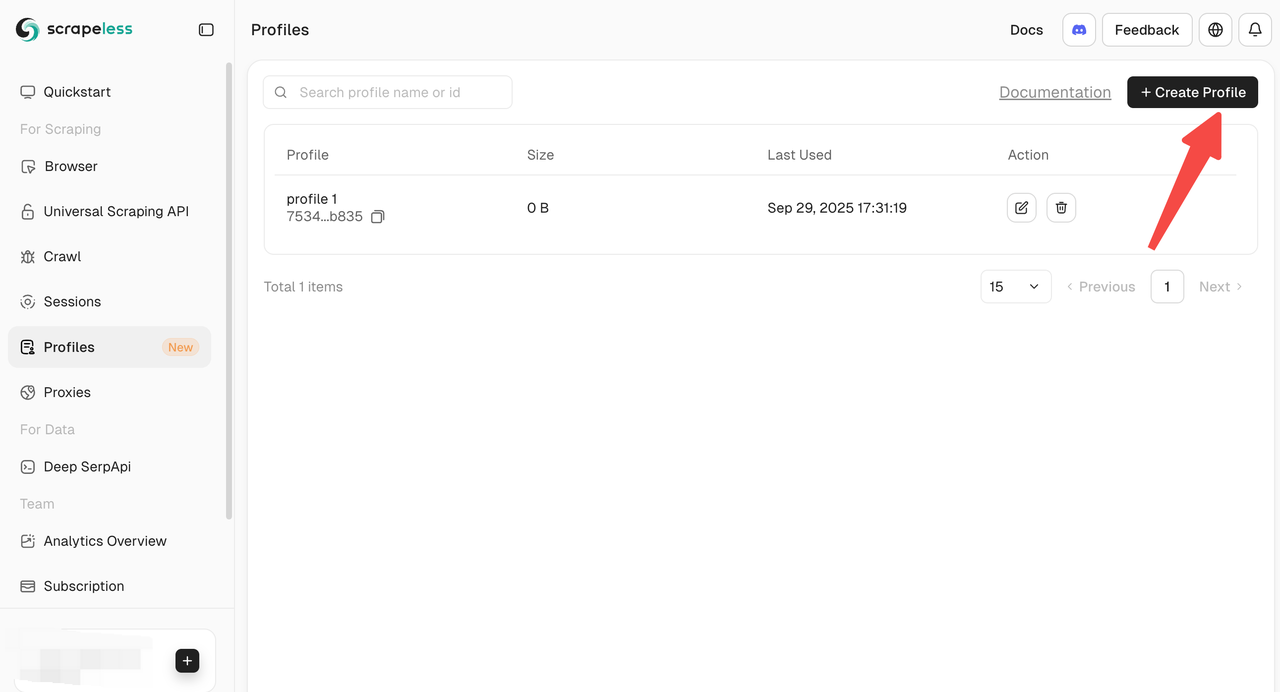
- Criação pela API: Crie perfis programaticamente através da API de Criação de Perfis para operações em lote.
- Criação pela SDK: Use a SDK oficial para criar perfis, ideal para alta concorrência ou fluxos de trabalho automatizados personalizados.
Caso 3: Desafio Cloudflare + Google reCAPTCHA – Bypass de CAPTCHA totalmente automatizado sem intervenção manual
Objetivo: Testar se o Scrapeless Cloud Browser consegue detectar e passar automaticamente desafios reCAPTCHA ou Cloudflare ao visitar sites, e registrar processos e resultados de verificação reproduzíveis.
Este exemplo:
- Visita a página de busca da Amazon https://www.amazon.com/s?k=toy (alta probabilidade de acionar reCAPTCHA)
- Lida automaticamente com o CAPTCHA e extrai dados de produtos
- Verifica a capacidade de lidar automaticamente com o CAPTCHA
Código do Exemplo:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // Número máximo de perfis necessários
// Obter ID de impressão digital do page CreepJS
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'Meu Navegador',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', { timeout: 15000 });
console.log('Página carregada com sucesso...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
javascript
const imageUrl = imageElement ? imageElement.src : 'N/D';
const asin = product.getAttribute('data-asin') || 'N/D';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// Criar um novo perfil
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('Meu Perfil' + randomString());
console.log('Perfil criado:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('Falha ao criar perfil:', error);
throw error;
}
};
// Obter ou criar perfis necessários
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({ page: 1, pageSize: count });
const profiles = response?.docs;
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('Falha ao obter perfis:', error);
throw error;
}
};
// Executar tarefas simultaneamente
const runTasks = async () => {
try {
const profileIds = await getProfiles(MAX_PROFILES);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('Todas as tarefas concluídas com sucesso');
} catch (error) {
console.error('Erro ao executar tarefas:', error);
}
};
// Executar tarefas
await runTasks();Resultados do Teste:
- A página de busca da Amazon lidou automaticamente com o reCAPTCHA acionado
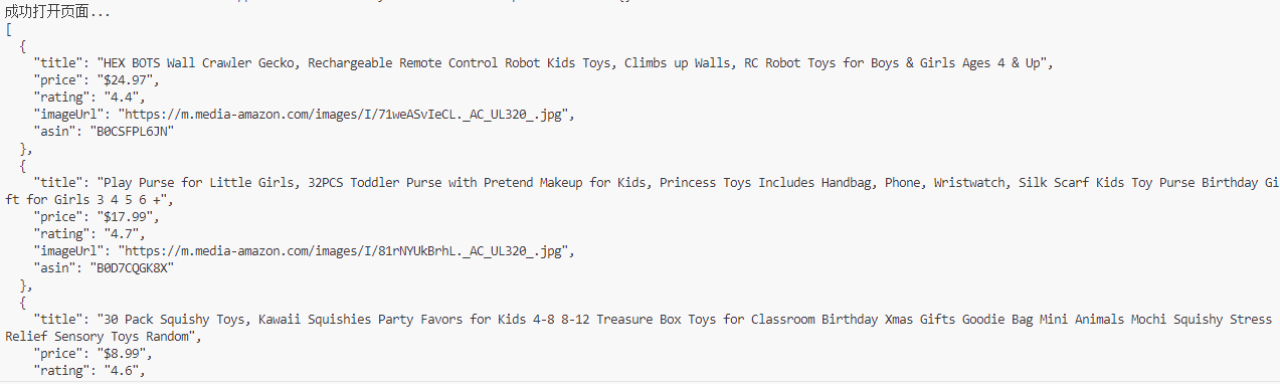
- Título do produto, preço, classificação, imagem, ASIN e outros dados extraídos com sucesso
- Todo o processo não exigiu intervenção humana; o CAPTCHA foi detectado e passado automaticamente
Explicação do Resultado de Exemplo:
- Desvio de CAPTCHA Bem-Sucedido e Extração de Dados:
A página é carregada com sucesso e os dados do produto são extraídos:
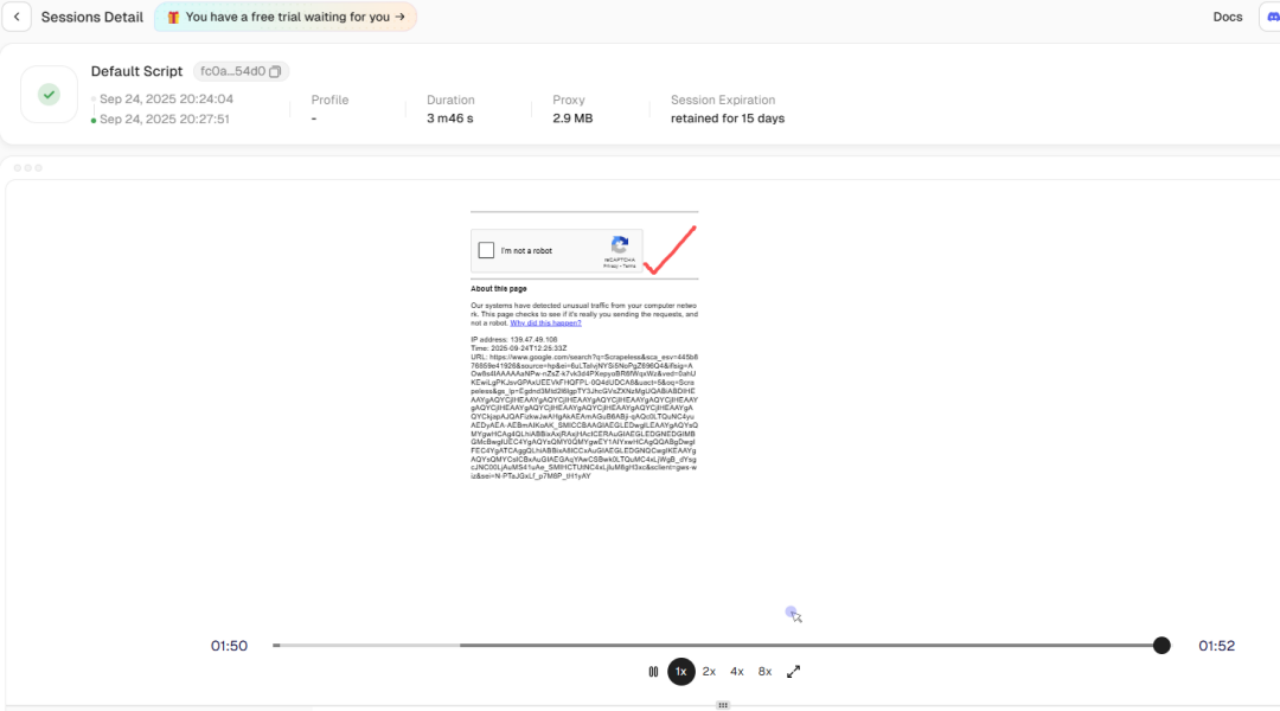
- Tratamento Automatizado de CAPTCHA:
Usando o recurso de reprodução de histórico de sessões, você pode ver que a verificação de risco foi acionada durante a coleta de dados, mas o Scrapeless contornou automaticamente o reCAPTCHA internamente. Isso resolve o obstáculo do bloqueio de coleta de dados em segundo plano.
Normalmente, visitar páginas de busca da Amazon pode acionar reCAPTCHA que requer interação manual. Com o Scrapeless Cloud Browser:
- reCAPTCHA é detectado automaticamente
- API integrada completa o fluxo de verificação automaticamente
- Script continua a executar e extrai dados do produto
- Observabilidade na Nuvem:
O painel Scrapeless fornece:
- Sessões Ao Vivo: Monitoramento em tempo real de instâncias do navegador para observar a execução do script
- Histórico de Sessões: Reproduzir sessões passadas para depuração e revisão do tratamento de CAPTCHA
Mesmo que o navegador funcione na nuvem, ele oferece uma experiência semelhante à depuração local, reduzindo drasticamente a dificuldade da depuração em navegadores na nuvem.
Resumo
A partir dos três cenários práticos, podemos resumir o desempenho do Scrapeless Cloud Browser em dimensões-chave:
- Concorrência e Isolamento de Ambiente
- Suporta criação e gerenciamento em lote de perfis
- A impressão digital, cookies, cache e dados do navegador de cada perfil são totalmente isolados
- Suporta 10+ tarefas simultâneas nos exemplos sem conflitos ou contenção de recursos; pode escalar para milhares de tarefas simultâneas
- Equivalente a ter centenas ou milhares de instâncias de navegadores independentes simultaneamente
- Impressões Digitais Aleatórias de Navegador
- Cada criação de perfil gera aleatoriamente parâmetros principais, como agente do usuário, fuso horário, idioma e resolução de tela
- A impressão digital imita de perto ambientes reais de navegador
- Reduz a probabilidade de ser detectado como acesso automatizado
- Automação de CAPTCHA Integrada
- Suporta reconhecimento automático de reCAPTCHA, Cloudflare Turnstile/Challenge e outros tipos de CAPTCHA
- Completa a verificação automaticamente sem intervenção humana
- Observabilidade de Navegador na Nuvem
- Sessões Ao Vivo: Monitore a execução do navegador em tempo real
- Histórico de Sessões: Reproduza sessões passadas para depuração e verificação
Para cenários de automação que exigem isolamento de múltiplos ambientes, alta concorrência e bypass de CAPTCHA, o Scrapeless Cloud Browser é uma opção sólida.
Pronto para potencializar sua automação na web? Experimente o Scrapeless Cloud Browser hoje e experimente gerenciamento de perfil sem costura, impressões digitais independentes e manuseio automatizado de CAPTCHA—tudo na nuvem!
Isenção de responsabilidade: O uso de qualquer ferramenta de automação deve estar em conformidade com os termos de serviço do site-alvo e as leis pertinentes. Este artigo é apenas para fins de pesquisa e validação técnica.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


